Ce guide explique aux professionnels de la sécurité comment intégrer des journaux Google Cloudà utiliser dans les analyses de sécurité. En effectuant des analyses de sécurité, vous aidez votre organisation à prévenir, détecter et contrer des menaces telles que les logiciels malveillants, l'hameçonnage, les rançongiciels et les éléments mal configurés.
Cette page vous explique comment :
- Activer les journaux à analyser.
- Acheminer ces journaux vers une seule destination en fonction de l'outil d'analyse de sécurité de votre choix, tel que l'Analyse de journaux, BigQuery, Google Security Operations ou d'une technologie tierce de gestion des informations et des événements de sécurité (SIEM, security information and event management).
- Analyser ces journaux pour auditer votre utilisation du cloud et détecter les menaces potentielles pour vos données et charges de travail, à l'aide d'exemples de requêtes issus du projet Community Security Analytics (CSA).
Les informations de ce guide font partie des Google Cloud opérations de sécurité autonomes, qui incluent la transformation des pratiques de détection et de réponse par des ingénieurs, ainsi que des analyses de sécurité visant à améliorer vos capacités de détection des menaces.
Dans ce guide, les journaux fournissent la source de données à analyser. Toutefois, vous pouvez appliquer les concepts de ce guide pour analyser d'autres données complémentaires sur la sécurité de Google Cloud, telles que les résultats de sécurité de Security Command Center. Security Command Center Premium fournit une liste de détecteurs gérés régulièrement mis à jour pour identifier les menaces, les failles et les erreurs de configuration dans vos systèmes, presque en temps réel. En analysant ces signaux à partir de Security Command Center et en les mettant en corrélation avec les journaux ingérés dans votre outil d'analyse de sécurité comme décrit dans ce guide, vous pouvez obtenir une perspective plus large des menaces de sécurité potentielles.
Le schéma suivant montre comment les sources de données de sécurité, les outils d'analyse de sécurité et les requêtes CSA fonctionnent ensemble.
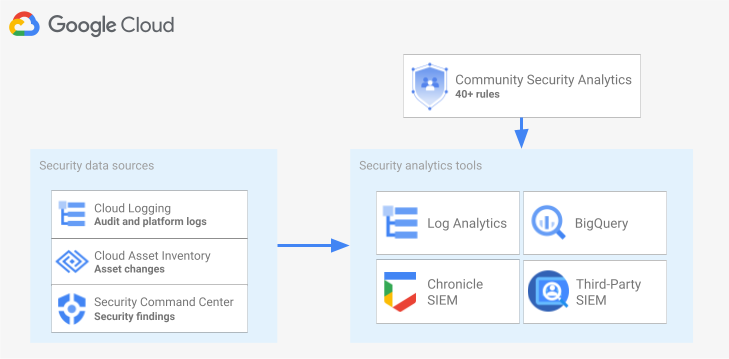
Le schéma commence par les sources de données de sécurité suivantes : les journaux de Cloud Logging, les modifications d'éléments provenant de l'inventaire des éléments cloud et les résultats de sécurité de Security Command Center. Le schéma affiche ensuite les sources de données de sécurité en cours de routage dans l'outil d'analyse de sécurité de votre choix : Analyse de journaux dans Cloud Logging, BigQuery, Google Security Operations ou une solution SIEM tierce. Enfin, le schéma montre comment les données de sécurité classées sont analysées en utilisant des requêtes CSA avec votre outil d'analyse.
Workflow d'analyse des journaux de sécurité
Cette section décrit la procédure à suivre pour configurer l'analyse des journaux de sécurité dansGoogle Cloud. Le workflow se compose des trois étapes présentées dans le schéma suivant et décrits dans les paragraphes suivants :
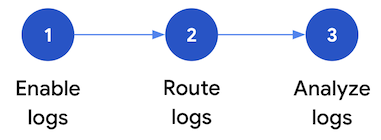
Activer les journaux : de nombreux journaux de sécurité sont disponibles dansGoogle Cloud. Chaque journal contient des informations différentes qui peuvent être utiles pour répondre à des questions de sécurité spécifiques. Certains journaux, comme les journaux d'audit pour les activités d'administration, sont activés par défaut. Les autres doivent être activés manuellement, car des coûts d'ingestion supplémentaires s'appliquent dans Cloud Logging. Par conséquent, la première étape du workflow consiste à hiérarchiser les journaux de sécurité les plus pertinents pour vos besoins d'analyse de sécurité et à activer individuellement ces journaux.
Pour vous aider à évaluer les journaux en termes de visibilité et de couverture des menaces, ce guide inclut un outil de champ d'application des journaux. Cet outil mappe chaque journal avec les tactiques et techniques de menace pertinentes de la matrice MITRE ATT&CK® pour les entreprises. L'outil mappe également les règles Event Threat Detection aux journaux sur lesquels elles reposent dans Security Command Center. Vous pouvez évaluer les journaux à l'aide de l'outil de champ d'application des journaux, quel que soit l'outil d'analyse que vous utilisez.
Routage des journaux : après avoir identifié et activé les journaux à analyser, l'étape suivante consiste à acheminer et agréger les journaux de votre organisation, y compris les dossiers, les projets et les comptes de facturation qu'ils contiennent. La manière dont vous acheminez les journaux dépend de l'outil d'analyse que vous utilisez.
Ce guide décrit les destinations courantes de routage des journaux et vous explique comment utiliser un récepteur agrégé Cloud Logging pour acheminer des journaux à l'échelle de l'organisation dans un bucket de journaux Cloud Logging ou un ensemble de données BigQuery selon que vous choisissez d'utiliser l'Analyse de journaux ou BigQuery pour les analyses.
Analyser les journaux : après avoir acheminé les journaux dans un outil d'analyse, l'étape suivante consiste à effectuer une analyse de ces journaux pour identifier les menaces de sécurité potentielles. La manière dont vous analysez les journaux dépend de l'outil d'analyse que vous utilisez. Si vous utilisez l'Analyse de journaux ou BigQuery, vous pouvez analyser les journaux à l'aide de requêtes SQL. Si vous utilisez Google Security Operations, vous analysez les journaux à l'aide de règles YARA-L. Si vous utilisez un outil SIEM tiers, utilisez le langage de requête spécifié par cet outil.
Dans ce guide, vous trouverez des requêtes SQL permettant d'analyser les journaux dans l'Analyse de journaux ou BigQuery. Les requêtes SQL fournies dans ce guide proviennent du projet Community Security Analytics (CSA). CSA est un ensemble Open Source d'analyses de sécurité de base conçues pour vous fournir une référence de requêtes et de règles prédéfinies que vous pouvez réutiliser pour commencer à analyser vos journaux Google Cloud .
Les sections suivantes fournissent des informations détaillées sur la configuration et l'application de chaque étape du workflow d'analyse des journaux de sécurité.
Activer les journaux
Le processus d'activation des journaux comprend les étapes suivantes :
- Identifier les journaux dont vous avez besoin à l'aide de l'outil de champ d'application des journaux, décrit dans ce guide.
- Enregistrez le filtre de journal généré par l'outil de champ d'application des journaux afin de l'utiliser ultérieurement lors de la configuration du récepteur de journaux.
- Activez la journalisation pour chaque type de journal ou service Google Cloud identifié. Selon le service, vous devrez peut-être également activer les journaux d'audit d'accès aux données correspondants, comme indiqué plus loin dans cette section.
Identifier les journaux à l'aide de l'outil de champ d'application des journaux
Pour vous aider à identifier les journaux qui répondent à vos besoins de sécurité et de conformité, vous pouvez utiliser l'outil de champ d'application des journaux présenté dans cette section. Cet outil fournit un tableau interactif qui regroupe les journaux utiles à la sécurité présents dansGoogle Cloud , y compris les journaux Cloud Audit Logs, les journaux Access Transparency, les journaux réseau et plusieurs journaux de plate-forme. Cet outil mappe chaque type de journal sur les zones suivantes :
- Les tactiques et techniques de menace MITRE ATT&CK pouvant être surveillées avec ce journal.
- Les violations de conformité aux benchmarks CIS Google Cloud Computing Platform qui peuvent être détectées dans ce journal.
- Les règles Event Threat Detection qui s'appuient sur ce journal.
L'outil de champ d'application des journaux génère également un filtre de journaux, qui s'affiche juste après la table. Lorsque vous identifiez les journaux dont vous avez besoin, sélectionnez-les dans l'outil pour mettre à jour automatiquement ce filtre de journaux.
Les procédures courtes suivantes expliquent comment utiliser l'outil de champ d'application des journaux :
- Pour sélectionner ou supprimer un journal dans l'outil de champ d'application des journaux, cliquez sur le bouton d'activation/de désactivation situé à côté du nom du journal.
- Pour sélectionner ou supprimer tous les journaux, cliquez sur le bouton d'activation/de désactivation à côté de l'en-tête Type de journal.
- Pour connaître les techniques MITRE ATT&CK pouvant être surveillées par chaque type de journal, cliquez sur le bouton à côté de l'en-tête Tactiques et techniques MITRE ATT&CK.
Outil de champ d'application des journaux
Enregistrer le filtre de journal
Le filtre de journal généré automatiquement par l'outil de champ d'application des journaux contient tous les journaux que vous avez sélectionnés dans l'outil. Vous pouvez utiliser le filtre tel quel ou l'affiner en fonction de vos besoins. Par exemple, vous pouvez inclure (ou exclure) des ressources uniquement dans un ou plusieurs projets spécifiques. Une fois que vous disposez d'un filtre de journal répondant à vos besoins de journalisation, vous devez l'enregistrer pour l'utiliser lors du routage des journaux. Par exemple, vous pouvez enregistrer le filtre dans un éditeur de texte ou l'enregistrer dans une variable d'environnement comme suit :
- Dans la section "Filtre de journal généré automatiquement" qui suit l'outil, copiez le code du filtre de journal.
- Facultatif : modifiez le code copié pour affiner le filtre.
Dans Cloud Shell, créez une variable pour enregistrer le filtre de journal :
export LOG_FILTER='LOG_FILTER'Remplacez
LOG_FILTERpar le code du filtre de journal.
Activer des journaux de plate-forme spécifiques aux services
Les journaux de plate-forme que vous sélectionnez dans l'outil de champ d'application des journaux doivent être activés service par service (généralement au niveau des ressources). Par exemple, les journaux Cloud DNS sont activés au niveau du réseau VPC. De même, les journaux de flux VPC sont activés au niveau du sous-réseau pour toutes les VM du sous-réseau et les journaux provenant de la journalisation des règles de pare-feu sont activés au niveau de la règle de pare-feu individuelle.
Chaque journal de plate-forme dispose de ses propres instructions concernant l'activation de la journalisation. Toutefois, vous pouvez utiliser l'outil de champ d'application des journaux pour ouvrir rapidement les instructions correspondantes pour chaque journal de plate-forme.
Pour savoir comment activer la journalisation pour un journal de plate-forme spécifique, procédez comme suit :
- Dans l'outil de champ d'application des journaux, localisez le journal de plate-forme que vous souhaitez activer.
- Dans la colonne Activé par défaut, cliquez sur le lien Activer correspondant à ce journal. Ce lien vous permet d'accéder à des instructions détaillées sur l'activation de la journalisation pour ce service.
Activer les journaux d'audit des accès aux données
Comme vous pouvez le constater dans l'outil de champ d'application des journaux, les journaux d'audit des accès aux données de Cloud Audit Logs offrent une couverture étendue de détection des menaces. Cependant, leur volume peut être assez important. L'activation de ces journaux d'audit peut donc entraîner des frais supplémentaires liés à leur ingestion, à leur stockage, à leur exportation et à leur traitement. Cette section explique comment activer ces journaux et présente certaines bonnes pratiques pour vous aider à trouver un compromis entre valeur et coût.
Les journaux d'audit des accès aux données sont désactivés par défaut, sauf pour BigQuery. Pour configurer des journaux d'audit d'accès aux données pour les services Google Cloud autres que BigQuery, vous devez les activer explicitement à l'aide de la console Google Cloud ou de Google Cloud CLI afin de modifier les objets des stratégies Identity and Access Management (IAM). Lorsque vous activez les journaux d'audit des accès aux données, vous pouvez également configurer les types d'opérations enregistrés. Il existe trois types de journaux d'audit des accès aux données :
ADMIN_READ: enregistre les opérations de lecture des métadonnées ou des informations de configuration.DATA_READ: enregistre les opérations de lecture des données fournies par l'utilisateur.DATA_WRITE: enregistre les opérations d'écriture des données fournies par l'utilisateur.
Notez que vous ne pouvez pas configurer l'enregistrement des opérations ADMIN_WRITE qui permettent d'écrire des métadonnées ou des informations de configuration. Les opérations ADMIN_WRITE sont incluses dans les journaux d'audit pour les activités d'administration à partir de Cloud Audit Logs et ne peuvent donc pas être désactivées.
Gérer le volume des journaux d'audit des accès aux données
Lorsque vous activez des journaux d'audit pour l'accès aux données, l'objectif est d'optimiser leur valeur en termes de visibilité sur la sécurité, tout en limitant les coûts et les frais de gestion. Pour vous aider à atteindre cet objectif, nous vous recommandons de procéder comme suit afin de filtrer les journaux de faible valeur et volumineux :
- Donnez la priorité aux services pertinents, tels que les services qui hébergent des charges de travail, des clés et des données sensibles. Pour obtenir des exemples spécifiques de services auxquels il peut être utile de donner la priorité, consultez la section Exemple de configuration d'un journal d'audit pour l'accès aux données.
Privilégiez les projets pertinents, tels que les projets hébergeant des charges de travail de production, plutôt que les projets hébergeant des environnements de développement et de préproduction. Pour filtrer tous les journaux d'un projet particulier, ajoutez l'expression suivante à votre filtre de journal pour votre récepteur. Remplacez PROJECT_ID par l'ID du projet à partir duquel vous souhaitez filtrer tous les journaux :
Projet Expression de filtre de journal Exclure tous les journaux d'un projet donné NOT logName =~ "^projects/PROJECT_ID"
Donnez la priorité à un sous-ensemble d'opérations d'accès aux données, telles que
ADMIN_READ,DATA_READetDATA_WRITE, pour un ensemble minimal d'opérations enregistrées. Par exemple, certains services tels que Cloud DNS écrivent les trois types d'opérations, mais vous ne pouvez activer la journalisation que pour les opérationsADMIN_READ. Une fois que vous avez configuré un ou plusieurs de ces trois types d'opérations d'accès aux données, vous pouvez exclure des opérations spécifiques dont le volume est particulièrement élevé. Vous pouvez exclure ces opérations à volume élevé en modifiant le filtre de journal du récepteur. Par exemple, vous décidez d'activer la journalisation d'audit complète pour l'accès aux données, y compris les opérationsDATA_READsur certains services de stockage critiques. Pour exclure des opérations spécifiques de lecture de données à trafic élevé dans cette situation, vous pouvez ajouter les expressions de filtre de journal recommandées suivantes au filtre de journal de votre récepteur :Service Expression de filtre de journal Exclure des journaux à volume élevé de Cloud Storage NOT (resource.type="gcs_bucket" AND (protoPayload.methodName="storage.buckets.get" OR protoPayload.methodName="storage.buckets.list"))
Exclure des journaux à volume élevé de Cloud SQL NOT (resource.type="cloudsql_database" AND protoPayload.request.cmd="select")
Donnez la priorité aux ressources pertinentes, telles que les ressources qui hébergent vos charges de travail et vos données les plus sensibles. Vous pouvez classer vos ressources en fonction de la valeur des données qu'elles traitent et du risque de sécurité qu'elles présentent, par exemple en fonction de leur disponibilité externe ou non. Bien que les journaux d'audit pour l'accès aux données soient activés par service, vous pouvez filtrer des ressources ou des types de ressources spécifiques via le filtre de journal.
Excluez des comptes principaux spécifiques de l'enregistrement de leurs accès aux données. Vous pouvez par exemple demander à ce que les opérations effectuées par vos comptes de test internes ne soient pas consignées. Pour en savoir plus, consultez la section Définir des exceptions dans la documentation sur les journaux d'audit pour l'accès aux données.
Exemple de configuration d'un journal d'audit pour l'accès aux données
Le tableau suivant fournit une configuration de référence pour les journaux d'audit d'accès aux données, que vous pouvez utiliser pour les projets Google Cloud afin de limiter les volumes de journaux tout en bénéficiant d'une visibilité précieuse sur la sécurité :
| Niveau | Services | Types de journaux d'audit pour l'accès aux données | Tactiques MITRE ATT&CK |
|---|---|---|---|
| Services d'authentification et d'autorisation | IAM Identity-Aware Proxy (IAP)1 Cloud KMS Secret Manager Resource Manager |
ADMIN_READ DATA_READ |
Découverte Accès aux identifiants Élévation des privilèges |
| Services de stockage | BigQuery (activé par défaut) Cloud Storage1, 2 |
DATA_READ DATA_WRITE |
Collecte Exfiltration |
| Services d'infrastructure | Compute Engine Règle d'organisation |
ADMIN_READ | Discovery |
1 L'activation des journaux d'audit pour l'accès aux données pour IAP ou Cloud Storage peut générer des volumes de journaux importants lorsque le trafic vers les ressources Web protégées par IAP ou vers Cloud Storage est élevé.
2 L'activation des journaux d'audit d'accès aux données pour Cloud Storage peut interrompre l'utilisation de téléchargements de navigateurs authentifiés pour les objets non publics. Pour obtenir plus de détails et des solutions de contournement à ce problème, consultez le guide de dépannage de Cloud Storage.
Dans l'exemple de configuration, notez la façon dont les services sont regroupés par niveaux de sensibilité en fonction de leurs données, métadonnées ou configurations sous-jacentes. Ces niveaux illustrent les niveaux de précision suivants recommandés pour la journalisation d'audit pour l'accès aux données :
- Services d'authentification et d'autorisation : pour ce niveau de services, nous vous recommandons d'effectuer un audit de toutes les opérations d'accès aux données. Ce niveau d'audit vous aide à surveiller l'accès à vos clés sensibles, à vos secrets et à vos stratégies IAM. Surveiller cet accès peut vous aider à détecter les tactiques MITRE ATT&CK telles que la détection, l'accès aux identifiants et l'élévation des privilèges.
- Services de stockage : pour ce niveau de services, nous vous recommandons d'effectuer un audit des opérations d'accès aux données impliquant des données fournies par l'utilisateur. Ce niveau d'audit vous aide à surveiller l'accès à vos données sensibles et précieuses. La surveillance de cet accès peut vous aider à détecter les tactiques MITRE ATT&CK telles que la collecte et l'exfiltration en fonction de vos données.
- Services d'infrastructure : pour ce niveau de services, nous vous recommandons d'effectuer un audit des opérations d'accès aux données impliquant des métadonnées ou des informations de configuration. Ce niveau d'audit vous aide à surveiller l'analyse de la configuration de l'infrastructure. La surveillance de cet accès peut vous aider à détecter les tactiques MITRE ATT&CK telles que la détection pour vos charges de travail.
Acheminer les journaux
Une fois les journaux identifiés et activés, l'étape suivante consiste à les acheminer vers une seule et même destination. La destination, le chemin et la complexité du routage varient en fonction des outils d'analyse que vous utilisez, comme illustré dans le schéma suivant.
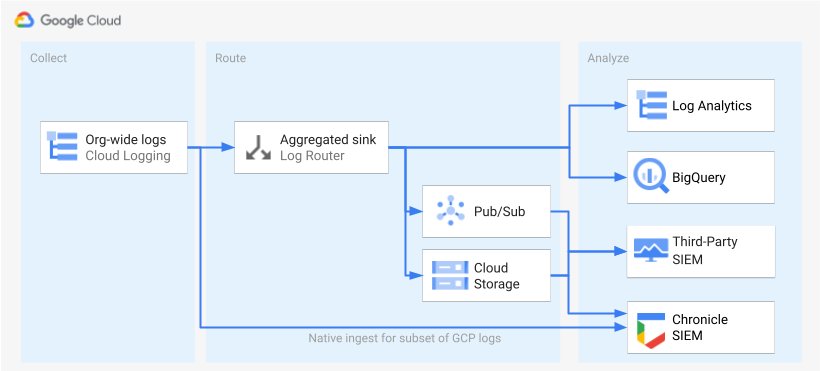
Le schéma illustre les options de routage suivantes :
Si vous utilisez l'analyse de journaux, vous avez besoin d'un récepteur agrégé pour agréger les journaux de votre organisation Google Cloud dans un seul bucket Cloud Logging.
Si vous utilisez BigQuery, vous avez besoin d'un récepteur agrégé pour agréger les journaux de votre organisation Google Cloud dans un seul et même ensemble de données BigQuery.
Si vous utilisez Google Security Operations et que ce sous-ensemble prédéfini de journaux répond à vos besoins en analyse de sécurité, vous pouvez agréger automatiquement ces journaux dans votre compte Google Security Operations à l'aide de l'ingestion Google Security Operations intégrée. Vous pouvez également afficher cet ensemble prédéfini de journaux en consultant la colonne Exportable directement vers Google Security Operations de l'outil de champ d'action des journaux. Pour en savoir plus sur l'exportation de ces journaux prédéfinis, consultez Ingérer des journaux Google Cloud dans Google Security Operations.
Si vous utilisez BigQuery ou une solution SIEM tierce, ou si vous souhaitez exporter un ensemble étendu de journaux dans Google Security Operations, le schéma montre qu'une étape supplémentaire est nécessaire entre l'activation des journaux et leur analyse. Cette étape supplémentaire consiste à configurer un récepteur agrégé qui achemine les journaux sélectionnés de manière appropriée. Si vous utilisez BigQuery, ce récepteur suffit pour acheminer les journaux vers BigQuery. Si vous utilisez une solution SIEM tierce, vous devez demander au récepteur d'agréger les journaux sélectionnés dans Pub/Sub ou Cloud Storage pour qu'ils puissent être intégrés dans votre outil d'analyse.
Les options de routage vers Google Security Operations et une solution SIEM tierce ne sont pas abordées dans ce guide. Toutefois, les sections suivantes fournissent les étapes détaillées permettant d'acheminer les journaux vers l'Analyse de journaux ou BigQuery :
- Configurer une seule destination
- Créer un récepteur de journaux agrégé
- Accorder l'accès au récepteur
- Configurer l'accès en lecture à la destination
- Vérifier que les journaux sont acheminés vers la destination
Configurer une seule destination
Analyse de journaux
Ouvrez la console Google Cloud dans le projet Google Cloud dans lequel vous souhaitez agréger des journaux.
Dans un terminal Cloud Shell, exécutez la commande
gcloudsuivante pour créer un bucket de journaux :gcloud logging buckets create BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_IDRemplacez les éléments suivants :
PROJECT_ID: ID du projet Google Cloud dans lequel les journaux agrégés seront stockés.BUCKET_NAME: nom du nouveau bucket Logging.BUCKET_LOCATION: emplacement géographique du nouveau bucket Logging. Les emplacements acceptés sontglobal,usoueu. Pour en savoir plus sur ces régions de stockage, consultez la section Régions où le service est disponible. Si vous ne spécifiez pas d'emplacement, la régionglobalest utilisée, ce qui signifie que les journaux peuvent se trouver physiquement dans n'importe quelle région.
Vérifiez que le bucket a été créé :
gcloud logging buckets list --project=PROJECT_ID(Facultatif) Définissez la durée de conservation des journaux dans le bucket. L'exemple suivant étend la conservation des journaux stockés dans le bucket à 365 jours :
gcloud logging buckets update BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID \ --retention-days=365Mettez à niveau votre nouveau bucket pour utiliser l'Analyse de journaux en suivant ces étapes.
BigQuery
Ouvrez la console Google Cloud dans le projet Google Cloud dans lequel vous souhaitez agréger des journaux.
Dans un terminal Cloud Shell, exécutez la commande
bq mksuivante pour créer un ensemble de données :bq --location=DATASET_LOCATION mk \ --dataset \ --default_partition_expiration=PARTITION_EXPIRATION \ PROJECT_ID:DATASET_IDRemplacez les éléments suivants :
PROJECT_ID: ID du Google Cloud projet dans lequel les journaux agrégés seront stockés.DATASET_ID: ID du nouvel ensemble de données BigQuery.DATASET_LOCATION: emplacement géographique de l'ensemble de données. Une fois l'ensemble de données créé, l'emplacement ne peut plus être modifié.PARTITION_EXPIRATION: durée de vie par défaut (en secondes) des partitions des tables partitionnées créées par le récepteur de journaux. Vous allez configurer le récepteur de journaux dans la section suivante. Le récepteur de journaux que vous configurez utilise des tables partitionnées par jour en fonction de l'horodatage de l'entrée de journal. Les partitions (y compris les entrées de journal associées) sont suppriméesPARTITION_EXPIRATIONsecondes après la date de la partition.
Créer un récepteur de journaux agrégé
Pour acheminer vos journaux d'organisation vers votre destination, vous devez créer un récepteur agrégé au niveau de l'organisation. Pour inclure tous les journaux que vous avez sélectionnés dans l'outil de champ d'application des journaux, configurez le récepteur avec le filtre de journaux généré par l'outil de champ d'application des journaux.
Analyse de journaux
Dans un terminal Cloud Shell, exécutez la commande
gcloudsuivante pour créer un récepteur agrégé au niveau de l'organisation :gcloud logging sinks create SINK_NAME \ logging.googleapis.com/projects/PROJECT_ID/locations/BUCKET_LOCATION/buckets/BUCKET_NAME \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --include-childrenRemplacez les éléments suivants :
SINK_NAME: nom du récepteur qui achemine les journaux.PROJECT_ID: ID du Google Cloud projet dans lequel les journaux agrégés seront stockés.BUCKET_LOCATION: emplacement du bucket Logging que vous avez créé pour le stockage des journaux.BUCKET_NAME: nom du bucket Logging que vous avez créé pour le stockage des journaux.LOG_FILTER: filtre de journal que vous avez enregistré à partir de l'outil de champ d'application des journaux.ORGANIZATION_ID: ID de ressource pour votre organisation.
L'option
--include-childrenest importante pour que les journaux de tous les projetsGoogle Cloud de votre organisation soient également inclus. Pour en savoir plus, consultez Générer et acheminer des journaux au niveau de l'organisation vers des destinations compatibles.Vérifiez que le récepteur a été créé :
gcloud logging sinks list --organization=ORGANIZATION_IDRécupérez le nom du compte de service associé au récepteur que vous venez de créer :
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_IDLa sortie ressemble à ceci :
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`Copiez la chaîne entière pour
writerIdentitycommençant par serviceAccount:. Cet identifiant correspond au compte de service du récepteur. Tant que vous n'accordez pas à ce compte de service un accès en écriture au bucket de journaux, le routage des journaux depuis ce récepteur échouera. Vous allez accorder un accès en écriture à l'identité du rédacteur du récepteur dans la section suivante.
BigQuery
Dans un terminal Cloud Shell, exécutez la commande
gcloudsuivante pour créer un récepteur agrégé au niveau de l'organisation :gcloud logging sinks create SINK_NAME \ bigquery.googleapis.com/projects/PROJECT_ID/datasets/DATASET_ID \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --use-partitioned-tables \ --include-childrenRemplacez les éléments suivants :
SINK_NAME: nom du récepteur qui achemine les journaux.PROJECT_ID: ID du projet Google Cloud dans lequel vous souhaitez agréger les journaux.DATASET_ID: ID de l'ensemble de données BigQuery que vous avez créé.LOG_FILTER: filtre de journal que vous avez enregistré à partir de l'outil de champ d'application des journaux.ORGANIZATION_ID: ID de ressource pour votre organisation.
L'option
--include-childrenest importante pour que les journaux de tous les projetsGoogle Cloud de votre organisation soient également inclus. Pour en savoir plus, consultez Générer et acheminer des journaux au niveau de l'organisation vers des destinations compatibles.L'option
--use-partitioned-tablesest importante pour que les données soient partitionnées par jour, sur la base du champtimestampde l'entrée de journal. Cela simplifie l'interrogation des données et permet de réduire les coûts des requêtes en limitant la quantité de données analysées par les requêtes. Un autre avantage des tables partitionnées est que vous pouvez définir une date d'expiration des partitions par défaut au niveau de l'ensemble de données pour répondre à vos exigences de conservation des journaux. Vous avez déjà défini un délai d'expiration des partitions par défaut lorsque vous avez créé la destination de l'ensemble de données dans la section précédente. Vous pouvez également définir un délai d'expiration des partitions au niveau de chaque table, ce qui vous permet de contrôler avec précision les données en fonction du type de journal.Vérifiez que le récepteur a été créé :
gcloud logging sinks list --organization=ORGANIZATION_IDRécupérez le nom du compte de service associé au récepteur que vous venez de créer :
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_IDLa sortie ressemble à ceci :
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`Copiez la chaîne entière pour
writerIdentitycommençant par serviceAccount:. Cet identifiant correspond au compte de service du récepteur. Tant que vous n'accordez pas à ce compte de service un accès en écriture à l'ensemble de données BigQuery, le routage des journaux depuis ce récepteur échouera. Vous allez accorder un accès en écriture à l'identité du rédacteur du récepteur dans la section suivante.
Accorder l'accès au récepteur
Après avoir créé le récepteur de journaux, vous devez l'autoriser à écrire dans sa destination, qu'il s'agisse du bucket Logging ou de l'ensemble de données BigQuery.
Analyse de journaux
Pour ajouter les autorisations au compte de service du récepteur, procédez comme suit :
Dans la console Google Cloud , accédez à la page IAM :
Assurez-vous d'avoir sélectionné le projet Google Cloud de destination qui contient le bucket Logging que vous avez créé pour le stockage de journaux central.
Cliquez sur person_addAccorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez le compte de service du récepteur, sans le préfixe
serviceAccount:. Rappel : cette identité provient du champwriterIdentity, que vous avez récupéré dans la section précédente après la création du récepteur.Dans le menu déroulant Sélectionner un rôle, sélectionnez Rédacteur de bucket de journaux.
Cliquez sur Ajouter une condition IAM pour limiter l'accès du compte de service au seul bucket de journaux que vous avez créé.
Saisissez un titre et une description pour la condition.
Dans le menu déroulant Type de condition, sélectionnez Ressource > Nom.
Dans le menu déroulant Opérateur, sélectionnez Se termine par.
Dans le champ Valeur, saisissez l'emplacement et le nom du bucket comme suit :
locations/BUCKET_LOCATION/buckets/BUCKET_NAMECliquez sur Enregistrer pour ajouter la condition.
Cliquez sur Enregistrer pour définir les autorisations.
BigQuery
Pour ajouter les autorisations au compte de service du récepteur, procédez comme suit :
Dans la console Google Cloud , accédez à BigQuery :
Ouvrez l'ensemble de données BigQuery que vous avez créé pour le stockage de journaux central.
Dans l'onglet "Informations sur l'ensemble de données", cliquez sur le menu déroulant Partage keyboard_arrow_down, puis sur Autorisations.
Dans le panneau latéral "Autorisations d'ensemble de données", cliquez sur Ajouter un compte principal.
Dans le champ Nouveaux comptes principaux, saisissez le compte de service du récepteur, sans le préfixe
serviceAccount:. Rappel : cette identité provient du champwriterIdentity, que vous avez récupéré dans la section précédente après la création du récepteur.Dans le menu déroulant Rôle, sélectionnez Éditeur de données BigQuery.
Cliquez sur Enregistrer.
Une fois que vous avez accordé l'accès au récepteur, les entrées de journal commencent à remplir la destination du récepteur : le bucket Logging ou l'ensemble de données BigQuery.
Configurer l'accès en lecture à la destination
Maintenant que votre récepteur de journaux achemine les journaux depuis l'ensemble de votre organisation vers une seule et même destination, vous pouvez effectuer une recherche parmi tous ces journaux. Utilisez les autorisations IAM pour gérer les autorisations et accorder les accès nécessaires.
Analyse de journaux
Pour autoriser l'affichage et l'interrogation des journaux de votre nouveau bucket de journaux, procédez comme suit :
Dans la console Google Cloud , accédez à la page IAM :
Assurez-vous d'avoir sélectionné le projet Google Cloud que vous utilisez pour agréger les journaux.
Cliquez sur person_addAjouter.
Dans le champ Nouveau compte principal, ajoutez votre compte de messagerie.
Dans le menu déroulant Sélectionner un rôle, sélectionnez Accesseur de vues de journaux.
Ce rôle fournit au compte principal nouvellement ajouté un accès en lecture à toutes les vues de tous les buckets du projet Google Cloud . Pour limiter l'accès d'un utilisateur, ajoutez une condition qui limite l'accès en lecture de l'utilisateur uniquement à votre nouveau bucket.
Cliquez sur Ajouter une condition :
Saisissez un titre et une description pour la condition.
Dans le menu déroulant Type de condition, sélectionnez Ressource > Nom.
Dans le menu déroulant Opérateur, sélectionnez Se termine par.
Dans le champ Valeur, saisissez l'emplacement et le nom du bucket, ainsi que la vue de journal par défaut
_AllLogs, comme suit :locations/BUCKET_LOCATION/buckets/BUCKET_NAME/views/_AllLogsCliquez sur Enregistrer pour ajouter la condition.
Cliquez sur Enregistrer pour définir les autorisations.
BigQuery
Pour autoriser l'affichage et l'interrogation des journaux dans votre ensemble de données BigQuery, suivez les étapes décrites dans la section Accorder l'accès à un ensemble de données, dans la documentation BigQuery.
Vérifier que les journaux sont acheminés vers la destination
Analyse de journaux
Lorsque vous acheminez des journaux vers un bucket de journaux mis à niveau vers l'Analyse de journaux, vous pouvez afficher et interroger toutes les entrées de journal via une vue de journal unique avec un schéma unifié pour tous les types de journaux. Pour vérifier que les journaux sont correctement acheminés, procédez comme suit :
Dans la console Google Cloud , accédez à la page "Analyse de journaux" :
Accéder à l'analyse de journaux
Assurez-vous d'avoir sélectionné le projet Google Cloud que vous utilisez pour agréger les journaux.
Cliquez sur l'onglet Vues de journaux.
Si ce n'est pas déjà fait, développez les vues de journaux dans le bucket de journaux que vous avez créé (c'est-à-dire
BUCKET_NAME).Sélectionnez la vue de journaux par défaut
_AllLogs. Vous pouvez maintenant inspecter l'intégralité du schéma de journal dans le panneau de droite, comme illustré dans la capture d'écran suivante :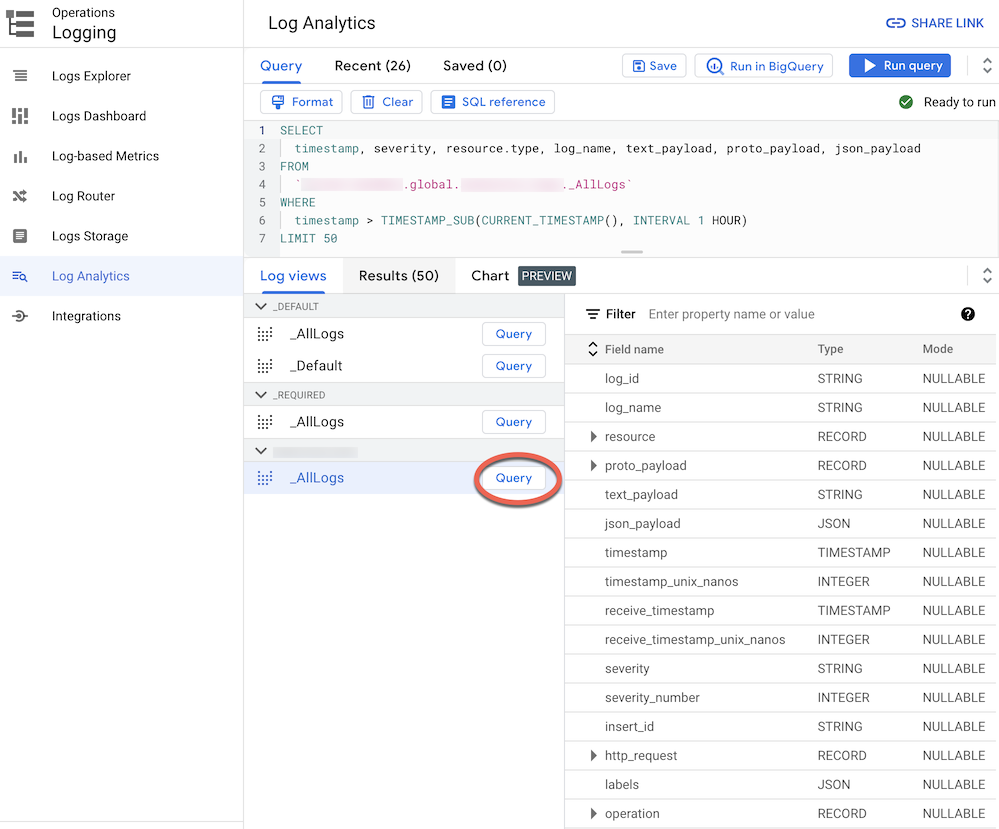
À côté de
_AllLogs, cliquez sur Query (Requête). Cela remplit l'éditeur Query (Requête) avec un exemple de requête SQL pour récupérer les entrées de journal récemment acheminées.Cliquez sur Exécuter la requête pour afficher les entrées de journal récemment acheminées.
En fonction du niveau d'activité dans les projets Google Cloud de votre organisation, vous devrez peut-être attendre quelques minutes avant que certains journaux ne soient générés, puis acheminés vers votre bucket de journaux.
BigQuery
Lorsque vous acheminez des journaux vers un ensemble de données BigQuery, Cloud Logging crée des tables BigQuery pour conserver les entrées de journal, comme illustré dans la capture d'écran suivante :
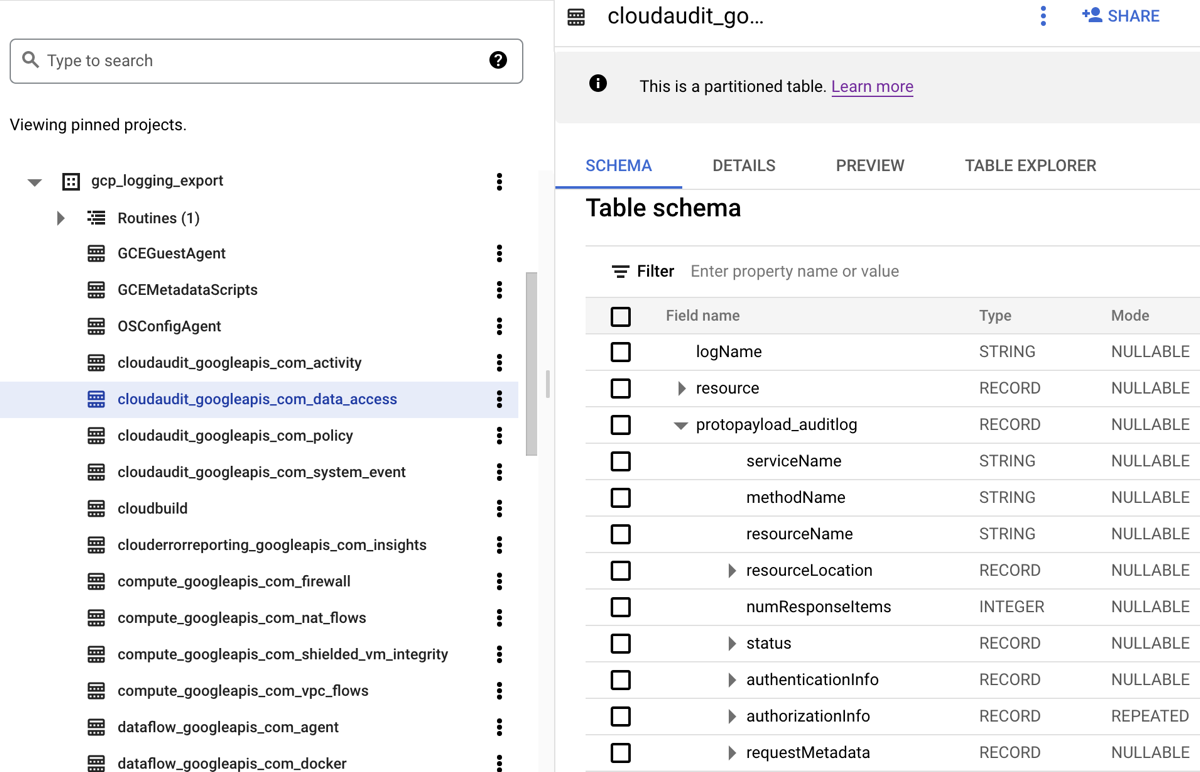
La capture d'écran montre comment Cloud Logging nomme chaque table BigQuery en fonction du nom du journal auquel une entrée de journal appartient. Par exemple, la table cloudaudit_googleapis_com_data_access sélectionnée dans la capture d'écran contient des journaux d'audit d'accès aux données dont l'ID de journal est cloudaudit.googleapis.com%2Fdata_access. En plus d'être nommées en fonction de l'entrée de journal correspondante, les tables sont également partitionnées selon les codes temporels de chaque entrée de journal.
En fonction du niveau d'activité dans les projets Google Cloud de votre organisation, vous devrez peut-être attendre quelques minutes avant que certains journaux ne soient générés, puis acheminés vers votre ensemble de données BigQuery.
Analyser des journaux
Vous pouvez exécuter un large éventail de requêtes sur vos journaux d'audit et de plate-forme. La liste suivante fournit un ensemble d'exemples de questions de sécurité que vous pouvez poser dans vos propres journaux. Pour chaque question figurant dans cette liste, il existe deux versions de la requête CSA correspondante : l'une pour une utilisation avec l'Analyse de journaux et l'autre avec BigQuery. Utilisez la version de requête qui correspond à la destination du récepteur que vous avez configurée précédemment.
Analyse de journaux
Avant d'utiliser l'une des requêtes SQL ci-dessous, remplacez MY_PROJECT_ID par l'ID du projet Google Cloud dans lequel vous avez créé le bucket de journaux (soit PROJECT_ID), et MY_DATASET_ID par la région et le nom de ce bucket de journaux (soit BUCKET_LOCATION.BUCKET_NAME).
BigQuery
Avant d'utiliser l'une des requêtes SQL ci-dessous, remplacez MY_PROJECT_ID par l'ID du projet Google Cloud dans lequel vous avez créé l'ensemble de données BigQuery (soit PROJECT_ID), et MY_DATASET_ID par le nom de cet ensemble de données, soit DATASET_ID).
- Questions sur la connexion et l'accès
- Questions sur les modifications des autorisations
- Questions sur l'activité de provisionnement
- Questions sur l'utilisation des charges de travail
- Questions sur l'accès aux données
- Quels sont les utilisateurs ayant le plus consulté des données durant la semaine passée ?
- Quels utilisateurs ont accédé aux données de la table "accounts" le mois passé ?
- Quelles sont les tables les plus fréquemment utilisées et par qui ?
- Quelles sont les 10 requêtes les plus fréquentes dans BigQuery au cours de la semaine écoulée ?
- Quelles sont les actions les plus courantes enregistrées dans le journal d'accès aux données au cours du mois passé ?
- Questions sur la sécurité du réseau
Questions liées à la connexion et à l'accès
Ces exemples de requêtes effectuent une analyse pour détecter les tentatives de connexion suspectes ou les tentatives d'accès initiales à votre environnement Google Cloud .
Des tentatives de connexion suspectes signalées par Google Workspace ?
En recherchant les journaux Cloud Identity faisant partie de l'audit de connexion Google Workspace, la requête suivante détecte les tentatives de connexion suspectes signalées par Google Workspace. Ces tentatives de connexion peuvent provenir de la console Google Cloud , de la console d'administration ou de gcloud CLI.
Analyse de journaux
BigQuery
Des échecs de connexion excessifs liés à l'identité d'un utilisateur ?
En recherchant les journaux Cloud Identity faisant partie de l'audit de connexion Google Workspace, la requête suivante détecte les utilisateurs qui ont rencontré au moins trois échecs de connexion successifs au cours des dernières 24 heures.
Analyse de journaux
BigQuery
Des tentatives d'accès ne respectent pas VPC Service Controls ?
En analysant les journaux d'audit des refus de règles à partir de Cloud Audit Logs, la requête suivante détecte les tentatives d'accès bloquées par VPC Service Controls. Tout résultat de requête peut indiquer une activité potentiellement malveillante, telle que des tentatives d'accès de réseaux non autorisés utilisant des identifiants volés.
Analyse de journaux
BigQuery
Des tentatives d'accès ne respectent pas les contrôles d'accès IAP ?
En analysant les journaux de l'équilibreur de charge d'application externe, la requête suivante détecte les tentatives d'accès bloquées par IAP. Tous les résultats de requête peuvent indiquer une tentative d'accès initiale ou une tentative d'exploitation de failles.
Analyse de journaux
BigQuery
Questions sur les modifications des autorisations
Ces exemples de requêtes effectuent une analyse de l'activité des administrateurs qui modifie les autorisations, y compris les stratégies IAM, les groupes et les adhésions aux groupes, les comptes de service et les clés associées. Ces modifications d'autorisation peuvent fournir un niveau d'accès élevé aux données ou aux environnements sensibles.
Des utilisateurs ont-ils été ajoutés à des groupes hautement privilégiés ?
En analysant les journaux d'audit de l'audit des administrateurs Google Workspace, la requête suivante détecte les utilisateurs qui ont été ajoutés à l'un des groupes hautement privilégiés répertoriés dans la requête. Vous utilisez l'expression régulière dans la requête pour définir les groupes (tels que admin@example.com ou prod@example.com) à surveiller. Tous les résultats de requête peuvent indiquer une élévation de privilèges malveillante ou accidentelle.
Analyse de journaux
BigQuery
Des autorisations sont-elles accordées via un compte de service ?
En analysant les journaux d'audit des activités d'administration à partir de Cloud Audit Logs, la requête suivante détecte toutes les autorisations accordées à un compte principal sur un compte de service. Voici des exemples d'autorisations pouvant être accordées : la possibilité d'emprunter l'identité de ce compte de service ou de créer des clés de compte de service. Tous les résultats de requête peuvent indiquer une instance d'élévation des privilèges ou un risque de fuite d'identifiants.
Analyse de journaux
BigQuery
Comptes de service ou clés créés par une identité non approuvée ?
En analysant les journaux d'audit pour les activités d'administration, la requête suivante détecte tous les comptes de service ou les clés créés manuellement par un utilisateur. Par exemple, vous pouvez suivre une bonne pratique qui consiste à autoriser uniquement la création de comptes de service par un compte de service approuvé au sein d'un workflow automatisé. Par conséquent, toute création de compte de service en dehors de ce workflow est considérée comme non conforme et peut être malveillante.
Analyse de journaux
BigQuery
Un utilisateur a-t-il ajouté (ou supprimé) à une stratégie IAM sensible ?
En recherchant des journaux d'audit pour les activités d'administration, la requête suivante détecte toute modification d'accès d'utilisateur ou de groupe pour une ressource sécurisée par IAP, telle qu'un service de backend Compute Engine. La requête suivante recherche toutes les mises à jour de stratégie IAM pour les ressources IAP impliquant le rôle IAM roles/iap.httpsResourceAccessor. Ce rôle fournit des autorisations d'accès à la ressource HTTPS ou au service de backend. Tous les résultats de requête peuvent indiquer des tentatives de contournement des défenses d'un service de backend susceptible d'être exposé à Internet.
Analyse de journaux
BigQuery
Questions sur l'activité de provisionnement
Ces exemples de requêtes effectuent une analyse pour détecter les activités d'administration suspectes ou anormales, telles que le provisionnement et la configuration des ressources.
Des modifications ont-elles été apportées aux paramètres de journalisation ?
En recherchant les journaux d'audit pour les activités d'administration, la requête suivante détecte toute modification apportée aux paramètres de journalisation. Les paramètres de journalisation de la surveillance vous permettent de détecter une désactivation accidentelle ou malveillante des journaux d'audit et des techniques d'éviction de défense similaires.
Analyse de journaux
BigQuery
Les journaux de flux VPC sont-ils activement désactivés ?
En recherchant les journaux d'audit pour les activités d'administration, la requête suivante détecte tous les sous-réseaux dont les journaux de flux VPC ont été activement désactivés. La surveillance des paramètres des journaux de flux VPC vous permet de détecter la désactivation accidentelle ou malveillante des journaux de flux VPC et d'autres techniques d'éviction de défense similaires.
Analyse de journaux
BigQuery
Un nombre inhabituel de règles de pare-feu modifiées au cours de la semaine passée ?
En recherchant les journaux d'audit pour les activités d'administration, la requête suivante détecte un nombre inhabituellement élevé de modifications des règles de pare-feu pour un jour donné au cours de la semaine écoulée. Pour déterminer s'il existe une anomalie, la requête effectue une analyse statistique sur le nombre quotidien de modifications des règles de pare-feu. Les moyennes et les écarts-types sont calculés pour chaque jour en examinant les nombres quotidiens précédents avec une période d'analyse de 90 jours. Une anomalie est prise en compte lorsque le nombre quotidien est supérieur à deux écarts types par rapport à la moyenne. La requête, y compris le facteur d'écart type et les périodes d'analyse, peuvent toutes être configurées pour s'adapter à votre profil d'activité de provisionnement cloud et pour minimiser les faux positifs.
Analyse de journaux
BigQuery
Des VM supprimées au cours de la semaine passée ?
En recherchant les journaux d'audit pour les activités d'administration, la requête suivante répertorie toutes les instances Compute Engine supprimées au cours de la semaine écoulée. Cette requête peut vous aider à auditer les suppressions de ressources et à détecter les activités malveillantes potentielles.
Analyse de journaux
BigQuery
Questions sur l'utilisation des charges de travail
Ces exemples de requêtes effectuent une analyse pour comprendre qui et ce qui consomme vos charges de travail et API Cloud, et vous aident à détecter d'éventuels comportements malveillants en interne ou en externe.
L'utilisation de l'API est-elle inhabituellement élevée par une identité utilisateur au cours de la semaine passée ?
En analysant tous les journaux d'audit Cloud, la requête suivante détecte une utilisation d'API inhabituellement élevée par une identité d'utilisateur sur un jour donné au cours de la semaine passée. Une utilisation inhabituellement élevée peut être un indicateur d'un abus potentiel d'API, d'une menace interne ou d'informations d'identification divulguées. Pour déterminer s'il existe une anomalie, cette requête effectue une analyse statistique du nombre quotidien d'actions par compte principal. Les moyennes et les écarts-types sont calculés pour chaque jour et pour chaque compte principal en examinant les nombres quotidiens précédents avec une période d'analyse de 60 jours. Une anomalie est prise en compte lorsque le nombre quotidien d'un utilisateur est supérieur à trois écarts types par rapport à sa moyenne. La requête, y compris le facteur d'écart type et les périodes d'analyse, peuvent toutes être configurées pour s'adapter à votre profil d'activité de provisionnement cloud et pour minimiser les faux positifs.
Analyse de journaux
BigQuery
Quelle est l'utilisation quotidienne de l'autoscaling au cours du mois passé ?
En analysant les journaux d'audit pour les activités d'administration, la requête suivante indique l'utilisation de l'autoscaling par jour au cours du dernier mois. Cette requête peut être utilisée pour identifier des modèles ou des anomalies qui justifient un examen de sécurité plus approfondi.
Analyse de journaux
BigQuery
Questions sur l'accès aux données
Ces exemples de requêtes effectuent une analyse pour comprendre qui accède aux données ou les modifie dans Google Cloud.
Quels sont les utilisateurs ayant le plus consulté des données durant la semaine passée ?
La requête suivante utilise les journaux d'audit pour l'accès aux données pour identifier les utilisateurs qui ont le plus fréquemment accédé aux données des tables BigQuery au cours de la semaine écoulée.
Analyse de journaux
BigQuery
Quels utilisateurs ont accédé aux données de la table "accounts" le mois passé ?
La requête suivante utilise les journaux d'audit d'accès aux données pour identifier les utilisateurs qui ont le plus fréquemment interrogé une table accounts donnée au cours du mois écoulé.
Outre les espaces réservés MY_DATASET_ID et MY_PROJECT_ID de votre destination d'exportation BigQuery, la requête suivante utilise les espaces réservés DATASET_ID et PROJECT_ID. Vous devez remplacer les espaces réservés DATASET_ID et PROJECT_ID pour spécifier la table cible dont l'accès est analysé, tel que la table accounts dans cet exemple.
Analyse de journaux
BigQuery
Quelles sont les tables les plus fréquemment utilisées et par qui ?
La requête suivante utilise les journaux d'audit pour l'accès aux données pour identifier les tables BigQuery contenant les données les plus fréquemment lues et modifiées au cours du mois passé. Elle affiche l'identité de l'utilisateur associé, ainsi que la répartition du nombre total de fois où les données ont été lues et modifiées.
Analyse de journaux
BigQuery
Quelles sont les 10 requêtes les plus fréquentes dans BigQuery au cours de la semaine écoulée ?
La requête suivante utilise les journaux d'audit pour l'accès aux données pour identifier les requêtes les plus courantes au cours de la semaine écoulée. Elle répertorie également les utilisateurs correspondants et les tables référencées.
Analyse de journaux
BigQuery
Quelles sont les actions les plus courantes enregistrées dans le journal d'accès aux données au cours du mois passé ?
La requête suivante utilise tous les journaux de Cloud Audit Logs pour identifier les 100 actions les plus fréquentes enregistrées au cours du mois passé.
Analyse de journaux
BigQuery
Questions sur la sécurité du réseau
Ces exemples de requêtes effectuent une analyse de votre activité réseau dans Google Cloud.
Des connexions entre une nouvelle adresse IP et un sous-réseau spécifique ?
La requête suivante détecte les connexions de toute nouvelle adresse IP source à un sous-réseau donné en analysant les journaux de flux VPC. Dans cet exemple, une adresse IP source est considérée comme nouvelle si elle a été vue pour la première fois au cours des dernières 24 heures sur une période d'analyse de 60 jours. Vous pouvez utiliser et ajuster cette requête sur un sous-réseau soumis à une exigence de conformité particulière, telle que la norme PCI.
Analyse de journaux
BigQuery
Des connexions bloquées par Google Cloud Armor ?
La requête suivante permet de détecter les tentatives d'exploitation potentielles en analysant les journaux d'équilibrage de charge d'application externes pour détecter toute connexion bloquée par la règle de sécurité configurée dans Google Cloud Armor. Cette requête suppose que vous avez configuré une règle de sécurité Google Cloud Armor sur votre équilibrage de charge d'application externe. Nous supposons également que vous avez activé la journalisation de l'équilibrage de charge d'application externe, comme décrit dans les instructions fournies par le lien Activer dans l'outil de champ d'application des journaux.
Analyse de journaux
BigQuery
Un virus ou un logiciel malveillant de gravité élevée détecté par Cloud IDS ?
La requête suivante affiche les virus ou logiciels malveillants de gravité élevée éventuellement détectés par Cloud IDS en effectuant une recherche dans les journaux de menaces Cloud IDS. Dans cette requête, nous partons du principe que vous avez un point de terminaison Cloud IDS configuré.
Analyse de journaux
BigQuery
Quels sont les principaux domaines Cloud DNS interrogés à partir de votre réseau VPC ?
La requête suivante répertorie les 10 principaux domaines Cloud DNS interrogés depuis votre ou vos réseaux VPC au cours des 60 derniers jours. Cette requête suppose que vous avez activé la journalisation Cloud DNS pour vos réseaux VPC, comme décrit dans les instructions fournies par le lien Activer dans l'outil de champ d'application des journaux.
Analyse de journaux
BigQuery
Étapes suivantes
Découvrez comment diffuser des journaux depuis Google Cloud vers Splunk.
Ingérer des journaux Google Cloud dans Google Security Operations
Exporter des données de sécurité Google Cloud vers votre système SIEM
Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.