Criar serviços de alta disponibilidade com discos regionais
Esta secção explica como pode criar serviços de HA com discos persistentes regionais ou discos de alta disponibilidade Hyperdisk Balanced.
Considerações de design
Antes de começar a conceber um serviço de HA, compreenda as caraterísticas da aplicação, do sistema de ficheiros e do sistema operativo. Estas características são a base do design e podem excluir várias abordagens. Por exemplo, se uma aplicação não suportar a replicação ao nível da aplicação, algumas opções de design correspondentes não são aplicáveis.
Da mesma forma, se a aplicação, o sistema de ficheiros ou o sistema operativo não forem tolerantes a falhas, a utilização de um disco persistente regional ou de discos de alta disponibilidade equilibrados do Hyperdisk, ou mesmo de instantâneos de discos zonais, pode não ser uma opção.A tolerância a falhas é definida como a capacidade de recuperação de uma terminação abrupta sem perder nem danificar dados que já tinham sido confirmados num disco antes da falha.
Considere o seguinte quando criar em função da alta disponibilidade:
- O efeito na aplicação da utilização do Hyperdisk Balanced de alta disponibilidade, Persistent Disk regional ou outras soluções.
- Desempenho de escrita no disco.
- O objetivo de tempo de recuperação do serviço: a rapidez com que o seu serviço tem de recuperar de uma indisponibilidade zonal e os requisitos do SLA.
- O custo de criar uma arquitetura de serviços resiliente e fiável.
- Para mais informações sobre considerações específicas da região, consulte o artigo Geografia e regiões.
Em termos de custo, use as seguintes opções para a replicação de aplicações síncrona e assíncrona:
Use duas instâncias da base de dados e da VM. Neste caso, os seguintes itens determinam o custo total:
- Custos da instância de VM
- Custos dodisco persistente ou doHyperdisk
- Custos de manutenção da replicação de aplicações
Use uma única VM com discos replicados de forma síncrona. Para alcançar uma elevada disponibilidade com um disco persistente regional ou um disco de elevada disponibilidade equilibrado do Hyperdisk, use os mesmos componentes de disco e instância de VM que na opção anterior, mas inclua também um disco replicado de forma síncrona. Os discos persistentes regionais e os discos de alta disponibilidade equilibrados do Hyperdisk têm o dobro do custo por byte em comparação com os discos zonais, porque são replicados em duas zonas.
No entanto, a utilização de discos replicados de forma síncrona pode reduzir o custo de manutenção, uma vez que os dados são escritos automaticamente em duas réplicas sem a necessidade de manter a replicação da aplicação.
Não inicie a VM secundária até ser necessária a comutação por falha. Pode reduzir ainda mais os custos de alojamento iniciando a VM secundária apenas a pedido durante a comutação por falha, em vez de manter a VM como uma VM de reserva ativa.
Compare o custo, o desempenho e a resiliência
A tabela seguinte realça as concessões em termos de custo, desempenho e resiliência para as diferentes arquiteturas de serviços.
| Arquitetura de serviço de HA |
instantâneos de discos zonais |
Nível da aplicação síncrono |
Nível da aplicação assíncrono |
Discos regionais |
|---|---|---|---|---|
| Protege contra falhas de aplicações, VMs e zonas* | ||||
| Mitigação contra a corrupção de aplicações (Exemplo: intolerância a falhas de aplicações) | † | † | ||
| Custo | $ |
$$
|
$$
|
$1.5x - $$
|
| Desempenho das aplicações |
|
|
|
|
| Adequado para aplicações com um requisito de RPO baixo (Tolerância muito baixa para perda de dados) |
|
|
|
|
| Tempo de recuperação do armazenamento após um desastre# |
|
|
|
|
* A utilização de discos ou instantâneos regionais não é suficiente para proteger e mitigar falhas e danos. A sua aplicação, sistema de ficheiros e, possivelmente, outros componentes de software têm de ser consistentes em caso de falha ou usar algum tipo de suspensão.
† A replicação de algumas aplicações oferece mitigação contra algumas corrupções de aplicações. Por exemplo, a danificação da aplicação principal do MySQL não faz com que as instâncias de VM da réplica também fiquem danificadas. Consulte a documentação da sua aplicação para ver detalhes.
‡ A perda de dados significa a perda irrecuperável de dados confirmados no armazenamento persistente. Os dados não comprometidos continuam a ser perdidos.
# O desempenho da comutação por falha não inclui a verificação do sistema de ficheiros, a recuperação da aplicação nem o carregamento após a comutação por falha.
Criar serviços de base de dados de HA com discos regionais
Esta secção aborda conceitos de alto nível para criar soluções de HA para serviços de base de dados com estado (MySQL, Postgres, etc.) através do Compute Engine comdiscos persistentes regionais e discos de alta disponibilidade equilibrados do Hyperdisk.
Se houver interrupções generalizadas em Google Cloud, por exemplo, se uma região inteira ficar indisponível, a sua aplicação pode ficar indisponível. Consoante as suas necessidades, considere usar técnicas de replicação entre regiões ou replicação assíncrona para uma disponibilidade ainda maior.
Normalmente, as configurações de HA da base de dados têm, pelo menos, duas instâncias de VM. De preferência, estas instâncias de VM fazem parte de um ou mais grupos de instâncias geridas:
- Uma instância de VM principal na zona principal
- Uma instância de VM em espera numa zona secundária
Uma instância de VM principal tem, pelo menos, dois discos: um disco de arranque e um disco regional. O disco regional contém dados da base de dados e quaisquer outros dados mutáveis que devem ser preservados noutra zona em caso de indisponibilidade.
Uma instância de VM em modo de espera requer um disco de arranque separado para poder recuperar de interrupções relacionadas com a configuração, que podem resultar, por exemplo, de uma atualização do sistema operativo. Além disso, não pode forçar a anexação de um disco de arranque a outra VM durante uma comutação por falha.
As instâncias de VM principal e de reserva estão configuradas para usar um equilibrador de carga com o tráfego direcionado para a VM principal com base nos sinais de verificação de funcionamento. O cenário de recuperação de desastres para dados descreve outras configurações de comutação por falha, que podem ser mais adequadas para o seu cenário.
Desafios com a replicação da base de dados
A tabela seguinte apresenta alguns desafios comuns relacionados com a configuração e a gestão da replicação síncrona ou semissíncrona de aplicações (como o MySQL) e a forma como se comparam com a replicação síncrona de discos com odisco persistente regional e os discos de alta disponibilidade equilibrados do Hyperdisk.
| Desafios | Replicação síncrona ou semissíncrona da aplicação |
Replicação síncrona de discos |
|---|---|---|
| Manter a replicação estável entre a réplica principal e a de alternativa. | Existem vários aspetos que podem correr mal e fazer com que uma instância de VM
saia do modo de HA:
|
As falhas de armazenamento são processadas pelo disco persistente regional e pelos discos de alta disponibilidade equilibrados do Hyperdisk. Isto acontece de forma transparente para a aplicação, exceto por uma possível flutuação no desempenho do disco. Tem de haver verificações de estado de funcionamento definidas pelo utilizador para revelar problemas de aplicações ou VMs e acionar a comutação por falha. |
| O tempo de comutação por falha ponto a ponto é superior ao esperado. | O tempo necessário para a operação de ativação pós-falha não tem um limite superior. A espera pela repetição de todas as transações (passo 2 acima) pode demorar um período arbitrariamente longo, consoante o esquema e a carga na base de dados. | Disco persistente regional e discos de alta disponibilidade equilibrados do Hyperdisk oferecem replicação síncrona, pelo que o tempo de comutação por falha é limitado pela soma das seguintes latências:
|
| Cérebro dividido | Para evitar divisão de cérebro, ambas as abordagens requerem disposições para garantir que existe apenas um principal de cada vez. | |
Sequência de operações de leitura e escrita em discos
Ao determinar as sequências de leitura e escrita, ou a ordem em que os dados são lidos e escritos no disco, a maioria do trabalho é feita pelo controlador de disco na sua VM. Como utilizador, não tem de lidar com a semântica de replicação e pode interagir com o sistema de ficheiros como habitualmente. O controlador subjacente processa a sequência para leitura e escrita.
Por predefinição, uma VM do Compute Engine com um disco persistente regional ou Hyperdisk Balanced de alta disponibilidade funciona no modo de replicação total, em que os pedidos de leitura ou escrita do disco são enviados para ambas as réplicas.
No modo de replicação total, ocorre o seguinte:
- Quando escreve, um pedido de escrita tenta escrever em ambas as réplicas e confirma quando ambas as escritas são bem-sucedidas.
- Durante a leitura, a VM envia um pedido de leitura a ambas as réplicas e devolve os resultados daquela que for bem-sucedida. Se o pedido de leitura exceder o limite de tempo, é enviado outro pedido de leitura.
Se uma réplica ficar para trás ou não acusar a receção dos pedidos de leitura ou escrita, o estado da réplica é atualizado.
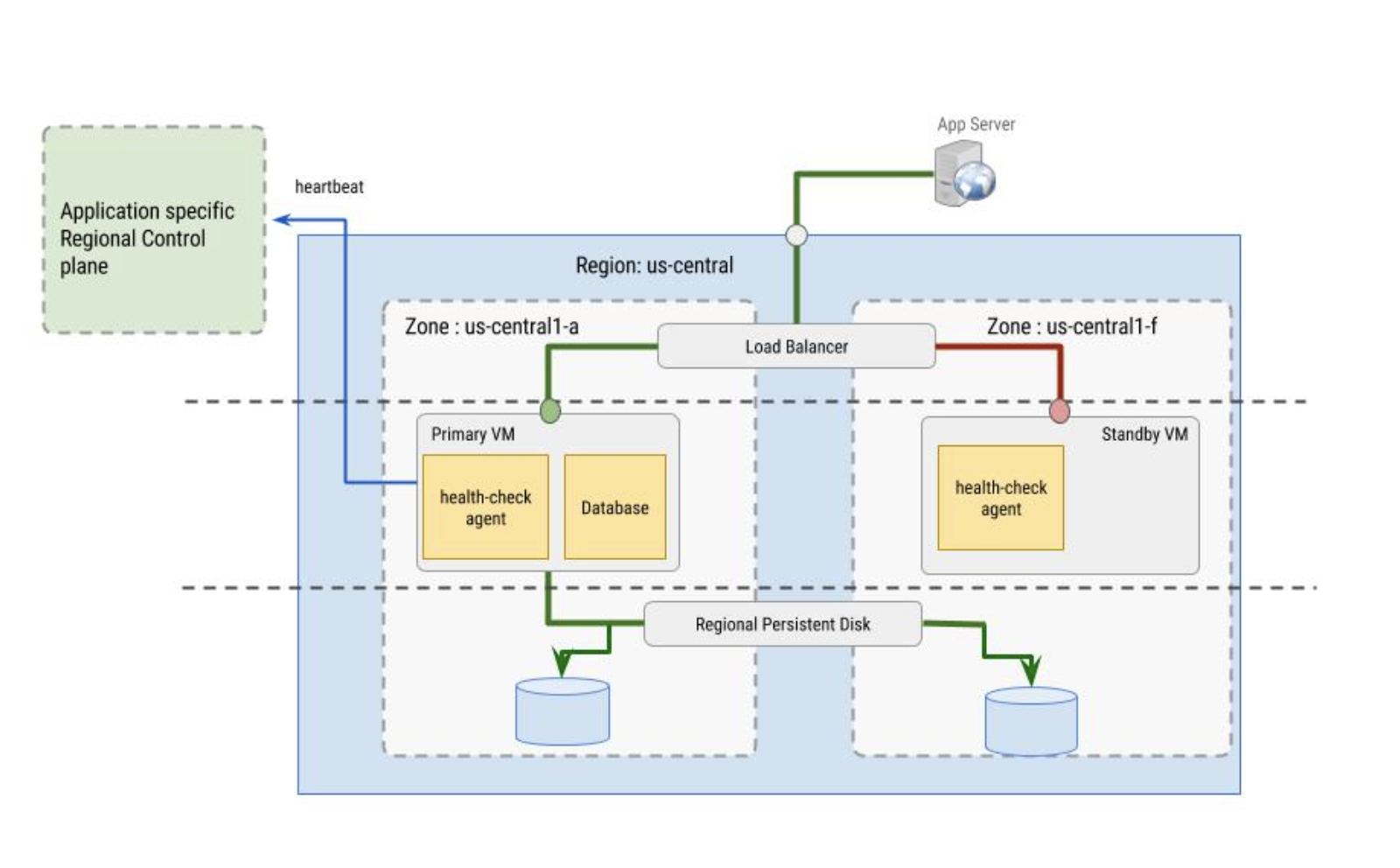
Verificações de funcionamento
As verificações de funcionamento usadas pelo balanceador de carga são implementadas pelo agente de verificação de funcionamento. O agente de verificação de funcionamento tem dois objetivos:
- O agente de verificação de estado reside nas VMs principal e secundária para monitorizar as instâncias de VM e comunicar com o equilibrador de carga para direcionar o tráfego. Isto funciona melhor quando configurado com grupos de instâncias.
- O agente de verificação de funcionamento sincroniza-se com o plano de controlo regional específico da aplicação e toma decisões de comutação por falha com base no comportamento do plano de controlo. O plano de controlo tem de estar numa zona diferente da instância de VM cuja integridade está a monitorizar.
O próprio agente de verificação de estado tem de ser tolerante a falhas. Por exemplo, repare que, na imagem que se segue, o plano de controlo está separado da instância de VM principal, que reside na zona us-central1-a, enquanto a VM de reserva reside na zona us-central1-f.
O que se segue?
- Saiba como criar e gerir discos regionais.
- Saiba mais sobre a replicação assíncrona.
- Saiba como configurar uma instância de cluster de failover do SQL Server para discos no modo de gravação múltipla.
- Saiba como criar aplicações Web escaláveis e resilientes no Google Cloud.
- Reveja o guia de planeamento de recuperação de desastres.