本页面介绍了如何从图片中移除对象。借助 Imagen on Vertex AI,您可以指定一个蒙版区域(称为修复),以从图片中移除对象。您可以自带蒙版,也可以让 Imagen on Vertex AI 为您生成蒙版。
内容移除示例
以下示例使用修复和图片蒙版从现有图片中移除内容:
输入
要修改的基础映像* |
使用 Google Cloud 控制台中的工具指定的蒙版区域 |
文本提示 |
|---|---|---|

|
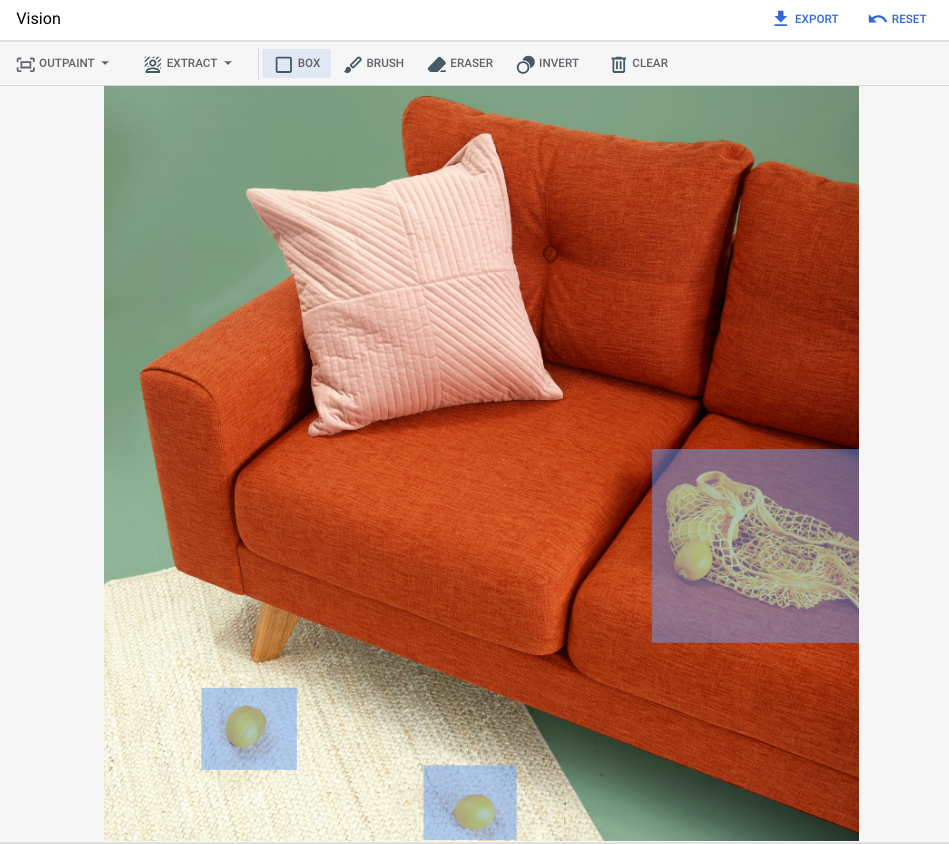
|
提示:从图片中移除选定对象 |
* 图片来源:Unsplash 用户 Inside Weather。
在 Google Cloud 控制台中指定了一个蒙版区域后的输出
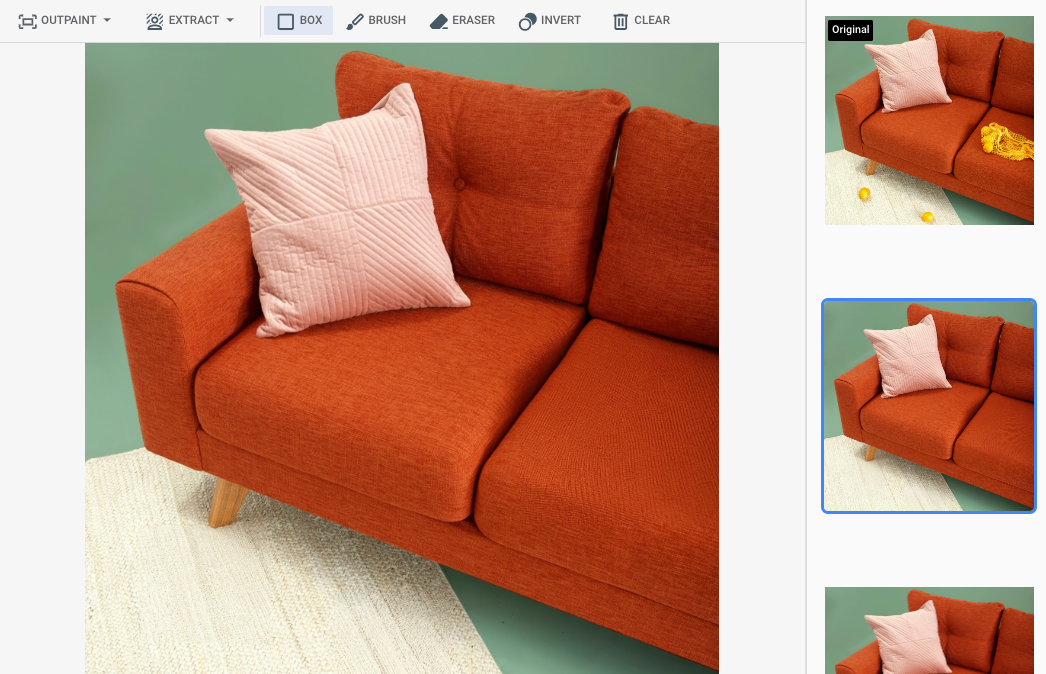
|
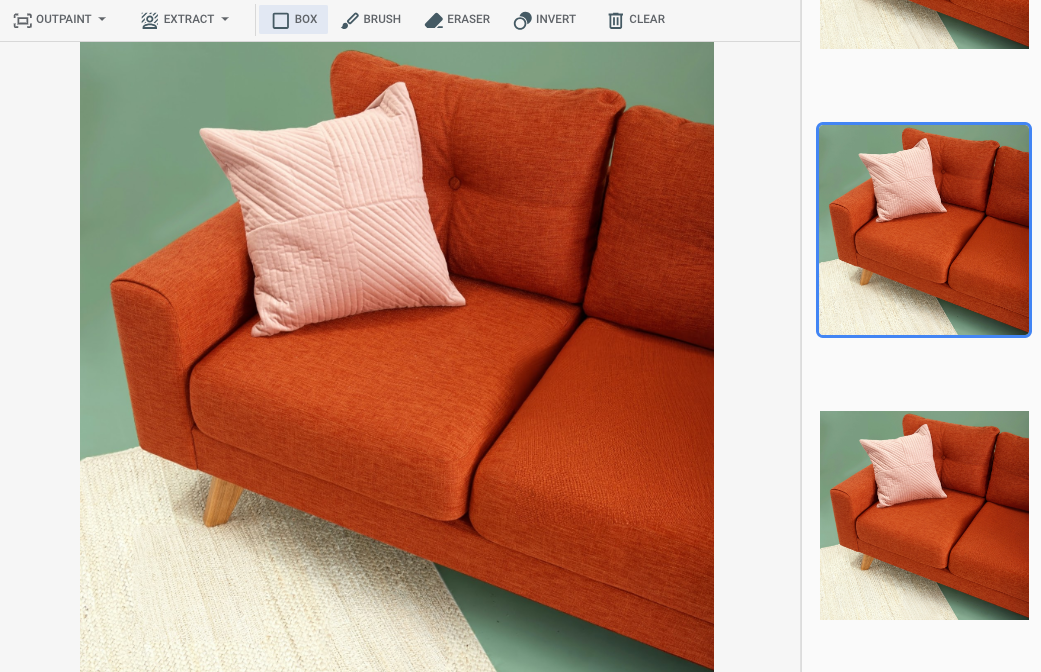
|
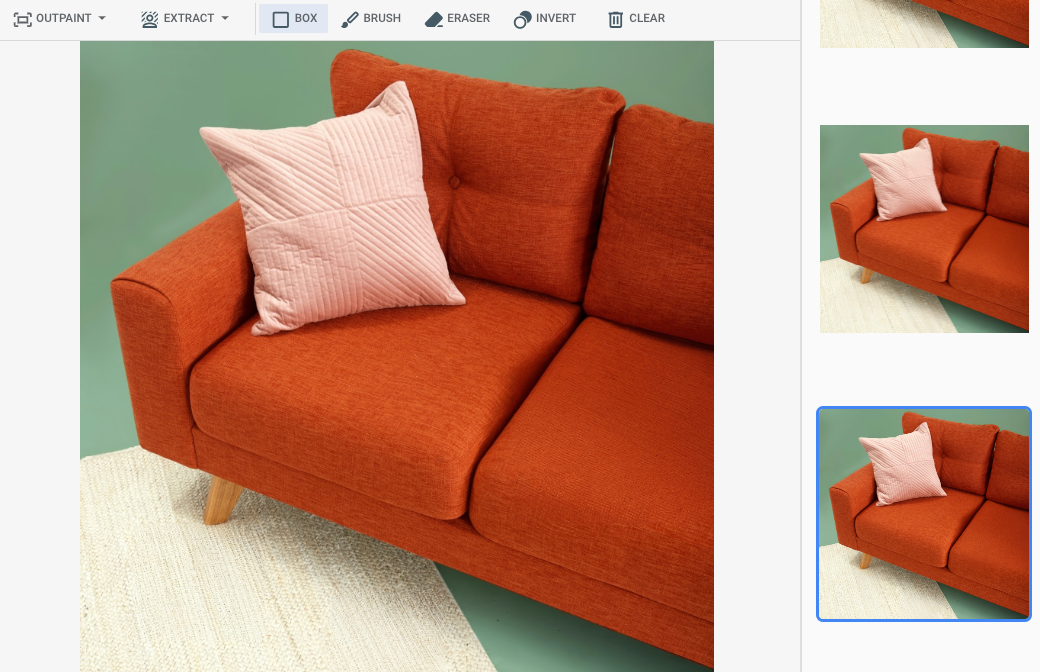
|
查看 Imagen for Editing and Customization 模型卡片
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
为您的环境设置身份验证。
Select the tab for how you plan to use the samples on this page:
Console
When you use the Google Cloud console to access Google Cloud services and APIs, you don't need to set up authentication.
Java
如需在本地开发环境中使用本页面上的 Java 示例,请安装并初始化 gcloud CLI,然后使用您的用户凭证设置应用默认凭证。
安装 Google Cloud CLI。
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Google Cloud
Node.js
如需在本地开发环境中使用本页面上的 Node.js 示例,请安装并初始化 gcloud CLI,然后使用您的用户凭证设置应用默认凭证。
安装 Google Cloud CLI。
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Google Cloud
Python
如需在本地开发环境中使用本页面上的 Python 示例,请安装并初始化 gcloud CLI,然后使用您的用户凭证设置应用默认凭证。
安装 Google Cloud CLI。
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
Google Cloud
REST
如需在本地开发环境中使用本页面上的 REST API 示例,请使用您提供给 gcloud CLI 的凭证。
安装 Google Cloud CLI。
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
如需了解详情,请参阅 Google Cloud 身份验证文档中的使用 REST 时进行身份验证。
使用定义的蒙版区域进行移除
使用以下示例可指定通过修复移除内容。在这些示例中,您可以指定基础图片、文本提示和蒙版区域来修改基础图片。
Imagen 3
使用以下示例通过 Imagen 3 模型发送修复请求。
控制台
-
在 Google Cloud 控制台中,依次前往 Vertex AI > Media Studio 页面。
- 点击上传。在显示的文件对话框中,选择要上传的文件。
- 点击修复。
- 在参数面板中,点击修复(移除)。
-
执行下列其中一项操作:
- 上传您自己的蒙版:
- 在电脑上创建蒙版。
- 点击上传蒙版。在显示的对话框中,选择要上传的蒙版。
- 定义自己的蒙版:在修改工具栏中,使用蒙版工具( 方框、 画笔或 masked_transitions 反转工具)指定要添加内容的一个或多个区域。
- 上传您自己的蒙版:
-
可选:在参数面板中,调整以下选项:
- 模型:要使用的 Imagen 模型
- 结果数量:要生成的结果数量
- 否定提示:要避免生成的内容
- 在提示字段中,输入提示以修改图片。
- 点击 生成。
Python
安装
pip install --upgrade google-genai
如需了解详情,请参阅 SDK 参考文档。
设置环境变量以将 Gen AI SDK 与 Vertex AI 搭配使用:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=us-central1 export GOOGLE_GENAI_USE_VERTEXAI=True
REST
如需了解详情,请参阅修改图片 API 参考文档。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目 ID。
- LOCATION:您的项目的区域。 例如
us-central1、europe-west2或asia-northeast3。如需查看可用区域的列表,请参阅 Vertex AI 上的生成式 AI 位置。 prompt:为获得最佳结果,在使用修复来移除时,请省略提示和negativePrompt。- B64_BASE_IMAGE:要修改或放大的基础图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- B64_MASK_IMAGE:您要用作蒙版层来修改原始图片的黑白图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- MASK_DILATION - 浮点数。将此蒙版扩大的图像宽度的百分比。建议使用值
0.01来弥补不完美的输入蒙版。 - EDIT_STEPS - 整数。基本模型的采样步数。对于修复移除,请从
12步数开始。如果质量不符合您的要求,请将步数增加到75的上限。增加步数也会增加请求延迟时间。 - EDIT_IMAGE_COUNT - 已修改图片的数量。接受的整数值:1-4。默认值:4。
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict
请求 JSON 正文:
{ "instances": [ { "prompt": "", "referenceImages": [ { "referenceType": "REFERENCE_TYPE_RAW", "referenceId": 1, "referenceImage": { "bytesBase64Encoded": "B64_BASE_IMAGE" } }, { "referenceType": "REFERENCE_TYPE_MASK", "referenceId": 2, "referenceImage": { "bytesBase64Encoded": "B64_MASK_IMAGE" }, "maskImageConfig": { "maskMode": "MASK_MODE_USER_PROVIDED", "dilation": MASK_DILATION } } ] } ], "parameters": { "editConfig": { "baseSteps": EDIT_STEPS }, "editMode": "EDIT_MODE_INPAINT_REMOVAL", "sampleCount": EDIT_IMAGE_COUNT } }如需发送请求,请选择以下方式之一:
以下示例响应适用于包含curl
将请求正文保存在名为
request.json的文件中,然后执行以下命令:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict"PowerShell
将请求正文保存在名为
request.json的文件中,然后执行以下命令:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict" | Select-Object -Expand Content"sampleCount": 2的请求。响应返回两个预测对象,其中生成的图片字节采用 base64 编码。{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }Imagen 2
使用以下示例通过 Imagen 2 模型发送修复请求。
控制台
-
在 Google Cloud 控制台中,依次前往 Vertex AI > Media Studio 页面。
-
在下层任务面板中,点击 修改图片。
-
点击上传以选择要修改的本地存储的产品图片。
-
在修改工具栏中,使用蒙版工具(方框、画笔或 masked_transitions 反转工具)指定要移除内容的一个或多个区域。
-
可选:在参数面板中,调整结果数量、否定提示(可选移除)、文本提示指南或其他参数。
-
将提示字段留空。
-
点击 生成。
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目 ID。
- LOCATION:您的项目的区域。 例如
us-central1、europe-west2或asia-northeast3。如需查看可用区域的列表,请参阅 Vertex AI 上的生成式 AI 位置。 - B64_BASE_IMAGE:要修改或放大的基础图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- B64_MASK_IMAGE:您要用作蒙版层来修改原始图片的黑白图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- EDIT_IMAGE_COUNT:已修改图片的数量。默认值:4。
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict
请求 JSON 正文:
{ "instances": [ { "prompt": "", "image": { "bytesBase64Encoded": "B64_BASE_IMAGE" }, "mask": { "image": { "bytesBase64Encoded": "B64_MASK_IMAGE" } } } ], "parameters": { "sampleCount": EDIT_IMAGE_COUNT, "editConfig": { "editMode": "inpainting-remove" } } }如需发送请求,请选择以下方式之一:
以下示例响应适用于包含curl
将请求正文保存在名为
request.json的文件中,然后执行以下命令:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict"PowerShell
将请求正文保存在名为
request.json的文件中,然后执行以下命令:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict" | Select-Object -Expand Content"sampleCount": 2的请求。响应返回两个预测对象,其中生成的图片字节采用 base64 编码。{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
Java
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Java 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Java API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
在此示例中,您将此模型指定为
EndpointName的一部分。EndpointName会传递给对PredictionServiceClient调用的predict方法。该服务会返回图片的修改版本,然后将其保存在本地。如需详细了解模型版本及功能,请参阅 Imagen 模型。
Node.js
在尝试此示例之前,请按照《Vertex AI 快速入门:使用客户端库》中的 Node.js 设置说明执行操作。 如需了解详情,请参阅 Vertex AI Node.js API 参考文档。
如需向 Vertex AI 进行身份验证,请设置应用默认凭证。 如需了解详情,请参阅为本地开发环境设置身份验证。
在此示例中,您将对PredictionServiceClient调用predict方法。该服务会生成图片,然后将其保存在本地。如需详细了解模型版本及功能,请参阅 Imagen 模型。使用自动蒙版检测进行移除
使用以下示例可指定通过修复移除内容。在这些示例中,您需要指定基础图片和文本提示。Imagen 会自动检测并创建蒙版区域来修改基础图片。
Imagen 3
使用以下示例通过 Imagen 3 模型发送修复请求。
控制台
-
在 Google Cloud 控制台中,依次前往 Vertex AI > Media Studio 页面。
- 点击上传。在显示的文件对话框中,选择要上传的文件。
- 点击修复。
- 在参数面板中,选择修复(移除)
- 在修改工具栏中,点击 background_replace 提取。
-
选择其中一个蒙版提取选项:
- 背景元素:检测背景元素并创建一个围绕它们的蒙版。
- 前景元素:检测前景对象并创建一个围绕它们的蒙版。
- background_replace 人员:检测人员并创建一个围绕他们的蒙版。
-
可选:在参数面板中,调整以下选项:
- 模型:要使用的 Imagen 模型
- 结果数量:要生成的结果数量
- 否定提示:要避免生成的内容
- 在提示字段中,输入新提示以修改图片。
- 点击发送生成。
Python
安装
pip install --upgrade google-genai
如需了解详情,请参阅 SDK 参考文档。
设置环境变量以将 Gen AI SDK 与 Vertex AI 搭配使用:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=us-central1 export GOOGLE_GENAI_USE_VERTEXAI=True
REST
如需了解详情,请参阅修改图片 API 参考文档。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目 ID。
- LOCATION:您的项目的区域。 例如
us-central1、europe-west2或asia-northeast3。如需查看可用区域的列表,请参阅 Vertex AI 上的生成式 AI 位置。 prompt:为获得最佳结果,在使用修复来移除时,请省略提示和negativePrompt。- B64_BASE_IMAGE:要修改或放大的基础图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- MASK_MODE - 用于设置模型使用的自动蒙版创建类型的字符串。可用的值:
MASK_MODE_BACKGROUND:使用背景分割自动生成蒙版。使用此设置来修改背景内容。MASK_MODE_FOREGROUND:使用前景分割自动生成蒙版。使用此设置来修改前景内容,例如移除这些前景对象(使用修复进行移除)。MASK_MODE_SEMANTIC:根据您在maskImageConfig.maskClasses数组中指定的分割类,使用语义分割自动生成蒙版。例如:"maskImageConfig": { "maskMode": "MASK_MODE_SEMANTIC", "maskClasses": [175, 176], // bicycle, car "dilation": 0.01 }
- MASK_DILATION - 浮点数。将此蒙版扩大的图像宽度的百分比。建议使用值
0.01来弥补不完美的输入蒙版。 - EDIT_STEPS - 整数。基本模型的采样步数。对于修复移除,请从
12步数开始。如果质量不符合您的要求,请将步数增加到75的上限。增加步数也会增加请求延迟时间。 - EDIT_IMAGE_COUNT - 已修改图片的数量。接受的整数值:1-4。默认值:4。
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict
请求 JSON 正文:
{ "instances": [ { "prompt": "", "referenceImages": [ { "referenceType": "REFERENCE_TYPE_RAW", "referenceId": 1, "referenceImage": { "bytesBase64Encoded": "B64_BASE_IMAGE" } }, { "referenceType": "REFERENCE_TYPE_MASK", "referenceId": 2, "maskImageConfig": { "maskMode": "MASK_MODE", "dilation": MASK_DILATION } } ] } ], "parameters": { "editConfig": { "baseSteps": EDIT_STEPS }, "editMode": "EDIT_MODE_INPAINT_REMOVAL", "sampleCount": EDIT_IMAGE_COUNT } }如需发送请求,请选择以下方式之一:
以下示例响应适用于包含curl
将请求正文保存在名为
request.json的文件中,然后执行以下命令:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict"PowerShell
将请求正文保存在名为
request.json的文件中,然后执行以下命令:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagen-3.0-capability-001:predict" | Select-Object -Expand Content"sampleCount": 2的请求。响应返回两个预测对象,其中生成的图片字节采用 base64 编码。{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }Imagen 2
使用以下示例通过 Imagen 2 模型发送修复请求。
控制台
-
在 Google Cloud 控制台中,依次前往 Vertex AI > Media Studio 页面。
-
在下层任务面板中,点击 修改图片。
-
点击上传以选择要修改的本地存储的产品图片。
-
在修改工具栏中,点击 background_replace提取。
-
选择其中一个蒙版提取选项:
- 背景元素 - 检测背景元素并创建一个围绕它们的蒙版。
- 前景元素 - 检测前景对象并创建一个围绕它们的蒙版。
- background_replace人员 - 检测人员并创建一个围绕他们的蒙版。
-
可选。在参数面板中,调整结果数量、否定提示、文本提示指导或其他参数。
-
将提示字段留空。
-
点击 生成。
REST
在使用任何请求数据之前,请先进行以下替换:
- PROJECT_ID:您的 Google Cloud 项目 ID。
- LOCATION:您的项目的区域。 例如
us-central1、europe-west2或asia-northeast3。如需查看可用区域的列表,请参阅 Vertex AI 上的生成式 AI 位置。 - B64_BASE_IMAGE:要修改或放大的基础图片。图片必须指定为 base64 编码的字节字符串。大小上限:10 MB。
- EDIT_IMAGE_COUNT:已修改图片的数量。 默认值:4。
- MASK_TYPE:提示模型生成蒙版,而无需您提供蒙版。因此,当您提供此参数时,应省略
mask对象。可用的值:background:自动为图片中除主要对象、人物或主体外的所有区域生成蒙版。foreground:自动为图片中的主要对象、人物或主题生成蒙版。semantic:使用自动细分功能为一个或多个细分类别创建蒙版区域。使用classes参数和相应的class_id值设置细分类别。您最多可以指定 5 个类别。使用语义蒙版类型时,maskMode对象应如下所示:"maskMode": { "maskType": "semantic", "classes": [class_id1, class_id2] }
HTTP 方法和网址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict
请求 JSON 正文:
{ "instances": [ { "prompt": "", "image": { "bytesBase64Encoded": "B64_BASE_IMAGE" } } ], "parameters": { "sampleCount": EDIT_IMAGE_COUNT, "editConfig": { "editMode": "inpainting-remove", "maskMode": { "maskType": "MASK_TYPE" } } } }如需发送请求,请选择以下方式之一:
以下示例响应适用于包含curl
将请求正文保存在名为
request.json的文件中,然后执行以下命令:curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict"PowerShell
将请求正文保存在名为
request.json的文件中,然后执行以下命令:$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagegeneration@006:predict" | Select-Object -Expand Content"sampleCount": 2的请求。响应返回两个预测对象,其中生成的图片字节采用 base64 编码。{ "predictions": [ { "bytesBase64Encoded": "BASE64_IMG_BYTES", "mimeType": "image/png" }, { "mimeType": "image/png", "bytesBase64Encoded": "BASE64_IMG_BYTES" } ] }Python
如需了解如何安装或更新 Vertex AI SDK for Python,请参阅安装 Vertex AI SDK for Python。 如需了解详情,请参阅 Python API 参考文档。
限制
以下部分将介绍 Imagen 的对象移除功能的一些局限性。
修改后的像素
模型生成的蒙版外区域的像素无法保证与输入完全相同,并且这些区域是采用模型的分辨率(例如 1024x1024)生成的。生成的图片中可能存在非常细微的变化。
如果您希望完美保留图片,建议您使用蒙版将生成的图片与输入图片相融合。通常,如果输入图片的分辨率为 2K 或更高,则需要将生成的图片与输入图片相融合。
移除限制
蒙版附近的一些小对象也可能会移除。根据最佳实践,我们建议您尽可能精确地设置蒙版。
移除室外图像天空区域中的大片区域可能会导致出现不必要的伪影。根据最佳实践,我们建议您提供提示。
后续步骤
阅读有关 Imagen 和其他 Vertex AI 上的生成式 AI 产品的文章:
- Imagen 3 on Vertex AI 开发者入门指南
- 与创作者一起为创作者打造的全新生成式媒体模型和工具
- Gemini 中的新功能:自定义 Gem 以及通过 Imagen 3 改进的图片生成
- Google DeepMind:Imagen 3 - 我们质量最高的文本转图片模型
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2025-10-04。
-