Spanner Data Boost adalah layanan serverless yang terkelola sepenuhnya dan menyediakan resource komputasi independen untuk workload Spanner yang didukung. Data Boost memungkinkan Anda menjalankan kueri analisis dan ekspor data dengan dampak yang hampir tidak ada ke workload yang ada di instance Spanner yang disediakan. Layanan ini terdiri dari cluster Spanner yang dikelola Google di tingkat region. Untuk kueri yang memenuhi syarat yang meminta Data Boost, Spanner merutekan beban kerja ke server ini secara transparan. Kueri yang memenuhi syarat adalah kueri yang operator pertamanya dalam rencana eksekusi kueri adalah union terdistribusi. Kueri ini tidak harus diubah untuk memanfaatkan Data Boost.
Data Boost paling berdampak dalam skenario berikut saat Anda ingin menghindari dampak negatif pada sistem transaksional yang ada karena persaingan resource:
- Kueri ad hoc atau jarang yang melibatkan pemrosesan data dalam jumlah besar. Contoh umum adalah kueri gabungan dari BigQuery ke Spanner.
- Tugas pelaporan atau ekspor data. Contohnya adalah tugas Dataflow untuk mengekspor data Spanner ke Cloud Storage.
Diagram berikut mengilustrasikan cara Data Boost berkoordinasi dengan instance Spanner untuk menyediakan resource komputasi independen.
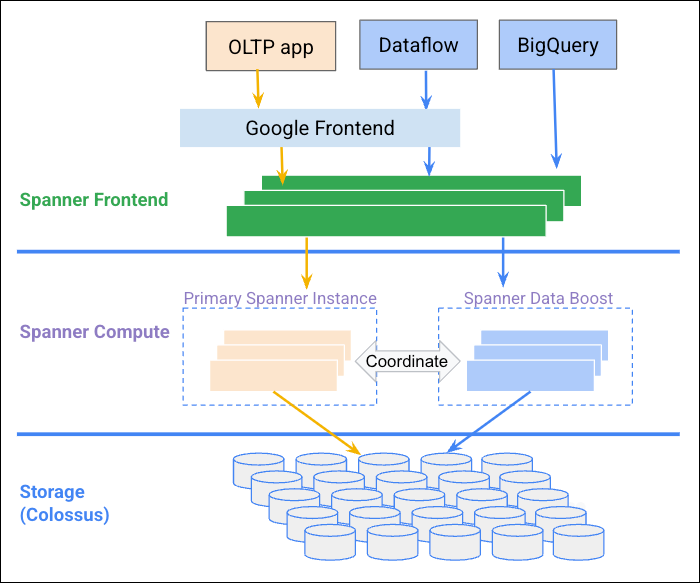
Manfaat
Data Boost menawarkan manfaat berikut:
- Memberikan isolasi beban kerja. Anda dapat menjalankan kueri yang didukung terhadap data terbaru dengan dampak yang hampir nol pada workload transaksional yang ada, terlepas dari kerumitan kueri atau jumlah data yang diproses.
- Memberikan latensi yang sama atau lebih baik.
- Mencegah penyediaan berlebih instance Spanner hanya untuk mendukung kueri analisis sesekali.
- Menawarkan tingkat skalabilitas yang tinggi dengan paralelisme kueri yang lebih besar yang skalabilitasnya fleksibel dengan beban burst.
- Memberikan metrik komprehensif, yang memungkinkan administrator mengidentifikasi kueri yang paling mahal dan menentukan komponen biaya yang akan dioptimalkan. Administrator kemudian dapat memverifikasi dampak pengoptimalan mereka dengan memantau konsumsi unit pemrosesan serverless kueri dalam eksekusi berikutnya.
- Tidak memerlukan overhead operasional tambahan. Tidak ada layanan tambahan yang perlu dikelola, tidak ada perencanaan atau penyediaan kapasitas, tidak perlu menunggu penskalaan, dan tidak ada pemeliharaan.
Izin
Setiap akun utama yang menjalankan kueri atau ekspor yang meminta Data Boost
harus memiliki izin Identity and Access Management (IAM)
spanner.databases.useDataBoost. Sebaiknya gunakan peran IAM Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Penagihan dan kuota
Anda hanya membayar untuk unit pemrosesan sebenarnya yang digunakan oleh kueri yang berjalan di Data Boost. Administrator dapat menetapkan batas penggunaan untuk menghindari kelebihan biaya.
Langkah selanjutnya
- Menjalankan kueri gabungan dengan Data Boost
- Mengekspor data dengan Data Boost
- Menggunakan Data Boost di aplikasi Anda
- Memantau penggunaan Data Boost
- Memantau dan mengelola penggunaan kuota Data Boost