Vertex AI embeddings models can generate optimized embeddings for various task types, such as document retrieval, question and answering, and fact verification. Task types are labels that optimize the embeddings that the model generates based on your intended use case. This document describes how to choose the optimal task type for your embeddings.
Supported models
Task types are supported by the following models:
text-embedding-005text-multilingual-embedding-002gemini-embedding-001
Benefits of task types
Task types can improve the quality of embeddings generated by an embeddings model.
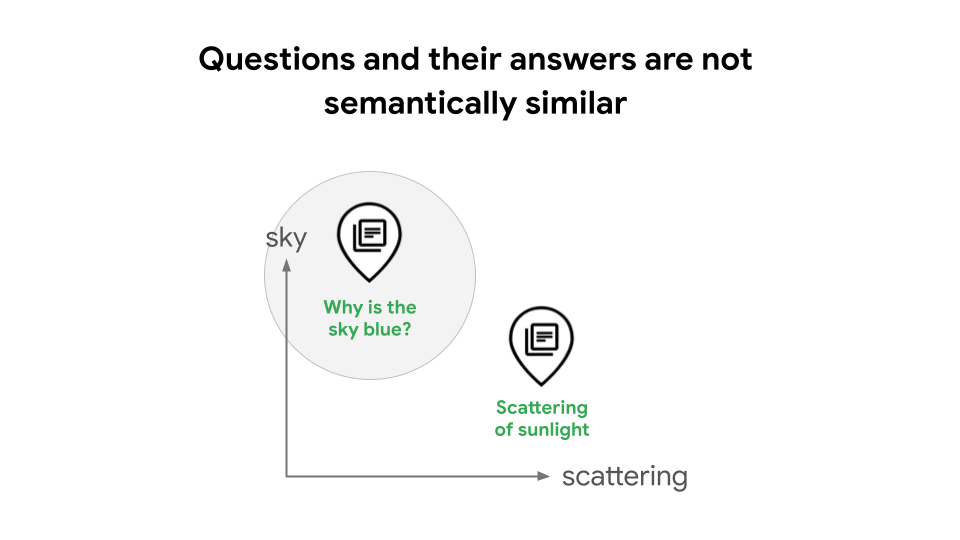
For example, when building Retrieval Augmented Generation (RAG) systems, a common design is to use text embeddings and Vector Search to perform a similarity search. In some cases this can lead to degraded search quality, because questions and their answers are not semantically similar. For example, a question like "Why is the sky blue?" and its answer "The scattering of sunlight causes the blue color," have distinctly different meanings as statements, which means that a RAG system won't automatically recognize their relation, as demonstrated in figure 1. Without task types, a RAG developer would need to train their model to learn the relationship between queries and answers which requires advanced data science skills and experience, or use LLM-based query expansion or HyDE which can introduce high latency and costs.
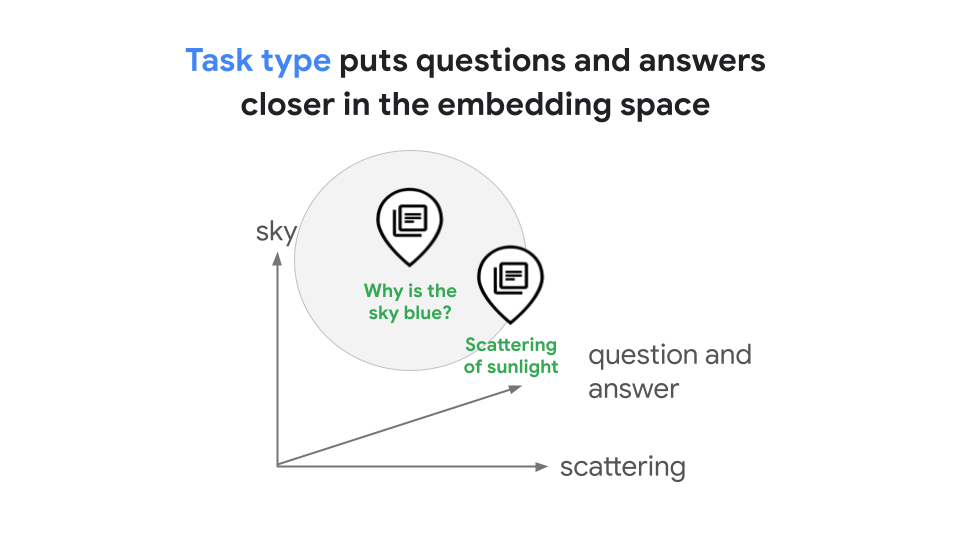
Task types enable you to generate optimized embeddings for specific tasks, which saves you the time and cost it would take to develop your own task-specific embeddings. The generated embedding for a query "Why is the sky blue?" and its answer "The scattering of sunlight causes the blue color" would be in the shared embedding space that represents the relationship between them, as demonstrated in figure 2. In this RAG example, the optimized embeddings would lead to improved similarity searches.
In addition to the query and answer use case, task types also provide optimized embeddings space for tasks such as classification, clustering, and fact verification.
Supported task types
Embeddings models that use task types support the following task types:
| Task type | Description |
|---|---|
CLASSIFICATION |
Used to generate embeddings that are optimized to classify texts according to preset labels |
CLUSTERING |
Used to generate embeddings that are optimized to cluster texts based on their similarities |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING, and FACT_VERIFICATION |
Used to generate embeddings that are optimized for document search or information retrieval |
CODE_RETRIEVAL_QUERY |
Used to retrieve a code block based on a natural language query, such as sort an array or reverse a linked list. Embeddings of the code blocks are computed using RETRIEVAL_DOCUMENT. |
SEMANTIC_SIMILARITY |
Used to generate embeddings that are optimized to assess text similarity. This is not intended for retrieval use cases. |
The best task type for your embeddings job depends on what use case you have for your embeddings. Before you select a task type, determine your embeddings use case.
Determine your embeddings use case
Embeddings use cases typically fall within one of four categories: assessing
text similarity, classifying texts, clustering texts, or retrieving information
from texts. If your use case doesn't fall into one of the preceding categories,
use the RETRIEVAL_QUERY task type by default.
There are 2 types of task instruction formatting, asymmetric format and symmetric format. You'll need to use the correct one based on your use case.
| Retrieval Use cases (Asymmetric Format) |
Query task type | Document task type |
|---|---|---|
| Search Query | RETRIEVAL_QUERY | RETRIEVAL_DOCUMENT |
| Question Answering | QUESTION_ANSWERING | |
| Fact Checking | FACT_VERIFICATION | |
| Code Retrieval | CODE_RETRIEVAL_QUERY |
| Single-input Use Cases (Symmetric Format) |
Input task type |
|---|---|
| Classification | CLASSIFICATION |
| Clustering | CLUSTERING |
| Semantic Similarity (Do not use for retrieval use cases; intended for STS) |
SEMANTIC_SIMILARITY |
Classify texts
If you want to use embeddings to classify texts according to preset labels, use
the CLASSIFICATION task type. This task type generates embeddings in an
embeddings space that is optimized for classification.
For example, suppose you want to generate embeddings for social media posts that you can then use to classify their sentiment as positive, negative, or neutral. When embeddings for a social media post that reads "I don't like traveling on airplanes" are classified, the sentiment would be classified as negative.
Cluster texts
If you want to use embeddings to cluster texts based on their similarities, use
the CLUSTERING task type. This task type generates embeddings that are
optimized for being grouped based on their similarities.
For example, suppose you want to generate embeddings for news articles so that you can show users articles that are topically-related to the ones they have previously read. After the embeddings are generated and clustered, you can suggest additional sports-related articles to users who read a lot about sports.
Additional use cases for clustering include the following:
- Customer segmentation: group customers with similar embeddings generated from their profiles or activities for targeted marketing and personalized experiences.
- Product segmentation: clustering product embeddings based on their product title and description, product images, or customer reviews can help businesses do segment analysis on their products.
- Market research: clustering consumer survey responses or social media data embeddings can reveal hidden patterns and trends in consumer opinions, preferences, and behaviors, aiding market research efforts and informing product development strategies.
- Healthcare: clustering patient embeddings derived from medical data can help identify groups with similar conditions or treatment responses, leading to more personalized healthcare plans and targeted therapies.
- Customer feedback trends: clustering customer feedback from various channels (surveys, social media, support tickets) into groups can help identify common pain points, feature requests, and areas for product improvement.
Retrieve information from texts
When you build a search or retrieval system, you work with two types of text:
- Corpus: The collection of documents that you want to search over.
- Query: The text that a user provides to search for information within the corpus.
To get the best performance, you must use different task types to generate embeddings for your corpus and your queries.
First, generate embeddings for your entire collection of documents. This is the
content that will be retrieved by user queries. When embedding these documents,
use the RETRIEVAL_DOCUMENT task type. You typically perform this step once to
index your entire corpus and then store the resulting embeddings in a vector
database.
Next, when a user submits a search, you generate an embedding for their query text in real time. For this, you should use a task type that matches the user's intent. Your system will then use this query embedding to find the most similar document embeddings in your vector database.
The following task types are used for queries:
RETRIEVAL_QUERY: Use this for a standard search query where you want to find relevant documents. The model looks for document embeddings that are semantically close to the query embedding.QUESTION_ANSWERING: Use this when all queries are expected to be proper questions, such as "Why is the sky blue?" or "How do I tie my shoelaces?".FACT_VERIFICATION: Use this when you want to retrieve a document from your corpus that proves or disproves a statement. For example, the query "apples grow underground" might retrieve an article about apples that would ultimately disprove the statement.
Consider the following real-world scenario where retrieval queries would be useful:
- For an ecommerce platform, you want to use embeddings to enable users to search for products using both text queries and images, providing a more intuitive and engaging shopping experience.
- For an educational platform, you want to build a question-answering system that can answer students' questions based on textbook content or educational resources, providing personalized learning experiences and helping students understand complex concepts.
Code Retrieval
text-embedding-005 supports a new task type CODE_RETRIEVAL_QUERY,
which can be used to retrieve relevant code blocks using plain text queries. To
use this feature, code blocks should be be embedded using the
RETRIEVAL_DOCUMENT task type, while text queries embedded using
CODE_RETRIEVAL_QUERY.
To explore all task types, see the model reference.
Here is an example:
REST
PROJECT_ID=PROJECT_ID
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/text-embedding-005:predict -d \
$'{
"instances": [
{
"task_type": "CODE_RETRIEVAL_QUERY",
"content": "Function to add two numbers"
}
],
}'
Python
To learn how to install or update the Vertex AI SDK for Python, see Install the Vertex AI SDK for Python. For more information, see the Python API reference documentation.
Assess text similarity
If you want to use embeddings to assess text similarity, use the
SEMANTIC_SIMILARITY task type. This task type generates embeddings that are
optimized for generating similarity scores.
For example, suppose you want to generate embeddings to use to compare the similarity of the following texts:
- The cat is sleeping
- The feline is napping
When the embeddings are used to create a similarity score, the similarity score is high, because both texts have nearly the same meaning.
Consider the following real-world scenarios where assessing input similarity would be useful:
- For a recommendation system, you want to identify items (e.g., products, articles, movies) that are semantically similar to a user's preferred items, providing personalized recommendations and enhancing user satisfaction.
The following limitations apply when using these models:
- Don't use these preview models on mission critical or production systems.
- These models are available in
us-central1only. - Batch predictions are not supported.
- Customization is not supported.
What's next
- Learn how to get text embeddings.