本互動式教學課程說明如何使用自動修復功能,在 Compute Engine 上建構高可用性的應用程式。
高可用性的應用程式是專為提供用戶端最少延遲時間和停機時間所設計。當應用程式當機或停止運作時,可用性會遭到破壞;而可用性遭破壞應用程式的用戶端可能就會遇到高延遲或停機狀況。
您可以利用自動修復功能,自動重新啟動可用性遭破壞的應用程式。這項功能可立即偵測運作失敗的虛擬機器 (VM) 執行個體並自動重新建立執行個體,以再次為用戶端提供服務。有了自動修復功能,您就不必在發生故障後手動復原應用程式的服務。
應用程式架構
應用程式包含以下 Compute Engine 元件:
- 健康狀態檢查:自動修復程式使用的 HTTP 健康狀態檢查政策,用於偵測故障的 VM。
- 防火牆規則:Google Cloud 防火牆規則可讓您允許或拒絕傳入 VM 的流量。
- 代管執行個體群組:執行相同示範網路服務的一組 VM。
- 執行個體範本:這類範本是用於在執行個體群組中建立各個 VM。

健康狀態檢查如何探測示範網路服務
健康狀態檢查會透過指定通訊協定 (例如 HTTP(S)、SSL 或 TCP),將探測要求傳送給 VM。詳情請參閱健康狀態檢查運作方式和健康狀態檢查類別、通訊協定和通訊埠。
本教學課程中的健康狀態檢查是探測通訊埠 80 上 HTTP 路徑 /health 的 HTTP 健康狀態檢查。如果是 HTTP 健康狀態檢查,則只有在路徑傳回 HTTP 200 (OK) 回應時才會傳送探測要求。在本教學課程中,示範網路伺服器會定義路徑 /health 在健康狀態良好的狀況下傳回 HTTP 200 (OK) 回應,在健康狀態不良的狀況下則傳回 HTTP 500 (Internal Server Error) 回應。詳情請參閱 HTTP、HTTPS 和 HTTP/2 的成功標準一節。
建立健康狀態檢查
如要設定自動修復功能,請建立自訂健康狀態檢查,並將網路防火牆設定為允許使用健康狀態檢查探測器。
在本教學課程中,您會建立地區健康狀態檢查。如要使用自動修復功能,可以選擇區域或全域健康狀態檢查。區域健康狀態檢查可減少跨區域依附元件,並協助實現資料落地權。如果您想為多個區域的 MIG 使用相同的健康狀態檢查,全域健康狀態檢查就很方便。
控制台
建立健康狀態檢查。
前往 Google Cloud 控制台的「建立健康狀態檢查」頁面。
在「Name」(名稱) 欄位中輸入
autohealer-check。將「範圍」設為
Regional。在「Region」(區域) 下拉式選單中,選取「
europe-west1」。在「Protocol」(通訊協定) 中選取
HTTP。將「Request path」(要求路徑) 設為
/health。這項設定會指出健康狀態檢查使用的是哪一個 HTTP 路徑。在本教學課程中,示範網路伺服器會定義路徑/health在健康狀態良好的狀況下傳回HTTP 200 (OK)回應,在健康狀態不良的狀況下則傳回HTTP 500 (Internal Server Error)回應。設定「健康狀態判定條件」:
- 將「Check interval」(檢查時間間隔) 設為
10。這項設定可定義從開始一次探測到開始下一次探測的時間長度。 - 將「Timeout」(逾時) 設定為
5。這項設定可定義Google Cloud 等待探測回應的時間長度。這個值必須小於或等於檢查時間間隔。 - 將「Healthy threshold」(良好健康狀態判定門檻) 設為
2。這項設定可定義要將 VM 的健康狀態判定為良好時必須執行成功的連續探測次數。 - 將「Unhealthy threshold」(不良健康狀態判定門檻) 設為
3。這項設定可定義要將 VM 的健康狀態判定為不良時必須執行失敗的連續探測次數。
- 將「Check interval」(檢查時間間隔) 設為
其他選項則維持預設值。
按一下底端的 [Create] (建立)。
建立防火牆規則,允許健康狀態檢查探測器發出 HTTP 要求。
前往 Google Cloud 控制台的「Create firewall rule」(建立防火牆規則) 頁面。
在「Name」(名稱) 中輸入
default-allow-http-health-check。在「Network」(網路) 中選取
default。在「Targets」(目標) 中選取
All instances in the network。在「Source filter」(來源篩選器) 中選取
IPv4 ranges。在「Source IPv4 ranges」(來源 IPv4 範圍) 中輸入
130.211.0.0/22, 35.191.0.0/16。在「Protocols and ports」(通訊協定和通訊埠) 中選取「TCP」,然後輸入
80。其他選項則維持預設值。
點選「建立」。
gcloud
使用
health-checks create http指令建立健康狀態檢查。gcloud compute health-checks create http autohealer-check \ --region europe-west1 \ --check-interval 10 \ --timeout 5 \ --healthy-threshold 2 \ --unhealthy-threshold 3 \ --request-path "/health"check-interval定義從一次探測開始到下一次探測開始之間的時間間隔。timeout定義 Google Cloud等待探測回應的時間長度。這個值必須小於或等於檢查時間間隔。healthy-threshold定義要將 VM 的健康狀態判定為良好時必須執行成功的連續探測次數。unhealthy-threshold定義要將 VM 判定為健康狀態不良時必須執行失敗的連續探測次數。request-path指出健康狀態檢查使用的是哪一個 HTTP 路徑。在本教學課程中,示範網路伺服器會定義路徑/health在健康狀態良好的狀況下傳回HTTP 200 (OK)回應,在健康狀態不良的狀況下則傳回HTTP 500 (Internal Server Error)回應。
建立防火牆規則,允許健康狀態檢查探測器發出 HTTP 要求。
gcloud compute firewall-rules create default-allow-http-health-check \ --network default \ --allow tcp:80 \ --source-ranges 130.211.0.0/22,35.191.0.0/16
什麼是良好的自動修復健康狀態檢查
用於自動修復功能的健康狀態檢查必須較為保守,這樣才不會預先刪除及重新建立執行個體。如果自動修復程式的健康狀態檢查過於嚴格,自動修復程式可能會將忙碌的執行個體誤判為失敗的執行個體,不必要地加以重新啟動,因而降低了可用性。
unhealthy-threshold。應大於1。最好將此值設為3或更大的值。這樣可防止發生如網路封包遺失等罕見失敗狀況。healthy-threshold。值為2可以滿足大多數應用程式的需求。timeout。將此時間值設為遠大於 (五倍以上) 預期回應時間。這樣可防止意外的延遲狀況 (例如執行個體忙碌運作或網路連線速度緩慢)。check-interval。此值應介於 1 秒和兩倍的逾時值之間 (不會過長也不會過短)。當值過長時,就無法及時找出失敗的執行個體。如果過短,執行個體和網路可能會因每秒發送的大量健康狀態檢查探測器而變得非常忙碌。
設定網路服務
本教學課程使用儲存在 GitHub 上的網路應用程式。如要進一步瞭解應用程式的實作方式,請參閱 GoogleCloudPlatform/python-docs-samples GitHub 存放區。
如要設定示範網路服務,請建立執行個體範本,這個範本必須在開機時啟動示範網路伺服器。接著,使用這個執行個體範本部署代管執行個體群組並啟用自動修復功能。
主控台
建立執行個體範本。請在其中加入開機指令碼,以啟動示範網路伺服器。
前往 Google Cloud 控制台的「Create instance template」(建立執行個體範本) 頁面。
將「Name」(名稱) 設為
webserver-template。在「Location」(位置) 區段中,從「Region」(區域) 下拉式選單選取「europe-west1」。
在「機器設定」專區中,選取「機器類型」下拉式選單中的「e2-medium」。
在「Firewall」(防火牆) 區段中,選取「Allow HTTP traffic」(允許 HTTP 流量) 核取方塊。
展開「進階選項」部分,即可查看進階設定。系統會顯示數個子區段。
在「Management」(管理) 專區中,找到「Automation」(自動) 並輸入下列開機指令碼:
apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo
其他選項則維持預設值。
點選「建立」。
將網路伺服器部署為代管執行個體群組。
前往 Google Cloud 控制台的「Create instance group」(建立執行個體群組) 頁面。
將「Name」(名稱) 設為
webserver-group。在「Instance template」(執行個體範本) 中選取
webserver-template。在「Region」(區域) 中選取
europe-west1。在「Zone」(可用區) 中選取
europe-west1-b。在「Autoscaling」(自動調度資源) 區段中,針對「Autoscaling mode」(自動調度資源模式),選取「Off: do not autoscale」(關閉:不自動調度資源)。
捲動返回「Number of instances」(執行個體數量) 欄位,並將其設為
3。在「Autohealing」(自動修復) 部分,執行下列操作:
- 在「健康狀態檢查」下拉式選單中,選取
autohealer-check。 將「Initial delay」(初始延遲) 設為
300。
- 在「健康狀態檢查」下拉式選單中,選取
其他選項則維持預設值。
點選「建立」。
建立防火牆規則,允許對網路伺服器發出 HTTP 要求。
前往 Google Cloud 控制台的「Create firewall rule」(建立防火牆規則) 頁面。
在「Name」(名稱) 中輸入
default-allow-http。在「Network」(網路) 中選取
default。在「Targets」(目標) 中選取
Specified target tags。在「Target Tags」(目標標記) 中輸入
http-server。在「Source filter」(來源篩選器) 中選取
IPv4 ranges。在「Source IPv4 ranges」(來源 IPv4 範圍) 中輸入
0.0.0.0/0,允許存取所有 IP 位址。在「Protocols and ports」(通訊協定和通訊埠) 中選取「TCP」,然後輸入
80。其他選項則維持預設值。
點選「建立」。
gcloud
建立執行個體範本。請在其中加入開機指令碼,以啟動示範網路伺服器。
gcloud compute instance-templates create webserver-template \ --instance-template-region europe-west1 \ --machine-type e2-medium \ --tags http-server \ --metadata startup-script=' apt-get update apt-get -y install git python3-pip python3-venv git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git python3 -m venv venv ./venv/bin/pip3 install -Ur ./python-docs-samples/compute/managed-instances/demo/requirements.txt ./venv/bin/pip3 install gunicorn ./venv/bin/gunicorn --bind 0.0.0.0:80 app:app --daemon --chdir ./python-docs-samples/compute/managed-instances/demo'建立代管執行個體群組。
gcloud compute instance-groups managed create webserver-group \ --zone europe-west1-b \ --template projects/PROJECT_ID/regions/europe-west1/instanceTemplates/webserver-template \ --size 3 \ --health-check projects/PROJECT_ID/regions/europe-west1/healthChecks/autohealer-check \ --initial-delay 300建立防火牆規則,允許對網路伺服器發出 HTTP 要求。
gcloud compute firewall-rules create default-allow-http \ --network default \ --allow tcp:80 \ --target-tags http-server
請稍候幾分鐘,讓代管執行個體群組建立及驗證 VM。
模擬健康狀態檢查失敗
如要模擬健康狀態檢查失敗的狀況,您可以利用示範網路伺服器所提供的數種方式強制發生健康狀態檢查失敗的狀況。
控制台
前往網路伺服器 VM。
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面。
在任一
webserver-groupVM 的「External IP」(外部 IP) 欄下方,點選 IP 位址。網路瀏覽器應隨即開啟新的分頁。如果要求逾時或網頁無法使用,請稍候幾分鐘,讓伺服器完成設定,然後再試一次。
示範網路伺服器會顯示如下頁面:
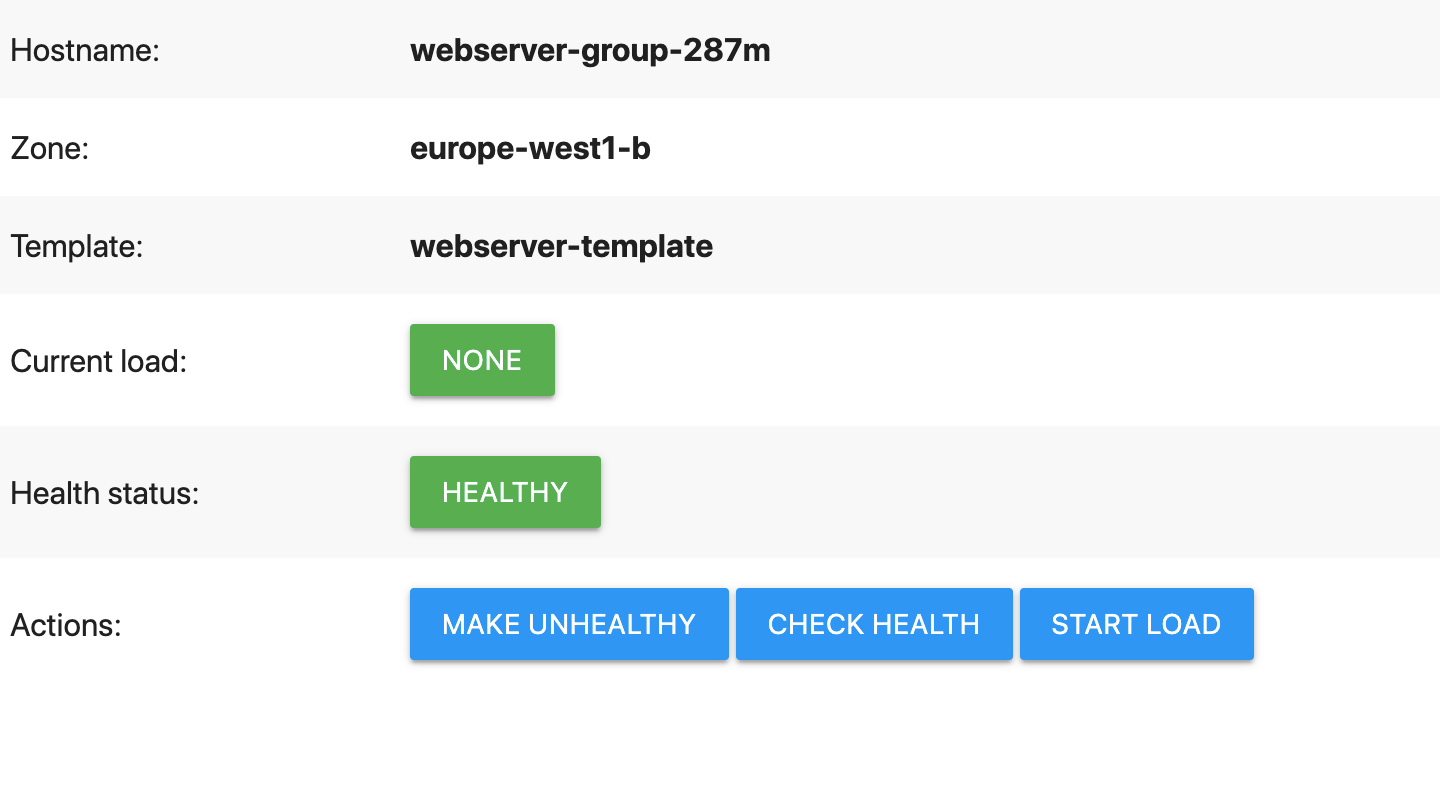
在示範網頁上,按一下 [Make unhealthy] (將健康狀態設為不良)。
這樣做會導致網路伺服器無法通過健康狀態檢查。具體來說,網路伺服器會讓
/health路徑傳回HTTP 500 (Internal Server Error)。您可以快速點選「檢查健康狀態」按鈕,自行確認這個狀況 (這個方法將在自動修復程式開始重新啟動 VM 後失效)。等待自動修復程式採取動作。
前往 Google Cloud 控制台的「VM instances」(VM 執行個體) 頁面。
等待網路伺服器 VM 的狀態變更。VM 名稱旁的綠色勾號應會變成灰色正方形,代表自動修復程式已開始重新啟動健康狀態不良的 VM。
定期點選頁面頂端的 [Refresh] (重新整理),即可取得最新狀態。
當灰色正方形變回綠色勾號時,自動修復程序就完成了,代表 VM 已再次回到良好的健康狀態。
gcloud
監控代管執行個體群組的狀態。(完成後,請按下
Ctrl+C停止操作)。while : ; do gcloud compute instance-groups managed list-instances webserver-group \ --zone europe-west1-b sleep 5 # Wait for 5 seconds done
NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-4qbx ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: NAME: webserver-group-m5v5 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR:
群組中的所有 VM 都必須顯示
STATUS: RUNNING和ACTION: NONE。 如果沒有,請稍候幾分鐘,讓 VM 完成設定,然後再試一次。開啟新的 Cloud Shell 工作階段,並安裝 Google Cloud CLI。
取得網路伺服器 VM 的位址。
gcloud compute instances list --filter webserver-group
在「
EXTERNAL_IP」(外部 IP) 欄底下,複製任一網路伺服器 VM 的 IP 位址,並儲存為本機 bash 變數。export IP_ADDRESS=EXTERNAL_IP_ADDRESS
確認網路伺服器已完成設定。伺服器會傳回
HTTP 200 OK回應。curl --head $IP_ADDRESS/health
HTTP/1.1 200 OK Server: gunicorn ...
如果收到
Connection refused錯誤,請稍候幾分鐘,讓伺服器完成設定,然後再試一次。將網路伺服器的健康狀態設為不良。
curl $IP_ADDRESS/makeUnhealthy > /dev/null
這樣做會導致網路伺服器無法通過健康狀態檢查。具體來說,網路伺服器會讓
/health路徑傳回HTTP 500 INTERNAL SERVER ERROR。您可以快速對/health發出要求,自行確認這個狀況 (這個方法將在自動修復程式開始重新啟動 VM 後失效)。curl --head $IP_ADDRESS/health
HTTP/1.1 500 INTERNAL SERVER ERROR Server: gunicorn ...
返回第一個殼層工作階段監控代管執行個體群組,並等待自動修復程式採取動作。
自動修復程序啟動後,
STATUS和ACTION兩欄將會更新,代表自動修復程式已開始重新啟動健康狀態不良的 VM。NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: STOPPING HEALTH_STATE: UNHEALTHY ACTION: RECREATING INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
自動修復程序一旦完成,虛擬機器就會再次回報
RUNNING的STATUS以及NONE的ACTION,代表虛擬機器已成功重新啟動。NAME: webserver-group-0zx6 ZONE: europe-west1-b STATUS: RUNNING HEALTH_STATE: HEALTHY ACTION: NONE INSTANCE_TEMPLATE: webserver-template VERSION_NAME: LAST_ERROR: ...
代管執行個體群組監控完畢後,按下
Ctrl+C即可結束監控。
您可視需要重複進行這項練習。不妨參考下列建議:
如果一次將所有 VM 的健康狀態都設為不良,會發生什麼狀況?如要進一步瞭解並行錯誤的自動修復行為,請參閱自動修復行為一節。
您是否能夠透過更新健康狀態檢查設定的方式,盡快修復 VM?(在實務上,您應該採用本教學課程中說明的保守值來設定健康狀態檢查參數。否則,VM 可能會在沒有實際發生問題的情況下遭到錯誤刪除及重新啟動)。
代管執行個體群組提供
initial delay設定。 您是否能夠決定本示範網路伺服器所需的最少延遲時間?(在實務上,您應將延遲時間設為比 VM 開機及開始提供應用程式要求服務的時間更長 (10% 到 20% 之間)。否則,VM 可能會卡在自動修復開機循環中)。
查看自動修復程式記錄 (選用)
如要查看自動修復程式的作業記錄,請使用以下 gcloud 指令:
gcloud compute operations list --filter='operationType~compute.instances.repair.*'
詳情請參閱查看自動修復作業記錄一節。