Neste documento, você vai conhecer estratégias de recuperação de desastres (DR) do Microsoft SQL Server para arquitetos e líderes técnicos responsáveis por projetar e implementar a recuperação de desastres no Google Cloud.
Os bancos de dados ficam indisponíveis por vários motivos. Por exemplo, por falhas no hardware ou na rede. Para fornecer acesso contínuo ao banco de dados durante essas falhas, é usado um banco de dados secundário, que é uma réplica do primário. Quando o banco de dados secundário está em um local diferente, é muito mais provável que ele esteja disponível quando o primário falhar.
Se o banco de dados primário ficar indisponível, seu app de missão crítica se conectará a um secundário. Esse banco de dados usa o estado de dados consistente mais recente para fornecer serviços aos usuários com tempo de inatividade mínimo ou zero.
O processo de disponibilização do banco de dados secundário após a falha do primário é chamado de recuperação de desastres do banco de dados. O banco de dados secundário serve para você se recuperar da indisponibilidade do primário. Idealmente, o banco de dados secundário tem o mesmo estado consistente que o primário quando ele fica indisponível. O secundário perde no máximo um pequeno conjunto de transações recentes do primário.
A recuperação de desastres do banco de dados é um recurso essencial para clientes corporativos. O principal motivo é a continuidade de negócios nos apps de missão crítica. Por exemplo, esses apps geram receita (comércio eletrônico), fornecem serviços confiáveis e contínuos (controle de voos ou de usinas elétricas) ou oferecem suporte a funcionalidades médicas (monitoramento de pacientes). Em todos esses exemplos, é de extrema importância que o app esteja sempre disponível porque ele é de missão crítica.
A maioria dos sistemas de gerenciamento de banco de dados tem a funcionalidade de recuperação de desastres, incluindo o Microsoft SQL Server. Neste documento de arquitetura, você vai conferir como os recursos de DR fornecidos pelo SQL Server são implementados no contexto de Google Cloud.
Terminologia
Nas seções a seguir, você encontra explicações dos termos usados neste documento.
Arquitetura geral de recuperação de desastres
O diagrama a seguir ilustra a topologia da arquitetura geral da recuperação de desastres.
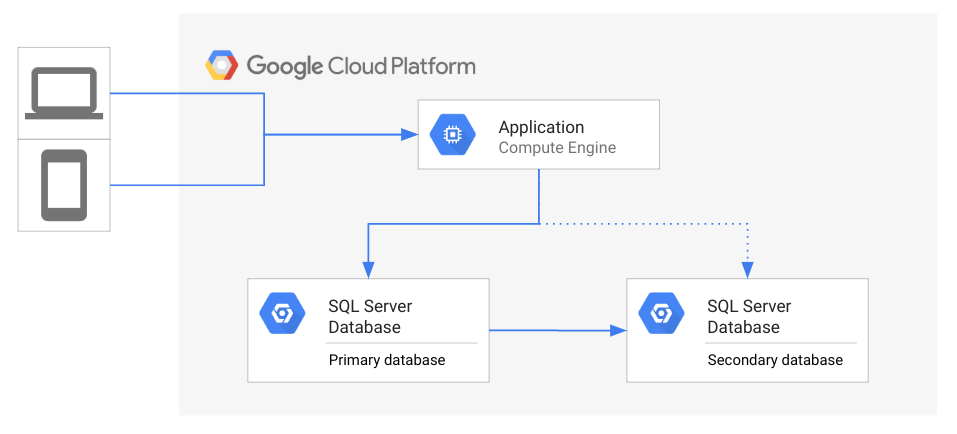
No diagrama, um app acessa um banco de dados primário enquanto um secundário fica em espera e reflete o estado do primário. Os clientes estão acessando o app que é executado no Google Cloud.
Se o banco de dados primário ficar indisponível, os administradores dele ou a equipe de operações precisarão decidir se iniciarão o processo de recuperação de desastres. Se ela for iniciada, o app será reconectado ao banco de dados secundário. Depois disso, os clientes podem voltar a usar o app. Em uma situação ideal, o app fica disponível no banco de dados secundário o mais rápido possível para que não ocorra interrupção no serviço dos clientes. Outra opção é aguardar a acessibilidade do banco de dados primário voltar, em vez de iniciar a recuperação de desastres. Por exemplo, se as falhas forem intermitentes, talvez seja mais rápido resolver o problema em vez de fazer o failover.
Banco de dados primário e secundário
O banco de dados primário é acessado por um ou mais apps e fornece serviços de persistência para o gerenciamento do estado deles. O banco de dados secundário está vinculado ao primário, além de ter uma réplica dele. Idealmente, o conteúdo do banco de dados secundário é exatamente igual ao do primário em qualquer momento. Em muitos casos, o banco de dados secundário retarda o primário. Isso é por conta de atrasos na aplicação das alterações transacionais feitas no banco de dados primário. É possível associar mais de um banco de dados secundário dependendo da tecnologia. O SQL Server é compatível com a associação de mais de um banco de dados secundário a um primário.
Recuperação de desastres
Na recuperação de desastres, se um banco de dados primário fica indisponível, o papel dele é assumido pelo secundário. Quando há mais de um banco de dados secundário, é possível selecionar um deles manualmente ou com base em uma lista de preferências de failover. Os apps precisam se reconectar ao novo banco de dados primário para continuar acessando o estado deles. Se o novo banco de dados primário não estiver sincronizado com o último estado conhecido do anterior, o app será iniciado a partir de um estado passado, também conhecido como flashback.
É importante ter sempre pelo menos um banco de dados secundário para cada primário. Após uma recuperação de desastres, não deixe de configurar um novo banco de dados secundário para lidar com cenários futuros de falhas.
Failover, alternância e fallback
Há vários cenários em que o papel dos bancos de dados primário e secundário são alterados:
- Failover: quando o banco de dados secundário assume o papel do novo banco de dados primário e conecta todos os apps a ele. O failover não é intencional, já que ele é acionado pela indisponibilidade de um banco de dados primário. É possível configurar o acionamento do failover como automático ou manual.
- Alternância: em comparação com o failover, a alternância de um banco de dados primário para um secundário é acionada intencionalmente em testes iniciais e manutenção programada. Faça uma alternância com frequência para testar o sistema de recuperação de desastres e garantir a confiabilidade contínua desse processo.
- Fallback: é a reversão do processo, em que o novo banco de dados primário volta a ser o secundário após o reparo. O fallback é acionado intencionalmente para restabelecer o estado de antes do failover ou da alternância. Ele não é tão necessário, mas pode ser feito com base nos requisitos da recuperação de desastres, como localidade ou recursos disponíveis.
Google Cloud zonas e regiões
Recursos como bancos de dados estão localizados em zonas e regiões doGoogle Cloud , onde cada zona pertence a uma região. A zona é um domínio de ponto único de falha. Recomendamos a implantação de um recurso altamente disponível e tolerante a falhas em várias zonas de uma região.
Para se proteger quando houver a interrupção de uma região inteira, crie estratégias multirregionais de recuperação de desastres. Por exemplo, coloque os bancos de dados primário e secundário em regiões diferentes.
Modos ativos: ativo-passivo e ativo-ativo
O banco de dados primário aceita operações de leitura e gravação, chamadas de DML, para que os apps que o acessam possam gerenciar o estado deles. O banco de dados primário é chamado de ativo. Já o secundário correspondente é passivo porque ele replica o banco de dados primário, mas não fica disponível para os apps realizarem operações de alteração de estado. Após um failover ou alternância, o banco de dados secundário se torna o novo primário, ou seja, fica ativo.
O banco de dados primário e o secundário poderão ser ativos se a tecnologia for compatível com esse recurso, que é chamado de modo ativo-ativo. Nesse caso, os apps podem se conectar a um desses bancos de dados porque ambos estão disponíveis para o gerenciamento de estado. A recuperação de desastres nesse modo não requer um failover se apenas um dos bancos de dados ativos fica indisponível. Quando isso acontece, o outro banco de dados ativo continua disponível. O modo ativo-ativo não está no escopo deste artigo porque o SQL Server não é compatível com ele.
Modos de espera: ativa, semiativa, passiva e sem espera
Para que o banco de dados primário seja ativo, ele precisa estar em funcionamento e ter a capacidade de executar instruções DML. O secundário não precisa estar em execução, ou seja, ele pode estar desligado. Se ele não estiver em execução, o tempo necessário para se recuperar de uma falha aumentará. Isso acontece porque o novo banco de dados primário precisa atingir um estado de execução antes de assumir esse papel.
A configuração do banco de dados secundário tem diversas variações:
- Espera ativa: o banco de dados secundário está em execução e pronto para receber a conexão dos clientes. A última alteração do banco de dados primário é sempre aplicada assim que ela fica disponível.
- Espera semiativa: o banco de dados secundário está em execução. No entanto, nem todas as alterações do primário foram aplicadas ainda.
- Espera passiva: o banco de dados secundário não está em execução. Primeiro, ele precisa ser inicializado e depois sincronizado com o estado mais recente disponível.
- Sem espera: é necessário instalar o software do banco de dados primeiro e iniciá-lo antes que todas as alterações do primário sejam aplicadas. Esse é o modo mais econômico porque não consome recursos quando o banco de dados secundário não é necessário. No entanto, comparado aos outros modos, ele gasta mais tempo para atribuir o papel de novo banco de dados primário.
Estratégias de recuperação de desastres
Nas seções a seguir, você vê explicações sobre as estratégias de recuperação de desastres compatíveis com o Microsoft SQL Server.
Dimensões da estratégia de recuperação
Há várias dimensões importantes a serem consideradas ao selecionar ou implementar uma estratégia de recuperação de desastres do banco de dados. Cada dimensão tem um espectro, e os pontos dele que você seleciona determinam o funcionamento e as expectativas da estratégia de recuperação de desastres. As dimensões importantes são as seguintes:
- Objetivo do ponto de recuperação (RPO, na sigla em inglês) [página em inglês]: o período máximo aceitável em que os dados podem ser perdidos do app devido a um incidente grave. Essa dimensão varia de acordo com a forma como os dados são usados. É possível expressar o RPO em duração (segundos, minutos ou horas) a partir do horário da indisponibilidade do banco de dados primário ou como estados de processamento identificáveis (último backup completo ou incremental). Seja qual for a forma de especificar o RPO, a estratégia de recuperação de desastres precisa implementar essa determinada medida para que o requisito do RPO seja atendido. O caso mais exigente é a última transação confirmada, em que nenhuma perda do banco de dados primário para o secundário pode acontecer.
- Objetivo do tempo de recuperação (RTO, na sigla em inglês): o período máximo aceitável em que o app pode ficar off-line. Geralmente, esse valor é especificado como parte de um contrato de nível de serviço maior. O RTO costuma ser expresso em termos de duração a partir do horário da indisponibilidade do banco de dados primário. Por exemplo, o app precisa estar totalmente operacional em até 5 minutos. O caso mais exigente é imediato para que os usuários do app não percebam que a recuperação de desastres ocorreu.
- Domínio de ponto único de falha: cabe a você decidir se uma região é considerada um domínio de ponto único de falha nos requisitos de recuperação de desastres. Nesse caso, a recuperação de desastres precisará ser configurada para que duas ou mais regiões estejam incluídas na configuração real. Se a região que contém o banco de dados primário falhar, o secundário em uma região diferente será o novo banco de dados primário. Se o domínio de ponto único de falha for uma zona, a recuperação de desastres poderá ser configurada entre as zonas de uma única região. Se uma zona falhar, a recuperação de desastres usará outra e disponibilizará o novo banco de dados primário nela.
Escolher quais dessas dimensões importantes usar na estratégia é uma questão de decidir entre custo e qualidade. Quanto menor o RTO e o RPO, mais cara a solução de recuperação de desastres pode ficar à medida que mais recursos ativos são usados. Nas seções a seguir, você verá várias estratégias alternativas de recuperação de desastres. Elas representam os pontos nas dimensões dentro do contexto do banco de dados do Microsoft SQL Server.
Estratégias de DR do SQL Server
Em Recuperação de banco de dados e continuidade de negócios – SQL Server, você vê descrições dos recursos de disponibilidade que podem ser usados para implementar estratégias de recuperação de desastres.
Informações preliminares
O SQL Server é executado no Windows e no Linux. No entanto, nem todos os recursos de disponibilidade são oferecidos no Linux. O SQL Server tem várias edições, mas nem todos os recursos de disponibilidade são oferecidos em todas elas.
O SQL Server diferencia as instâncias dos bancos de dados. A instância é o software SQL Server em execução. Já o banco de dados é o conjunto de dados gerenciado por uma instância do SQL Server.
Grupos de disponibilidade sempre ativados
Os grupos de disponibilidade sempre ativados fornecem proteção no nível do banco de dados. Eles têm duas ou mais réplicas: uma delas é a réplica primária com acesso de leitura e gravação, e as restantes são secundárias que fornecem acesso de leitura. Cada réplica do banco de dados é gerenciada por uma instância autônoma do SQL Server. O grupo de disponibilidade pode conter um ou mais bancos de dados. O número de bancos de dados que pode ser incluído em um grupo de disponibilidade e a quantidade de réplicas secundárias compatíveis dependem da edição do SQL Server. Todos os bancos de dados em um grupo de disponibilidade passam pelas mesmas mudanças de ciclo de vida ao mesmo tempo. Os grupos de disponibilidade implementam o modo ativo-passivo porque somente o banco de dados primário tem acesso de gravação.
Quando ocorre o failover, uma réplica secundária se torna a primária. Como o grupo de disponibilidade inclui instâncias autônomas do SQL Server, todas as operações coletadas nos registros de transação ficam disponíveis nas réplicas. Qualquer alteração não coletada em um registro de transações precisa ser sincronizada manualmente. Por exemplo, logins no nível da instância do SQL Server ou jobs do SQL Server Agent. Para fornecer proteção no nível do banco de dados e para a instância do SQL Server, é necessário configurar instâncias de cluster de failover (FCIs, na sigla em inglês). Essa arquitetura de implantação é abordada posteriormente na seção Instância de cluster de failover sempre ativada.
Para proteger os apps contra alterações de papel, use um detector. Ele é compatível com os apps que se conectam ao grupo de disponibilidade. Os apps não sabem quais instâncias do SQL Server gerenciam o banco de dados primário ou as réplicas secundárias em qualquer momento. Os detectores exigem que os clientes usem a versão mínima 3.5 do .NET com uma atualização ou 4.0 e superior, conforme descrito em Recuperação de banco de dados e continuidade de negócios – SQL Server.
Os grupos de disponibilidade dependem de camadas subjacentes de abstração para fornecer a funcionalidade deles. Os grupos de disponibilidade são executados em um cluster de failover do Windows Server (WSFC, na sigla em inglês), conforme descrito em Clustering de failover do Windows Server com o SQL Server. Todos os nós que executam instâncias do SQL Server precisam fazer parte do mesmo WSFC.
As transações são enviadas do banco de dados primário para todas as réplicas secundárias. Há dois modos de envio de transações: síncrono e assíncrono. É possível configurar cada réplica separadamente para usar um desses modos. No modo síncrono, a transação no banco de dados primário só é enviada se ela for bem-sucedida em todas as réplicas secundárias vinculadas de forma síncrona. Já no modo assíncrono, a transação no banco de dados primário pode ser enviada mesmo que ela não seja aplicada a todas as réplicas secundárias.
O modo de envio escolhido influencia o possível RTO, RPO e o modo de espera. Por exemplo, se as transações forem enviadas a todas as réplicas no modo síncrono, todas as réplicas estarão no mesmo estado. O RPO mais exigente, ou transação mais recente, é atendido porque todas as réplicas são totalmente sincronizadas. As réplicas secundárias têm espera ativa. Portanto, qualquer uma delas pode ser usada imediatamente como banco de dados primário.
O failover pode ser automático ou manual. O modo automático é possível se todas as réplicas estiverem totalmente sincronizadas. No exemplo anterior, ele é aplicável já que todas as réplicas são sempre sincronizadas totalmente.
No gráfico a seguir, há um grupo de disponibilidade Always On em uma única região.
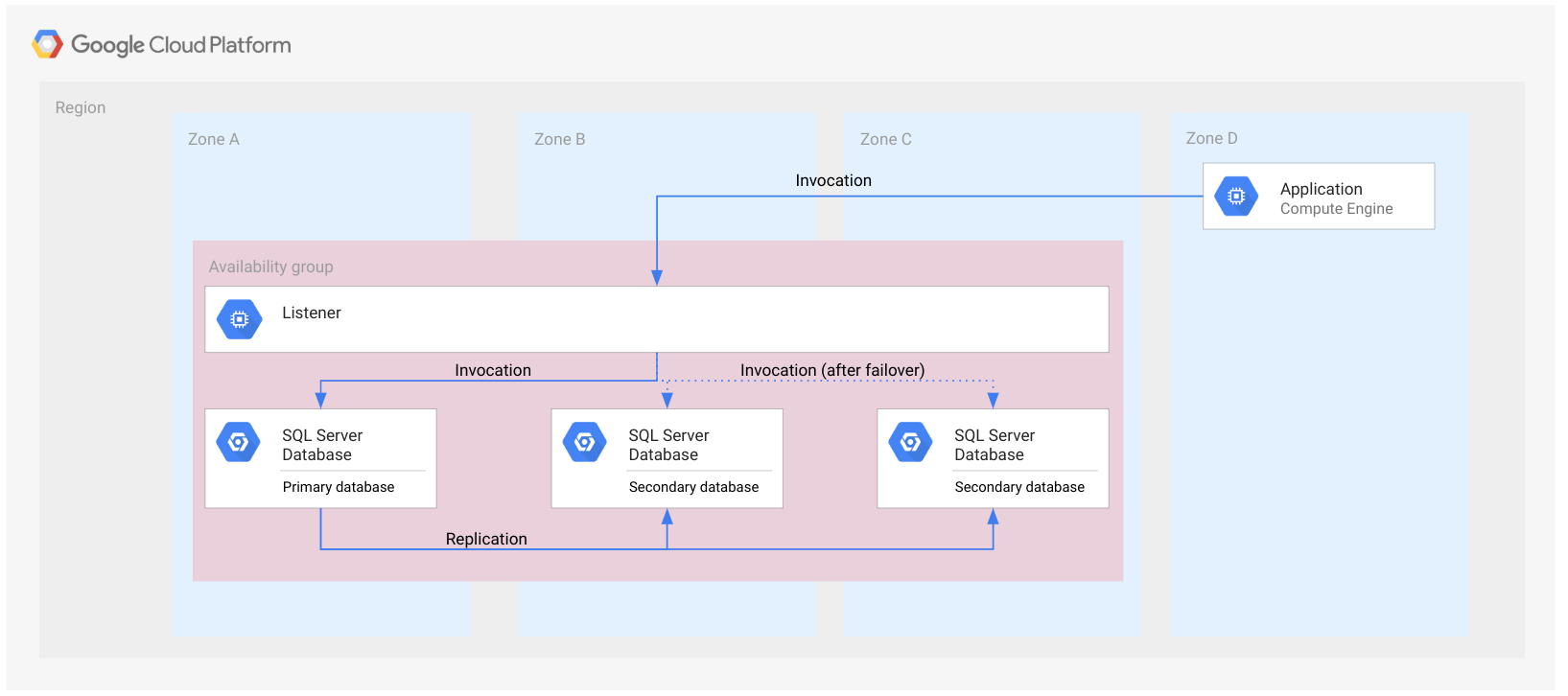
O grupo de disponibilidade é representado pelo retângulo que passa por cima das zonas. Isso é apenas para fins ilustrativos e indica que todos os bancos de dados pertencem ao mesmo grupo de disponibilidade. O grupo de disponibilidade não é um recurso de nuvem e, por isso, não é implementado em um nó ou em qualquer outro tipo de recurso.
Instância de cluster de failover sempre ativada
Para se proteger contra falhas em nós, use as instâncias de cluster de failover (FCIs, na sigla em inglês) em vez das autônomas do SQL Server. Há dois ou mais nós que executam instâncias do SQL Server para gerenciar um banco de dados primário ou secundário. Eles formam o cluster de failover. Apenas um nó no cluster executa ativamente uma instância do SQL Server. Quando esse nó falha, outro no cluster inicia uma instância do SQL Server, assumindo o gerenciamento do banco de dados. Isso é chamado de failover do nó. O processo de inicialização automática de uma instância do SQL Server fornece a funcionalidade de alta disponibilidade.
O cluster da FCI aparece como uma única unidade, e os clientes que o acessam não veem o failover entre os nós, exceto talvez durante um curto período da indisponibilidade. Não há perda de dados quando ocorre um failover de nó. Tudo que é executado na instância do SQL Server com falha é migrado para outra no mesmo cluster. Por exemplo, os jobs ou servidores vinculados do SQL Server Agent são migrados para outra instância.
É possível configurar nós de cluster da FCI em diferentes Google Cloud zonas. Essa arquitetura fornece alta disponibilidade durante a falha do nó e da zona. Você encontra um exemplo de implantação dessa estratégia na seção de alternativas de implantação de DR.
Mesmo que diferentes nós gerenciem e compartilhem o mesmo banco de dados, não há um armazenamento comum necessário entre os nós de um cluster da FCI. O SQL Server usa a funcionalidade Storage Spaces Direct (S2D) para gerenciar bancos de dados em discos de nós dedicados. Para mais informações, consulte Como configurar instâncias de cluster de failover do SQL Server.
No exemplo da seção anterior Grupos de disponibilidade sempre ativados, o exemplo com FCIs, em vez de instâncias autônomas do SQL Server, é mostrado na figura a seguir. Cada FCI tem uma instância ativa do SQL Server que gerencia o banco de dados.
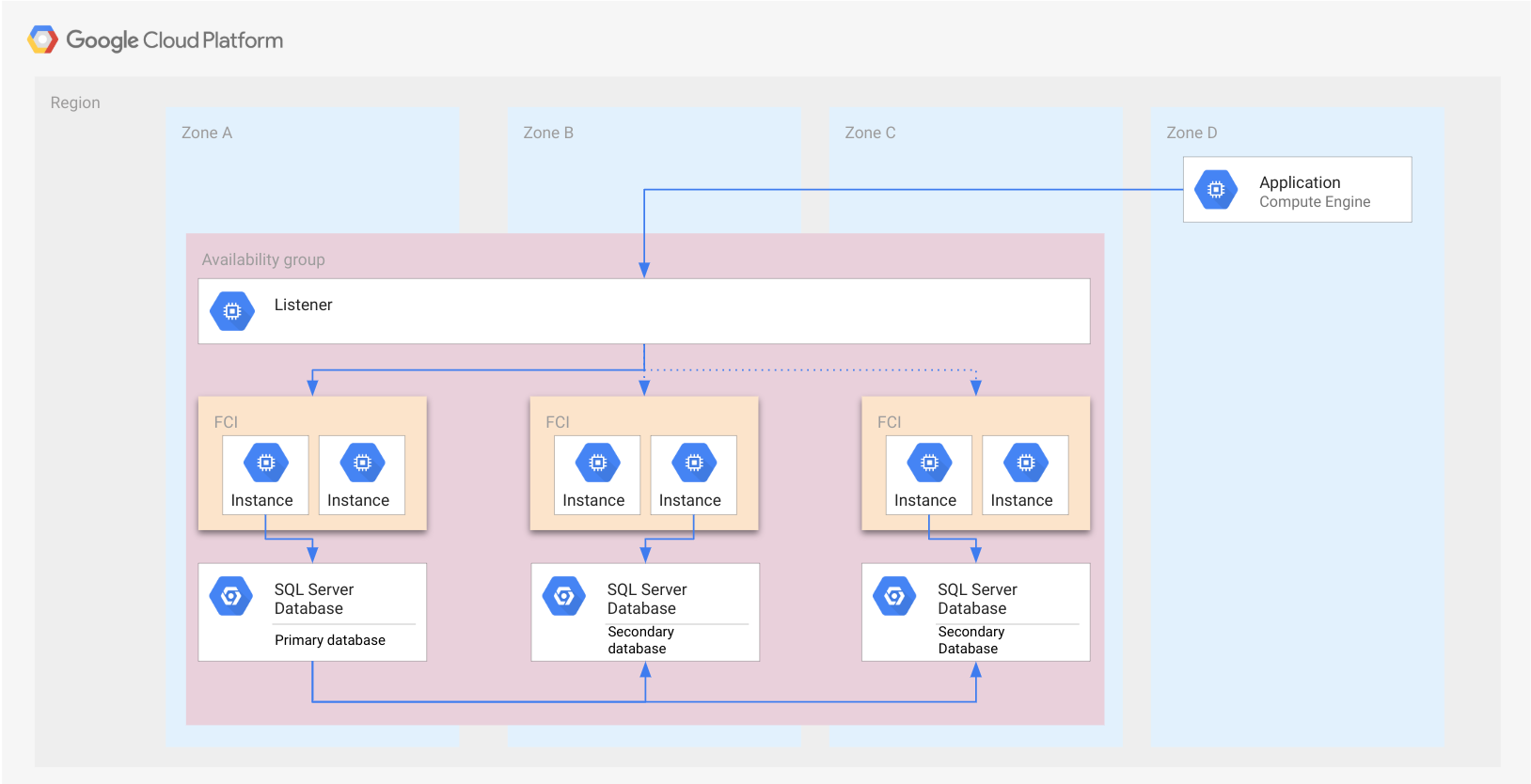
Como no caso do grupo de disponibilidade, a FCI é representada por um retângulo. Isso tem fins ilustrativos apenas e indica que todos os nós pertencem à mesma FCI. Uma FCI não é um recurso de nuvem e, por isso, não é implementada em um nó ou qualquer outro tipo de recurso.
Para uma discussão mais detalhada, consulte Instâncias de cluster de failover sempre ativadas (SQL Server).
Grupos de disponibilidade distribuídos
Os grupos de disponibilidade distribuídos são de um tipo especial. Eles abrangem dois grupos de disponibilidade: um no papel de primário e outro de secundário. Os grupos de disponibilidade distribuídos podem encaminhar transações no modo síncrono e assíncrono, do grupo de disponibilidade primário para o secundário.
Mesmo que cada um dos grupos de disponibilidade tenha o próprio banco de dados primário, esta não é uma implantação ativa-ativa. Apenas o banco de dados primário do grupo de disponibilidade primário pode receber operações de gravação. O banco de dados primário do grupo de disponibilidade secundário é chamado de encaminhador. Ele recebe as transações do grupo de disponibilidade primário e as encaminha para os bancos de dados secundários do grupo secundário. Quando você faz o failover do grupo de disponibilidade primário para o secundário, o banco de dados primário do novo grupo primário pode receber operações de gravação.
Os grupos de disponibilidade primário e secundário não precisam estar no mesmo local e sistema operacional. No entanto, é necessário que cada um deles tenha um detector instalado. Os próprios grupos de disponibilidade distribuídos não têm um detector. Eles não requerem que os dois grupos de disponibilidade estejam no mesmo WSFC. Todas as funcionalidades necessárias para fazer com que os grupos de disponibilidade distribuídos funcionem está contida na funcionalidade do SQL Server e não requerem a instalação complementar de componentes subjacentes.
Um grupo de disponibilidade distribuído inclui exatamente dois grupos de disponibilidade. Por sua vez, eles podem fazer parte de dois grupos de disponibilidade distribuídos. Isso gera diferentes topologias. Uma delas é a de encadeamento entre grupos de disponibilidade em vários locais. Outra é a topologia em árvore, em que o grupo de disponibilidade primário faz parte de dois grupos distribuídos diferentes e separados.
Os grupos de disponibilidade distribuídos são a principal maneira de implementar a recuperação de desastres em sistemas operacionais. Por exemplo, é possível definir o grupo de disponibilidade primário no Windows e outro correspondente no Linux, com ambos formando um grupo distribuído.
O diagrama a seguir mostra dois grupos de disponibilidade que fazem parte de um distribuído.
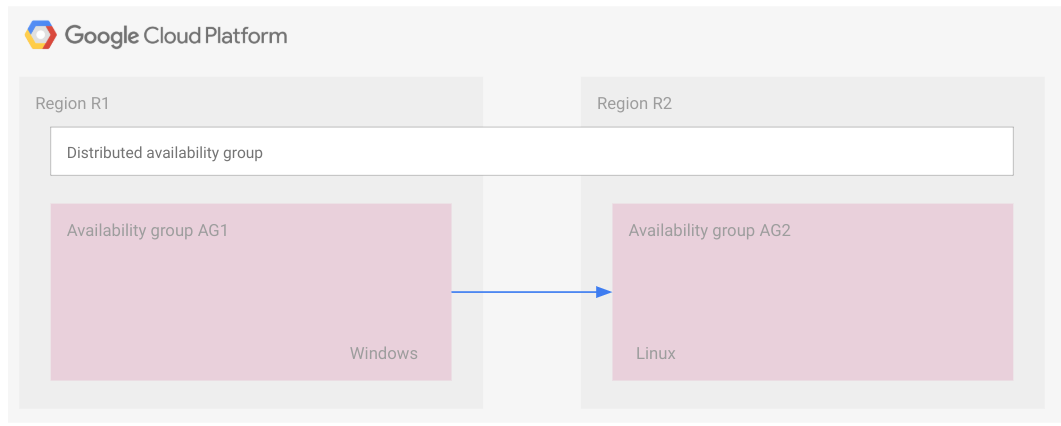
O grupo de disponibilidade 1 é o primário, e o 2 é o secundário.
Como no caso das FCIs, um grupo de disponibilidade distribuído é representado por um retângulo. Isso é apenas para fins ilustrativos e indica que todos os grupos de disponibilidade pertencem ao mesmo grupo distribuído. O grupo de disponibilidade e o grupo distribuído não são recursos de nuvem e, por isso, não são implementados em um nó ou em qualquer outro tipo de recurso.
Para mais informações, consulte Grupos de disponibilidade distribuídos.
Envio de registros
O envio de registros de transações é um recurso de disponibilidade do SQL Server quando o RTO e RPO não são tão rígidos (RTO baixo e/ou RPO recente) porque a discrepância de estado entre um banco de dados primário e o secundário é muito maior. O motivo é que um arquivo de registros de transações contém muitas alterações de estado. A discrepância também é maior em termos de atraso porque os arquivos de registros de transações são transferidos de forma assíncrona e precisam ser aplicados integralmente a um banco de dados secundário.
Os arquivos de registros de transações são criados pelo banco de dados primários e submetidos a backup para o Cloud Storage, por exemplo. Todos eles são copiados para cada banco de dados secundário e aplicados a ele. Como o banco de dados secundário fica em defasagem com relação ao primário, eles têm o modo de espera semiativa. Os objetos e alterações que não são coletados pelos registros de transação precisam ser aplicados manualmente aos bancos de dados secundários para estabelecer a sincronização completa e sem perda.
O SQL Server Agent automatiza o processo geral de criação, cópia e aplicação de registros de transação. O envio de registros precisa ser configurado para cada banco de dados separadamente. Se um grupo de disponibilidade gerencia mais de um banco de dados, então é necessário configurar processos de envio de registros nessa mesma quantidade.
No caso de falha, o processo de recuperação de desastres precisa ser iniciado manualmente porque não há suporte automatizado. Além disso, o acesso do cliente não é abstraído do banco de dados primário e secundários por um detector. No caso de failover, os clientes precisam processar por conta própria a mudança de papel de um banco de dados (de secundário para o novo primário). Para isso, é necessário conectar-se ao novo banco de dados primário após uma recuperação de desastres. É possível criar abstrações separadas, seja qual for a instância do SQL Server. Por exemplo, endereços IP flutuantes, conforme descrito em Práticas recomendadas para endereços IP flutuantes.
O envio de registros é, em partes, um processo manual. Por isso, é possível atrasar intencionalmente a aplicação de arquivos de registro copiados para bancos de dados secundários. Em comparação, nos grupos de disponibilidade e grupos distribuídos, as alterações são aplicadas imediatamente. Por exemplo, um caso de uso é evitar que erros na modificação de dados do banco de dados primário sejam aplicados ao secundário. Nesse caso, um banco de dados secundário que ainda não recebeu os erros na modificação de dados pode se tornar o primário até que eles sejam resolvidos. Depois, o processamento normal é retomado.
Como no caso de grupos de disponibilidade distribuídos, é possível usar o envio de registros em soluções de várias plataformas. Nelas, por exemplo, o banco de dados primário é executado no Linux, e os secundários estão no Linux e no Windows.
O diagrama a seguir ilustra uma implantação de várias plataformas com o envio de registros. Não há uma configuração comum nas regiões como um grupo de disponibilidade distribuído nessa topologia.
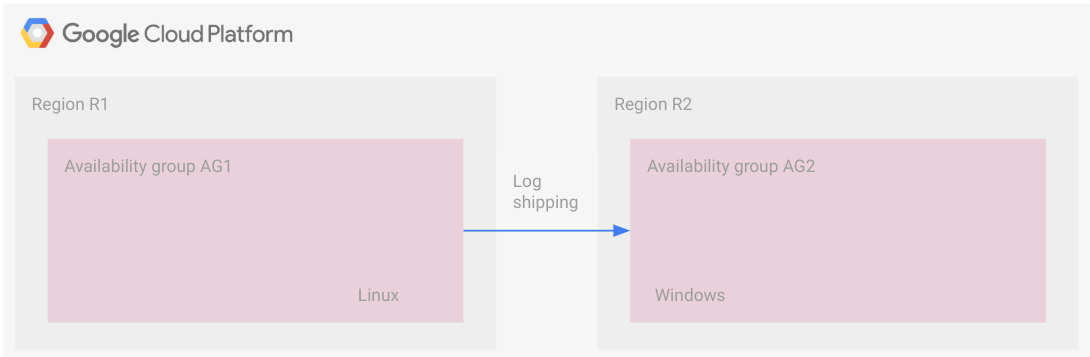
Os grupos de disponibilidade estão em regiões separadas. Um deles é executado no Linux e outro no Windows.
Para mais informações sobre o envio de registros do SQL Server, leia este artigo.
Como combinar recursos de disponibilidade do SQL Server
Implante recursos de disponibilidade do SQL Server em diferentes combinações. Por exemplo, no caso de uso anterior, o envio de registros foi usado com diferentes grupos de disponibilidade instalados em sistemas operacionais distintos.
A seguir, veja uma lista de possíveis combinações dos recursos de disponibilidade do SQL Server:
- Usar o envio de registros entre os grupos de disponibilidade instalados no mesmo sistema operacional.
- Ter um grupo de disponibilidade primário que usa FCIs com um secundário que utiliza apenas instâncias autônomas do SQL Server.
- Usar um grupo de disponibilidade distribuído entre regiões próximas. Fazer o envio de registros em regiões de continentes diferentes.
Essas são apenas algumas das possíveis combinações de recursos de disponibilidade do SQL Server.
Com a flexibilidade fornecida pelos recursos de disponibilidade do SQL Server, é possível ajustar uma estratégia de recuperação de desastres de acordo com os requisitos indicados.
Replicação do SQL Server
Geralmente, a replicação do SQL Server não é considerada um recurso de disponibilidade. No entanto, nesta seção, você vê um resumo de como esse recurso pode ser usado na recuperação de desastres.
O recurso de replicação é compatível com a criação e manutenção de réplicas de bancos de dados. Diferentes tipos de agentes do SQL Server trabalham juntos para coletar e transmitir alterações, além de aplicá-las às réplicas. Esse processo é assíncrono, e as réplicas costumam ficar em defasagem com relação ao banco de dados de replicação em vários níveis.
Por exemplo, é possível ter uma réplica de um banco de dados de produção. Em termos de recuperação de desastres, o banco de dados de produção é o primário, e a réplica é o secundário. O recurso de replicação do SQL Server não sabe que os bancos de dados assumem papéis diferentes no contexto da recuperação de desastres. Portanto, a replicação não inclui operações que aceitam o processo de recuperação de desastres. Por exemplo, alterações de papéis. É necessário implantar o processo de recuperação de desastres separadamente da funcionalidade do SQL Server. Além disso, ele precisa ser executado pela organização responsável pela implantação, já que não há abstrações de acesso do cliente.
Envio de arquivos de backup
O envio de arquivos de backup é outra estratégia de implementação de recuperação de desastres. Uma abordagem padrão para configurar e atualizar continuamente um banco de dados secundário é usar o backup completo inicial do primário e backups incrementais dele posteriormente. Todos os backups incrementais são aplicados aos bancos de dados secundários na ordem correta. Há muitas variações nessa abordagem, dependendo da frequência dos backups incrementais e do local de armazenamento dos arquivos de backup (localização global ou copiado entre locais).
Essa estratégia não inclui nenhum recurso de disponibilidade do SQL Server ao replicar alterações de estado do banco de dados primário para qualquer secundário. Ela não usa o SQL Server Agent, utilizado no caso de envio de registros.
Para mais informações, consulte a seção Exemplo: estratégia de recuperação de desastres com backup e restauração.
Em comparação com a abordagem de replicação vista na seção anterior, tanto a replicação quanto o envio de arquivos de backup têm uma característica em comum: o processo de recuperação de desastres é implementado separadamente, fora do conjunto de recursos do SQL Server. Do ponto de vista do envio de alterações coletadas, a replicação do SQL Server é melhor, porque implementa essa parte automaticamente por meio dos SQL Server Agents.
Informações sobre a interação dos ciclos de vida do banco de dados e do app
O failover do banco de dados não é um processo totalmente separado e independente dos apps que acessam o banco de dados. Em geral, há dois cenários de falha.
No primeiro, o app continua funcionando enquanto o banco de dados recebe o failover. Desde a indisponibilidade do banco de dados primário até o momento em que o novo primário entra em operação, ele não pode ser acessado pelos apps. As conexões atuais falham, e nenhuma outra é estabelecida. Durante esse período, os clientes não conseguem usar o app, pelo menos nas atividades que exigem acesso ao banco de dados. Os apps precisam reconhecer quando o novo banco de dados primário está disponível para que eles possam retomar o processamento normal.
Os apps podem ter estado fora do banco de dados. Por exemplo, nos caches da memória principal. Os apps garantem que o cache esteja consistente, ou sincronizado, com o novo banco de dados primário. Se não houve perda de transações durante o failover, a consistência do cache não exige manutenção extra. No entanto, se tiver ocorrido perda de transação, ou dados, durante o failover, o cache pode não ser consistente com o novo banco de dados primário. A mesma discussão se aplica ao estado compartilhado quando, por exemplo, alguns dos dados no banco de dados também fazem parte de mensagens em filas ou arquivos no sistema de arquivos. Esse aspecto da consistência de dados não está no escopo deste documento porque ele não está diretamente relacionado à recuperação de desastres do banco de dados.
No segundo cenário, um ou mais apps podem ficar indisponíveis ao mesmo tempo que o banco de dados primário. Por exemplo, se uma região ficar off-line, um sistema de aplicativo em execução nela ficará indisponível assim como o banco de dados primário nessa mesma região. Nesse caso, também é necessário recuperar o app, e não apenas o sistema do banco de dados primário. Além do processo de recuperação de desastres do banco de dados, você precisa iniciar um processo similar para o app. É necessário que o app recuperado seja conectado ao novo banco de dados primário e reconfigurado. Por exemplo, endereços IP flutuantes. A recuperação de apps não está no escopo deste documento.
Relação entre backup e restauração e recuperação de desastres
O backup do banco de dados não depende da recuperação de desastres do banco de dados e não está relacionado a ela. A finalidade do backup de banco de dados é restaurar um estado consistente. Por exemplo, se um banco de dados for perdido ou corrompido, ou um estado anterior precise ser recuperado por conta de falhas ou bugs no app.
Na seção a seguir, você vê como usar backups como um mecanismo possível para implementar a recuperação de desastres do banco de dados. Nesse cenário, você copia os arquivos de backup para o local do banco de dados secundário para que ele possa ser restaurado. No entanto, os arquivos de backup não são um pré-requisito da recuperação de desastres. Você encontra alternativas nas informações anteriores sobre os recursos de disponibilidade.
Alta disponibilidade e recuperação de desastres
Tanto a alta disponibilidade quanto a recuperação de desastres fornecem soluções para a falha do banco de dados. Se o banco de dados primário falhar, o secundário será o novo primário, com consistência e disponibilidade.
A diferença entre alta disponibilidade e recuperação de desastres é o domínio de ponto único de falha. Com a alta disponibilidade, você resolve uma interrupção em uma região. Por exemplo, quando uma única zona ou nó falham. Essa solução fornece um novo banco de dados primário em outra zona na mesma região. Além disso, a alta disponibilidade resolve as falhas no nó, e não apenas no banco de dados. Se um nó que executa uma instância do SQL Server falhar, outro será disponibilizado, executando uma nova instância do SQL Server. Para mais informações, consulte a seção Instância de cluster de failover sempre ativada.
A recuperação de desastres envolve pelo menos duas regiões e entra em cena quando uma região inteira fica indisponível. Ela fornece um novo banco de dados primário em uma região diferente.
Os recursos de alta disponibilidade do SQL Server são compatíveis com soluções de alta disponibilidade e recuperação de desastres ao mesmo tempo. Um único grupo de disponibilidade abrange as zonas de uma região, bem como as próprias regiões. Eles podem conter instâncias de cluster de failover para processar a alta disponibilidade.
O SQL Server estabelece grupos de disponibilidade em uma região no caso de alta disponibilidade e falhas de zona. Ele os combina ao envio de registros entre regiões para lidar com a recuperação de desastres.
Alternativas de implantação de recuperação de desastres
Nas seções a seguir, você vê algumas topologias possíveis de recuperação de desastres, além daquelas já abordadas. Essas topologias atendem a diferentes requisitos de RPO e RTO. Esta lista não está completa.
Alta disponibilidade e recuperação de desastres intrarregional
Esta implantação é uma variação de um grupo de disponibilidade que contém FCIs em uma região que inclui três zonas. Neste cenário, as zonas são consideradas o domínio de ponto único de falha.
Em comparação com a implantação mostrada anteriormente, cada FCI inclui três nós. Cada um deles está em execução em uma zona diferente. A vantagem dessa configuração é que uma ou ambas as zonas podem falhar sem exigir o processo de recuperação de desastres.
O diagrama a seguir mostra esta configuração.
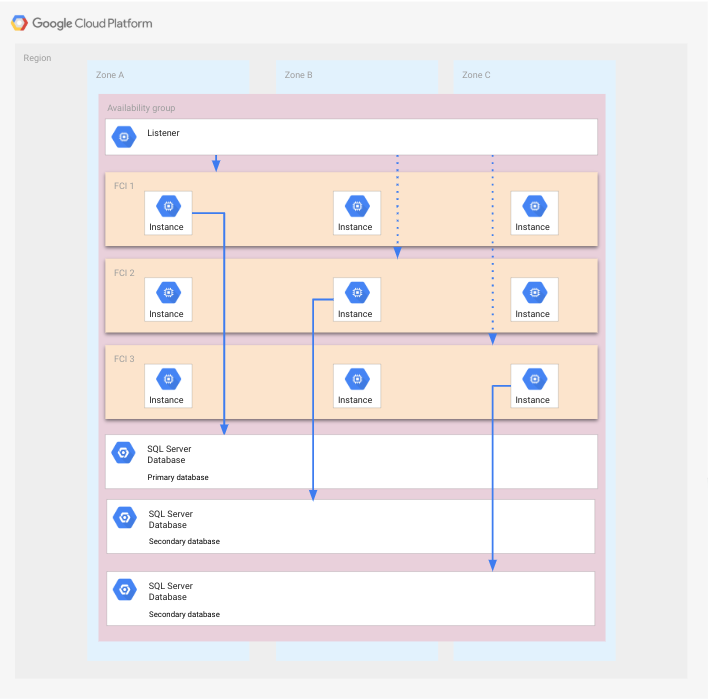
As FCIs abrangem todas as zonas, e cada uma delas tem uma instância do SQL Server em execução que acessa o banco de dados correspondente. Cada FCI também inclui mais duas instâncias do SQL Server que não estão em execução. É possível iniciá-las quando uma região falha. Os bancos de dados são mostrados entre as zonas, porque cada banco de dados usa os discos de todos os nós em uma determinada FCI. Para maior clareza, não é mostrado um aplicativo.
DR inter-regional: grupo de disponibilidade que abrange regiões
Neste cenário, um grupo de disponibilidade é executado em um cluster de failover do Windows Server e abrange duas regiões. As regiões são consideradas um domínio de ponto único de falha.
O diagrama a seguir ilustra essa configuração.

Para resolver possíveis problemas de latência, configure as réplicas na região R1 para usar a propagação de transação síncrona. Além disso, defina as réplicas na região R2 para utilizar a propagação de transação assíncrona.
Recuperação de desastres inter-regional: transferência de arquivos de backup
Neste cenário, a transferência de arquivos de backup é usada. Dois grupos de disponibilidade em duas regiões estão vinculados. Cada grupo tem réplicas que recebem as transações de forma síncrona. Portanto, as réplicas secundárias de cada região têm configuração de espera ativa.
O diagrama a seguir ilustra essa configuração.
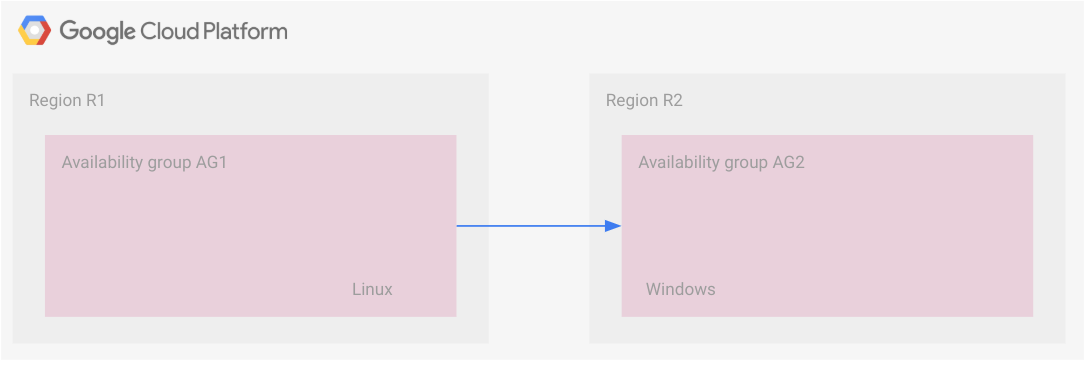
No entanto, os dois grupos de disponibilidade são conectados pela transferência de arquivos de backup. O grupo de disponibilidade AG1 é o primário, e o AG2 é o secundário. Como os arquivos de backup são disponibilizados para o grupo secundário, eles são aplicados lá. Veja este cenário em mais detalhes na próxima seção: Exemplo: estratégia de recuperação de desastres de backup e restauração.
Local duplo e topologia de localização terciária
Se você tiver apenas dois bancos de dados, ou seja, um primário e um secundário em uma região separada, haverá um período sem proteção após o failover. Isso acontece a partir do momento em que o novo banco de dados primário está em execução, e o novo banco de dados secundário fica pronto. Se o novo banco de dados primário ficar indisponível enquanto o secundário ainda não estiver em execução, poderá haver um grande tempo de inatividade. Só será possível resolvê-lo a partir do momento que um novo banco de dados primário for estabelecido. O mesmo se aplica aos grupos de disponibilidade.
Com um terceiro local que executa outro grupo de disponibilidade ou banco de dados secundário, você elimina o período sem proteção após o failover. Nessa configuração, você precisa garantir que um dos dois bancos de dados secundários permaneça nesse papel e seja reatribuído a um novo banco de dados primário para que não ocorra perda de dados. Como antes, o mesmo se aplica aos grupos de disponibilidade.
Ciclo de vida da DR
Seja qual for a solução de recuperação de desastres escolhida, há etapas comuns de ciclo de vida aplicáveis.
Em uma situação real de recuperação de desastres, todas as partes interessadas (proprietários de apps, grupos de operações e administradores de bancos de dados) precisam estar disponíveis e participar ativamente desse processo. As partes precisam escolher a autoridade responsável pelas decisões (às vezes chamada de mestre de cerimônia) e os processos de decisão que ela segue. Além disso, as partes interessadas precisam estabelecer uma terminologia e métodos de comunicação comuns.
Como decidir sobre a inicialização de um processo de failover
Quando o failover não é iniciado automaticamente, as partes interessadas precisam tomar essa decisão. É necessário que elas entrem em acordo para decidir sobre a inicialização do failover.
A inicialização do processo de failover depende de vários fatores, principalmente da causa raiz da indisponibilidade do banco de dados primário.
Se o processo de recuperação de desastres demorar mais do que o esperado para solucionar a indisponibilidade do banco de dados primário, o failover poderá ser prejudicial. Primeiro, você precisa avaliar se a restauração do banco de dados primário é uma opção viável.
Quanto melhor for o teste da estratégia de recuperação de desastres, e quanto mais rápido ela for implementada, mais fácil será de iniciar o processo de failover, já que a decisão será melhor embasada.
Execução do processo de failover
Na situação ideal, o processo de failover é testado regularmente e, por isso, é bem conhecido pelas várias partes interessadas.
A autoridade de decisão precisa estar ciente de todas as etapas e de todos os problemas inesperados que surgirem. A autoridade de decisão conduz o processo de failover e as partes interessadas são responsáveis por apoiar a autoridade de decisão.
Guarde as estatísticas para realizar análises retrospectivas e fazer melhorias no failover, incluindo a duração das atividades, problemas que surgiram e qualquer confusão nas etapas do processo.
Sem proteção
A partir do momento em que o novo banco de dados primário estiver disponível e operacional até que um novo secundário seja configurado, você não terá a proteção da recuperação de desastres. Isso é aplicável quando você conta com apenas um banco de dados secundário. Durante esse período, uma indisponibilidade pode causar um grande tempo de inatividade, porque não será possível realizar o failover para outro banco de dados. Se isso acontecer, será necessário configurar outro banco de dados primário, e o RPA é o último ponto que pode ser recriado com base nos backups disponíveis.
A menos que a estratégia de recuperação de desastres seja configurada para que haja proteção em todos os momentos, todas as partes interessadas precisam estar cientes desse período sem proteção. Assim, será possível tomar mais precauções durante as mudanças na definição de ambientes e configurações.
Para evitar esse período sem proteção, atrase o acesso do app ao novo banco de dados primário até que o novo secundário esteja em execução. Assim que as alterações do banco de dados primário forem aplicadas, ele ficará disponível para os apps. Com essa abordagem, você evita que os apps fiquem desprotegidos. No entanto, ela atrasa a conclusão do processo de recuperação de desastres.
Evitar casos de "dupla personalidade"
É essencial que os apps não possam acessar um banco de dados primário e um secundário ao mesmo tempo, o que emite operações DML. Nesse caso, ocorre uma inconsistência de dados, em que o banco de dados primário e secundário têm valores de dados discordantes para o mesmo item (dupla personalidade) [em inglês]. Essa arquitetura é especialmente importante se o banco de dados primário ficar indisponível enquanto continua em execução e pode receber operações de gravação. Quando a indisponibilidade é causada pelo particionamento intermitente de rede, ele pode parar a qualquer momento, garantindo acesso novamente ao app. Se houver um failover naquele momento, as alterações no banco de dados primário antigo poderão ser perdidas. Ou então, alguns apps começarão a funcionar no novo banco de dados primário, enquanto os outros ainda estarão acessando o primário antigo.
Durante o failover, todo o acesso do app é desativado em qualquer banco de dados. Assim, nenhuma alteração de estado acontece em qualquer banco de dados. Após o failover, apenas um banco de dados fica disponível para operações de gravação, ou seja, o novo banco de dados primário.
Declaração de conclusão
Após a conclusão do failover, a autoridade de decisão precisa informar explicitamente a todas as partes interessadas que o processo foi concluído. Qualquer problema que ocorrer após a conclusão precisa ser tratado como um incidente separado que não faz parte do failover, e sim do processamento regular. Esse problema pode ser a consequência de um erro no processo de failover ou algo isolado. No entanto, a forma como você resolve o problema antes e durante o processo de failover é diferente.
Relatório e análise retrospectiva
Para você consultar no futuro e melhorar o processo de failover, faça uma análise retrospectiva imediata. Assim, você descobre aspectos, informações e ações necessárias importantes.
Faça um relatório que resuma o evento de recuperação de desastres, as causas raiz e todas as ações executadas. Esse relatório poderá ser obrigatório se você estiver implementando requisitos regulamentares.
Verificação e teste de recuperação de desastres
Como a recuperação de desastres não faz parte das tarefas rotineiras, você precisa testar sua solução regularmente para garantir o funcionamento adequado quando ela realmente for necessária.
A frequência do teste depende dos requisitos operacionais e varia de acordo com o banco de dados, o app e a empresa. Além disso, o teste de recuperação de desastres pode ser acionado no caso de alterações no ambiente, como mudanças na configuração de rede e atualizações nos componentes de infraestrutura. Isso se aplica apenas se as alterações forem feitas nos sistemas em que a solução escolhida de recuperação de desastres se baseia. Qualquer alteração pode causar falhas na solução de recuperação de desastres ou exigir o ajuste do processo.
Para fazer o teste manual, inicie o processo de alternância. Se quiser fazer o teste automaticamente, siga a abordagem da engenharia de caos, conforme descrita nesta página (em inglês). Com o teste manual, você diminui o impacto nos negócios no caso de tempo de inatividade esperado.
Um aspecto importante do teste é a coleta de estatísticas detalhadas. Estas são algumas estatísticas importantes a serem consideradas:
- Tempo de recuperação real (em inglês): avalie o tempo de recuperação real e compare-o com o RTO.
- Ponto de recuperação real (em inglês): observe o ponto de recuperação real e compare-o com o RPO.
- Tempo até detecção de falha: quanto tempo os administradores de bancos de dados ou a equipe de operações levaram para perceber a necessidade de failover.
- Tempo para início da recuperação: quanto tempo levou para iniciar o processo de failover após a falha ter sido detectada.
- Confiabilidade: o processo de failover foi seguido estritamente de acordo com a estratégia, ou foram necessárias soluções alternativas? Ocorreram problemas inesperados que precisam ser investigados, gerados possivelmente por uma mudança na estratégia de recuperação?
Com base nas estatísticas coletadas, o processo de failover pode ser ajustado ou aprimorado para melhor corresponder às expectativas de RPO e RTO.
Exemplo: estratégia de recuperação de desastres de backup e restauração
Nas seções a seguir, você vê um exemplo de estratégia de recuperação de desastres de backup e restauração. Nesse cenário, o uso de recursos de disponibilidade do SQL Server é reduzido. O objetivo é demonstrar o trabalho necessário para especificar uma estratégia de backup e restauração de recuperação de desastres e discutir aspectos que passam despercebidos em configurações mais automatizadas.
Caso de uso
Um grupo de disponibilidade primário sempre ativado está localizado e funciona na região R1. Já o secundário correspondente fica na região R2 para garantir proteção extra entre localizações. Ele está disponível como destino de failover ou de alternância.
Estratégia
A estratégia de recuperação de desastres é baseada em backups do banco de dados. Um backup completo inicial é usado, seguido por backups diferenciais posteriores. Eles são aplicados ao grupo de disponibilidade secundário sempre ativado conforme coletados. Todos os backups são armazenados em um bucket do Cloud Storage.
Neste exemplo, é aceitável que, após a conclusão do failover, o novo grupo de disponibilidade primário sempre ativado em R2 fique ativo e desprotegido por um período limitado até que o novo secundário correspondente em R1 entre em funcionamento.
Não é necessário fazer o fallback porque o grupo de disponibilidade sempre ativado de cada região é igualmente qualificado para funcionar como um grupo de disponibilidade sempre ativado de produção.
RTO e RPO
Neste exemplo, o RPO é definido como o total de 60 minutos. Portanto, um backup diferencial é feito a cada 60 minutos.
O RTO não é definido explicitamente como um período, mas ele precisa ser o menor possível. No melhor caso, ele precisa ser imediato. É necessário que o grupo de disponibilidade secundário seja configurado com a espera ativa. Nesse tipo de espera, todos os backups são aplicados imediatamente para que o failover não seja atrasado por esse processo.
Estratégia de recuperação de desastres detalhada
Nas seções a seguir, você verá a descrição da estratégia de recuperação de desastres. As informações estão resumidas para você se concentrar nas etapas essenciais.
Configuração inicial
- Crie o grupo de disponibilidade secundário sempre ativado na região R2.
- Impeça o acesso do app ao grupo de disponibilidade secundário para que nenhum caso de dupla personalidade ocorra sem querer.
- Crie o bucket de arquivos de backup B1 no Cloud Storage para armazenar o backup completo inicial e os backups diferenciais posteriores por hora do grupo de disponibilidade sempre ativado em R1. É necessário estabelecer a ordem correta dos backups diferenciais para que ela possa ser inferida pelo processo de aplicação dos backups ao grupo de disponibilidade secundário. Por exemplo, é possível usar uma convenção de nomenclatura para estabelecer a ordem cronológica correta com base na data e horário que começam a fazer parte dos vários nomes de arquivo.
Estratégia de lançamento
- Aplique o backup completo ao grupo de disponibilidade secundário sempre ativado na região R2.
- À medida que os backups diferenciais ficam disponíveis, aplique-os imediatamente ao grupo de disponibilidade secundário sempre ativado em R2. Isso é necessário para atender ao RTO.
- Depois que o backup completo inicial e todos os incrementais forem aplicados, o grupo de disponibilidade secundário sempre ativado estará pronto.
- Teste a estratégia de recuperação de desastres. Para isso, execute uma alternância do grupo de disponibilidade primário para o secundário. Pelo menos um backup incremental estará disponível durante o teste.
Caso de failover ou alternância
Em R2, as etapas essenciais são as seguintes:
- Garanta que o backup diferencial mais recente tenha sido aplicado ao grupo de disponibilidade secundário sempre ativado em R2.
- Defina R2 como o novo grupo de disponibilidade primário sempre ativado.
- Crie um novo bucket B2, use um backup completo como valor de referência e permita o acesso do app ao novo grupo de disponibilidade primário.
- Comece a coletar backups diferenciais.
Em R1, as etapas essenciais são as seguintes:
- Remova o bucket B1 porque ele não é mais necessário.
- Quando o grupo de disponibilidade sempre ativado em R1 ficar disponível novamente como o novo grupo secundário, impeça o acesso do app. Depois, remova todos os dados do banco de dados ou o redefina para seu estado inicial (vazio), a menos que ele tenha sido criado do zero.
- Aplique o backup completo do novo grupo de disponibilidade primário sempre ativado em R2 e continue aplicando backups diferenciais imediatamente à medida que eles ficam disponíveis (armazenados no bucket B2).
Melhorias possíveis
Uma melhoria possível na estratégia de recuperação de desastres é evitar a coleta de um backup completo após um failover ou alternância, enquanto ainda é possível configurar rapidamente o novo grupo de disponibilidade secundário. Em vez de um único backup completo e backups diferenciais posteriores, faça um backup completo toda semana. Além disso, crie um bucket semanal que contenha o backup completo da semana e todos os posteriores relacionados. O novo grupo de disponibilidade primário precisa criar backups diferenciais, e não um backup completo, somente após o failover e adicioná-los ao bucket. O novo grupo de disponibilidade secundário aplica todos os backups no bucket da semana atual. Se você já usa essa abordagem semanal, é necessário implementar uma estratégia de limpeza para remover os backups obsoletos.
Outra melhoria é baseada no fato de que o novo grupo de disponibilidade secundário era o antigo grupo de disponibilidade primário. Se o banco de dados ainda existir e estiver operacional depois de voltar a ficar disponível, faça uma recuperação pontual do último backup diferencial. Isso evita a necessidade de restaurá-lo completamente a partir do último backup completo, conforme descrito em Restaurar um banco de dados do SQL Server até um ponto determinado (modelo de recuperação completa). Esse cenário reduz o esforço e a quantidade de tempo em que o novo grupo de disponibilidade primário está desprotegido.
Práticas recomendadas de produção
Esta solução não especifica se as instâncias do SQL Server nos grupos de disponibilidade sempre ativados são independentes ou FCI. O tipo de instâncias usadas precisa ser escolhido antes da implementação.
Até que um novo grupo de disponibilidade secundário sempre ativado esteja operacional depois de um failover, há um período em que a recuperação de desastres não está protegida. Você precisa configurar um terceiro grupo de disponibilidade sempre ativado em uma terceira região.
Além disso, é necessário implementar o monitoramento para garantir que qualquer falha ou erro seja detectado. O monitoramento não está no escopo deste documento, mas é algo essencial para qualquer solução de recuperação de desastres.
A seguir
- Como configurar grupos de disponibilidade sempre ativados do SQL Server.
- Como implantar um grupo de disponibilidade sempre ativado do SQL Server 2016 em várias sub-redes no Compute Engine.
- Como configurar instâncias de cluster de failover do SQL Server.
- Como executar o clustering de failover do Windows Server.
- Como ativar o Cloud Logging, o Cloud Monitoring e o Error Reporting para aplicativos .NET.
- Como instalar o agente do Cloud Monitoring.
- Confira arquiteturas de referência, diagramas e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.