用語集を使用して、ドメイン固有の用語を定義できます。用語集を使用すると、移行元言語と移行先言語の用語を含む用語のペアを追加できます。用語ペアを使用すると、Vertex AI Translation サービスで用語が常に一貫して翻訳されます。
用語集エントリを定義できるケースの例を次に示します。
- 商品名: 翻訳で保持する商品名を特定します。たとえば、Google Home は Google Home に翻訳する必要があります。
- 曖昧な単語: 曖昧な単語や同音異義語の意味を指定します。たとえば、「bat」という単語は、スポーツ用品のバット、または動物のコウモリを意味します。
- 外来語: 別の言語から採用された単語の意味を明確にします。たとえば、フランス語の bouillabaisse は、英語では魚介類の煮込み料理である bouillabaisse に翻訳されます。
用語集には、単語(トークンとも呼ばれます)または短いフレーズ(通常は 5 単語未満)が登録されています。単語がストップワードの場合、Vertex AI Translation は一致する用語集エントリを無視します。
Vertex AI Translation には、Google Distributed Cloud(GDC)エアギャップで利用可能な次の用語集メソッドが用意されています。
| メソッド | 説明 |
|---|---|
CreateGlossary |
用語集を作成します。 |
GetGlossary |
保存された用語集を返します。 |
ListGlossaries |
プロジェクト内の用語集 ID のリストを返します。 |
DeleteGlossary |
不要になった用語集を削除します。 |
始める前に
翻訳用語を定義する用語集を作成する前に、translation-glossary-project という名前のプロジェクトが必要です。プロジェクトのカスタム リソースは次の例のようになります。
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
用語集の使用に必要な権限を取得するには、プロジェクトの IAM 管理者に、プロジェクトの Namespace で次のロールを付与するよう依頼してください。
- AI Translation デベロッパー: Vertex AI Translation サービスにアクセスするには、AI Translation デベロッパー(
ai-translation-developer)ロールを取得します。 - プロジェクト バケット管理者: プロジェクト バケット管理者(
project-bucket-admin)ロールを取得して、バケット内のストレージ バケットとオブジェクトを管理します。これにより、ファイルの作成とアップロードが可能になります。
前提条件の詳細については、翻訳プロジェクトを設定するをご覧ください。
用語集ファイルを作成する
ソース言語とターゲット言語の用語を保存する用語集ファイルを作成する必要があります。このセクションでは、用語の定義に使用できる 2 つの異なる用語集レイアウトについて説明します。
次の表は、Distributed Cloud でサポートされている用語集ファイルの上限を示しています。
| 説明 | 上限 |
|---|---|
| 最大ファイルサイズ | 1,040 万(10,485,760)UTF-8 バイト |
| 用語集の用語の最大文字数 | 1,024 UTF-8 バイト |
| 1 プロジェクトに使用できる用語集リソースの最大数 | 10,000 |
用語集ファイルに次のいずれかのレイアウトを選択します。
- 単一方向の用語集: 特定の言語のソース用語とターゲット用語のペアに対して、期待される翻訳を指定します。単方向用語集は、TSV、CSV、TMX のファイル形式をサポートしています。
- 多言語の用語セットの用語集: 各行に複数の言語で期待される翻訳を指定します。多言語の用語セットの用語集は、CSV ファイル形式をサポートしています。
単一言語ペアの用語集
Vertex AI Translation API は、タブ区切り値(TSV)とカンマ区切り値(CSV)を受け入れます。これらのファイル形式の場合、各行には 1 つのタブ(\t)またはカンマ(,)で区切られた用語のペアが含まれます。
Vertex AI Translation API は、Translation Memory eXchange(TMX)形式も受け入れます。これは、翻訳の原文と訳文の用語ペアを提供する標準的な XML 形式です。サポートされている入力ファイルは、TMX バージョン 1.4 に基づく形式です。
次の例は、一方向の用語集の TSV、CSV、TMX ファイル形式に必要な構造を示しています。
TSV と CSV
次の画像は、TSV ファイルまたは CSV ファイルの 2 つの列を示しています。最初の列にはソース言語の用語が、2 番目の列にはターゲット言語の用語が含まれます。

用語集ファイルを作成するときに、ヘッダー行を定義できます。用語集リクエストにより、Vertex AI Translation API でファイルを使用できるようになります。
TMX
次の例は、TMX ファイルに必要な構造を示しています。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
この例に示されていない XML タグがファイルに含まれている場合、Vertex AI Translation API はそれらのタグを無視します。
Vertex AI Translation API での処理を確実に行うため、TMX ファイルに次の要素を含めます。
<header>:srclang属性を使用してソース言語を特定します。<tu>: 同じソース言語とターゲット言語の<tuv>要素のペアを含めます。これらの<tuv>要素は、次の要件を満たしています。- 各
<tuv>要素は、xml:lang属性を使用して、含まれるテキストの言語を指定します。ソース言語とターゲット言語を識別するには、ISO-639-1 コードを使用します。サポートされている言語とその言語コードのリストをご覧ください。 - 1 つの
<tu>要素に 3 つ以上の<tuv>要素が含まれる場合、Vertex AI Translation API は、ソース言語に一致する最初の<tuv>要素とターゲット言語に一致する最初の<tuv>要素のみを処理します。サービスは残りの<tuv>要素を無視します。 <tu>要素に対応する<tuv>要素のペアがない場合、Vertex AI Translation API は無効な<tu>要素を無視します。
- 各
<seg>: テキストの一般化された文字列を表します。Vertex AI Translation API は、ファイルを処理する前に<seg>要素からマークアップ タグを除外します。1 つの<tuv>要素に複数の<seg>要素が含まれている場合、Vertex AI Translation API はテキスト文字列の間にスペースを挿入して、テキストを 1 つの要素に連結します。
単方向用語集で用語集の用語を特定したら、ファイルをストレージ バケットにアップロードし、用語集を作成してインポートすることで、Vertex AI Translation API で使用できるようにします。
多言語用語セットの用語集
Vertex AI Translation API は、CSV 形式を使用して同等の用語セットの用語集ファイルを受け入れます。多言語の用語セットを定義するには、複数列の CSV ファイルを作成します。1 行に 1 つの用語を定義し、各国語の対訳を同じ行に記述します。サポートされている言語とその言語コードのリストをご覧ください。
次の図は、複数列の CSV ファイルの例を示しています。各行は用語集の用語を表し、各列は用語のさまざまな言語への翻訳を表します。
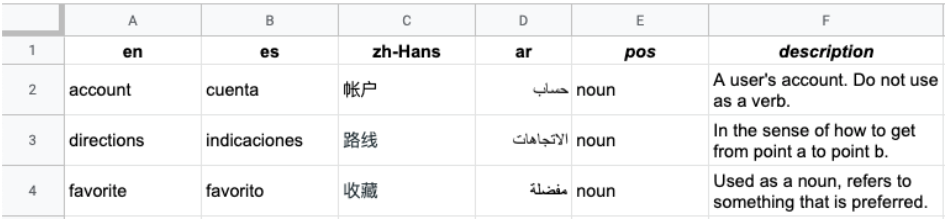
ヘッダーはファイルの最初の行で、各列の言語を識別します。ヘッダー行では、ISO-639-1 または BCP-47 標準の言語コードを使用します。Vertex AI Translation API は品詞(pos)情報を使用せず、特定の位置の値は検証されません。
以降の行では、ヘッダーに指定されている言語の順番で対訳が並びます。1 つの用語に対して、すべての言語で訳語があるとは限りません。その場合、該当する列を空白にします。
多言語用語セットで用語集の用語を特定したら、ファイルをストレージ バケットにアップロードし、用語集を作成してインポートすることで、Vertex AI Translation API で使用できるようにします。
用語集ファイルをストレージ バケットにアップロードする
用語集ファイルをストレージ バケットにアップロードする手順は次のとおりです。
- オブジェクト ストレージ用に gdcloud CLI を構成します。
プロジェクト Namespace にストレージ バケットを作成します。
Standardストレージ クラスを使用します。ストレージ バケットを作成するには、プロジェクト Namespace に
Bucketリソースをデプロイします。apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Vertex AI Translation サービスで使用されるサービス アカウント(
ai-translation-system-sa)に、バケットに対するread権限を付与します。次の手順に沿って、カスタム リソースを使用してロールとロール バインディングを作成します。
プロジェクト Namespace に
Roleリソースをデプロイして、ロールを作成します。apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectプロジェクト Namespace に
RoleBindingリソースをデプロイして、ロール バインディングを作成します。apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
作成したストレージ バケットに用語集ファイルをアップロードします。詳細については、プロジェクトでストレージ オブジェクトをアップロードしてダウンロードするをご覧ください。
用語集を作成する
CreateGlossary メソッドは用語集を作成し、用語集を生成する長時間実行オペレーションの識別子を返します。
用語集を作成するには、リクエストのデータを使用する前に、次のように置き換えます。
ENDPOINT: 組織で使用する Vertex AI Translation エンドポイント。詳細については、サービス ステータスとエンドポイントを表示するをご覧ください。PROJECT_ID: プロジェクト ID。GLOSSARY_ID: 用語集 ID(リソース名)。BUCKET_NAME: 用語集ファイルが配置されているストレージ バケットの名前。GLOSSARY_FILENAME: ストレージ バケット内の用語集ファイルの名前。
用語集を作成する HTTP リクエストの構文は次のとおりです。
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
作成した用語集ファイルに従って、次のいずれかのオプションを選択して用語集を作成します。
単一指向性
単一言語ペアの用語集を作成するには、ソース言語(source_language_code)とターゲット言語(target_language_code)で言語ペア(language_pair)を指定します。
単方向の用語集を作成する手順は次のとおりです。
次のリクエスト本文を
request.jsonという名前の JSON ファイルに保存します。{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }次のように置き換えます。
SOURCE_LANGUAGE: 用語集のソース言語の言語コード。サポートされている言語とそれぞれの言語コードのリストをご覧ください。TARGET_LANGUAGE: 用語集のターゲット言語の言語コード。サポートされている言語とそれぞれの言語コードのリストをご覧ください。
リクエストを行います。次の例では、REST API メソッドとコマンドラインを使用していますが、クライアント ライブラリを使用して単一言語ペアの用語集を作成することもできます。
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
TOKEN は、取得した認証トークンに置き換えます。
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
TOKEN は、取得した認証トークンに置き換えます。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
多言語の用語セット
多言語の用語セットの用語集を作成するには、用語集の言語コード(language_codes)を含む言語セット(language_codes_set)を指定します。
同等の用語セットの用語集を作成する手順は次のとおりです。
次のリクエスト本文を
request.jsonという名前の JSON ファイルに保存します。{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }LANGUAGE_CODEは、用語集の言語のコードに置き換えます。サポートされている言語とその言語コードのリストをご覧ください。次のリクエストを行います。
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
TOKEN は、取得した認証トークンに置き換えます。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
TOKEN は、取得した認証トークンに置き換えます。
次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
作成した Python スクリプトに次のコードを追加します。
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Python スクリプトを保存します。
Python スクリプトを実行します。
python SCRIPT_NAME
SCRIPT_NAME は、Python スクリプトに付けた名前(glossary.py など)に置き換えます。
create_glossary メソッドの詳細については、Python クライアント ライブラリをご覧ください。
通常、用語集の作成には 10 分もかかりません。このオペレーションのステータスを取得して、完了したタイミングを確認できます。
用語集を取得する
GetGlossary メソッドは、保存された用語集を返します。用語集が存在しない場合、出力は NOT_FOUND 値を返します。GetGlossary メソッドを呼び出すには、プロジェクト ID と用語集 ID を指定します。CreateGlossary メソッドと ListGlossaries メソッドはどちらも用語集 ID を返します。
たとえば、次のリクエストは、プロジェクト内の特定の用語集に関する情報を返します。
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
TOKEN は、取得した認証トークンに置き換えます。
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
用語集の一覧表示
ListGlossaries メソッドは、プロジェクト内の用語集 ID のリストを返します。用語集が存在しない場合、出力は NOT_FOUND 値を返します。ListGlossaries メソッドを呼び出すには、プロジェクト ID と Vertex AI Translation エンドポイントを指定します。
たとえば、次のリクエストは、プロジェクト内の用語集 ID のリストを返します。
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
TOKEN は、取得した認証トークンに置き換えます。
用語集を削除する
DeleteGlossary メソッドは、用語集を削除します。用語集が存在しない場合、出力は NOT_FOUND 値を返します。DeleteGlossary メソッドを呼び出すには、プロジェクト ID、用語集 ID、Vertex AI Translation エンドポイントを指定します。CreateGlossary メソッドと ListGlossaries メソッドはどちらも用語集 ID を返します。
たとえば、次のリクエストはプロジェクトから用語集を削除します。
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
TOKEN は、取得した認証トークンに置き換えます。