Questo tutorial descrive come eseguire la migrazione da Amazon DynamoDB a Spanner. È destinato principalmente ai proprietari di app che vogliono passare da un sistema NoSQL a Spanner, un sistema di database SQL completamente relazionale, tollerante agli errori e altamente scalabile che supporta le transazioni. Se utilizzi in modo coerente le tabelle Amazon DynamoDB, in termini di tipi e layout, la mappatura a Spanner è semplice. Se le tue tabelle Amazon DynamoDB contengono tipi e valori di dati arbitrari, potrebbe essere più semplice passare ad altri servizi NoSQL, come Datastore o Firestore.
Questo tutorial presuppone che tu abbia familiarità con gli schemi di database, i tipi di dati, i fondamenti di NoSQL e i sistemi di database relazionali. Il tutorial si basa sull'esecuzione di attività predefinite per eseguire una migrazione di esempio. Dopo il tutorial, puoi modificare il codice e i passaggi forniti per adattarli al tuo ambiente.
Il seguente diagramma dell'architettura descrive i componenti utilizzati nel tutorial per eseguire la migrazione dei dati:

Obiettivi
- Esegui la migrazione dei dati da Amazon DynamoDB a Spanner.
- Crea un database Spanner e una tabella di migrazione.
- Mappa uno schema NoSQL a uno schema relazionale.
- Crea ed esporta un set di dati di esempio che utilizza Amazon DynamoDB.
- Trasferisci dati tra Amazon S3 e Cloud Storage.
- Utilizza Dataflow per caricare i dati in Spanner.
Costi
Questo tutorial utilizza i seguenti componenti fatturabili di Google Cloud:
Gli addebiti di Spanner si basano sulla quantità di capacità di calcolo nella tua istanza e sulla quantità di dati archiviati durante il ciclo di fatturazione mensile. Durante il tutorial, utilizzi una configurazione minima di queste risorse, che vengono ripulite alla fine. Per scenari reali, stima i requisiti di velocità effettiva e spazio di archiviazione, quindi utilizza la documentazione sulle istanze Spanner per determinare la quantità di capacità di calcolo necessaria.
Oltre alle risorse Google Cloud , questo tutorial utilizza le seguenti risorse Amazon Web Services (AWS):
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Questi servizi sono necessari solo durante la procedura di migrazione. Al termine del tutorial, segui le istruzioni per eliminare tutte le risorse per evitare addebiti non necessari. Utilizza il Calcolatore prezzi di AWS per stimare questi costi.
Per generare una stima dei costi in base all'utilizzo previsto, utilizza il calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Imposta la zona di Compute Engine predefinita. Ad esempio,
us-central1-b. gcloud config set compute/zone us-central1-b - Clona il repository GitHub contenente il codice campione. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- Vai alla directory clonata. cd dynamodb-spanner-migration
- Crea un ambiente virtuale Python. pip3 install virtualenv virtualenv env
- Attiva l'ambiente virtuale: source env/bin/activate
- Installa i moduli Python richiesti. pip3 install -r requirements.txt
- Nella console AWS, vai alla sezione IAM, fai clic su Ruoli e poi seleziona Crea ruolo.
- In Tipo di entità attendibile, assicurati che sia selezionato Servizio AWS.
- In Caso d'uso, seleziona Lambda e poi fai clic su Avanti.
- Nella casella del filtro Policy relative alle autorizzazioni, inserisci
AWSLambdaDynamoDBExecutionRolee premiReturnper eseguire la ricerca. - Seleziona la casella di controllo AWSLambdaDynamoDBExecutionRole e poi fai clic su Avanti.
- Nella casella Nome ruolo, inserisci
dynamodb-spanner-lambda-rolee poi fai clic su Crea ruolo. - Mentre ti trovi ancora nella sezione IAM della console AWS, fai clic su Utenti, quindi seleziona Aggiungi utenti.
- Nella casella Nome utente, inserisci
dynamodb-spanner-migration. Nella sezione Tipo di accesso, seleziona la casella di controllo a sinistra di Chiave di accesso - Accesso programmatico.
Fai clic su Avanti: autorizzazioni.
Fai clic su Allega direttamente le norme esistenti e, utilizzando la casella Cerca per filtrare, seleziona la casella di controllo accanto a ciascuna delle tre norme seguenti:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Fai clic su Avanti: tag e Avanti: esamina, quindi su Crea utente.
Fai clic su Mostra per visualizzare le credenziali. Vengono visualizzati l'ID della chiave di accesso e la chiave di accesso segreta per l'utente appena creato. Per il momento lascia aperta questa finestra perché le credenziali sono necessarie nella sezione seguente. Conserva in modo sicuro queste credenziali perché ti consentono di apportare modifiche al tuo account e influire sul tuo ambiente. Al termine di questo tutorial, puoi eliminare l'utente IAM.
In Cloud Shell, configura l'interfaccia a riga di comando AWS (CLI).
aws configure
Viene visualizzato il seguente output:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Inserisci
ACCESS KEY IDeSECRET ACCESS KEYdall'account AWS IAM che hai creato. - Nel campo Nome regione predefinito, inserisci
us-west-2. Lascia invariati i valori predefiniti degli altri campi.
- Inserisci
Chiudi la finestra della console AWS IAM.
In Cloud Shell, crea una tabella Amazon DynamoDB che utilizza gli attributi della tabella di esempio.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Verifica che lo stato della tabella sia
ACTIVE.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Compila la tabella con dati di esempio.
python3 make-fake-data.py --table Migration --items 25000
Crea un'istanza Spanner nella stessa regione in cui hai impostato la zona Compute Engine predefinita. Ad esempio,
us-central1.gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Crea un database nell'istanza Spanner insieme alla tabella di esempio.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"In Cloud Shell, attiva gli stream Amazon DynamoDB nella tabella di origine.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESConfigura un argomento Pub/Sub per ricevere le modifiche.
gcloud pubsub topics create spanner-migration
Viene visualizzato il seguente output:
Created topic [projects/your-project/topics/spanner-migration].
Crea un account di servizio IAM per eseguire il push degli aggiornamenti delle tabelle nell'argomento Pub/Sub.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"Viene visualizzato il seguente output:
Created service account [spanner-migration].
Crea un binding dei criteri IAM in modo che il account di servizio disponga dell'autorizzazione per pubblicare su Pub/Sub. Sostituisci
GOOGLE_CLOUD_PROJECTcon il nome del tuo progetto Google Cloud .gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comViene visualizzato il seguente output:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Crea le credenziali per il account di servizio.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comViene visualizzato il seguente output:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Prepara e pacchettizza la funzione AWS Lambda per eseguire il push delle modifiche alla tabella Amazon DynamoDB nell'argomento Pub/Sub.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
Crea una variabile per acquisire l'Amazon Resource Name (ARN) del ruolo di esecuzione Lambda creato in precedenza.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Utilizza il pacchetto
pubsub-lambda.zipper creare la funzione AWS Lambda.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"Viene visualizzato il seguente output:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Crea una variabile per acquisire l'ARN dello stream Amazon DynamoDB per la tua tabella.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Collega la funzione Lambda alla tabella Amazon DynamoDB.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONPer ottimizzare la reattività durante il test, aggiungi
--batch-size 1alla fine del comando precedente, che attiva la funzione ogni volta che crei, aggiorni o elimini un elemento.Vedrai un output simile al seguente:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...In Cloud Shell, crea una variabile per un nome di bucket che utilizzi in diverse sezioni seguenti.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportCrea un bucket Amazon S3 per ricevere l'esportazione di DynamoDB.
aws s3 mb s3://${BUCKET}Nella console di gestione AWS, vai a DynamoDB e fai clic su Tabelle.
Fai clic sulla tabella
Migration.Nella scheda Esportazioni e stream, fai clic su Esporta in S3.
Se richiesto, abilita
point-in-time-recovery(PITR).Fai clic su Sfoglia S3 per scegliere il bucket S3 creato in precedenza.
Fai clic su Esporta.
Fai clic sull'icona Aggiorna per aggiornare lo stato del job di esportazione. Il completamento dell'esportazione del job richiede diversi minuti.
Al termine del processo, esamina il bucket di output.
aws s3 ls --recursive s3://${BUCKET}Questo passaggio dovrebbe richiedere circa 5 minuti. Al termine, viene visualizzato un output simile al seguente:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
In Cloud Shell, crea un bucket Cloud Storage per ricevere i file esportati da Amazon S3.
gcloud storage buckets create gs://${BUCKET}Sincronizza i file da Amazon S3 in Cloud Storage. Per la maggior parte delle operazioni di copia, il comando
rsyncè efficace. Se i file di esportazione sono di grandi dimensioni (diversi GB o più), utilizza il servizio di trasferimento Cloud Storage per gestire il trasferimento in background.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objectsPer scrivere i dati dai file esportati nella tabella Spanner, esegui un job Dataflow con codice Apache Beam di esempio.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Per monitorare l'avanzamento del job di importazione, nella console Google Cloud , vai a Dataflow.
Mentre il job è in esecuzione, puoi osservare il grafico di esecuzione per esaminare i log. Fai clic sul job con lo Stato In esecuzione.
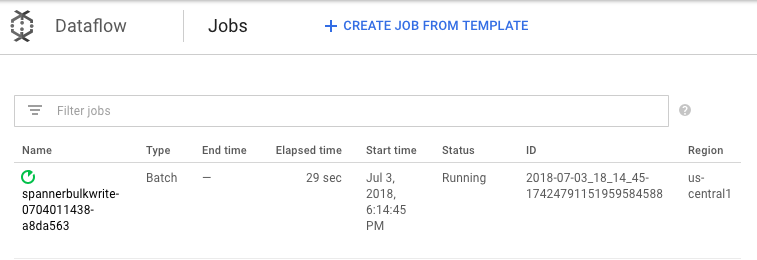
Fai clic su ogni fase per vedere quanti elementi sono stati elaborati. L'importazione è completata quando tutte le fasi riportano lo stato Riuscito. Lo stesso numero di elementi creati nella tabella Amazon DynamoDB viene visualizzato come elaborato in ogni fase.
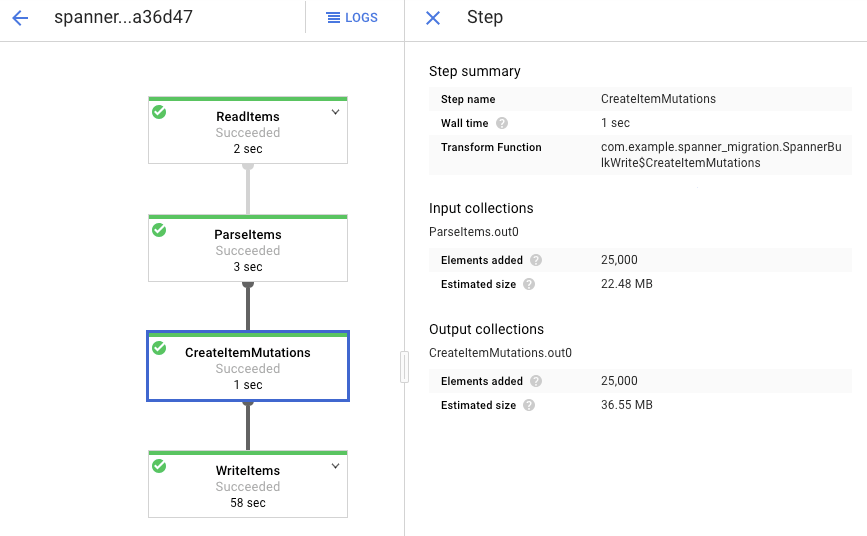
Verifica che il numero di record nella tabella Spanner di destinazione corrisponda al numero di elementi nella tabella Amazon DynamoDB.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
Viene visualizzato il seguente output:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Esegui il campionamento di voci casuali in ogni tabella per assicurarti che i dati siano coerenti.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"Viene visualizzato il seguente output:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Esegui una query sulla tabella Amazon DynamoDB con lo stesso
Usernamerestituito dalla query Spanner nel passaggio precedente. Ad esempio,aallen2538. Il valore è specifico per i dati di esempio nel tuo database.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'I valori degli altri campi devono corrispondere a quelli dell'output di Spanner. Viene visualizzato il seguente output:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }Crea una sottoscrizione all'argomento Pub/Sub a cui AWS Lambda invia gli eventi.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationViene visualizzato il seguente output:
Created subscription [projects/your-project/subscriptions/spanner-migration].
Per trasmettere in streaming le modifiche in arrivo in Pub/Sub per scriverle nella tabella Spanner, esegui il job Dataflow da Cloud Shell.
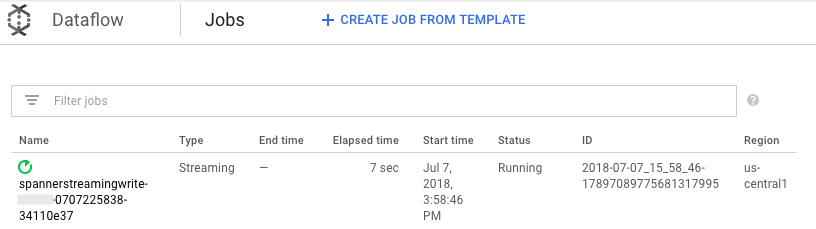
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"Analogamente al passaggio di caricamento batch, per monitorare l'avanzamento del job, nella console Google Cloud , vai a Dataflow.
Fai clic sul job con lo Stato In esecuzione.
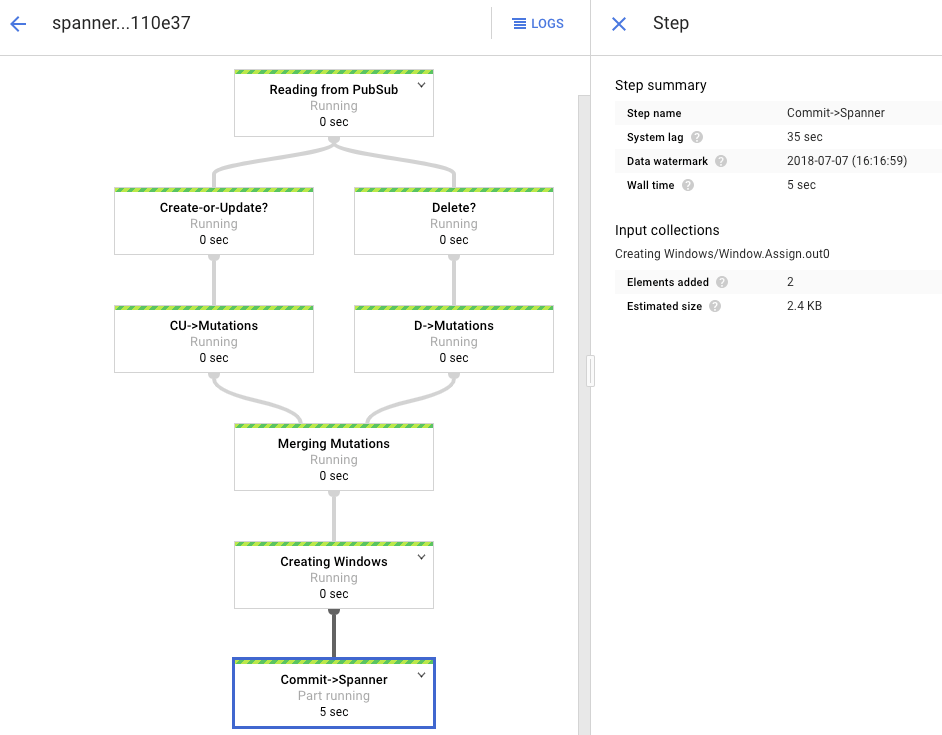
Il grafico di elaborazione mostra un output simile a quello precedente, ma ogni elemento elaborato viene conteggiato nella finestra di stato. Il tempo di ritardo del sistema è una stima approssimativa del ritardo da prevedere prima che le modifiche vengano visualizzate nella tabella Spanner.
Esegui una query su una riga inesistente in Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"L'operazione non restituirà alcun risultato.
Crea un record in Amazon DynamoDB con la stessa chiave che hai utilizzato nella query Spanner. Se il comando viene eseguito correttamente, non viene visualizzato alcun output.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Esegui di nuovo la stessa query per verificare che la riga sia ora in Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"L'output mostra la riga inserita:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Modifica alcuni attributi nell'elemento originale e aggiorna la tabella Amazon DynamoDB.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWVedrai un output simile al seguente:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Verifica che le modifiche vengano propagate alla tabella Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"L'output visualizzato è il seguente:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Elimina l'elemento di test dalla tabella di origine Amazon DynamoDB.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Verifica che la riga corrispondente sia eliminata dalla tabella Spanner. Quando la modifica viene propagata, il seguente comando restituisce zero righe:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Vai a Spanner.
Fai clic su Spanner Studio.
Nel campo Query, inserisci la seguente query e poi fai clic su Esegui query.
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
Dopo l'esecuzione della query, fai clic su Spiegazione e prendi nota di Righe scansionate rispetto a Righe restituite. Senza un indice, Spanner analizza l'intera tabella per restituire un piccolo sottoinsieme di dati che corrispondono alla query.
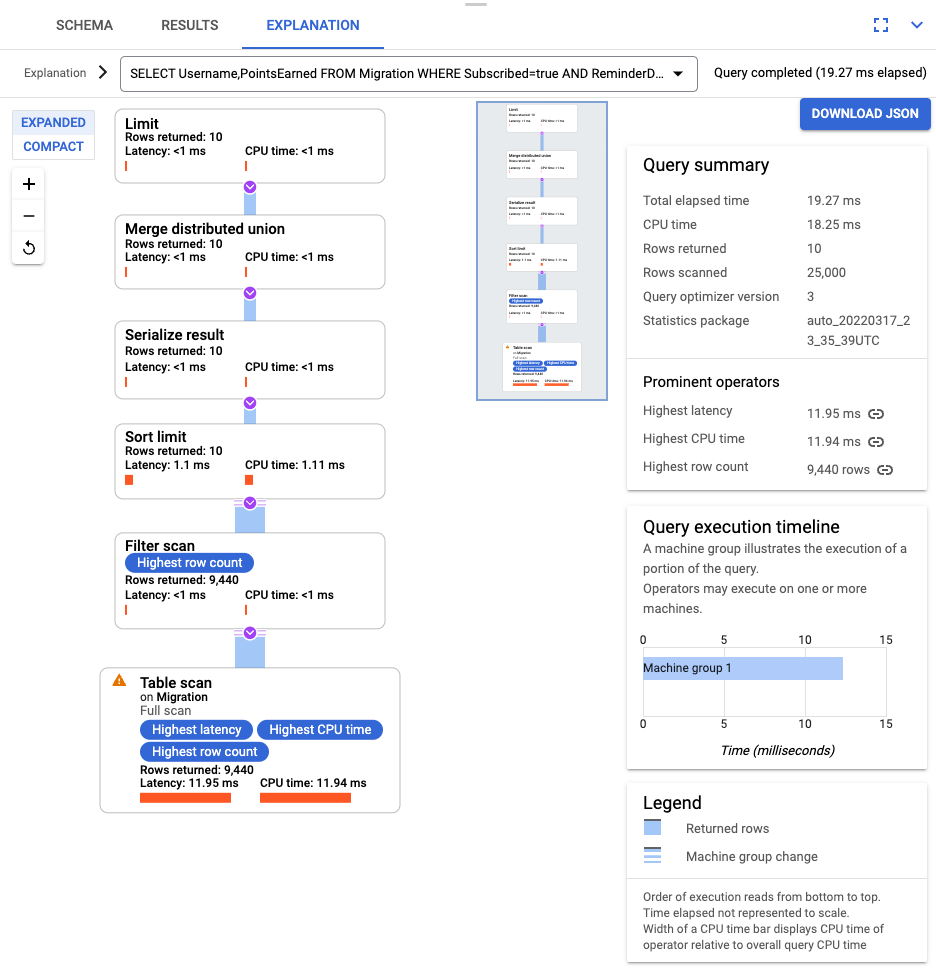
Se questa query si verifica di frequente, crea un indice composito sulle colonne Subscribed e ReminderDate. Nella console Spanner, seleziona Indici nel riquadro di navigazione a sinistra, quindi fai clic su Crea indice.
Nella casella di testo, inserisci la definizione dell'indice.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Per iniziare a creare il database in background, fai clic su Crea.
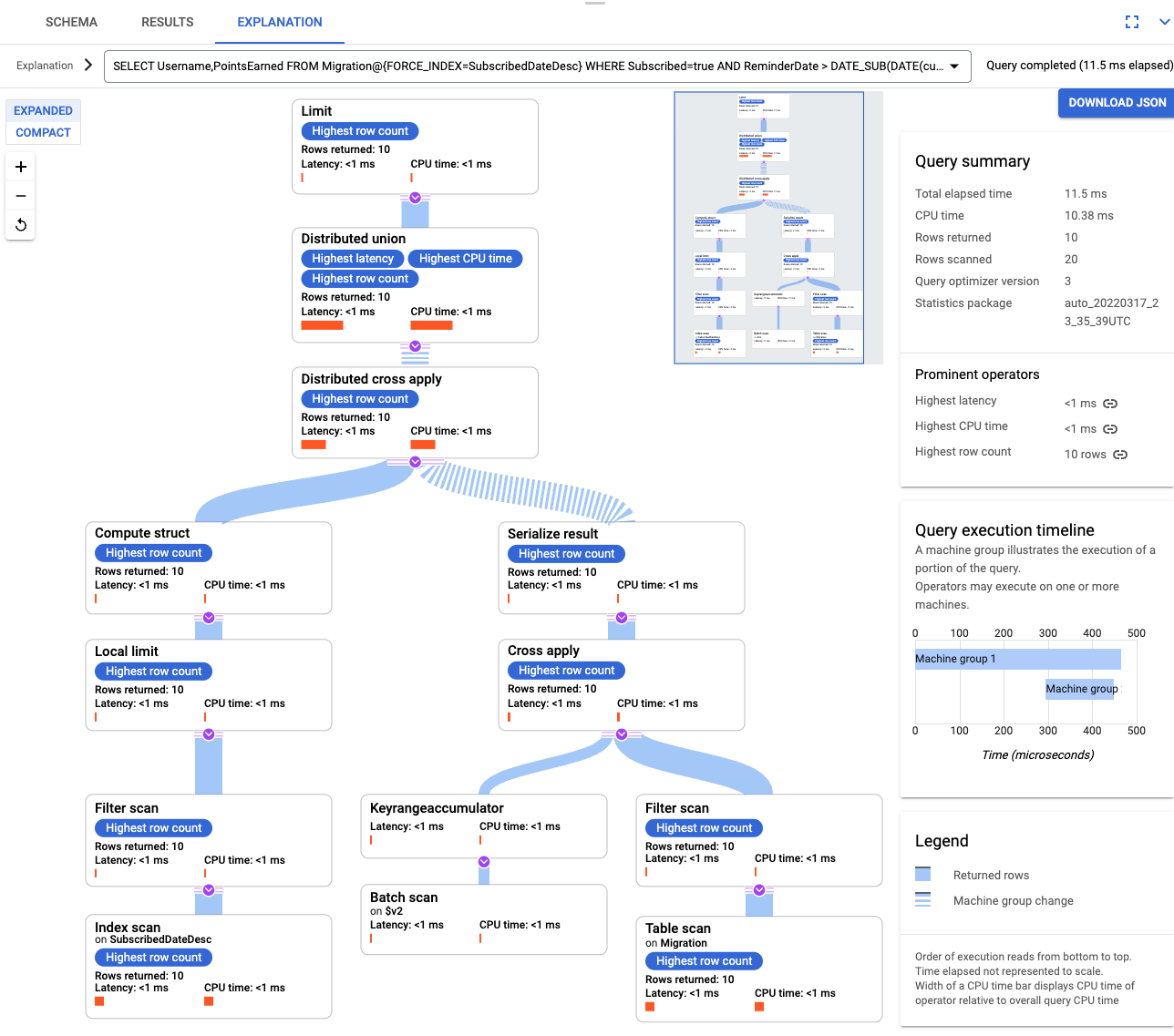
Dopo aver creato l'indice, esegui nuovamente la query e aggiungi l'indice.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Esamina di nuovo la spiegazione della query. Tieni presente che il numero di righe scansionate è diminuito. Il numero di Righe restituite in ogni passaggio corrisponde al numero restituito dalla query.
Per analizzare il JSON in entrata e creare mutazioni, utilizza GSON. Modifica la definizione JSON in modo che corrisponda ai tuoi dati.
Modifica il mapping JSON corrispondente.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Elimina la tabella DynamoDB denominata Migration.
- Elimina il bucket Amazon S3 e la funzione Lambda che hai creato durante i passaggi di migrazione.
- Infine, elimina l'utente AWS IAM che hai creato durante questo tutorial.
- Scopri come ottimizzare lo schema Spanner.
- Scopri come utilizzare Dataflow per situazioni più complesse.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
prepara l'ambiente
In questo tutorial, esegui i comandi in Cloud Shell. Cloud Shell ti consente di accedere alla riga di comando in Google Cloude include Google Cloud CLI e altri strumenti necessari per lo sviluppo di Google Cloud . L'inizializzazione di Cloud Shell può richiedere diversi minuti.
Configurare l'accesso ad AWS
In questo tutorial, crei ed elimini tabelle Amazon DynamoDB, bucket Amazon S3 e altre risorse. Per accedere a queste risorse, devi prima creare le autorizzazioni AWS Identity and Access Management (IAM) richieste. Puoi utilizzare un account AWS di test o sandbox per evitare di influire sulle risorse di produzione nello stesso account.
Crea un ruolo IAM AWS per AWS Lambda
In questa sezione, crei un ruolo AWS IAM che AWS Lambda utilizza in un passaggio successivo del tutorial.
Crea un utente IAM AWS
Segui questi passaggi per creare un utente IAM AWS con accesso programmatico alle risorse AWS, che vengono utilizzate durante il tutorial.
Configurare l'interfaccia a riga di comando AWS
Informazioni sul modello dei dati
La seguente sezione descrive le somiglianze e le differenze tra tipi di dati, chiavi e indici per Amazon DynamoDB e Spanner.
Tipi di dati
Spanner utilizza i tipi di dati GoogleSQL. La seguente tabella descrive come i tipi di dati di Amazon DynamoDB vengono mappati ai tipi di dati di Spanner.
| Amazon DynamoDB | Spanner |
|---|---|
| Numero | A seconda della precisione o dell'utilizzo previsto, potrebbe essere mappato a INT64, FLOAT64, TIMESTAMP o DATE. |
| Stringa | Stringa |
| Booleano | BOOL |
| Null | Nessun tipo esplicito. Le colonne possono contenere valori null. |
| Binario | Byte |
| Set | Array |
| Mappa ed elenco | Struct se la struttura è coerente e può essere descritta utilizzando la sintassi DDL della tabella. |
Chiave primaria
Una chiave primaria Amazon DynamoDB stabilisce l'unicità e può essere una chiave hash o una combinazione di una chiave hash e una chiave di intervallo. Questo tutorial inizia mostrando la migrazione di una tabella Amazon DynamoDB la cui chiave primaria è una chiave hash. Questa chiave hash diventa la chiave primaria della tabella Spanner. In seguito, nella sezione sulle tabelle interleaved, modelli una situazione in cui una tabella Amazon DynamoDB utilizza una chiave primaria composta da una chiave hash e una chiave di intervallo.
Indici secondari
Sia Amazon DynamoDB che Spanner supportano la creazione di un indice su un attributo di chiave non primaria. Prendi nota di tutti gli indici secondari nella tabella Amazon DynamoDB in modo da poterli creare nella tabella Spanner, come descritto in una sezione successiva di questo tutorial.
Tabella di esempio
Per facilitare questo tutorial, esegui la migrazione della seguente tabella di esempio da Amazon DynamoDB a Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Nome tabella |
Migration
|
Migration
|
| Chiave primaria |
"Username" : String
|
"Username" : STRING(1024)
|
| Tipo di chiave | Hash | n/a |
| Altri campi |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Prepara la tabella Amazon DynamoDB
Nella sezione seguente, crea una tabella di origine Amazon DynamoDB e la popola con i dati.
Creazione di un database Spanner
Crea un'istanza Spanner con la capacità di calcolo più piccola possibile: 100 unità di elaborazione. Questa capacità di calcolo è sufficiente per l'ambito di questo tutorial. Per un deployment di produzione, consulta la documentazione relativa alle istanze Spanner per determinare la capacità di calcolo appropriata per soddisfare i requisiti di prestazioni del database.
In questo esempio, crei uno schema della tabella contemporaneamente al database. È anche possibile, e comune, eseguire aggiornamenti dello schema dopo aver creato il database.
Preparare la migrazione
Le sezioni successive mostrano come esportare la tabella di origine Amazon DynamoDB e impostare la replica Pub/Sub per acquisire le modifiche al database che si verificano durante l'esportazione.
Trasmettere in streaming le modifiche a Pub/Sub
Utilizzi una funzione AWS Lambda per trasmettere in streaming le modifiche al database a Pub/Sub.
Esporta la tabella Amazon DynamoDB in Amazon S3
Eseguire la migrazione
Ora che la distribuzione Pub/Sub è attiva, puoi eseguire il push di tutte le modifiche alla tabella apportate dopo l'esportazione.
Copia la tabella esportata in Cloud Storage
Importare i dati in batch
Replica le nuove modifiche
Al termine del job di importazione batch, configura un job di streaming per scrivere gli aggiornamenti continui dalla tabella di origine in Spanner. Ti iscrivi agli eventi di Pub/Sub e li scrivi in Spanner.
La funzione Lambda che hai creato è configurata per acquisire le modifiche alla tabella Amazon DynamoDB di origine e pubblicarle su Pub/Sub.
Il job Dataflow eseguito nella fase di caricamento batch era un insieme finito di input, noto anche come set di dati delimitato. Questo job Dataflow utilizza Pub/Sub come origine di streaming ed è considerato senza limiti. Per saperne di più su questi due tipi di origini, consulta la sezione sulle PCollection nella Guida alla programmazione di Apache Beam. Il job Dataflow in questo passaggio deve rimanere attivo, quindi non termina al termine. Il job Dataflow di streaming rimane nello stato In esecuzione anziché nello stato Riuscito.
Verifica la replica
Apporta alcune modifiche alla tabella di origine per verificare che vengano replicate nella tabella Spanner.
Utilizzare tabelle con interfoliazione
Spanner supporta il concetto di tabelle interleaved. Si tratta di un modello di progettazione in cui un elemento di primo livello ha diversi elementi nidificati correlati a quell'elemento di primo livello, ad esempio un cliente e i suoi ordini o un giocatore e i suoi punteggi di gioco. Se la tabella di origine Amazon DynamoDB utilizza una chiave primaria composta da una chiave hash e una chiave di intervallo, puoi modellare uno schema di tabella interleaved come mostrato nel seguente diagramma. Questa struttura consente di eseguire query in modo efficiente sulla tabella con interleaving unendo i campi nella tabella principale.

Applicare gli indici secondari
È una best practice applicare gli indici secondari alle tabelle Spanner dopo aver caricato i dati. Ora che la replica funziona, configura un indice secondario per velocizzare le query. Come le tabelle Spanner, gli indici secondari Spanner sono completamente coerenti. Non sono coerenti alla fine, come accade in molti database NoSQL. Questa funzionalità può aiutarti a semplificare la progettazione della tua app.
Esegui una query che non utilizza indici. Stai cercando le prime N occorrenze, dato un particolare valore di colonna. Si tratta di una query comune in Amazon DynamoDB per l'efficienza del database.
Indici intercalati
Puoi configurare gli indici con interleaving in Spanner. Gli indici secondari descritti nella sezione precedente si trovano alla radice della gerarchia del database e utilizzano gli indici allo stesso modo di un database convenzionale. Un indice interleaved si trova nel contesto della relativa riga interleaved. Per ulteriori dettagli su dove applicare gli indici intercalati, consulta Opzioni di indice.
Modificare il modello dei dati
Per adattare la parte relativa alla migrazione di questo tutorial alla tua situazione, modifica i file di origine Apache Beam. È importante non modificare lo schema di origine durante la finestra di migrazione effettiva, altrimenti potresti perdere dati.
Nei passaggi precedenti, hai modificato il codice sorgente di Apache Beam per l'importazione collettiva. Modifica il codice sorgente per la parte di streaming della pipeline in modo simile. Infine, modifica gli script di creazione delle tabelle, gli schemi e gli indici del database di destinazione Spanner.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
Elimina risorse AWS
Se il tuo account AWS viene utilizzato al di fuori di questo tutorial, fai attenzione quando elimini le seguenti risorse: