リソースの利用効率を高めるために、仮想マシン(VM)インスタンスの GPU 使用率を追跡できます。
GPU の使用率がわかったら、リソースの自動スケーリングを可能にするマネージド インスタンス グループの設定などのタスクを実行できます。
Cloud Monitoring を使用して GPU 指標を確認するには、次の手順を行います。
- 各 VM で、GPU 指標レポート スクリプトを設定します。このスクリプトは、GPU 指標レポート エージェントをインストールします。このエージェントは、VM で一定の間隔を置いて実行され、収集した GPU データを Cloud Monitoring に送信します。
- 各 VM でスクリプトを実行します。
- 各 VM で、GPU 指標レポート エージェントを起動時に自動的に開始するように設定します。
- Google Cloud Cloud Monitoring でログを表示します。
必要なロール
Windows VM で GPU のパフォーマンスをモニタリングするには、次のプリンシパルに必要な Identity and Access Management(IAM)ロールを付与する必要があります。
- VM インスタンスで使用されるサービス アカウント
- ユーザー アカウント
Windows VM で GPU のパフォーマンスをモニタリングするために必要な権限がユーザーと VM のサービス アカウントに付与されていることを確認するには、プロジェクトに対する次の IAM ロールをユーザーと VM のサービス アカウントに付与するように管理者に依頼してください。
-
Compute インスタンス管理者(v1)(
roles/compute.instanceAdmin.v1) -
モニタリング指標の書き込み(
roles/monitoring.metricWriter)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
管理者は、カスタムロールや他の事前定義ロールを使用して、必要な権限をユーザーと VM のサービス アカウントに付与することもできます。
GPU 指標レポート スクリプトを設定する
要件
各 VM で次の要件を満たしていることを確認します。
- 各 VM に GPU が接続されている。
- 各 VM に GPU ドライバがインストールされている。
スクリプトをダウンロードする
管理者として PowerShell ターミナルを開き、Invoke-WebRequest コマンドを使用してスクリプトをダウンロードします。
Invoke-WebRequest は PowerShell 3.0 以降で使用できます。Google Cloud では、コピーしたコードブロックを貼り付ける場合は ctrl+v の使用をおすすめします。
mkdir c:\google-scripts cd c:\google-scripts Invoke-Webrequest -uri https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-monitoring/main/windows/gce-gpu-monitoring-cuda.ps1 -outfile gce-gpu-monitoring-cuda.ps1
スクリプトを実行する
cd c:\google-scripts .\gce-gpu-monitoring-cuda.ps1
起動時に自動的に開始するようにエージェントを構成する
GPU 指標レポート エージェントがシステム起動時に実行されるように設定するには、次のコマンドを使用してエージェントを Windows タスク スケジューラに追加します。
$Trigger= New-ScheduledTaskTrigger -AtStartup $Trigger.ExecutionTimeLimit = "PT0S" $User= "NT AUTHORITY\SYSTEM" $Action= New-ScheduledTaskAction -Execute "PowerShell.exe" -Argument "C:\google-scripts\gce-gpu-monitoring-cuda.ps1" $settingsSet = New-ScheduledTaskSettingsSet # Set the Execution Time Limit to unlimited on all versions of Windows Server $settingsSet.ExecutionTimeLimit = 'PT0S' Register-ScheduledTask -TaskName "MonitoringGPUs" -Trigger $Trigger -User $User -Action $Action -Force -Settings $settingsSet
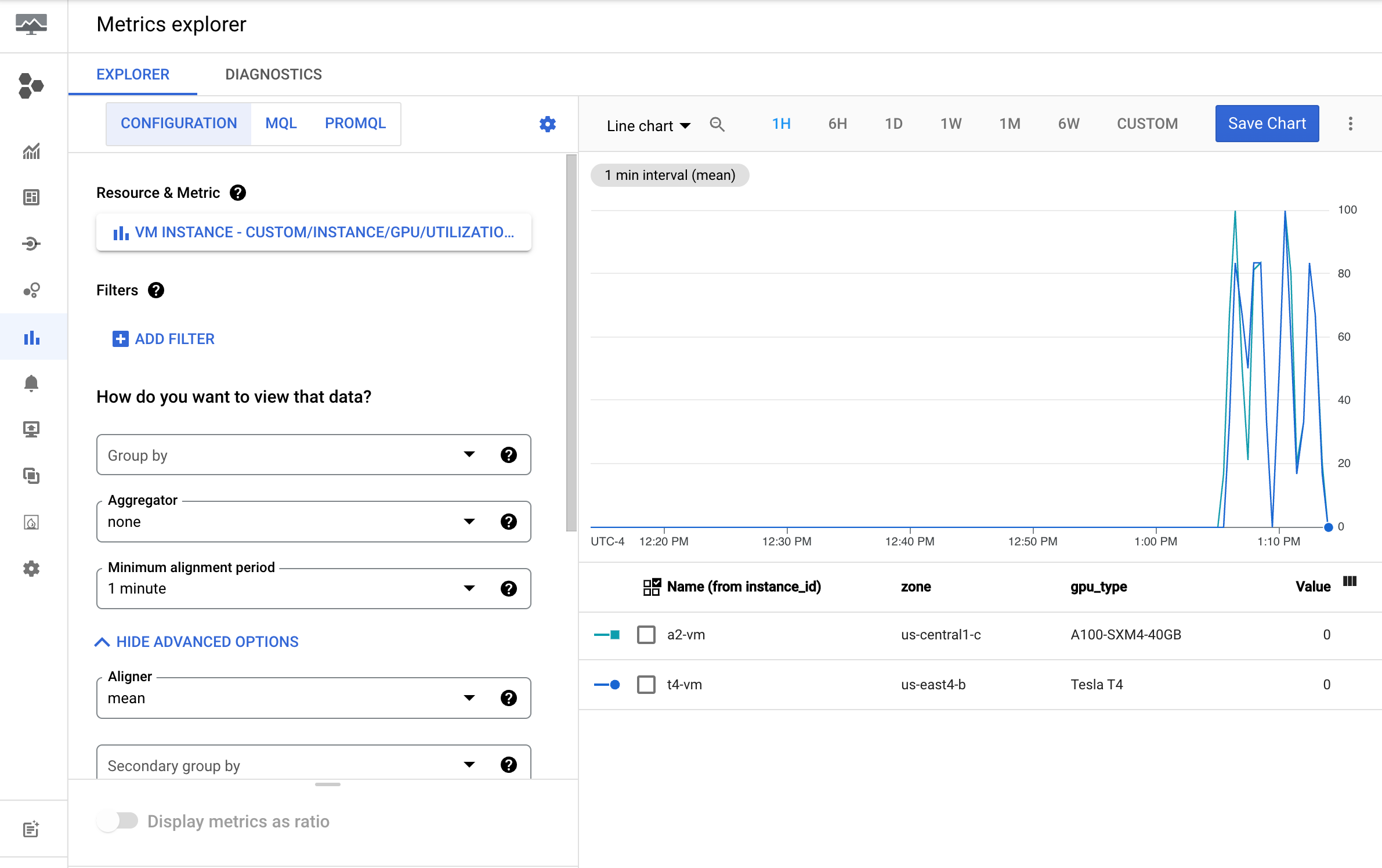
Cloud Monitoring で指標を確認する
Google Cloud コンソールで、[Metrics Explorer] ページに移動します。
[指標を選択] メニューを開きます。
[リソース] メニューで、[VM インスタンス] を選択します。
[指標カテゴリ] メニューで、[カスタム] を選択します。
[指標] メニューで、グラフにする指標を選択します。例:
custom/instance/gpu/utilization[適用] をクリックします。
GPU 使用率は次の出力のようになります。
利用可能な指標
| 指標名 | 説明 |
|---|---|
instance/gpu/utilization |
過去のサンプル期間に対して、1 つ以上のカーネルが GPU で実行されていた時間の割合。 |
instance/gpu/memory_utilization |
過去のサンプル期間に対して、グローバル(デバイス)メモリの読み書きが実行された時間の割合。 |
instance/gpu/memory_total |
インストールされている GPU メモリの合計。 |
instance/gpu/memory_used |
アクティブなコンテキストによって割り当てられた合計メモリ。 |
instance/gpu/memory_used_percent |
アクティブなコンテキストによって割り当てられた合計メモリの割合。値の範囲は 0~100 です。 |
instance/gpu/memory_free |
空きメモリの合計。 |
instance/gpu/temperature |
コア GPU の温度(°C)。 |
次のステップ
- GPU ホスト メンテナンスを処理するには、GPU ホスト メンテナンス イベントの処理をご覧ください。
- ネットワーク パフォーマンスを改善するには、高いネットワーク帯域幅を使用するをご覧ください。