Para ajudar a melhorar a utilização dos recursos, pode acompanhar as taxas de utilização da GPU das suas instâncias de máquinas virtuais (VM).
Quando conhece as taxas de utilização da GPU, pode realizar tarefas como configurar grupos de instâncias geridos que podem ser usados para ajustar automaticamente a escala dos recursos.
Para rever as métricas da GPU através do Cloud Monitoring, conclua os seguintes passos:
- Em cada MV, configure o script de relatórios de métricas da GPU. Este script instala o agente de relatórios de métricas da GPU. Este agente é executado em intervalos na VM para recolher dados da GPU e envia estes dados para o Cloud Monitoring.
- Em cada VM, execute o script.
- Em cada VM, defina o agente de relatórios de métricas de GPU para iniciar automaticamente no arranque.
- Veja os registos no Google Cloud Cloud Monitoring.
Funções necessárias
Para monitorizar o desempenho da GPU em VMs do Windows, tem de conceder as funções de gestão de identidades e acessos (IAM) necessárias aos seguintes princípios:
- A conta de serviço usada pela instância de VM
- A sua conta de utilizador
Para garantir que tem e que a conta de serviço da VM tem as autorizações necessárias para monitorizar o desempenho da GPU em VMs do Windows, peça ao seu administrador para lhe conceder e à conta de serviço da VM as seguintes funções de IAM no projeto:
-
Administrador de instâncias do Compute (v1) (
roles/compute.instanceAdmin.v1) -
Monitoring Metric Writer (
roles/monitoring.metricWriter)
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
O administrador também pode conceder-lhe e à conta de serviço da VM as autorizações necessárias através de funções personalizadas ou outras funções predefinidas.
Configure o script de relatórios de métricas da GPU
Requisitos
Em cada uma das suas VMs, verifique se cumpre os seguintes requisitos:
- Cada VM tem de ter GPUs anexadas.
- Cada MV tem de ter um controlador de GPU instalado.
Transfira o script
Abra um terminal do PowerShell como administrador e use o comando Invoke-WebRequest para transferir o script.
Invoke-WebRequest está disponível no PowerShell 3.0 ou posterior.
Google Cloud recomenda que use ctrl+v para colar os blocos de código copiados.
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
Execute o script
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
Configure o agente para iniciar automaticamente no arranque
Para garantir que o agente de relatórios de métricas da GPU está configurado para ser executado no arranque do sistema, use o seguinte comando para adicionar o agente ao Agendador de tarefas do Windows.
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
Reveja as métricas no Cloud Monitoring
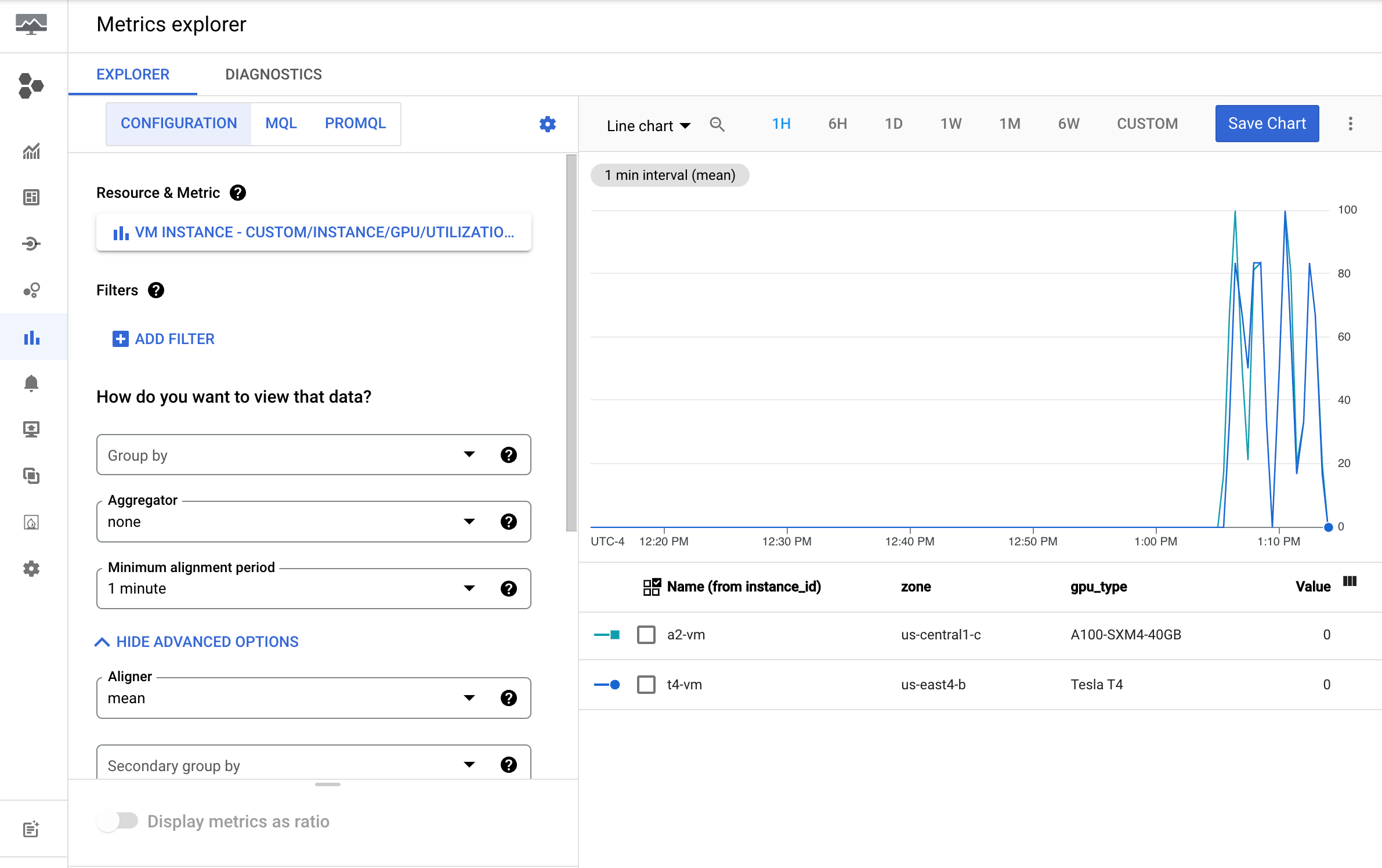
Na Google Cloud consola, aceda à página Explorador de métricas.
Expanda o menu Selecionar uma métrica.
No menu Recurso, selecione Instância de VM.
No menu Categoria de métricas, selecione Personalizado.
No menu Métrica, selecione a métrica a representar no gráfico. Por exemplo
custom/instance/gpu/utilization.Clique em Aplicar.
A utilização da GPU deve ser semelhante ao seguinte resultado:
Métricas disponíveis
| Nome da métrica | Descrição |
|---|---|
instance/gpu/utilization |
Percentagem do tempo durante o período de amostragem anterior em que um ou mais kernels estavam a ser executados na GPU. |
instance/gpu/memory_utilization |
Percentagem do tempo durante o período de amostragem anterior em que a memória global (do dispositivo) estava a ser lida ou escrita. |
instance/gpu/memory_total |
Memória de GPU total instalada. |
instance/gpu/memory_used |
Memória total atribuída por contextos ativos. |
instance/gpu/memory_used_percent |
Percentagem da memória total atribuída por contextos ativos. Varia entre 0 e 100. |
instance/gpu/memory_free |
Memória livre total. |
instance/gpu/temperature |
Temperatura da GPU principal em Celsius (°C). |
O que se segue?
- Para processar a manutenção do anfitrião da GPU, consulte o artigo Processar eventos de manutenção do anfitrião da GPU.
- Para melhorar o desempenho da rede, consulte o artigo Use uma largura de banda da rede mais elevada.