Este documento descreve como aceder e ver as métricas de máquinas virtuais (VMs). Também descreve como rever as métricas da VM para saber mais sobre as suas VMs ou resolver problemas específicos com uma VM.
A monitorização de instâncias de máquinas virtuais (VMs) é essencial para manter os seus recursos de VM. O Compute Engine oferece uma vista de alto nível das métricas de VM através do separador Observabilidade na Google Cloud consola. Este separador apresenta um painel de controlo predefinido com dados de telemetria para que possa monitorizar as suas VMs e tomar decisões informadas sobre os recursos do Compute Engine. Também pode personalizar o painel de controlo predefinido para ver apenas as métricas específicas que quer.
Todas as VMs têm dados de utilização de processos básicos disponíveis quando são criadas. No entanto, a instalação do agente do Ops fornece estatísticas mais detalhadas sobre o comportamento da VM.
Para mais informações sobre como criar uma política de alertas de monitorização, usar o Explorador de métricas ou informações gerais sobre como a monitorização e as métricas funcionam no Google Cloud, consulte os documentos do Cloud Monitoring.
Antes de começar
Opcional: instale o agente de operações para recolher dados mais detalhados das suas instâncias do Compute Engine.
Para verificar que instâncias de VM têm o agente Ops instalado, faça o seguinte:
Na Google Cloud consola, aceda a Painéis de controlo de monitorização
Selecione Instâncias de VM na lista do painel de controlo.
Clique em Lista para ver as VMs como uma lista.
São apresentadas todas as VMs no seu projeto. A coluna Agente mostra o estado da instalação do agente de operações. Pode instalar ou atualizar o agente a partir desta página.
Opcional: para atualizar o painel de controlo Predefinido para apresentar eventos, como os que indicam uma atualização a um grupo de instâncias gerido, clique em event_available Selecionar eventos e, de seguida, conclua a caixa de diálogo.
Para mais informações sobre eventos, consulte o artigo Tipos de eventos.
Aceda às métricas de observabilidade da VM
Aceda às informações de uma ou várias VMs através do separador Observabilidade na Google Cloud consola. Por predefinição, um painel de controlo predefinido apresenta as métricas de VM. Se quiser ver apenas as métricas específicas que pretende, pode criar um painel de controlo personalizado.
Veja métricas de observabilidade para uma única VM
As métricas básicas da VM, como a utilização da CPU e o tráfego de rede, estão disponíveis para si quando cria a VM. As métricas de utilização da memória e dos processos só estão disponíveis com a instalação do agente de operações, que é o agente principal para recolher telemetria das suas instâncias do Compute Engine.
Para ver as métricas de uma única MV, faça o seguinte:
Na Google Cloud consola, aceda à página Instâncias de VM.
Selecione uma VM para abrir a página Detalhes.
Clique no separador Observabilidade para apresentar informações sobre a VM.
Opcional: reponha o período predefinido de uma hora para o período que quer monitorizar.
Opcional: para atualizar o painel de controlo Predefinido para apresentar eventos, como os que indicam uma atualização a um grupo de instâncias gerido, clique em event_available Selecionar eventos e, de seguida, conclua a caixa de diálogo.
Para mais informações sobre eventos, consulte o artigo Tipos de eventos.
As informações na Figura 1 apresentam os detalhes da VM sem o agente de operações instalado na VM. Repare que os gráficos Memória e Utilização do espaço em disco não têm dados.
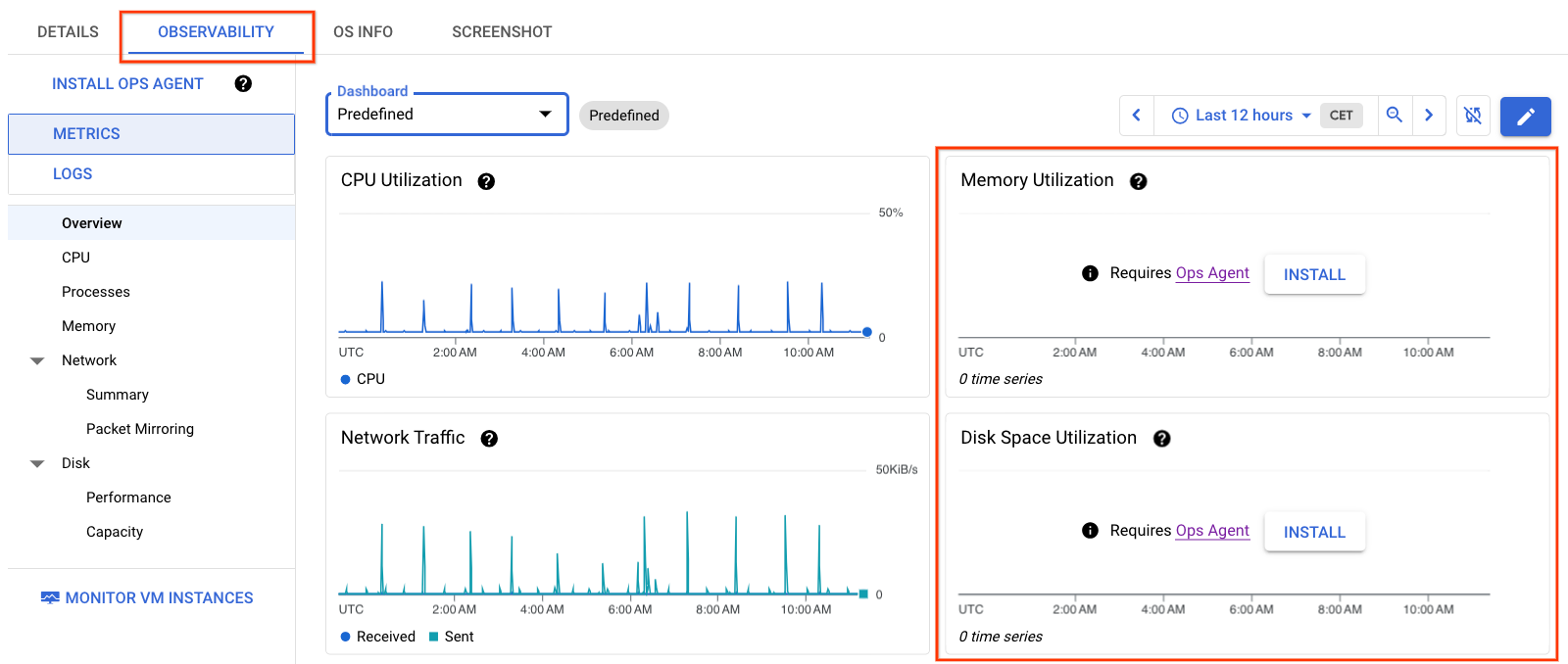
Veja métricas de observabilidade para várias VMs
A observabilidade ao nível da frota apresenta as métricas das cinco principais VMs com a utilização de processos mais elevada. As 5 principais VMs apresentadas variam consoante a métrica. Pode não ver as mesmas cinco VMs para cada processo. Embora existam mais dados disponíveis ao nível da frota sem instalar o Ops Agent em comparação com a quantidade de dados disponíveis para uma única VM, a instalação do agente fornece mais dados para fins de resolução de problemas futuros.
Para ver as métricas de várias VMs, faça o seguinte:
Na Google Cloud consola, aceda à página Instâncias de VM.
Clique no separador Observabilidade.
Opcional: reponha o período predefinido de uma hora para o período que quer monitorizar.
Filtre os resultados por uma ou mais das seguintes opções:
- ID
- Nome
- Tipo de máquina
- Zona
- Região
- Grupo de instâncias
- Etiquetas
- Estado
As informações na Figura 2 apresentam um exemplo do separador Observabilidade quando várias VMs num projeto têm o agente de operações instalado. Repare que existem mais métricas disponíveis sobre estas VMs.
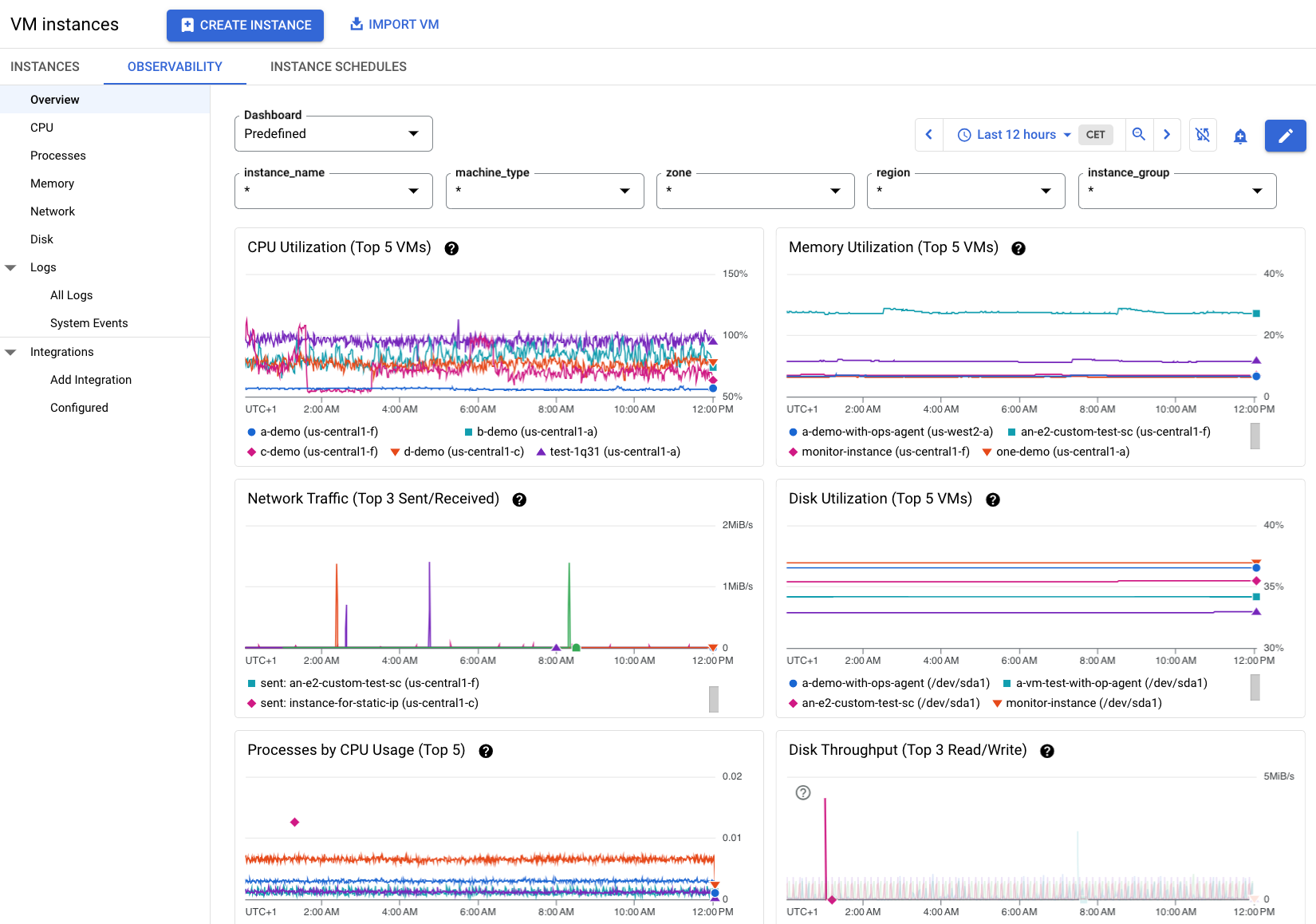
Veja métricas detalhadas de uma VM
Cada métrica do processo de MV é representada por uma linha de gráfico num gráfico. No exemplo seguinte, a VM uptime-demo tem o agente Ops instalado. Os dados de utilização da memória estão disponíveis para fins de resolução de problemas. Se uma VM não estiver indicada no cartão, filtre pelo nome da VM para encontrar uma VM específica.
Para obter as informações sobre esta VM ou outra das cinco principais VMs no separador Observabilidade, faça o seguinte:
- Mantenha o ponteiro sobre a linha do gráfico de qualquer VM. É apresentado um cartão com uma lista das cinco principais VMs que usam o processo, cada uma a apresentar uma métrica.
- Para saber mais sobre o comportamento da VM, clique na linha do gráfico da VM ou num nome de VM específico na lista.
A VM uptime-demo apresentada no cartão na Figura 3 revela algumas métricas que podem exigir uma revisão.
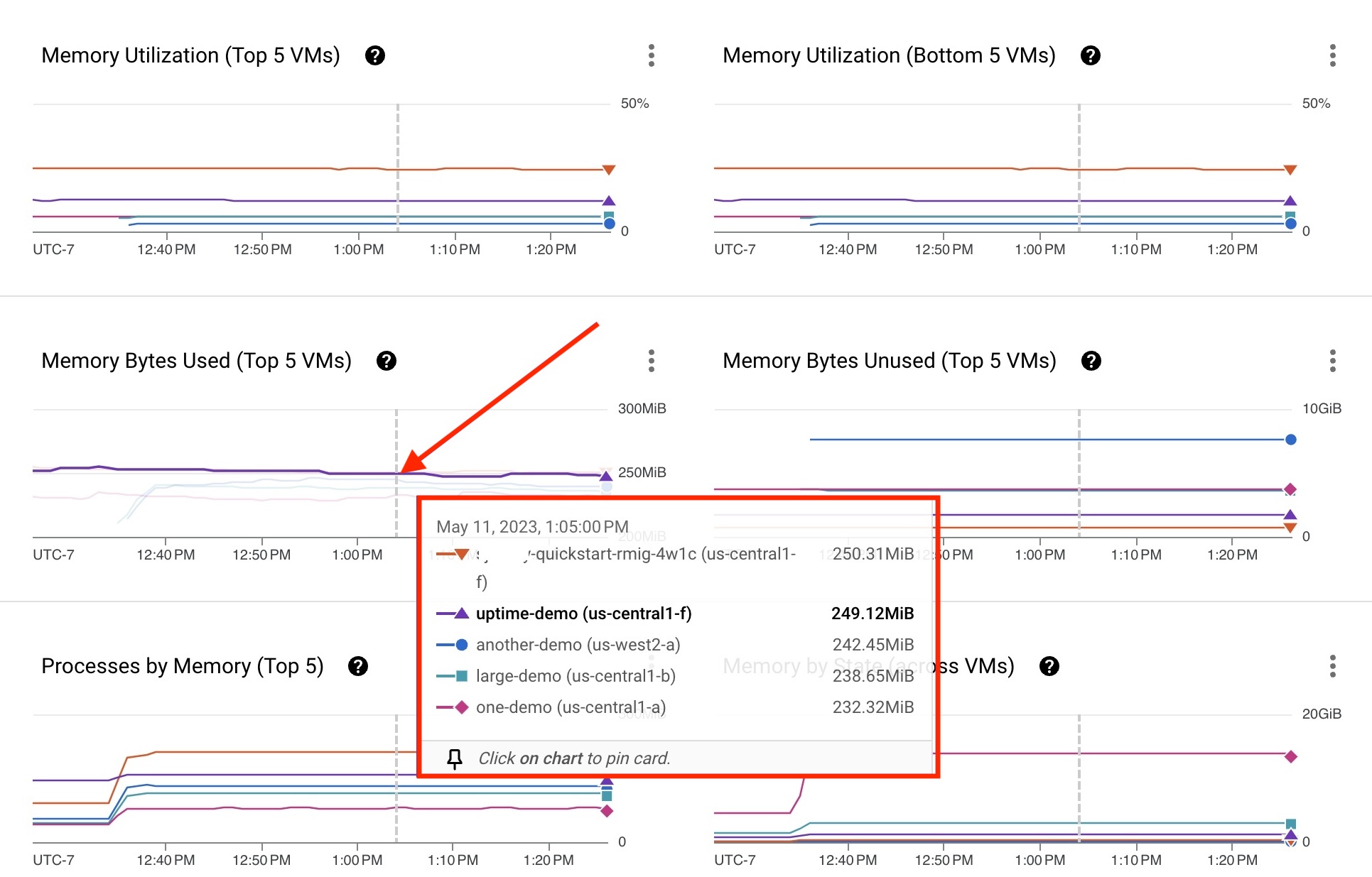
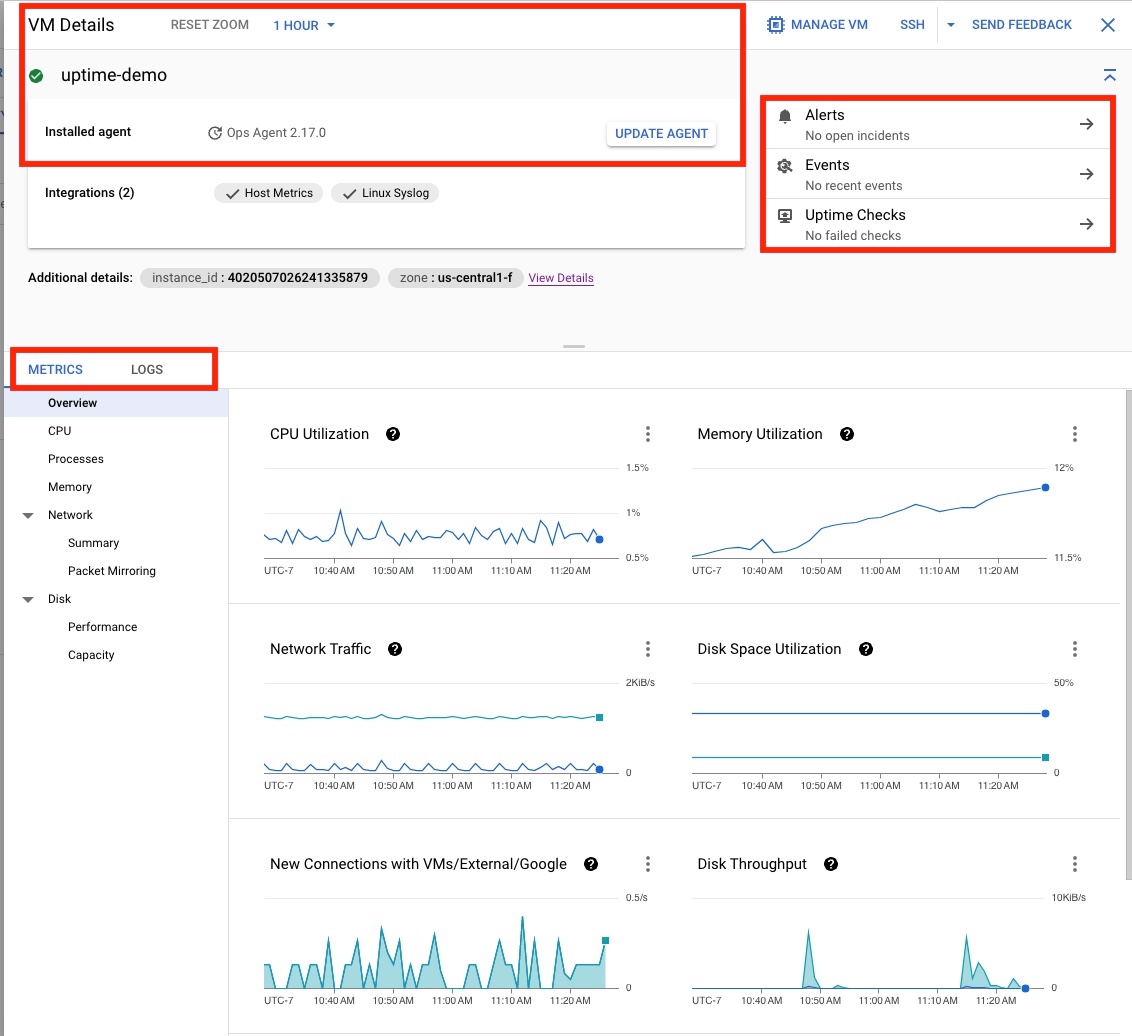
Clique na VM uptime-demo para abrir a página Detalhes da VM apresentada na Figura 4, que fornece as seguintes informações:
- O estado do Ops Agent.
- As opções no contexto para criar Alertas, verificar Eventos> ou criar Verificações de tempo de atividade.
- A opção para ver os detalhes das configurações, das métricas e dos registos da VM.
Crie um painel de controlo personalizado para ver métricas específicas
Por predefinição, o separador Observabilidade no Compute Engine fornece um painel de controlo predefinido que apresenta métricas básicas de VMs. Para ver apenas as métricas específicas que quer ver, pode modificar o painel de controlo predefinido e guardá-lo como um painel de controlo personalizado. Pode personalizar ainda mais o painel de controlo conforme pretender.
Para criar um painel de controlo personalizado, faça o seguinte:
Na Google Cloud consola, aceda à página Instâncias de VM.
Aceda ao separador Observabilidade da seguinte forma:
- Para uma única VM: na página Instâncias de VM, clique no nome da VM para abrir a respetiva página de Detalhes e, de seguida, clique no separador Observabilidade dessa VM.
- Para várias VMs: na página Instâncias de VM, clique no separador Observabilidade.
Se o menu pendente Painel de controlo estiver ativado, os painéis de controlo personalizados estão disponíveis. Para modificar uma vista personalizada, selecione uma vista personalizada no menu pendente e, de seguida, na barra de ferramentas do painel de controlo, clique em .
Caso contrário, para personalizar o painel de controlo predefinido, na barra de ferramentas do painel de controlo, clique em .
O Compute Engine cria uma cópia do painel de controlo predefinido e, em seguida, abre a cópia no modo de edição.
No editor, pode adicionar, modificar, eliminar, reposicionar ou redimensionar as visualizações no painel de controlo. As visualizações são denominadas coletivamente widgets. Para mais informações sobre os diferentes tipos de widgets, consulte o artigo Vista geral dos painéis de controlo.
Para adicionar um widget, na barra de ferramentas do painel de controlo, clique em Adicionar widget e conclua a configuração.
Por exemplo, para ver os registos com os dados das métricas, clique em Adicionar widget, selecione Registos e, de seguida, clique em Aplicar.
Para modificar um widget, coloque o ponteiro sobre o widget para ativar a barra de ferramentas, clique em Editar widget e, em seguida, use a caixa de diálogo Configurar widget. Para aplicar as alterações ao painel de controlo, na barra de ferramentas, clique em Aplicar. Para rejeitar as alterações, clique em Cancelar.
Para eliminar um widget, posicione o ponteiro sobre o widget para ativar a barra de ferramentas, clique em Mais opções do gráfico e, de seguida, selecione Eliminar.
Para reposicionar um widget, use o ponteiro para arrastar o widget pelo cabeçalho para uma nova localização.
Para redimensionar um widget, use o ponteiro para reposicionar o canto direito do widget.
Quando terminar de modificar o painel de controlo, clique em Guardar.
Na caixa de diálogo que confirma as alterações, clique em Ver painel de controlo personalizado para aceder à vista personalizada.
Pode voltar à vista predefinida selecionando Predefinido no menu pendente Painel de controlo.
Reveja as métricas de recursos
Para saber mais sobre cada métrica de recursos, clique em cada processo no menu do separador Observabilidade:
- Explore a utilização da CPU, dos processos, da memória, do tráfego de rede e do disco.
- Veja os dados de registo pesquisando Registos para identificar e ver Eventos do sistema.
- Adicione integrações de terceiros e verifique se existem integrações configuradas.
O resto desta secção descreve exemplos de como alguns processos podem afetar as suas cargas de trabalho. Estas informações pressupõem que o agente de operações está instalado nas suas VMs.
Utilização da CPU
Um exemplo de utilização extrema da CPU pode ocorrer quando um servidor está sob uma carga inesperadamente pesada, como quando um Website regista um aumento súbito no tráfego ou quando uma tarefa de processamento de dados em grande escala está em curso. Nestas situações, a CPU pode estar a funcionar a 100% da capacidade durante um período prolongado, o que pode fazer com que o servidor fique mais lento ou deixe de responder.
Neste exemplo, a saturação é o motivo de preocupação. Se a utilização da CPU for de 100%, isso pode ser adequado para as suas cargas de trabalho, mas é recomendável examinar outras métricas para saber se isto requer intervenção. Neste caso, é recomendável criar uma política de alertas para receber uma notificação quando a utilização da CPU de uma VM aumentar repentinamente.
Com as autorizações adequadas, pode estabelecer ligação às suas VMs através de SSH para investigar o problema. No entanto, se o agente de operações estiver instalado, pode ver mais dados do histórico para ajudar a resolver problemas.
Utilização do processo
Um exemplo de comportamento de processo extremo pode ser quando um processo está a consumir uma quantidade excessiva de recursos, como CPU, memória ou E/S de disco, ao ponto de causar uma degradação do desempenho ou até falhas na VM.
Por exemplo, se um processo em execução numa VM estiver a sofrer uma fuga de memória, pode começar a consumir quantidades cada vez maiores de memória ao longo do tempo, o que acaba por fazer com que a VM fique sem memória e falhe. Da mesma forma, se um processo estiver a usar o disco em grande medida, pode fazer com que a E/S do disco da VM fique saturada, o que leva a tempos de resposta lentos para outros processos.
Utilização da memória
As bases de dados requerem uma grande quantidade de memória para realizar operações como a indexação, a ordenação e a junção de tabelas.
Um exemplo de utilização elevada de memória numa VM é quando executa um servidor de base de dados, como o Cloud SQL para MySQL ou o Cloud SQL para PostgreSQL, com um grande conjunto de dados. Se a memória disponível da sua MV for demasiado pequena, o recarregamento de um conjunto de dados na memória pode fazer com que a base de dados seja executada lentamente ou falhe.
Desempenho da rede
Os problemas de desempenho da rede são o resultado de diferentes fatores: congestionamento, limitações de largura de banda, problemas de hardware ou software e latência. Para diagnosticar o problema, monitorize as métricas de desempenho da rede, resolva problemas de hardware e software, e analise os padrões de tráfego de rede para identificar e resolver a causa principal do problema.
Utilização do disco
A utilização elevada do disco numa VM ocorre quando existe uma grande quantidade de dados a ser lida ou escrita no disco virtual, o que resulta num atraso no acesso ao disco e num possível efeito no desempenho da VM.
A monitorização de métricas de utilização do disco, como as operações de E/S do disco por segundo (IOPS), o comprimento da fila do disco e o tempo de resposta médio do disco, pode ajudar a identificar e diagnosticar problemas de utilização elevada do disco numa VM.
Verifique os registos e os eventos do sistema
A página Todos os registos fornece dados de registo sobre os seus recursos. Ordene por gravidade para identificar problemas e inspecionar a carga útil.
Os registos de auditoria registam eventos administrativos que ocorrem nos seus recursos. Os registos podem indicar o que aconteceu para acionar o evento. São registados e mantidos vários registos na mesma linha. Por exemplo, se tiver 20 registos idênticos, as informações são armazenadas numa linha, em vez de 20 linhas separadas.
Pode considerar os Eventos do sistema como um termo genérico para eventos que ocorrem a um nível superior, mas que podem afetar os seus recursos do Compute Engine. Um evento do sistema ocorre quando é acionado um erro não relacionado com um evento planeado. Os eventos do sistema são registados ao nível da frota.
Use integrações de terceiros
A monitorização oferece integrações com aplicações de terceiros. Estas integrações permitem-lhe recolher telemetria de aplicações como o Apache Web Server, o Cloud SQL para MySQL, o Memorystore para Redis e outras para implementações executadas no Compute Engine e no GKE. Quando usa o Compute Engine, a telemetria de terceiros é recolhida pelo agente de operações.