Cet article décrit une solution permettant d'exporter des métriques Cloud Monitoring pour une analyse à long terme. Cloud Monitoring fournit une solution de surveillance pourGoogle Cloud et Amazon Web Services (AWS). Il conserve les métriques pendant six semaines, car leur valeur est souvent limitée dans le temps. Par conséquent, la valeur des métriques historiques diminue avec le temps. Or, au bout de six semaines, il est possible que les métriques cumulées conservent leur intérêt pour une analyse à long terme des tendances.
Ce guide explique les spécificités de stockage des métriques à exporter, ainsi que la mise en œuvre de référence sans serveur pour l'exportation des métriques vers BigQuery.
Les rapports sur l'état du DevOps identifient les capacités qui améliorent les performances de livraison de logiciels. Ce guide vous aidera dans la mise en place des capacités suivantes :
- Surveillance et observabilité
- Systèmes de surveillance permettant d'éclairer les décisions métier
- Capacités de gestion visuelle
Dans quels cas exporter des métriques ?
Cloud Monitoring collecte des métriques et des métadonnées à partir de Google Cloud, AWS et d'outils d'instrumentation des applications. Les métriques Monitoring offrent une visibilité approfondie sur les performances, le temps d'activité et l'état général de vos applications cloud à l'aide d'une API, de tableaux de bord et d'un explorateur de métriques. Ces outils vous permettent de passer en revue les valeurs des métriques des six dernières semaines à des fins d'analyse. Pour effectuer une analyse des métriques à long terme, exportez-les à l'aide de l'API Cloud Monitoring en vue d'un stockage à long terme.
Cloud Monitoring conserve les métriques des six dernières semaines. Il est souvent utilisé à des fins opérationnelles, comme pour la surveillance de l'infrastructure d'une machine virtuelle (processeur, mémoire et métriques réseau) et pour les métriques de performance des applications (latence des requêtes ou des réponses). Lorsque ces métriques dépassent les seuils prédéfinis, un processus opérationnel est déclenché par une alerte.
Les métriques enregistrées peuvent également servir pour une analyse à long terme. Par exemple, vous pouvez comparer les métriques de performance des applications lors du Cyber Monday ou d'autres événements à fort trafic avec les métriques de l'année précédente pour vous aider à planifier le prochain événement de ce type. Un autre scénario consiste à examiner l'utilisation des services sur un trimestre ou une année afin de mieux prévoir les coûts. Google Cloud Vous pouvez également afficher les métriques de performance des applications sur plusieurs mois ou années.
Dans ces exemples, il est nécessaire de conserver les métriques pour l'analyse à long terme. L'exportation de ces métriques vers BigQuery offre les fonctionnalités analytiques adéquates.
Exigences
Pour effectuer une analyse à long terme des données des métriques Monitoring, trois conditions principales doivent être remplies :
- Exporter les données depuis Cloud Monitoring. Vous devez exporter les données des métriques Cloud Monitoring sous la forme d'une valeur de métrique agrégée.
L'agrégation de métriques est nécessaire, car le stockage des points de données bruts
timeseries, bien que techniquement réalisable, n'apporte pas de valeur. La plupart des analyses à long terme sont effectuées au niveau global sur une période plus longue. La précision de l'agrégation est propre à votre cas d'utilisation, mais nous vous recommandons une agrégation d'au moins une heure. - Ingérer les données pour l'analyse. Vous devez importer les métriques Cloud Monitoring exportées dans un moteur d'analyse.
- Écrire des requêtes et créer des tableaux de bord en fonction des données. Vous avez besoin de tableaux de bord et d'un accès SQL standard pour interroger, analyser et visualiser les données.
Étapes fonctionnelles
- Créer une liste de métriques à inclure dans l'exportation
- Lire les métriques via l'API Monitoring
- Mapper les métriques de la sortie JSON exportée à partir de l'API Monitoring vers le format de table BigQuery
- Écrire les métriques dans BigQuery
- Créer un planning de programmation pour exporter régulièrement les métriques
Architecture
La conception de cette architecture tire parti des services gérés pour simplifier vos opérations et vos efforts en matière de gestion, réduire les coûts et s'adapter à vos volumes.
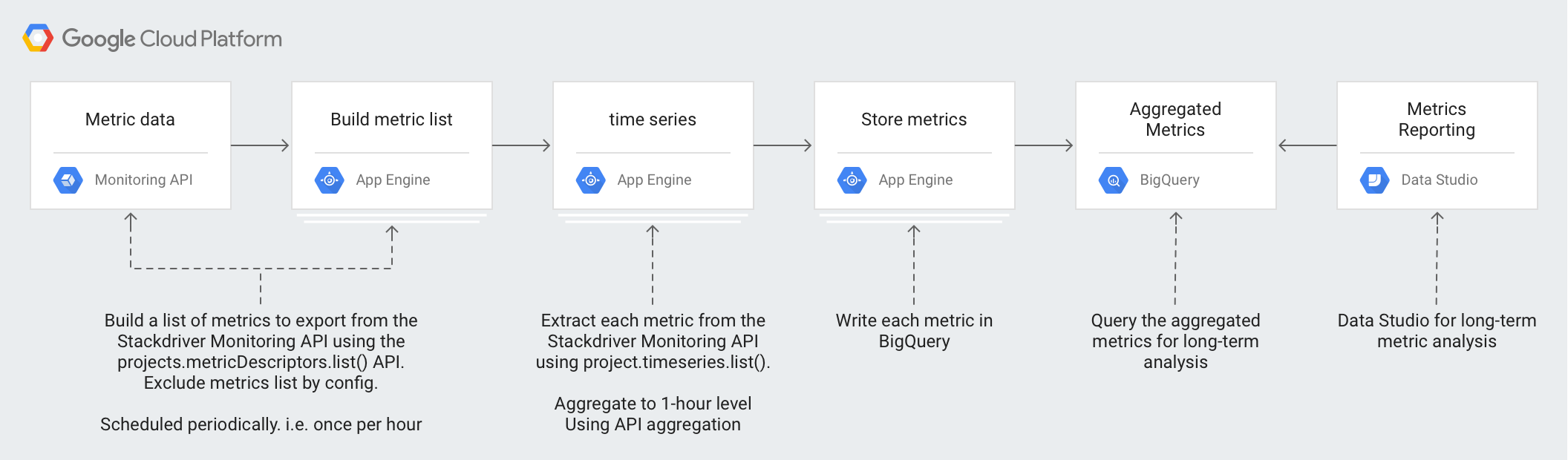
L'architecture utilise les technologies suivantes :
- App Engine : plate-forme en tant que service (PaaS) évolutive permettant d'appeler l'API Monitoring et d'écrire dans BigQuery.
- BigQuery : moteur d'analyse entièrement géré utilisé pour intégrer et analyser les données
timeseries. - Pub/Sub : service de messagerie en temps réel entièrement géré, utilisé pour fournir un traitement évolutif asynchrone.
- Cloud Storage : solution unifiée de stockage d'objets destinée aux développeurs et aux entreprises, permettant de stocker les métadonnées concernant l'état de l'exportation.
- Cloud Scheduler : planificateur de style Cron permettant d'exécuter le processus d'exportation.
Comprendre les détails des métriques Cloud Monitoring
Pour comprendre comment exporter au mieux les métriques depuis Cloud Monitoring, il est important de comprendre comment celui-ci stocke les métriques.
Types de métriques
Vous pouvez exporter quatre types de métriques principaux dans Cloud Monitoring.
- La liste des métriquesGoogle Cloud est constituée de métriques issues des services Google Cloud , tels que Compute Engine et BigQuery.
- La liste de métriques d'agent comprend des métriques issues des instances de VM exécutant les agents Cloud Monitoring.
- Les métriques AWS sont des métriques issues des services AWS, tels qu'Amazon Redshift et Amazon CloudFront.
- Les métriques provenant de sources externes sont des métriques issues d'applications tierces et des métriques définies par l'utilisateur, y compris les métriques personnalisées.
Chacun de ces types de métriques comporte un descripteur de métrique, qui inclut le type de métrique ainsi que d'autres métadonnées. La métrique suivante est un exemple de liste des descripteurs de métriques obtenu à l'aide de la méthode projects.metricDescriptors.list de l'API Monitoring.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
Les valeurs importantes à comprendre à partir du descripteur de métrique sont les champs type, valueType et metricKind. Ces champs identifient la métrique et ont un impact sur l'agrégation possible pour un descripteur de métrique.
Genres de métriques
Chaque métrique présente un genre de métrique et un type de valeur. Pour en savoir plus, consultez la section Genres de métriques et types de valeurs. Le genre de métrique et le type de valeur associé sont des valeurs importantes, car leur combinaison influence le mode d'agrégation des métriques.
Dans l'exemple précédent, le type de métrique pubsub.googleapis.com/subscription/push_request_count metric comporte un genre de métrique DELTA et un type de valeur INT64.

Dans Cloud Monitoring, le genre de métrique et les types de valeur sont stockés dans metricsDescriptors, disponible dans l'API Monitoring.
Séries temporelles (timeseries)
Les valeurs timeseries représentent des mesures régulières pour chaque type de métrique, stockées au fil du temps. Elles contiennent le type de métrique, les métadonnées, les libellés et les points de données mesurés individuellement. Les métriques collectées automatiquement par Monitoring, telles que les métriquesGoogle Cloud et AWS, le sont sur une base régulière. Par exemple, la métrique appengine.googleapis.com/http/server/response_latencies est collectée toutes les 60 secondes.
Un ensemble de points collectés pour une valeur timeseries donnée peut augmenter au fil du temps, en fonction de la fréquence des données transmises et des libellés associés au type de métrique. Si vous exportez les points de données bruts timeseries, cela peut entraîner une exportation importante. Pour réduire le nombre de points de données timeseries renvoyés, vous pouvez regrouper les métriques sur une période d'alignement donnée. Par exemple, en utilisant l'agrégation, vous pouvez renvoyer un point de données par heure pour une métrique timeseries donnée ayant un point de données par minute. Cette opération réduit le nombre de points de données exportés, ainsi que le traitement analytique requis dans le moteur d'analyse. Dans cet article, des valeurs timeseries sont renvoyées pour chaque type de métrique sélectionné.
Agrégation de métriques
Vous pouvez utiliser l'agrégation pour combiner les données de plusieurs valeurs timeseries en une seule valeur timeseries. L'API Monitoring fournit de puissantes fonctions d'alignement et d'agrégation pour vous éviter d'avoir à effectuer l'agrégation vous-même, en transmettant les paramètres d'alignement et d'agrégation à l'appel d'API. Pour en savoir plus sur le fonctionnement de l'agrégation pour l'API Monitoring, consultez la page Filtrage et agrégation, ainsi que cet article de blog.
Mappez metric type sur aggregation type pour vérifier que les métriques sont alignées et que la valeur timeseries est réduite afin de correspondre à vos besoins d'analyse.
Il existe des listes d'aligneurs et de réducteurs que vous pouvez utiliser pour regrouper les valeurs timeseries. Les aligneurs et les réducteurs disposent d'un ensemble de métriques que vous pouvez utiliser pour effectuer des opérations d'alignement ou de réduction en fonction des types de valeurs et des genres de métriques. Par exemple, si l'agrégation porte sur plus d'une heure, le résultat est d'un point renvoyé par heure pour la valeur timeseries.
Vous pouvez également affiner votre agrégation à l'aide de la fonction Group By, qui vous permet de regrouper les valeurs agrégées dans des listes timeseries agrégées. Par exemple, vous pouvez choisir de regrouper les métriques App Engine en fonction du module App Engine. Le regroupement via le module App Engine en combinaison avec les aligneurs et les réducteurs génère un point de données par module App Engine par heure en une heure d'agrégation.
L'agrégation de métriques permet de trouver l'équilibre entre le coût accru de l'enregistrement de points de données individuels et le besoin de conserver suffisamment de données pour une analyse détaillée à long terme.
Détails de la mise en œuvre de référence
La mise en œuvre de référence contient les mêmes composants que ceux décrits dans le diagramme de conception de l'architecture. Des détails fonctionnels et pertinents sont fournis ci-dessous pour chaque étape.
Créer une liste de métriques
Cloud Monitoring définit plus d'un millier de types de métriques pour vous aider à surveiller Google Cloud, AWS et des logiciels tiers. L'API Monitoring fournit la méthode projects.metricDescriptors.list, qui renvoie la liste des métriques disponibles pour un projet Google Cloud. L'API Monitoring inclut un mécanisme de filtrage vous permettant de filtrer une liste de métriques à exporter pour le stockage et l'analyse à long terme.
La mise en œuvre de référence dans GitHub utilise une application Python App Engine pour obtenir une liste de métriques, puis écrit chaque message séparément dans un sujet Pub/Sub. L'exportation est lancée par Cloud Scheduler qui génère une notification Pub/Sub pour exécuter l'application.
Il existe de nombreuses méthodes pour appeler l'API Monitoring. Dans ce cas, les API Cloud Monitoring et Pub/Sub sont appelées à l'aide de la bibliothèque cliente des API Google pour Python en raison de sa flexibilité d'accès aux API Google.
Créer des séries temporelles (timeseries)
Vous devez extraire les valeurs timeseries pour la métrique, puis écrire chaque valeur timeseries dans Pub/Sub. Avec l'API Monitoring, vous pouvez agréger les valeurs de métriques sur une période d'alignement donnée à l'aide de la méthode project.timeseries.list. L'agrégation des données réduit la charge de traitement, les exigences de stockage, le temps d'interrogation et les coûts d'analyse. C'est une pratique recommandée pour mener efficacement une analyse de métriques à long terme.
La mise en œuvre de référence dans GitHub fait appel à une application Python App Engine pour s'abonner au sujet, où chaque métrique à exporter est envoyée dans un message séparé. Pour chaque message reçu, Pub/Sub transmet le message à l'application App Engine. L'application obtient les valeurs timeseries pour une métrique donnée en fonction de la configuration d'entrée. Dans le cas présent, les API Cloud Monitoring et Pub/Sub sont appelées à l'aide de la bibliothèque cliente des API Google.
Chaque métrique peut renvoyer une ou plusieurs valeurs timeseries.. Chaque métrique est envoyée via un message Pub/Sub distinct à insérer dans BigQuery. Le mappage de métriques type-to-aligner et de métriques type-to-reducer est intégré à la mise en œuvre de référence. Le tableau ci-dessous définit le mappage utilisé dans la mise en œuvre de référence en fonction des classes de genres de métriques et de types de valeurs compatibles avec les aligneurs et les réducteurs.
| Type de valeur | GAUGE |
Aligneur | Réducteur | DELTA |
Aligneur | Réducteur | CUMULATIVE2 |
Aligneur | Réducteur |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
oui |
ALIGN_FRACTION_TRUE
|
aucun | non | N/A | N/A | non | N/A | N/A |
INT64 |
oui |
ALIGN_SUM
|
aucun | oui |
ALIGN_SUM
|
aucun | oui | aucun | aucun |
DOUBLE |
oui |
ALIGN_SUM
|
aucun | oui |
ALIGN_SUM
|
aucun | oui | aucun | aucun |
STRING |
oui | exclu | exclu | non | N/A | N/A | non | N/A | N/A |
DISTRIBUTION |
oui |
ALIGN_SUM
|
aucun | oui |
ALIGN_SUM
|
aucun | oui | aucun | aucun |
MONEY |
non | N/A | N/A | non | N/A | N/A | non | N/A | N/A |
Il est important de tenir compte du mappage de valueType sur les aligneurs et les réducteurs, car l'agrégation n'est possible que pour des valeurs valueTypes et metricKinds spécifiques pour chaque aligneur et réducteur.
Par exemple, prenons le type pubsub.googleapis.com/subscription/push_request_count metric. En fonction du genre de métrique DELTA et du type de valeur INT64, vous pouvez agréger la métrique comme suit :
- Période d'alignement : 3 600 s (une heure).
Aligner = ALIGN_SUM: le point de données résultant de la période d'alignement correspond à la somme de tous les points de données de la période d'alignement.Reducer = REDUCE_SUM: réduit le résultat en calculant la somme d'une valeurtimeseriespour chaque période d'alignement.
En plus des valeurs de la période d'alignement, de l'aligneur et du réducteur, la méthode project.timeseries.list nécessite plusieurs autres entrées :
filter: sélectionnez la métrique à renvoyer.startTime: sélectionnez le point de départ auquel renvoyer la valeurtimeseries.endTime: sélectionnez le dernier instant à partir duquel vous souhaitez renvoyer la valeurtimeseries.groupBy: saisissez les champs sur lesquels regrouper la réponsetimeseries.alignmentPeriod: saisissez les périodes pour lesquelles les métriques doivent être alignées.perSeriesAligner: alignez les points sur des intervalles réguliers définis par une valeuralignmentPeriod.crossSeriesReducer: combinez plusieurs points avec des valeurs de libellés différentes jusqu'à un seul point par intervalle de temps.
La requête GET adressée à l'API inclut tous les paramètres décrits dans la liste précédente.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
La commande HTTP GET suivante fournit un exemple d'appel à la méthode d'API projects.timeseries.list en utilisant les paramètres d'entrée :
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
L'appel d'API Monitoring précédent inclut une valeur crossSeriesReducer=REDUCE_SUM, ce qui signifie que les métriques sont réduites et regroupées en une seule somme comme illustré dans l'exemple suivant.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
Ce niveau d'agrégation regroupe les données en un seul point de données, ce qui en fait une métrique idéale pour l'ensemble de votre Google Cloud projet. Toutefois, il ne vous permet pas d'identifier les ressources qui ont contribué à la métrique. Dans l'exemple précédent, vous ne pouvez pas savoir quel abonnement Pub/Sub a le plus contribué au nombre de requêtes.
Si vous souhaitez examiner les détails des composants individuels qui génèrent la valeur timeseries, vous pouvez supprimer le paramètre crossSeriesReducer.
Sans le paramètre crossSeriesReducer, l'API Monitoring ne combine pas les différentes valeurs de timeseries pour créer une seule valeur.
La commande HTTP GET suivante fournit un exemple d'appel à la méthode d'API projects.timeseries.list en utilisant les paramètres d'entrée. La valeur crossSeriesReducer n'est pas incluse.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
Dans la réponse JSON suivante, les valeurs metric.labels.keys sont identiques dans les deux résultats, car la valeur timeseries est regroupée. Des points distincts sont renvoyés pour chacune des valeurs resource.labels.subscription_ids. Examinez les valeurs metric_export_init_pub et metrics_list dans le fichier JSON suivant. Ce niveau d'agrégation est recommandé, car il vous permet d'utiliser des produitsGoogle Cloud , inclus en tant que libellés de ressources, dans vos requêtes BigQuery.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
Chaque métrique de la sortie JSON de l'appel d'API projects.timeseries.list est écrite directement dans Pub/Sub sous la forme d'un message distinct. Il existe une éventuelle distribution ramifiée, où une métrique d'entrée génère une ou plusieurs valeurs timeseries.
Pub/Sub offre la possibilité d'absorber une telle distribution sans dépasser les délais avant expiration.
La période d'alignement fournie en tant qu'entrée signifie que les valeurs sur cette période sont agrégées en une seule valeur, comme indiqué dans l'exemple de réponse précédent. La période d'alignement définit également la fréquence d'exécution de l'exportation. Par exemple, si votre période d'alignement est de 3 600 secondes ou une heure, l'exportation s'exécute toutes les heures pour exporter régulièrement la valeur timeseries.
Stocker les métriques
La mise en œuvre de référence dans GitHub fait appel à une application Python App Engine pour lire chaque valeur timeseries, puis insérer les enregistrements dans la table BigQuery. Pour chaque message reçu, Pub/Sub transmet le message à l'application App Engine. Le message Pub/Sub contient des données de métrique exportées depuis l'API Monitoring au format JSON et doit être mappé sur une structure de table dans BigQuery. Dans le cas présent, les API BigQuery sont appelées à l'aide de la bibliothèque cliente de l'API Google.
Le schéma BigQuery est conçu pour mapper étroitement le code JSON exporté depuis l'API Monitoring. Lors de la création du schéma de la table BigQuery, il convient de prendre en compte la taille des données à mesure de leur croissance.
Dans BigQuery, nous vous recommandons de partitionner la table en fonction d'un champ de date, car les requêtes peuvent être plus efficaces si vous sélectionnez des plages de dates sans effectuer d'analyse complète de la table. Si vous envisagez d'exécuter régulièrement l'exportation, vous pouvez utiliser la partition par défaut en toute sécurité en fonction de la date d'ingestion.
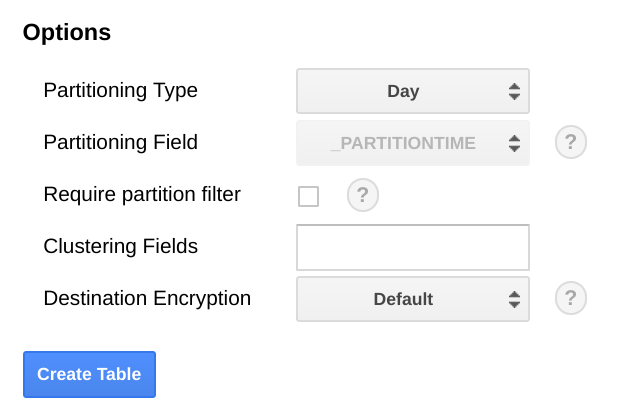
Si vous prévoyez d'importer des métriques de manière groupée ou de ne pas exécuter régulièrement l'exportation, utilisez la partition end_time,, ce qui nécessite des modifications du schéma BigQuery. Vous pouvez soit déplacer la valeur end_time vers un champ de niveau supérieur du schéma, où vous pouvez l'utiliser pour le partitionnement, soit ajouter un nouveau champ au schéma. Le transfert du champ end_time est nécessaire, car le champ est contenu dans un enregistrement BigQuery et le partitionnement doit être effectué dans un champ de niveau supérieur. Pour en savoir plus, consultez la documentation sur le partitionnement BigQuery.
BigQuery offre également la possibilité aux ensembles de données, tables et partitions de table d'expirer après un certain temps.
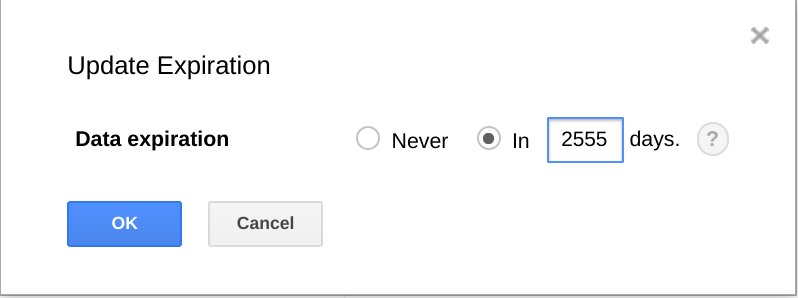
L'utilisation de cette fonctionnalité est un moyen utile de supprimer définitivement des données anciennes lorsque celles-ci ne sont plus utiles. Par exemple, si votre analyse porte sur une période de trois ans, vous pouvez ajouter une règle permettant de supprimer les données datant de plus de trois ans.
Planifier l'exportation
Cloud Scheduler est un planificateur de tâches Cron entièrement géré. Cloud Scheduler vous permet d'utiliser le format de planification Cron standard pour déclencher une application App Engine, envoyer un message à l'aide de Pub/Sub ou envoyer un message à un point de terminaison HTTP arbitraire.
Dans la mise en œuvre de référence de GitHub, Cloud Scheduler déclenche l'application App Engine list-metrics toutes les heures en envoyant un message Pub/Sub avec un jeton correspondant à la configuration d'App Engine. La période d'agrégation par défaut dans la configuration de l'application est de 3 600 secondes, soit une heure, ce qui correspond à la fréquence de déclenchement de l'application. Une agrégation minimale d'une heure est recommandée, car elle permet de générer un volume de données acceptable tout en conservant des données haute fidélité. Si vous utilisez une période d'alignement différente, modifiez la fréquence de l'exportation pour qu'elle corresponde à la période d'alignement. La mise en œuvre de référence stocke la dernière valeur end_time dans Cloud Storage et l'utilise en tant que valeur start_time ultérieure, sauf si une valeur start_time est transmise en tant que paramètre.
La capture d'écran de Cloud Scheduler suivante montre comment configurer Cloud Scheduler à l'aide de la console Google Cloud afin d'appeler l'application App Engine list-metrics toutes les heures.
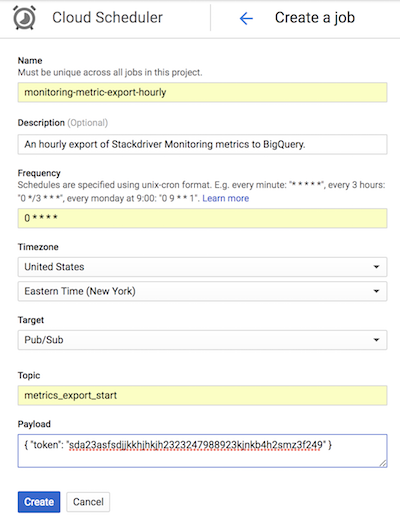
Le champ Frequency (Fréquence) utilise la syntaxe de type Cron pour indiquer à Cloud Scheduler la fréquence d'exécution de l'application. Le champ Target (Cible) spécifie un message Pub/Sub généré et le champ Payload (Charge utile) contient les données contenues dans le message Pub/Sub.
Utiliser les métriques exportées
Avec les données exportées dans BigQuery, vous pouvez désormais utiliser le langage SQL standard pour interroger les données ou créer des tableaux de bord permettant de visualiser les tendances de vos métriques au fil du temps.
Exemple de requête : latences App Engine
La requête suivante recherche la valeur minimale, maximale et moyenne parmi les valeurs des métriques de latence moyenne pour une application App Engine. La valeur metric.type identifie la métrique App Engine et les libellés identifient l'application App Engine en fonction de la valeur du libellé project_id. La valeur point.value.distribution_value.mean est utilisée, car cette métrique est une valeur DISTRIBUTION dans l'API Monitoring, qui est mappée sur l'objet de champ distribution_value dans BigQuery. Le champ end_time examine les valeurs des 30 derniers jours.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
Exemple de requête : nombre de requêtes BigQuery
La requête suivante renvoie le nombre de requêtes BigQuery par jour dans un projet. Le champ int64_value est utilisé, car cette métrique est une valeur INT64 dans l'API Monitoring, qui est mappée au champ int64_value dans BigQuery. La valeur metric.type identifie la métrique BigQuery et les libellés identifient le projet en fonction de la valeur du libellé project_id. Le champ end_time examine les valeurs des 30 derniers jours.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
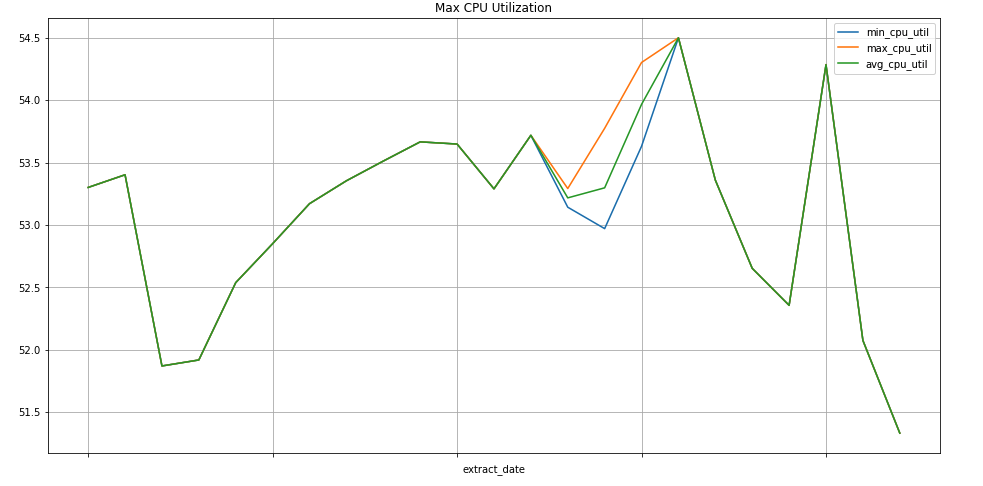
Exemple de requête : instances Compute Engine
La requête suivante recherche la valeur hebdomadaire minimale, maximale et moyenne parmi les valeurs des métriques d'utilisation du processeur pour les instances Compute Engine d'un projet. La valeur metric.type identifie la métrique Compute Engine et les libellés identifient les instances en fonction de la valeur du libellé project_id. Le champ end_time examine les valeurs au cours des 30 derniers jours.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
Visualisation des données
BigQuery est intégré à de nombreux outils vous permettant de visualiser les données.
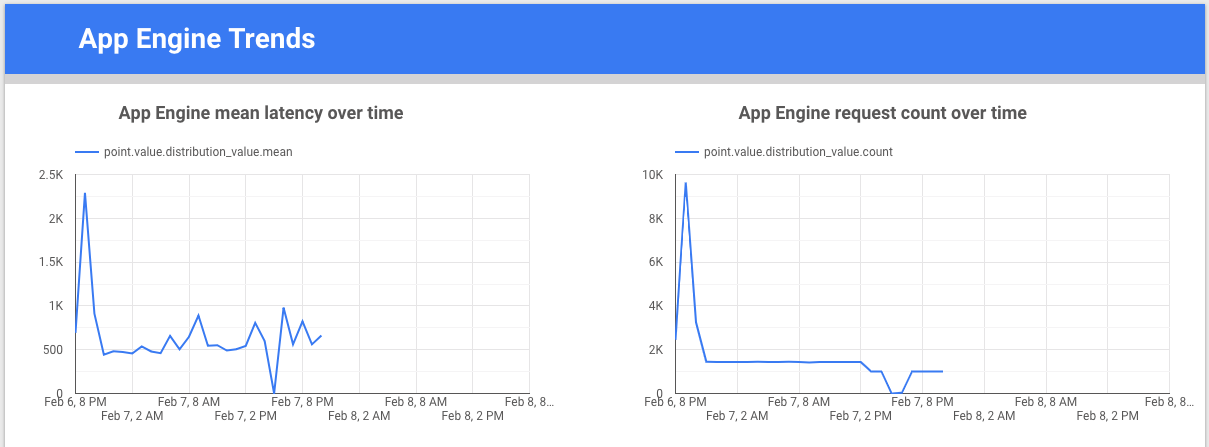
Looker Studio est un outil gratuit conçu par Google. Vous pouvez créer des graphiques de données et des tableaux de bord pour visualiser les données de métrique, et les partager avec votre équipe. L'exemple suivant illustre un graphique des tendances de la latence et du comptage de la valeur de la métrique appengine.googleapis.com/http/server/response_latencies au fil du temps.
Colaboratory est un outil destiné aux formations et aux travaux de recherche concernant le machine learning. Il s'agit d'un environnement de notebook hébergé, basé sur Jupyter. Aucune configuration n'est requise pour accéder aux données dans BigQuery et les exploiter. Vous pouvez développer des analyses et des visualisations détaillées à l'aide d'un notebook Colab, de commandes Python et de requêtes SQL.
Surveiller la mise en œuvre de référence pendant l'exportation
Lorsque l'exportation est en cours d'exécution, vous devez la surveiller. Pour déterminer les métriques à surveiller, vous pouvez définir un objectif de niveau de service (SLO). Un SLO est une valeur ou une plage de valeurs cible pour un niveau de service mesuré par une métrique. Dans le livre Ingénierie en fiabilité des sites, un SLO s'articule autour de quatre axes principaux : disponibilité, débit, taux d'erreur et latence. Pour une exportation de données, le débit et le taux d'erreur représentent deux considérations majeures, que vous pouvez surveiller via les métriques suivantes :
- Débit :
appengine.googleapis.com/http/server/response_count - Taux d'erreur :
logging.googleapis.com/log_entry_count
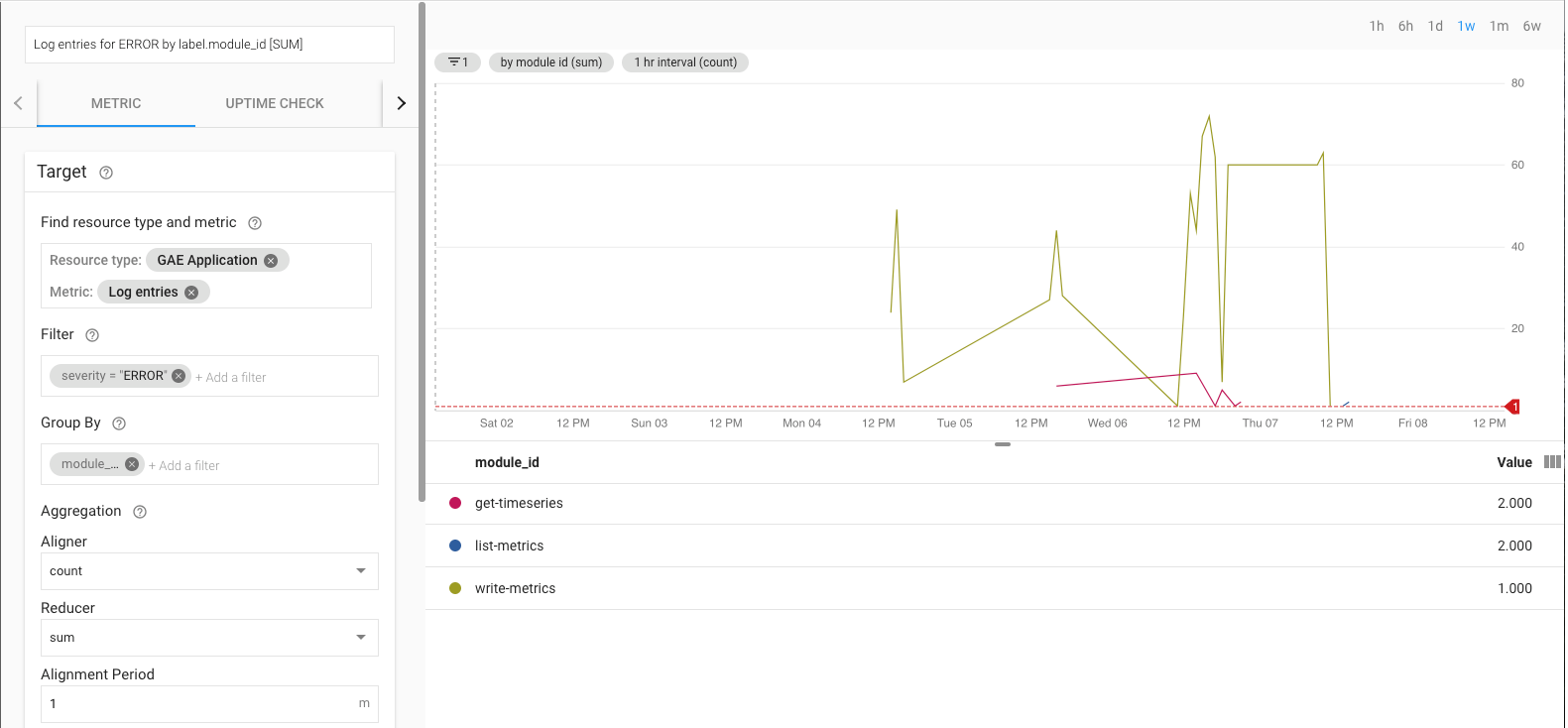
Par exemple, vous pouvez surveiller le taux d'erreur en utilisant la métrique log_entry_count et en la filtrant pour les applications App Engine (list-metrics, get-timeseries, write-metrics) avec une gravité de niveau ERROR. Vous pouvez ensuite utiliser les règles d'alerte dans Cloud Monitoring pour recevoir des alertes sur les erreurs rencontrées dans l'application d'exportation.
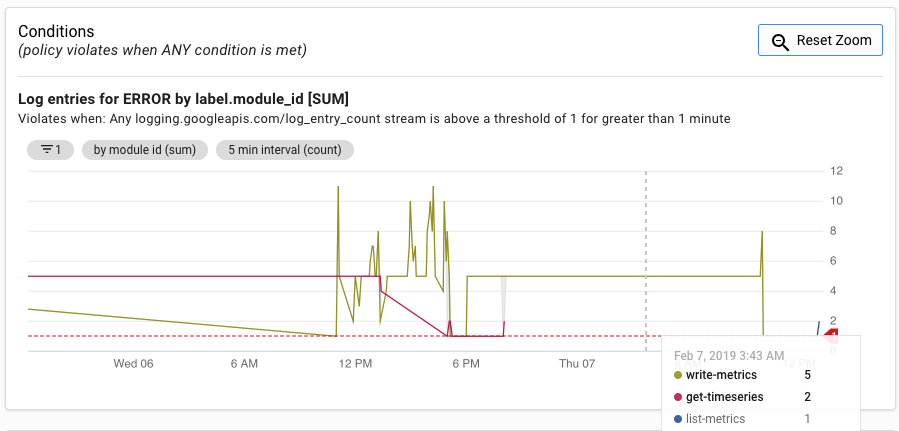
L'interface utilisateur des alertes affiche un graphique de la métrique log_entry_count par rapport au seuil de déclenchement de l'alerte.
Étape suivante
- Consultez la mise en œuvre de référence sur GitHub.
- Lisez la documentation de Cloud Monitoring.
- Consultez la documentation de l'API Cloud Monitoring v3.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.
- Consultez nos ressources sur DevOps.
Apprenez-en plus sur les fonctionnalités DevOps associées à cette solution :
Effectuez l'évaluation DevOps rapide pour comprendre votre position par rapport au reste du secteur.