このページでは、用語、Tensor Processing Unit(TPU)のメリット、ワークロードのスケジューリングに関する考慮事項を含め、Google Kubernetes Engine(GKE)での Cloud TPU の動作について説明します。TPU は、TensorFlow、PyTorch、JAX などのフレームワークを使用する ML ワークロードの高速化のために、Google が独自に開発した特定用途向け集積回路(ASIC)です。
このページは、大規模、長時間実行、行列計算が大半を占めるなどの特性を持つ ML モデルを実行するプラットフォーム管理者、運用担当者、データ スペシャリスト、AI スペシャリストを対象としています。 Google Cloudのコンテンツで使用されている一般的なロールとタスクの例について詳しくは、一般的な GKE ユーザー ロールとタスクをご覧ください。
このページを読む前に、ML アクセラレータの仕組みを理解しておいてください。詳細については、Cloud TPU の概要をご覧ください。
GKE で TPU を使用するメリット
GKE は、TPU VM の作成、構成、削除など、TPU ノードとノードプールのライフサイクル管理全体をサポートしています。GKE は、Spot VM と予約済み Cloud TPU の使用もサポートしています。詳細については、Cloud TPU の使用オプションをご覧ください。
GKE で TPU を使用するメリットは次のとおりです。
- 一貫性のある運用環境: 1 つのプラットフォームで、すべての ML とその他のワークロードに対応できます。
- 自動アップグレード: GKE はバージョンの更新を自動化し、運用上のオーバーヘッドを削減します。
- ロード バランシング: GKE は負荷を分散するため、レイテンシが短縮され、信頼性が向上します。
- レスポンシブなスケーリング: GKE は、ワークロードのニーズに合わせて TPU リソースを自動的にスケーリングします。
- リソース管理: Kubernetes ネイティブのジョブ キューイング システムである Kueue により、キューイング、プリエンプション、優先順位付け、公平な共有を使用して組織内の複数のテナントのリソースを管理できます。
- サンドボックス化オプション: GKE Sandbox は、gVisor を使用してワークロードを保護します。詳細については、GKE Sandbox をご覧ください。
TPU Trillium を使用するメリット
Trillium は Google の第 6 世代 TPU です。Trillium には次のようなメリットがあります。
- Trillium は、TPU v5e と比較してチップあたりのコンピューティング パフォーマンスを向上させます。
- Trillium では、高帯域幅メモリ(HBM)の容量と帯域幅が増加し、TPU v5e よりもチップ間相互接続(ICI)の帯域幅も増加しています。
- Trillium には第 3 世代の SparseCore が搭載されています。これは、高度なランキングやレコメンデーションのワークロードでよくある極めて大規模なエンベディングを処理するための、特別なアクセラレータです。
- Trillium のエネルギー効率は TPU v5e より 67% 以上向上しています。
- Trillium は、高帯域幅かつ低レイテンシの単一の TPU スライス内で 256 TPU までスケールアップできます。
- Trillium はコレクション スケジューリングをサポートしています。コレクション スケジューリングを使用すると、TPU のグループ(単一ホスト TPU スライス ノードプールとマルチホスト TPU スライス ノードプール)を宣言して、推論ワークロードの需要に応じた高可用性を確保できます。
API やログなどのすべての技術的な側面と、GKE ドキュメントの特定の部分では、Trillium TPU を表すために v6e または TPU Trillium(v6e)を使用しています。Trillium のメリットについて詳しくは、Trillium のお知らせに関するブログ投稿をご覧ください。TPU の設定を開始するには、GKE で TPU を計画するをご覧ください。
GKE の TPU に関連する用語
このページでは、TPU に関連する次の用語を使用します。
- TPU タイプ: Cloud TPU タイプ(v5e など)。
- TPU スライスノード: 相互接続された 1 つ以上の TPU チップを備えた単一の VM で表される Kubernetes ノード。
- TPU スライス ノードプール: クラスタ内の Kubernetes ノードのグループ。すべて同じ TPU 構成です。
- TPU トポロジ: TPU スライス内の TPU チップの数と物理配置。
- アトミック: GKE は、相互接続されたすべてのノードを単一のユニットとして扱います。スケーリング オペレーション中、GKE はノードセット全体を 0 にスケーリングし、新しいノードを作成します。グループ内のマシンに障害または停止が発生した場合、GKE はノードセット全体を新しいユニットとして再作成します。
- 変更不可: 相互接続されたノードのセットに新しいノードを手動で追加することはできません。ただし、目的の TPU トポロジを持つ新しいノードプールを作成し、新しいノードプールでワークロードをスケジュールできます。
TPU スライス ノードプールのタイプ
GKE は、次の 2 種類の TPU ノードプールをサポートしています。
TPU のタイプとトポロジによって、TPU スライスノードをマルチホストまたは単一ホストのいずれとして設定できるかが決まります。次のように設定することをおすすめします。
- 大規模モデルの場合は、マルチホスト TPU スライスノードを使用します。
- 小規模モデルの場合は、単一ホストの TPU スライスノードを使用します。
- 大規模なトレーニングや推論には、Pathways を使用します。Pathways は、単一の JAX クライアントで複数の大規模な TPU スライスにまたがるワークロードをオーケストレートすることで、大規模な ML 計算を簡素化します。詳細については、Pathways をご覧ください。
マルチホスト TPU スライス ノードプール
マルチホスト TPU スライスのノードプールは、相互接続された 2 つ以上の TPU VM を含むノードプールです。各 VM には TPU デバイスが接続されています。マルチホスト TPU スライスの TPU は、高速相互接続(ICI)を介して接続されます。マルチホスト TPU スライスのノードプールを作成した後に、ノードを追加することはできません。たとえば、v4-32 ノードプールを作成してから、後でこのノードプールに Kubernetes ノード(TPU VM)を追加することはできません。GKE クラスタに TPU スライスを追加するには、新しいノードプールを作成する必要があります。
マルチホスト TPU スライスのノードプール内の VM は、単一のアトミック単位として扱われます。GKE がスライスに 1 つのノードをデプロイできない場合、TPU スライスノードにノードはデプロイされません。
マルチホスト TPU スライス内のノードを修復する必要がある場合、GKE は TPU スライス内のすべての VM をシャットダウンし、ワークロード内のすべての Kubernetes Pod を強制的に排除します。TPU スライスのすべての VM が稼働したら、Kubernetes Pod により、新しい TPU スライスの VM でスケジュールが可能となります。
次の図は、v5litepod-16(v5e)マルチホスト TPU スライスを示しています。この TPU スライスには 4 つの VM があります。TPU スライスの各 VM には、高速相互接続(ICI)で接続された 4 つの TPU v5e チップがあり、各 TPU v5e チップには 1 つの TensorCore があります。
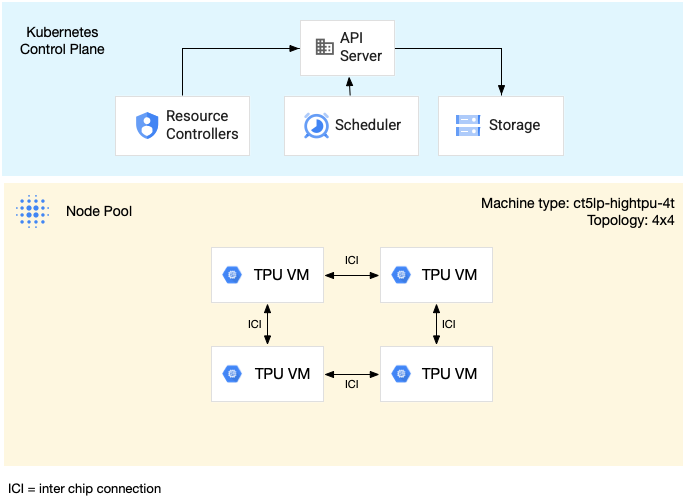
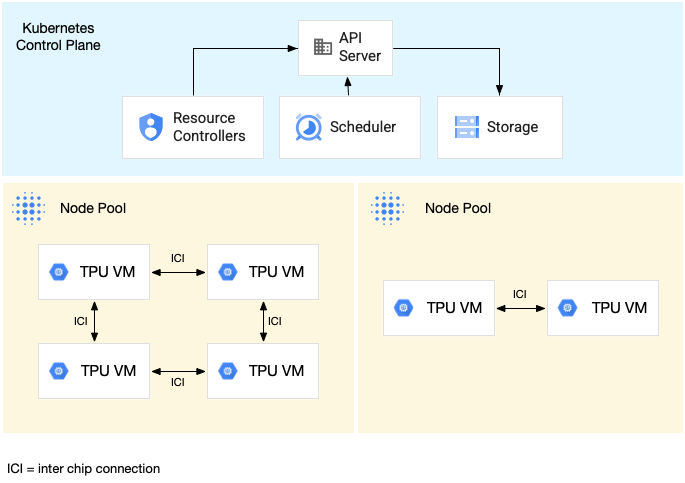
次の図は、1 つの TPU v5litepod-16(v5e)TPU スライス(トポロジ: 4x4)と 1 つの TPU v5litepod-8(v5e)スライス(トポロジ: 2x4)を含む GKE クラスタを示しています。
単一ホスト TPU スライス ノードプール
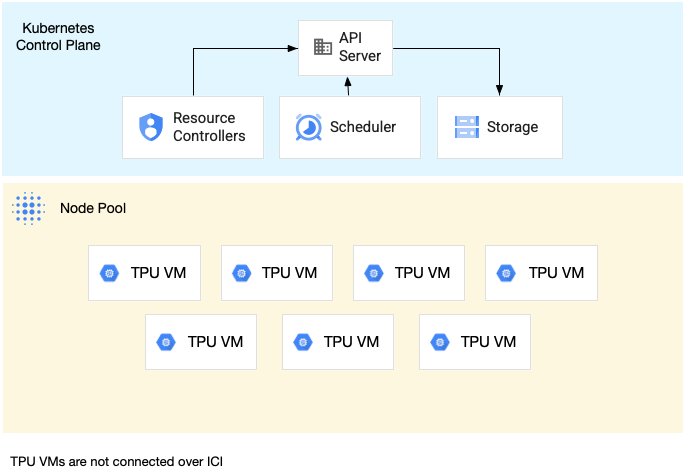
単一ホストスライスのノードプールは、1 つ以上の独立した TPU VM を含むノードプールです。各 VM には TPU デバイスが接続されています。単一ホストスライスのノードプール内の VM はデータセンター ネットワーク(DCN)を介して通信できますが、VM に接続された TPU は相互接続されません。
次の図は、7 つの v4-8 マシンを含む単一ホストの TPU スライスの例を示しています。
GKE の TPU の特性
TPU には、特別な計画と構成が必要な独自の特性があります。
TPU 使用率
ワークロードのパフォーマンスのバランスを取りながら、リソースの使用率と費用を最適化するために、GKE は次の TPU 使用オプションをサポートしています。
- Flex Start: 最大 7 日間 Flex Start VM をプロビジョニングします。GKE は、可用性に基づいてベスト エフォートでハードウェアを自動的に割り当てます。詳細については、Flex Start プロビジョニング モードでの GPU と TPU のプロビジョニングについてをご覧ください。
- Spot VM: Spot VM をプロビジョニングすると、大幅な割引が適用されます。ただし、Spot VM はいつでもプリエンプトされる可能性があります(30 秒前に警告が表示されます)。詳細については、Spot VM をご覧ください。
- 最大 90 日間の将来の予約(カレンダー モード): 指定した期間に最大 90 日間 TPU リソースをプロビジョニングします。詳細については、カレンダー モードの将来の予約で TPU をリクエストするをご覧ください。
- TPU 予約: 1 年以上の将来の予約をリクエストします。
ワークロードの要件を満たす使用オプションを選択するには、GKE での AI/ML ワークロードのアクセラレータ使用オプションについてをご覧ください。
GKE で TPU を使用する前に、ワークロードの要件に最適な消費オプションを選択します。
トポロジ
トポロジでは、TPU スライス内の TPU の物理的な配置を定義します。GKE は、TPU のバージョンに応じて、2 次元または 3 次元のトポロジで TPU スライスをプロビジョニングします。トポロジは、次のように各ディメンションの TPU チップの数として指定します。
マルチホストの TPU スライスのノードプールにスケジュールされる TPU v4 と v5p の場合、トポロジを 3 タプル({A}x{B}x{C})で定義します(例: 4x4x4)。{A}x{B}x{C} の積で、ノードプール内のチップ数が定義されます。たとえば、2x2x2、2x2x4、2x4x4 などのトポロジ フォームを使用して、64 個未満の TPU チップを持つ小さなトポロジを定義できます。64 個を超える TPU チップを持つ大きなトポロジを使用する場合、{A}、{B}、{C} に割り当てる値は、次の条件を満たしている必要があります。
- {A}、{B}、{C} は 4 の倍数にする必要があります。
- v4 でサポートされている最大のトポロジは
12x16x16で、v5p は16x16x24です。 - 割り当てられた値は、A ≤ B ≤ C の関係を維持する必要があります。たとえば、
4x4x8や、8x8x8です。
マシンタイプ
TPU リソースをサポートするマシンタイプは、TPU のバージョンとノードスライスあたりの TPU チップ数(ct<version>-hightpu-<node-chip-count>t など)を含む命名規則に従います。たとえば、マシンタイプ ct5lp-hightpu-1t は TPU v5e をサポートし、1 つの TPU チップのみを使用します。
特権モード
1.28 より前の GKE バージョンを使用している場合は、TPU にアクセスするための特別な機能を使用してコンテナを構成する必要があります。Standard モードクラスタでは、特権モードを使用してこのアクセス権を付与できます。特権モードは、securityContext の他のセキュリティ設定の多くをオーバーライドします。詳細については、特権モードなしでコンテナを実行するをご覧ください。
バージョン 1.28 以降では、特権モードや特別な機能は必要ありません。
GKE での TPU の仕組み
Kubernetes のリソース管理と優先度では、TPU 上の VM は他の VM タイプと同じように扱われます。TPU チップをリクエストするには、リソース名 google.com/tpu を使用します。
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
GKE で TPU を使用する場合は、次の TPU 特性を考慮してください。
- VM は最大 8 個の TPU チップにアクセスできます。
- TPU スライスには、選択した TPU マシンタイプに応じて一定数の TPU チップが含まれます。
- リクエストする
google.com/tpuの数は、TPU スライスノードで使用可能な TPU チップの合計数と同じにする必要があります。TPU をリクエストする GKE Pod 内のコンテナは、ノード内のすべての TPU チップを使用する必要があります。そうしないと Deployment が失敗します。GKE では TPU リソースを部分的に使用することはできません。次のようなシナリオを考えてみましょう。2x4トポロジのマシンタイプct5lp-hightpu-4tには、それぞれ 4 個の TPU チップを持つ 2 つの TPU スライスノード(合計 8 個の TPU チップ)があります。このマシンタイプの要件は次のとおりです。- このノードプールのノードに、8 個の TPU チップを必要とする GKE Pod をデプロイすることはできません。
- それぞれ 4 個の TPU チップを必要とする 2 つの Pod をデプロイできます。各 Pod は、このノードプール内の 2 つのノードのいずれかにデプロイできます。
- トポロジ 4x4 の TPU v5e には、4 つのノードに 16 個の TPU チップがあります。この構成を選択する GKE Autopilot ワークロードは、レプリカごとに 4 つの TPU チップをリクエストする必要があります(1~4 つのレプリカ)。
- Standard クラスタでは、1 つの VM に複数の Kubernetes Pod をスケジュールできますが、TPU チップにアクセスできるのは各 Pod の 1 つのコンテナのみです。
- kube-dns などの kube-system Pod を作成するには、各 Standard クラスタに TPU 以外のスライス ノードプールが少なくとも 1 つ必要です。
- デフォルトでは、TPU スライスノードには
google.com/tputaint が設定されているため、TPU 以外のワークロードが TPU スライスノードでスケジュールされません。TPU を使用しないワークロードは TPU 以外のノードで実行されるため、TPU を使用するコードの TPU スライスノードのコンピューティングが解放されます。taint は、TPU リソースが完全に使用されることを保証するものではありません。 - GKE は、TPU スライスノードで実行されているコンテナから出力されたログを収集します。詳細については、ロギングをご覧ください。
- ランタイム パフォーマンスなどの TPU 使用率の指標は Cloud Monitoring で利用できます。詳細については、オブザーバビリティと指標をご覧ください。
- GKE Sandbox を使用して TPU ワークロードをサンドボックスで処理できます。GKE Sandbox は、TPU モデル v4 以降で動作します。詳細については、GKE Sandbox をご覧ください。
コレクション スケジューリングの仕組み
TPU Trillium では、コレクション スケジューリングを使用して TPU スライスノードをグループ化できます。これらの TPU スライスノードをグループ化すると、ワークロードの需要に合わせてレプリカの数を簡単に調整できます。 Google Cloud はソフトウェア アップデートを制御し、コレクション内に十分なスライスが常にあり、トラフィックの処理に使用できるようにします。
TPU Trillium は、推論ワークロードを実行する単一ホスト ノードプールとマルチホスト ノードプールのコレクション スケジューリングをサポートしています。次の表に示すのは、コレクション スケジューリング動作が使用する TPU スライスのタイプにどのように依存するかです。
- マルチホスト TPU スライス: GKE はマルチホスト TPU スライスをグループ化してコレクションを形成します。各 GKE ノードプールは、このコレクション内のレプリカです。コレクションを定義するには、マルチホスト TPU スライスを作成し、コレクションに一意の名前を割り当てます。コレクションに TPU スライスを追加するには、同じコレクション名とワークロード タイプを持つ別のマルチホスト TPU スライス ノードプールを作成します。
- 単一ホストの TPU スライス: GKE は、単一ホストの TPU スライス ノードプール全体をコレクションと見なします。コレクションに TPU スライスを追加するには、単一ホストの TPU スライス ノードプールのサイズを変更します。
コレクション スケジューリングには次の制限があります。
- スケジュールできるのは TPU Trillium のコレクションのみです。
- コレクションを定義できるのは、ノードプールの作成時のみです。
- Spot VM はサポートされていません。
- マルチホスト TPU スライス ノードプールを含むコレクションでは、コレクション内のすべてのノードプールで同じマシンタイプ、トポロジ、バージョンを使用する必要があります。
コレクション スケジュールリングは、次のシナリオで構成できます。
- GKE Standard で TPU スライス ノードプールを作成する場合
- GKE Autopilot にワークロードをデプロイする場合
- ノードの自動プロビジョニングを有効にしてクラスタを作成する場合
次のステップ
GKE で Cloud TPU を設定する方法については、次のリソースをご覧ください。
- GKE で TPU を計画する。TPU の設定を開始します。
- GKE Autopilot に TPU ワークロードをデプロイする
- GKE Standard に TPU ワークロードをデプロイする
- ML タスクで Cloud TPU を使用する際のベスト プラクティスを確認する
- 動画: GKE を使用して Cloud TPU で大規模な ML を構築する
- TPU で KubeRay を使用して大規模言語モデルを提供する
- GKE Sandbox での GPU ワークロードのサンドボックス化について学習する