Os modelos de embeddings da Vertex AI podem gerar embeddings otimizados para vários tipos de tarefas, como recuperação de documentos, perguntas e respostas e verificação de fatos. Os tipos de tarefa são rótulos que otimizam os embeddings que o modelo é gerado com base no caso de uso pretendido. Este documento descreve como escolher o tipo de tarefa ideal para suas embeddings.
Modelos compatíveis
Os tipos de tarefa são compatíveis com os seguintes modelos:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Benefícios dos tipos de tarefa
Os tipos de tarefa podem melhorar a qualidade dos embeddings gerados por um modelo de embeddings.
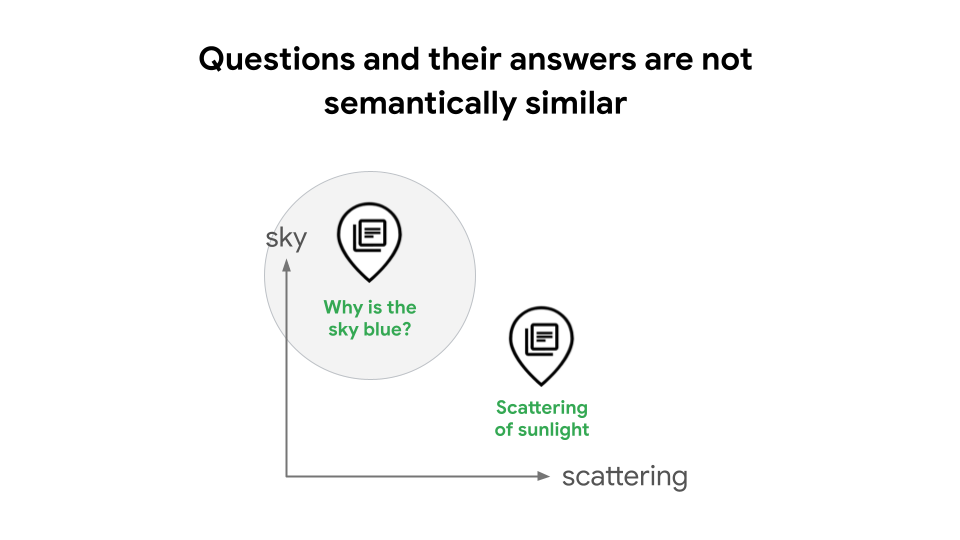
Por exemplo, ao criar sistemas de geração aumentada de recuperação (RAG), uma um design comum é usar embeddings de texto e Pesquisa Vetorial para realizar uma pesquisa de similaridade. Em alguns casos, isso pode prejudicar a pesquisa qualidade, porque as perguntas e suas respostas não são semanticamente parecidas. Por exemplo, uma pergunta como "Por que o céu é azul?" e a resposta "A dispersão da luz solar causa a cor azul" têm significados distintos como frases, o que significa que um sistema RAG não reconhece automaticamente a relação delas, conforme demonstrado na Figura 1. Sem os tipos de tarefas, um desenvolvedor RAG precisa treinam o modelo para aprender a relação entre consultas e respostas. o que requer habilidades e experiência avançadas em ciência de dados, ou use a expansão de consulta baseada em LLM ou HyDE, que pode introduzir alta latência e custos.
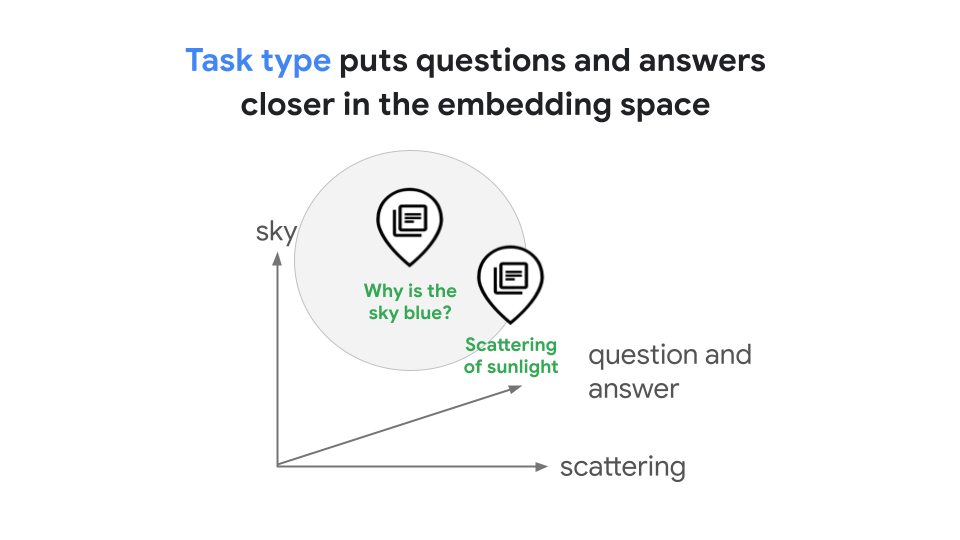
Os tipos de tarefa permitem gerar embeddings otimizados para tarefas específicas, o que economiza o tempo e o custo que seria necessário para desenvolver seu próprio embeddings específicos de tarefas. O embedding gerado para a consulta "Por que o céu é azul?" e sua resposta: "A dispersão da luz solar faz com que a cor azul" estar no espaço de embedding compartilhado que representa a relação entre eles, como mostrado na figura 2. Neste exemplo de RAG, os embeddings otimizados levariam a pesquisas de similaridade aprimoradas.
Além do caso de uso de consulta e resposta, os tipos de tarefa também oferecem espaço de embeddings otimizado para tarefas como classificação, agrupamento e verificação de fatos.
Tipos de tarefas com suporte
Os modelos de embedding que usam tipos de tarefas são compatíveis com os seguintes tipos de tarefas:
| Tipo de tarefa | Descrição |
|---|---|
CLASSIFICATION |
Usado para gerar embeddings otimizados para classificar textos de acordo com rótulos predefinidos |
CLUSTERING |
Usado para gerar embeddings otimizados para agrupar textos com base nas semelhanças deles |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING, e FACT_VERIFICATION |
Usado para gerar embeddings otimizados para pesquisa de documentos ou recuperação de informações |
CODE_RETRIEVAL_QUERY |
Usado para recuperar um bloco de código com base em uma consulta de linguagem natural, como classificar uma matriz ou inverter uma lista vinculada. Os embeddings dos blocos de código são calculados usando RETRIEVAL_DOCUMENT. |
SEMANTIC_SIMILARITY |
Usado para gerar embeddings otimizados para avaliar a similaridade de texto. Não é destinado a casos de uso de recuperação. |
O melhor tipo de tarefa para o job de embeddings depende do caso de uso para seus embeddings. Antes de selecionar um tipo de tarefa, determine que os embeddings usam caso.
Determinar seu caso de uso de embeddings
Os casos de uso de embeddings geralmente se enquadram em uma das quatro categorias: avaliar
similaridade de texto, classificação de textos, agrupamento de textos ou recuperação de informações
com base em textos. Caso seu caso de uso não se enquadre em uma das categorias anteriores,
use o tipo de tarefa RETRIEVAL_QUERY por padrão.
Há dois tipos de formatação de instruções de tarefa: assimétrica e simétrica. É necessário usar o correto com base no seu caso de uso.
| Casos de uso de recuperação (formato assimétrico) |
Tipo de tarefa de consulta | Tipo de tarefa de documento |
|---|---|---|
| Consulta de pesquisa | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Respostas a perguntas | QUESTION_ANSWERING | |
| Checagem de fatos | FACT_VERIFICATION | |
| Recuperação de código | CODE_RETRIEVAL_QUERY |
| Casos de uso de entrada única (formato simétrico) |
Tipo de tarefa de entrada |
|---|---|
| Classificação | CLASSIFICAÇÃO |
| Clustering | CLUSTERING |
| Similaridade semântica (não use para casos de uso de recuperação; destinado à STS) |
SEMANTIC_SIMILARITY |
Classificar textos
Se você quiser usar embeddings para classificar textos de acordo com rótulos predefinidos, use
o tipo de tarefa CLASSIFICATION. Esse tipo de tarefa gera embeddings em um
espaço de embeddings otimizado para classificação.
Por exemplo, suponha que você queira gerar incorporações para postagens em mídias sociais que possam ser usadas para classificar o sentimento como positivo, negativo ou neutro. Ao incorporar embeddings para uma postagem de mídia social que diz "Não gosto viajando de avião" forem classificados, o sentimento será classificado como negativa.
Textos de cluster
Se quiser usar embeddings para agrupar textos com base nas semelhanças deles, use
o tipo de tarefa CLUSTERING. Esse tipo de tarefa gera embeddings
otimizados para serem agrupados com base nas semelhanças deles.
Por exemplo, suponha que você queira gerar embeddings para artigos de notícias de modo que você pode mostrar aos usuários artigos sobre os artigos lidos anteriormente. Depois que as embeddings forem geradas e agrupadas, você poderá sugerir outros artigos relacionados a esportes para usuários que leem muito sobre o assunto.
Outros casos de uso para agrupamento incluem:
- Segmentação de clientes: agrupe clientes com incorporações semelhantes geradas a partir dos perfis ou atividades deles para marketing direcionado e experiências personalizadas.
- Segmentação de produtos: agrupar embeddings de produtos com base no produto. título e descrição, imagens do produto ou avaliações de clientes podem ajudar as empresas fazer análises de segmento dos produtos.
- Pesquisa de mercado: agrupar respostas de pesquisas com consumidores ou incorporações de dados de mídias sociais pode revelar padrões e tendências ocultos nas opiniões, preferências e comportamentos dos consumidores, auxiliando as pesquisas de mercado e informando estratégias de desenvolvimento de produtos.
- Cuidados de saúde: agrupar embeddings de pacientes derivados de dados médicos pode ajudar a identificar grupos com condições ou respostas ao tratamento semelhantes, levando a planos de saúde mais personalizados e terapias direcionadas.
- Tendências de feedback do cliente: agrupar o feedback do cliente de vários canais (pesquisas, mídias sociais, tickets de suporte) em grupos pode ajudar a identificar problemas comuns, solicitações de recursos e áreas para melhoria do produto.
Recuperar informações de textos
Ao criar um sistema de pesquisa ou recuperação, você trabalha com dois tipos de texto:
- Corpus: a coleção de documentos que você quer pesquisar.
- Consulta: o texto que um usuário fornece para pesquisar informações no corpus.
Para ter o melhor desempenho, use diferentes tipos de tarefas para gerar embeddings para seu corpus e suas consultas.
Primeiro, gere embeddings para toda a sua coleção de documentos. É o conteúdo que será recuperado pelas consultas dos usuários. Ao incorporar esses documentos, use o tipo de tarefa RETRIEVAL_DOCUMENT. Normalmente, você realiza essa etapa uma vez para indexar todo o corpus e armazena os embeddings resultantes em um banco de dados de vetores.
Em seguida, quando um usuário envia uma pesquisa, você gera um embedding para o texto da consulta em tempo real. Para isso, use um tipo de tarefa que corresponda à intenção do usuário. Em seguida, o sistema usa esse embedding de consulta para encontrar os embeddings de documentos mais semelhantes no banco de dados de vetores.
Os seguintes tipos de tarefas são usados para consultas:
RETRIEVAL_QUERY: use isso para uma consulta de pesquisa padrão em que você quer encontrar documentos relevantes. O modelo procura embeddings de documentos que sejam semanticamente próximos ao embedding da consulta.QUESTION_ANSWERING: use quando todas as consultas forem perguntas adequadas, como "Por que o céu é azul?" ou "Como faço para amarrar cadarços?".FACT_VERIFICATION: use quando quiser recuperar um documento do seu corpus que prove ou rejeite uma declaração. Por exemplo, a consulta "maçãs crescem debaixo do solo" pode recuperar um artigo sobre maçãs que acabaria refutando a declaração.
Considere o seguinte cenário real em que as consultas de recuperação seriam úteis:
- Para uma plataforma de e-commerce, você quer usar embeddings para permitir que os usuários pesquisar produtos usando consultas de texto e imagens, oferecendo uma experiência de compra intuitiva e envolvente.
- Para uma plataforma educacional, você quer criar um sistema de respostas a perguntas que podem responder perguntas baseadas no conteúdo recursos, oferecendo experiências de aprendizagem personalizadas e ajudando os estudantes compreender conceitos complexos.
Recuperação de código
O text-embedding-005 oferece suporte a um novo tipo de tarefa CODE_RETRIEVAL_QUERY,
que pode ser usado para recuperar blocos de código relevantes usando consultas de texto simples. Para
usar esse recurso, os blocos de código precisam ser incorporados com o
tipo de tarefa RETRIEVAL_DOCUMENT, enquanto as consultas de texto são incorporadas com
CODE_RETRIEVAL_QUERY.
Para conferir todos os tipos de tarefas, consulte a referência do modelo.
Veja um exemplo:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
Para saber como instalar o SDK da Vertex AI para Python, consulte Instalar o SDK da Vertex AI para Python. Para mais informações, consulte a documentação de referência da API Python.
Avaliar a semelhança de textos
Se você quiser usar embeddings para avaliar a semelhança de texto, use o
tipo de tarefa SEMANTIC_SIMILARITY. Esse tipo de tarefa gera embeddings
otimizado para gerar pontuações de similaridade.
Por exemplo, suponha que você queira gerar embeddings para comparar o semelhança dos seguintes textos:
- O gato está dormindo
- O felino está dormindo
Quando os embeddings são usados para criar uma pontuação de similaridade, ela é alta, porque os dois textos têm quase o mesmo significado.
Considere os seguintes cenários reais em que avaliar a semelhança de entrada seria útil:
- Para um sistema de recomendação, você quer identificar itens (por exemplo, produtos, artigos e filmes) que são semanticamente semelhantes aos itens preferidos de um usuário, fornecer recomendações personalizadas e aumentar a satisfação do usuário.
As limitações a seguir se aplicam ao uso desses modelos:
- Não use esses modelos de pré-lançamento em sistemas críticos ou de produção.
- Esses modelos estão disponíveis apenas em
us-central1. - As previsões em lote não são compatíveis.
- Não é possível personalizar.
A seguir
- Saiba como usar embeddings de texto.