Cloud Run è una piattaforma di computing gestita che ti consente di eseguire container direttamente sull'infrastruttura scalabile di Google.
Puoi eseguire il deployment su Cloud Run di codice scritto in qualsiasi linguaggio di programmazione se puoi creare un'immagine container. Infatti, la creazione di immagini container è facoltativa. Se usi Go, Node.js, Python, Java, .NET, Ruby o un framework supportato, puoi utilizzare l'opzione di deployment basato sull'origine, che crea il container per te, usando le best practice per il linguaggio che stai utilizzando.
Google ha creato Cloud Run per funzionare bene con altri servizi su Google Cloud, in modo da poter creare applicazioni complete.
In breve, Cloud Run consente agli sviluppatori di dedicare il proprio tempo alla scrittura del codice e di dedicare pochissimo tempo al funzionamento, alla configurazione e allo scaling del servizio Cloud Run. Non devi creare un cluster o gestire l'infrastruttura per essere produttivo con Cloud Run.
Servizi, job e pool di worker: tre modi per eseguire il codice
Su Cloud Run, il codice può essere eseguito come servizio, job o pool di worker. Tutti questi tipi di risorse vengono eseguiti nello stesso ambiente e possono utilizzare le stesse integrazioni con altri servizi su Google Cloud.
La tabella seguente fornisce una panoramica generale delle opzioni fornite da ciascun tipo di risorsa Cloud Run.
| Risorsa | Descrizione |
|---|---|
| Servizio | Risponde alle richieste HTTP inviate a un endpoint univoco e stabile, utilizzando istanze effimere e stateless che vengono scalate automaticamente in base a una serie di metriche chiave. Risponde anche a eventi e funzioni. |
| Job | Gestisce le attività parallelizzabili non basate su richieste che vengono eseguite manualmente o in base a una pianificazione e vengono completate. |
| Pool di worker | Gestisce i workload non basati su richieste, come i workload basati su pull, ad esempio i consumer Kafka, le code pull Pub/Sub o i consumer RabbitMQ. |
Servizi Cloud Run
Un servizio Cloud Run ti fornisce l'infrastruttura necessaria per eseguire un endpoint HTTPS affidabile. È tua responsabilità assicurarti che il codice sia in ascolto su una porta TCP e gestisca le richieste HTTP.
Il seguente diagramma mostra un servizio Cloud Run che esegue diverse istanze container per gestire richieste ed eventi web dal client utilizzando un endpoint HTTPS.

Un servizio standard include le seguenti funzionalità:
- Endpoint HTTPS univoco per ogni servizio
- Ogni servizio Cloud Run ha un endpoint HTTPS su un sottodominio univoco del dominio
*.run.appe puoi configurare anche domini personalizzati. Cloud Run gestisce TLS per te e supporta WebSocket, HTTP/2 (end-to-end) e gRPC (end-to-end). - Scalabilità automatica rapida basata sulle richieste
- Cloud Run esegue rapidamente lo scale out per gestire tutte le richieste in entrata o per gestire l'aumento dell'utilizzo della CPU al di fuori delle richieste se l'impostazione di fatturazione è impostata sulla fatturazione basata sulle istanze. Un servizio può essere scalato rapidamente fino a 1000 istanze o anche di più se richiedi un aumento della quota. Se la domanda diminuisce, Cloud Run rimuove i container inattivi. Se ti preoccupano i costi o il sovraccarico dei sistemi downstream, puoi limitare il numero massimo di istanze.
- Scalabilità manuale facoltativa
- Per impostazione predefinita, Cloud Run esegue automaticamente lo scale up a più istanze per gestire più traffico, ma puoi ignorare questo comportamento utilizzando lo scaling manuale per controllare il comportamento di scaling.
- Gestione del traffico integrata
Per ridurre il rischio di deployment di una nuova revisione, Cloud Run supporta l'esecuzione di un rollout graduale, incluso il routing del traffico in entrata all'ultima revisione, il rollback a una revisione precedente e la divisione del traffico in più revisioni contemporaneamente.
Ad esempio, puoi iniziare inviando l'1% delle richieste a una nuova revisione e aumentare questa percentuale monitorando la telemetria.
- Servizi pubblici e privati
Un servizio Cloud Run può essere raggiungibile da internet oppure puoi limitare l'accesso nei seguenti modi:
- Specifica un criterio di accesso utilizzando Cloud IAM.
- Utilizza le impostazioni di ingresso per limitare l'accesso alla rete. Questa opzione è utile se vuoi consentire solo il traffico interno dal VPC e dai servizi interni.
- Consenti solo utenti autenticati con Identity-Aware Proxy (IAP).
Puoi pubblicare asset memorizzabili nella cache da una località edge più vicina ai client anteponendo un servizio Cloud Run a una rete CDN (Content Delivery Network), come Firebase Hosting e Cloud CDN.
Scalabilità fino a zero e istanze minime
Per impostazione predefinita, se la fatturazione è impostata sulla fatturazione basata sulle istanze, Cloud Run aggiunge e rimuove automaticamente le istanze per gestire tutte le richieste in entrata o per gestire l'aumento dell'utilizzo della CPU al di fuori delle richieste.
Se non ci sono richieste in entrata al tuo servizio, verrà rimossa anche l'ultima istanza rimanente. Questo comportamento è comunemente chiamato scalabilità a zero. Poi, se non ci sono istanze attive quando arriva una richiesta, Cloud Run ne crea una nuova. Ciò aumenta il tempo di risposta per queste prime richieste, a seconda della velocità con cui il container diventa pronto a gestire le richieste.
Per modificare questo comportamento, utilizza uno dei seguenti metodi:
- Configura Cloud Run in modo che mantenga attivo un numero minimo di istanze, in modo che il servizio non venga scalato a zero istanze
- Utilizza lo scaling manuale per un maggiore controllo dello scaling.
Prezzi a consumo per i servizi
Lo scale to zero è interessante per motivi economici, in quanto ti viene addebitato l'utilizzo di CPU e memoria allocati a un'istanza con una granularità di 100 ms. Se non configuri le istanze minime, non ti vengono addebitati costi se il servizio non viene utilizzato. È disponibile un generoso livello gratuito. Per ulteriori informazioni, consulta la pagina Prezzi.
Puoi attivare due impostazioni di fatturazione:
- Basata sulle richieste
- Se un'istanza non elabora richieste, non ti viene addebitato alcun costo. Paghi una tariffa per richiesta.
- Basata sulle istanze
- Ti vengono addebitati i costi per l'intera durata di un'istanza. Non è prevista alcuna tariffa per richiesta.
È disponibile un generoso livello gratuito. Per saperne di più, consulta la sezione Prezzi e la sezione Impostazioni di fatturazione per scoprire come attivare la fatturazione basata sulle richieste o sulle istanze per il tuo servizio.
Un file system contenitore usa e getta
Le istanze su Cloud Run sono usa e getta. Ogni container ha un overlay del file system scrivibile in memoria, che non viene mantenuto se il container viene chiuso. Cloud Run determina quando interrompere l'invio di richieste a un'istanza e arrestarla, ad esempio durante lo scale down.
Per ricevere un avviso quando Cloud Run sta per arrestare un'istanza,
la tua applicazione può intercettare il segnale SIGTERM. In questo modo, il codice può svuotare
i buffer locali e rendere persistenti i dati locali in un datastore esterno.
Per rendere permanenti i file, esegui l'integrazione con Cloud Storage o monta un file system di rete (NFS).
Quando utilizzare i servizi Cloud Run
I servizi Cloud Run sono ideali per il codice che gestisce richieste, eventi o funzioni. Esempi di casi d'uso:
- Siti web e applicazioni web
- Crea la tua app web utilizzando il tuo stack preferito, accedi al tuo database SQL ed esegui il rendering di pagine HTML dinamiche.
- API e microservizi
- Puoi creare un'API REST, un'API GraphQL o microservizi privati che comunicano tramite HTTP o gRPC.
- Elaborazione dei flussi di dati
- I servizi Cloud Run possono ricevere messaggi da sottoscrizioni push di Pub/Sub ed eventi da Eventarc.
- Workload asincroni Le
- funzioni Cloud Run possono rispondere a eventi asincroni, come un messaggio in un argomento Pub/Sub, una modifica in un bucket Cloud Storage o un evento Firebase.
- Inferenza AI
- I servizi Cloud Run, con o senza GPU configurata, possono ospitare carichi di lavoro di AI come modelli di inferenza e addestramento dei modelli.
Job Cloud Run
Se il tuo codice esegue un lavoro e poi si arresta, ad esempio utilizzando uno script, puoi utilizzare un job Cloud Run per eseguire il codice. Puoi eseguire un job dalla riga di comando utilizzando Google Cloud CLI, pianificando un job ricorrente o eseguendolo nell'ambito di un flusso di lavoro.
I job array sono un modo più veloce per eseguire i job
Un job può avviare una singola istanza per eseguire il codice, un modo comune per eseguire uno script o uno strumento.
Tuttavia, puoi anche utilizzare un job array, avviando in parallelo molte istanze identiche e indipendenti. I job array sono un modo più rapido per elaborare i job che possono essere suddivisi in più attività indipendenti.
Il seguente diagramma mostra come un job con sette attività richiede più tempo per essere eseguito in sequenza rispetto allo stesso job quando quattro istanze possono elaborare attività indipendenti in parallelo:

Ad esempio, se ridimensioni e ritagli 1000 immagini da Cloud Storage, l'elaborazione consecutiva è più lenta rispetto all'elaborazione in parallelo con molte istanze, con Cloud Run che gestisce lo scale up automatico.
Quando utilizzare i job Cloud Run
I job Cloud Run sono adatti per eseguire codice che svolge un lavoro (un job) e termina quando il lavoro è completato. Ecco alcuni esempi:
- Script o strumento
- Esegui uno script per eseguire migrazioni di database o altre attività operative.
- Job array
- Esegui l'elaborazione altamente parallelizzata di tutti i file in un bucket Cloud Storage.
- Job pianificato
- Crea e invia fatture a intervalli regolari oppure salva i risultati di una query del database come XML e carica il file ogni poche ore.
- Workload AI
- I job Cloud Run con o senza GPU configurata possono ospitare carichi di lavoro di AI come l'inferenza batch, il perfezionamento dei modelli e l'addestramento dei modelli.
Pool di worker Cloud Run
I pool di worker sono progettati per i workload che non si basano sulla gestione delle richieste HTTP. Forniscono un pool flessibile e scalabile di risorse di calcolo progettato per l'elaborazione in background continua, non HTTP e basata sul pull. Le seguenti caratteristiche chiave definiscono il funzionamento dei pool di worker:
I pool di worker non vengono scalati automaticamente. Scala manualmente il numero di istanze richieste dal pool di worker Cloud Run per gestire il carico di lavoro. Per essere avviato e rimanere attivo, il tuo workload deve avere almeno un'istanza. Se imposti le istanze minime su
0, l'istanza worker non si avvierà, anche se il deployment è riuscito.Per regolare dinamicamente le istanze in base alla domanda in tempo reale, crea il tuo gestore della scalabilità automatica. Per un esempio, consulta Scalare automaticamente i carichi di lavoro del consumer Kafka.
I pool di worker gestiscono le implementazioni dividendo le istanze tra le revisioni, anziché dividere il traffico. Ad esempio, per un pool di worker con quattro istanze, puoi allocare il 25% (un'istanza) a una nuova revisione e il 75% (tre istanze) a una revisione stabile.
I pool di worker non hanno un endpoint o un URL con bilanciamento del carico.
Cloud Run addebita solo la durata di esecuzione delle istanze del pool di worker.
Quando utilizzare i pool di worker Cloud Run
I pool di worker non richiedono endpoint HTTP pubblici. In questo modo la tua rete è più sicura e il codice dell'applicazione è più semplice. Inoltre, non devi gestire le porte per i controlli di integrità. I seguenti casi d'uso si applicano ai pool di worker:
Carichi di lavoro basati sul pull: esegui il deployment di un carico di lavoro per estrarre i messaggi da una coda per la gestione. Ad esempio, Kafka Consumer, Pub/Sub pull e RabbitMQ.
Il seguente diagramma mostra i casi d'uso per il deployment di pool di worker per workload basati sul pull:
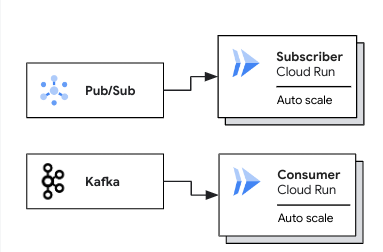
In un caso d'uso di Pub/Sub, un sottoscrittore Cloud Run con scalabilità automatica estrae i messaggi da una sottoscrizione Pub/Sub. In un caso d'uso di Kafka, un consumer Cloud Run con scalabilità automatica recupera i messaggi da un argomento Kafka.
Workload generici non basati su richieste: esegui un workload basato su container che non è destinato a gestire le richieste in entrata.
Google Cloud integrazioni
Cloud Run si integra con l'ecosistema più ampio di Google Cloud, che ti consente di creare applicazioni complete.
Le integrazioni essenziali includono:
- Archiviazione dei dati
- Cloud Run si integra con Cloud SQL (MySQL, PostgreSQL e SQL Server gestiti), Memorystore (Redis e Memcached gestiti), Firestore, Spanner, Cloud Storage e altro ancora. Per un elenco completo, consulta Archiviazione dei dati.
- Logging e segnalazione degli errori
- Cloud Logging importa automaticamente i log dei container. Se nei log sono presenti eccezioni, Error Reporting le aggrega e ti invia una notifica. Sono supportati i seguenti linguaggi: Go, Java, Node.js, PHP, Python, Ruby e .NET.
- Identità di servizio
- Ogni revisione di Cloud Run è collegata a un service account e le librerie client Google Cloud utilizzano in modo trasparente questo account di servizio per l'autenticazione con le API Google Cloud .
- Distribuzione continua
- Se memorizzi il codice sorgente in GitHub, Bitbucket o Cloud Source Repositories, puoi configurare Cloud Run per eseguire automaticamente il deployment dei nuovi commit.
- Networking privato
- Le istanze Cloud Run possono raggiungere le risorse nella rete Virtual Private Cloud tramite il connettore di accesso VPC serverless. In questo modo il tuo servizio può connettersi alle macchine virtuali Compute Engine o ai prodotti basati su Compute Engine come Google Kubernetes Engine o Memorystore.
- Google Cloud API
- Il codice del tuo servizio esegue l'autenticazione in modo trasparente con le Google Cloud API. Sono incluse le API AI e Machine Learning, come l'API Cloud Vision, l'API Speech-to-Text, l'API AutoML Natural Language, l'API Cloud Translation e molte altre.
- Attività in background
- Puoi programmare l'esecuzione del codice in un secondo momento o immediatamente dopo la restituzione di una richiesta web. Cloud Run funziona bene con Cloud Tasks per fornire un'esecuzione asincrona scalabile e affidabile.
Consulta la sezione Connessione ai servizi per un elenco dei numerosi servizi che funzionano bene con Cloud Run. Google Cloud Google Cloud
Il codice deve essere pacchettizzato in un'immagine container
Affinché il servizio, il job o il pool di worker possa essere sottoposto a deployment su Cloud Run, devi pacchettizzarlo in un'immagine container. Se non hai familiarità con i container, ecco una breve introduzione concettuale.

Come mostra il diagramma, utilizzi il codice sorgente, gli asset e le dipendenze della libreria per creare l'immagine container, che è un pacchetto con tutto ciò che serve al tuo servizio per essere eseguito. Sono inclusi artefatti di build, asset, pacchetti di sistema e (facoltativamente) un runtime. Ciò rende un'applicazione containerizzata intrinsecamente portatile: viene eseguita ovunque possa essere eseguito un container. Esempi di artefatti di build includono file binari o script compilati, mentre esempi di runtime sono il runtime JavaScript Node.js o una macchina virtuale Java (JVM).
I professionisti esperti apprezzano il fatto che Cloud Run non imponga ulteriori oneri per l'esecuzione del codice: puoi eseguire qualsiasi binario su Cloud Run.
Se vuoi maggiore praticità o vuoi delegare a Google la containerizzazione della tua applicazione, Cloud Run si integra con i buildpack open source di Google Cloud per offrire un deployment basato sull'origine.
Passaggi successivi
- Esegui il deployment di un servizio Cloud Run
- Crea ed esegui un job Cloud Run
- Scopri come eseguire i job in base a una pianificazione
- Esegui il deployment di un worker pool
- Esplora il modello di risorse
- Scopri di più sul contratto di runtime del container