Vous pouvez utiliser un glossaire pour définir la terminologie spécifique à votre domaine. Avec un glossaire, vous pouvez ajouter des paires de termes, y compris un terme source et un terme cible. Les paires de termes permettent au service Vertex AI Translation de traduire votre terminologie de manière cohérente.
Voici quelques exemples de cas dans lesquels vous pouvez définir des entrées de glossaire :
- Noms de produits : identifiez les noms de produits à conserver dans la traduction. Par exemple, Google Home doit être traduit par Google Home.
- Mots ambigus : précisez la signification des mots vagues et des homonymes. Par exemple, le mot avocat peut désigner une profession ou un aliment.
- Mots empruntés : clarifiez la signification des mots empruntés à une autre langue. Par exemple, le mot français bouillabaisse est traduit par bouillabaisse en anglais, qui désigne un plat à base de poisson.
Les termes d'un glossaire peuvent être des mots individuels (également appelés jetons) ou des expressions courtes, généralement de moins de cinq mots. Vertex AI Translation ignore les entrées de glossaire correspondantes si les mots sont des mots vides.
Vertex AI Translation propose les méthodes de glossaire suivantes disponibles dans Google Distributed Cloud (GDC) air-gapped :
| Méthode | Description |
|---|---|
CreateGlossary |
Créer un glossaire |
GetGlossary |
Renvoie un glossaire stocké. |
ListGlossaries |
Renvoie la liste des ID de glossaire dans un projet. |
DeleteGlossary |
Supprimez un glossaire dont vous n'avez plus besoin. |
Avant de commencer
Avant de créer un glossaire pour définir votre terminologie de traduction, vous devez disposer d'un projet nommé translation-glossary-project. La ressource personnalisée du projet doit ressembler à l'exemple suivant :
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
Pour obtenir les autorisations nécessaires pour utiliser un glossaire, demandez à l'administrateur IAM de votre projet de vous accorder les rôles suivants dans l'espace de noms de votre projet :
- Développeur AI Translation : obtenez le rôle Développeur AI Translation (
ai-translation-developer) pour accéder au service Vertex AI Translation. - Administrateur de bucket de projet : obtenez le rôle Administrateur de bucket de projet (
project-bucket-admin) pour gérer les buckets de stockage et les objets qu'ils contiennent, ce qui vous permet de créer et d'importer des fichiers.
Pour en savoir plus sur les conditions préalables, consultez Configurer un projet de traduction.
Créer un fichier de glossaire
Vous devez créer un fichier de glossaire pour stocker les termes de vos langues source et cible. Cette section contient les deux mises en page de glossaire différentes que vous pouvez utiliser pour définir vos termes.
Le tableau suivant décrit les limites acceptées sur Distributed Cloud pour les fichiers de glossaire :
| Description | Limite |
|---|---|
| Taille maximale du fichier | 10,4 millions (10 485 760) d'octets UTF-8 |
| Longueur maximale d'un terme de glossaire | 1 024 octets UTF-8 |
| Nombre maximal de ressources de glossaire pour un projet | 10 000 |
Choisissez l'une des mises en page suivantes pour votre fichier de glossaire :
- Glossaire unidirectionnel : spécifiez la traduction attendue pour une paire de termes source et cible dans une langue spécifique. Les glossaires unidirectionnels sont compatibles avec les formats de fichiers TSV, CSV et TMX.
- Glossaire d'ensembles de termes équivalents : spécifiez la traduction attendue dans plusieurs langues sur chaque ligne. Les glossaires d'ensembles de termes équivalents sont compatibles avec les formats de fichier CSV.
Glossaire unidirectionnel
L'API Vertex AI Translation accepte les valeurs séparées par des tabulations (TSV) et les valeurs séparées par des virgules (CSV). Pour ces formats de fichier, chaque ligne contient une paire de termes séparés par une tabulation (\t) ou une virgule (,).
L'API Vertex AI Translation accepte également le format TMX (Translation Memory eXchange), un format XML standard qui fournit les paires de termes source et cible de la traduction. Les fichiers d'entrée acceptés sont au format TMX, version 1.4.
Les exemples suivants montrent la structure requise pour les formats de fichier TSV, CSV et TMX des glossaires unidirectionnels :
TSV et CSV
L'image suivante montre deux colonnes dans un fichier TSV ou CSV. La première colonne contient le terme dans la langue source et la deuxième colonne contient le terme dans la langue cible.

Lorsque vous créez un fichier de glossaire, vous pouvez définir une ligne d'en-tête. La requête de glossaire rend le fichier disponible pour l'API Vertex AI Translation.
TMX
L'exemple suivant illustre la structure requise dans un fichier TMX :
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
Si votre fichier contient des balises XML qui ne figurent pas dans cet exemple, l'API Vertex AI Translation les ignore.
Incluez les éléments suivants dans votre fichier TMX pour vous assurer qu'il sera traité correctement par l'API Vertex AI Translation :
<header>: identifiez la langue source à l'aide de l'attributsrclang.<tu>: incluez une paire d'éléments<tuv>avec les mêmes langues source et cible. Ces éléments<tuv>respectent les règles suivantes :- Chaque élément
<tuv>identifie la langue du texte contenu à l'aide de l'attributxml:lang. Utilisez les codes ISO-639-1 pour identifier les langues source et cible. Consultez la liste des langues acceptées et de leurs codes respectifs. - Si un élément
<tu>contient plus de deux éléments<tuv>, l'API Vertex AI Translation ne traite que le premier élément<tuv>correspondant à la langue source et le premier élément<tuv>correspondant à la langue cible. Le service ignore le reste des éléments<tuv>. - Si un élément
<tu>ne comporte pas de paire d'éléments<tuv>correspondante, l'API Vertex AI Translation ignore l'élément<tu>non valide.
- Chaque élément
<seg>: représente des chaînes de texte généralisées. L'API Vertex AI Translation exclut les balises d'un élément<seg>avant de traiter le fichier. Si un élément<tuv>contient plusieurs éléments<seg>, l'API Vertex AI Translation concatène le texte en un seul élément avec un espace entre les chaînes de texte.
Après avoir identifié les termes de glossaire dans votre glossaire unidirectionnel, importez le fichier dans un bucket de stockage et mettez-le à la disposition de l'API Vertex AI Translation en créant et en important un glossaire.
Glossaire des ensembles de termes équivalents
L'API Vertex AI Translation accepte les fichiers de glossaire pour les ensembles de termes équivalents au format CSV. Pour définir des ensembles de termes équivalents, créez un fichier CSV à plusieurs colonnes dans lequel chaque ligne répertorie un terme de glossaire dans plusieurs langues. Consultez la liste des langues acceptées et de leurs codes de langue respectifs.
L'image suivante montre un exemple de fichier CSV à plusieurs colonnes. Chaque ligne représente un terme du glossaire, et chaque colonne représente une traduction du terme dans différentes langues.
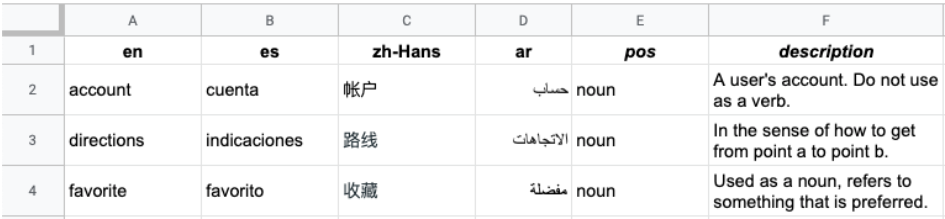
L'en-tête est la première ligne du fichier, qui identifie la langue de chaque colonne. La ligne d'en-tête utilise les codes de langue standards ISO-639-1 ou BCP-47. L'API Vertex AI Translation n'utilise pas d'informations sur les parties du discours (pos), et les valeurs de position spécifiques ne sont pas validées.
Chaque ligne suivante contient des termes de glossaire équivalents dans les langues identifiées dans l'en-tête. Vous pouvez laisser des colonnes vides si le terme n'est pas disponible dans toutes les langues.
Après avoir identifié les termes de glossaire dans votre ensemble de termes équivalents, importez le fichier dans un bucket de stockage et mettez-le à la disposition de l'API Vertex AI Translation en créant et en important un glossaire.
Importer votre fichier de glossaire dans un bucket de stockage
Pour importer votre fichier de glossaire dans un bucket de stockage, procédez comme suit :
- Configurez la gcloud CLI pour le stockage d'objets.
Créez un bucket de stockage dans l'espace de noms de votre projet. Utilisez une classe de stockage
Standard.Vous pouvez créer le bucket de stockage en déployant une ressource
Bucketdans l'espace de noms de votre projet :apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Accordez les autorisations
readsur le bucket au compte de service (ai-translation-system-sa) utilisé par le service Vertex AI Translation.Vous pouvez suivre ces étapes pour créer le rôle et l'association de rôle à l'aide de ressources personnalisées :
Créez le rôle en déployant une ressource
Roledans l'espace de noms du projet :apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectCréez la liaison de rôle en déployant une ressource
RoleBindingdans l'espace de noms du projet :apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
Importez votre fichier de glossaire dans le bucket de stockage que vous avez créé. Pour en savoir plus, consultez Importer et télécharger des objets de stockage dans des projets.
Créer un glossaire
La méthode CreateGlossary crée un glossaire et renvoie l'identifiant de l'opération de longue durée qui génère le glossaire.
Pour créer un glossaire, remplacez les éléments suivants avant d'utiliser les données de requête :
ENDPOINT: point de terminaison Vertex AI Translation que vous utilisez pour votre organisation. Pour en savoir plus, consultez l'état et les points de terminaison du service.PROJECT_ID: ID de votre projet.GLOSSARY_ID: ID de votre glossaire, qui correspond au nom de votre ressource.BUCKET_NAME: nom du bucket de stockage où se trouve votre fichier de glossaire.GLOSSARY_FILENAME: nom de votre fichier de glossaire dans le bucket de stockage.
Voici la syntaxe d'une requête HTTP permettant de créer un glossaire :
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
Selon le fichier de glossaire que vous avez créé, choisissez l'une des options suivantes pour créer un glossaire :
Unidirectionnel
Pour créer un glossaire unidirectionnel, spécifiez une paire de langues (language_pair) avec une langue source (source_language_code) et une langue cible (target_language_code).
Pour créer un glossaire unidirectionnel :
Enregistrez le corps de la requête suivant dans un fichier JSON nommé
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Remplacez les éléments suivants :
SOURCE_LANGUAGE: code de langue de la langue source du glossaire. Consultez la liste des langues acceptées et de leurs codes de langue respectifs.TARGET_LANGUAGE: code de langue de la langue cible du glossaire. Consultez la liste des langues acceptées et de leurs codes de langue respectifs.
Faites la demande. Les exemples suivants utilisent une méthode d'API REST et la ligne de commande, mais vous pouvez également utiliser des bibliothèques clientes pour créer un glossaire unidirectionnel.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
Vous devez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Ensemble de termes équivalents
Pour créer un glossaire d'ensemble de termes équivalents, spécifiez un ensemble de langues (language_codes_set) avec les codes de langue (language_codes) du glossaire.
Pour créer un glossaire d'ensemble de termes équivalents :
Enregistrez le corps de la requête suivant dans un fichier JSON nommé
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Remplacez
LANGUAGE_CODEpar le code de la ou des langues du glossaire. Consultez la liste des langues acceptées et de leurs codes respectifs.Envoyez la demande :
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
Vous devez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
Vous devez recevoir une réponse JSON de ce type :
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
Installez la dernière version de la bibliothèque cliente Vertex AI Translation.
Définissez les variables d'environnement requises dans un script Python.
Ajoutez le code suivant au script Python que vous avez créé :
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Enregistrez le script Python.
Exécutez le script Python :
python SCRIPT_NAME
Remplacez SCRIPT_NAME par le nom que vous avez donné à votre script Python, par exemple glossary.py.
Pour en savoir plus sur la méthode create_glossary, consultez la bibliothèque cliente Python.
Selon la taille du fichier de glossaire, la création d'un glossaire prend généralement moins de 10 minutes. Vous pouvez récupérer l'état de cette opération pour savoir quand elle est terminée.
Obtenir un glossaire
La méthode GetGlossary renvoie un glossaire stocké. Si le glossaire n'existe pas, la sortie renvoie la valeur NOT_FOUND. Pour appeler la méthode GetGlossary, spécifiez l'ID de votre projet et l'ID du glossaire. Les méthodes CreateGlossary et ListGlossaries renvoient l'ID du glossaire.
Par exemple, les requêtes suivantes renvoient des informations sur un glossaire spécifique de votre projet :
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
Répertorier des glossaires
La méthode ListGlossaries renvoie la liste des ID de glossaire d'un projet. Si aucun glossaire n'existe, la sortie renvoie la valeur NOT_FOUND. Pour appeler la méthode ListGlossaries, spécifiez l'ID de votre projet et le point de terminaison Vertex AI Translation.
Par exemple, la requête suivante renvoie la liste des ID de glossaire de votre projet :
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.
Supprimer un glossaire
La méthode DeleteGlossary supprime un glossaire. Si le glossaire n'existe pas, la sortie renvoie la valeur NOT_FOUND. Pour appeler la méthode DeleteGlossary, spécifiez l'ID de votre projet, l'ID du glossaire et le point de terminaison Vertex AI Translation.
Les méthodes CreateGlossary et ListGlossaries renvoient l'ID du glossaire.
Par exemple, la requête suivante supprime un glossaire de votre projet :
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Remplacez TOKEN par le jeton d'authentification que vous avez obtenu.