이 문서에서는 장기 분석을 위해 Cloud Monitoring 측정항목을 내보내는 솔루션을 설명합니다. Cloud Monitoring은Google Cloud 및 Amazon Web Services (AWS)를 위한 모니터링 솔루션을 제공합니다. Cloud Monitoring은 모니터링 측정항목의 값이 종종 시간 제한적이므로 6주 동안 측정항목을 유지 관리합니다. 따라서 이전 측정항목 값은 시간이 경과하면 감소합니다. 6주 기간이 지난 후에도 집계 측정항목에는 단기 분석에서는 명확하지 않을 수 있는 장기 동향 분석 값이 여전히 포함될 수 있습니다.
이 솔루션에서는 내보낼 측정항목 세부정보와 측정항목을 BigQuery에 내보내는 서버리스 참조 구현을 설명합니다.
State of DevOps 보고서에는 소프트웨어 배포 성능을 향상시키는 기능이 나와 있습니다. 이 솔루션에서는 다음 기능을 설명합니다.
측정항목 사용 사례 내보내기
Cloud Monitoring은 Google Cloud, AWS, 앱 계측에서 측정항목과 메타데이터를 수집합니다. API, 대시보드, 측정항목 탐색기를 통해 Monitoring 측정항목을 사용하여 클라우드 앱의 성능, 업타임, 전반적인 상태를 면밀하게 관찰할 수 있습니다. 이 도구를 사용하면 이전 6주간의 분석용 측정항목 값을 검토할 수 있습니다. 장기 측정항목 분석 요구사항이 있는 경우 Cloud Monitoring API를 사용하여 장기 스토리지 측정항목을 내보냅니다.
Cloud Monitoring은 최근 6주간의 측정항목을 유지합니다. 주로 가상 머신 인프라(CPU, 메모리, 네트워크 측정항목)와 애플리케이션 성능 측정항목(요청 또는 응답 지연 시간) 모니터링과 같은 운영 목적으로 사용됩니다. 이러한 측정항목이 사전 설정된 임곗값을 초과하면 알림을 통해 운영 프로세스가 트리거됩니다.
캡처된 측정항목은 장기 분석에도 유용할 수 있습니다. 예를 들어 사이버 먼데이의 앱 성능 측정항목 또는 기타 트래픽이 많은 이벤트를 전년도 측정항목과 비교하여 트래픽이 많은 다음 이벤트를 계획할 수 있습니다. 또 다른 사용 사례는 보다 정확하게 비용을 예측하기 위해 분기별 또는 연도별 Google Cloud 서비스 사용량을 조사하는 것입니다. 또한 몇 개월 또는 몇 년 동안의 앱 성능 측정항목을 확인하려 할 수도 있습니다.
이 예에서는 장기 분석에 사용할 측정항목을 유지해야 합니다. 이러한 측정항목을 BigQuery에 내보내면 이 예에서 필요한 분석 기능을 사용할 수 있습니다.
요구사항
Monitoring 측정항목 데이터를 장기 분석하려면 다음 3가지 주요 요구사항을 준수해야 합니다.
- Cloud Monitoring에서 데이터를 내보냅니다. Cloud Monitoring 측정항목 데이터를 집계된 측정항목 값으로 내보내야 합니다.
원시
timeseries데이터 포인트를 저장하는 것은 기술적으로 가능하지만 값을 추가하지 않기 때문에 측정항목을 집계해야 합니다. 대부분의 장기 분석은 장기간에 걸쳐 집계 수준에서 수행됩니다. 세부 집계 수준은 사용 사례별로 다르지만 최소 1시간 동안 집계하는 것이 좋습니다. - 분석할 데이터를 수집합니다. 내보낸 Cloud Monitoring 측정항목은 분석을 위해 분석 엔진으로 가져와야 합니다.
- 데이터에 대한 쿼리를 작성하고 대시보드를 빌드합니다. 데이터를 쿼리, 분석, 시각화하려면 대시보드와 표준 SQL 액세스가 필요합니다.
기능적 단계
- 내보내기에 포함시킬 측정항목 목록을 작성합니다.
- Monitoring API에서 측정항목을 읽습니다.
- Monitoring API에서 내보낸 JSON 출력의 측정항목을 BigQuery 테이블 형식으로 매핑합니다.
- 측정항목을 BigQuery에 씁니다.
- 정기적으로 측정항목을 내보내는 프로그래매틱 일정을 만듭니다.
아키텍처
이 아키텍처는 관리형 서비스를 활용하여 운영 및 관리를 간소화하고, 비용을 줄이고, 필요에 따라 확장될 수 있도록 설계되었습니다.
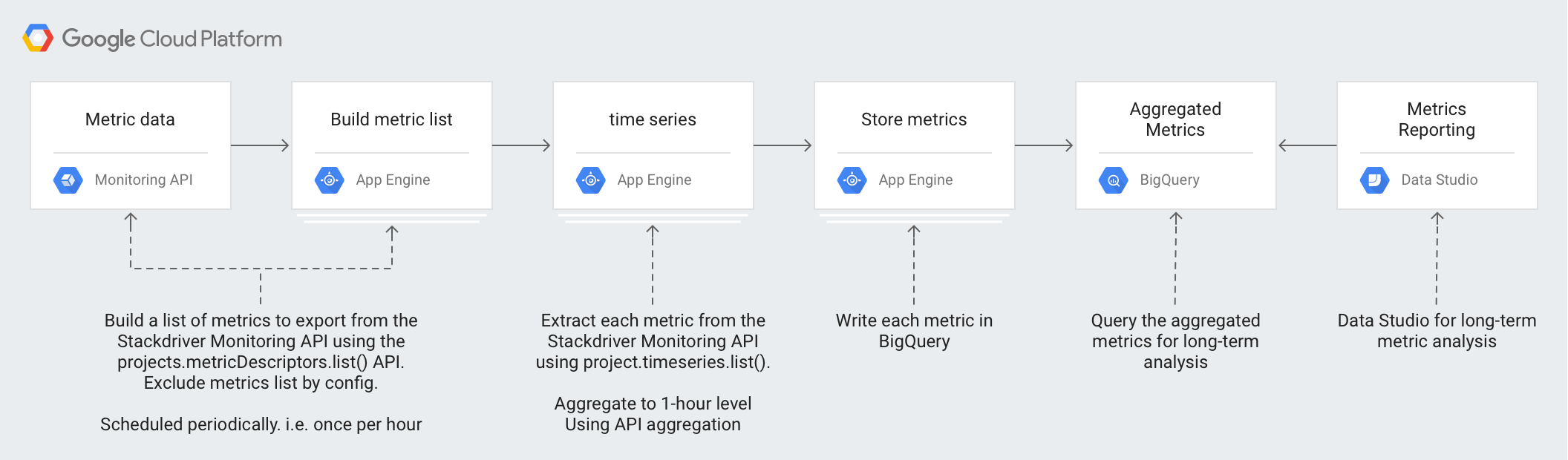
이 아키텍처에서 사용되는 기술은 다음과 같습니다.
- App Engine - Monitoring API를 호출하고 BigQuery에 쓰는 데 사용되는 확장 가능한 PaaS(Platform as a Service)입니다.
- BigQuery -
timeseries데이터를 수집하고 분석하는 데 사용되는 완전 관리형 분석 엔진입니다. - Pub/Sub - 확장 가능한 비동기 처리를 제공하는 데 사용되는 완전 관리형 실시간 메시징 서비스입니다.
- Cloud Storage - 내보내기 상태에 대한 메타데이터를 저장하는 데 사용되는 개발자와 기업용 통합 객체 스토리지입니다.
- Cloud Scheduler - 내보내기 프로세스를 실행하는 데 사용되는 크론 방식의 스케줄러입니다.
Cloud Monitoring 측정항목 세부정보 이해
Cloud Monitoring에서 측정항목을 가장 잘 내보내는 방법을 이해하려면 측정항목을 저장하는 방법을 이해하는 것이 중요합니다.
측정항목 유형
Cloud Monitoring에는 내보낼 수 있는 4가지 기본 유형의 측정항목이 있습니다.
- Google Cloud 측정항목 목록은 Compute Engine 및 BigQuery와 같은 Google Cloud 서비스의 측정항목입니다.
- 에이전트 측정항목 목록은 Cloud Monitoring 에이전트를 실행하는 VM 인스턴스의 측정항목입니다.
- AWS 측정항목 목록 - Amazon Redshift 및 Amazon CloudFront와 같은 AWS 서비스의 측정항목입니다.
- 외부 소스 측정항목 - 타사 애플리케이션의 측정항목과 커스텀 측정항목을 포함한 맞춤 설정 측정항목입니다.
이러한 각 측정항목 유형에는 측정항목 유형과 기타 측정항목 메타데이터가 포함된 측정항목 설명이 있습니다. 다음 측정항목은 Monitoring API projects.metricDescriptors.list 메서드의 측정항목 설명 목록의 예시입니다.
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
측정항목 설명자에서 이해해야 할 중요한 값은 type, valueType, metricKind 필드입니다. 이들 필드는 측정항목을 식별하고, 측정항목 설명에서 가능한 집계에 영향을 미칩니다.
측정항목 종류
각 측정항목에는 측정항목 종류와 값 유형이 있습니다. 자세한 내용은 값 유형 및 측정항목 종류를 참조하세요. 측정항목 종류와 연관된 값 유형 조합이 측정항목 집계 방식에 영향을 미치므로 이 두 가지가 중요합니다.
앞의 예시에서 pubsub.googleapis.com/subscription/push_request_count metric 측정항목 유형에는 DELTA 측정항목 종류와 INT64 값 유형이 있습니다.

Cloud Monitoring에서 측정항목 종류와 값 유형은 metricsDescriptors에 저장되며 Monitoring API에서 사용할 수 있습니다.
Timeseries
timeseries는 측정항목 유형, 메타데이터, 라벨, 개별 측정 데이터 포인트가 포함된 시간 경과에 따라 저장된 각 측정항목 유형의 정기 측정 값입니다.Google Cloud 및 AWS 측정항목과 같이 Monitoring에서 자동으로 수집되는 측정항목은 정기적으로 수집됩니다. 예를 들어 appengine.googleapis.com/http/server/response_latencies 측정항목은 60초마다 수집됩니다.
특정 timeseries에 대해 수집된 일련의 포인트는 보고되는 데이터의 빈도 그리고 측정항목 유형과 관련된 라벨에 따라 시간이 흐르면서 증가할 수 있습니다. 원시 timeseries 데이터 포인트를 내보내는 경우 대용량 내보내기가 발생할 수 있습니다. 반환되는 timeseries 데이터 포인트 수를 줄이려면 지정된 정렬 기간 동안 측정항목을 집계하면 됩니다. 예를 들어 집계를 사용하면 분당 데이터 포인트가 한 개 있는 특정 측정항목 timeseries에 대해 시간당 하나의 데이터 포인트를 반환할 수 있습니다. 이렇게 하면 내보낸 데이터 포인트 수가 줄어들고 분석 엔진에 필요한 분석 처리도 줄어듭니다. 이 문서에서는 선택한 각 측정항목 유형에 대해 timeseries가 반환됩니다.
측정항목 집계
집계를 사용하여 여러 timeseries의 데이터를 단일 timeseries로 결합할 수 있습니다. Monitoring API는 강력한 정렬 및 집계 함수를 제공하므로 개발자가 직접 집계를 수행할 필요가 없으며 정렬 및 집계 매개변수를 API 호출 시 전달하기만 하면 됩니다. Monitoring API의 집계 작동 방식에 대한 자세한 내용은 필터링 및 집계 및 이 블로그 게시물을 참조하세요.
metric type을 aggregation type에 매핑하면 측정항목이 정렬되며 timeseries가 분석 요구에 맞게 축소됩니다.
timeseries를 집계하는 데 사용할 수 있는 정렬기 및 감소기 목록이 있습니다. 정렬기와 감소기에는 측정항목 종류와 값 유형에 따라 정렬하거나 줄이는 데 사용할 수 있는 측정항목 세트가 있습니다. 예를 들어 1시간 이상 집계하면 timeseries에 대해 집계 결과가 시간당 1포인트씩 반환됩니다.
집계를 세부 조정하는 또 다른 방법은 집계 값을 집계된 timeseries 목록으로 그룹화할 수 있는 Group By 함수를 사용하는 것입니다. 예를 들어 App Engine 모듈을 기준으로 App Engine 측정항목을 그룹화할 수 있습니다. App Engine 모듈을 기준으로 그룹화하고 정렬기와 감소기를 사용하여 1시간 단위로 집계하면 App Engine 모듈별로 시간당 데이터 포인트 1개가 생성됩니다.
측정항목을 집계하면 상세 장기 분석용으로 충분한 데이터를 보관해야 하는 필요성과 개별 데이터 포인트 기록으로 인한 비용 증가 간의 균형을 맞출 수 있습니다.
참조 구현 세부정보
참조 구현에는 아키텍처 설계 다이어그램의 설명대로 동일한 구성요소가 포함됩니다. 각 단계의 기능 및 관련 구현 세부정보는 아래에서 설명됩니다.
측정항목 목록 작성
Cloud Monitoring은 Google Cloud, AWS, 서드 파티 소프트웨어를 모니터링하는 데 도움이 되는 수천 가지 측정항목 유형을 정의합니다. Monitoring API는 프로젝트에 사용할 수 있는 측정항목 목록을 반환하는 projects.metricDescriptors.list 메서드를 제공합니다. Google Cloud
Monitoring API는 필터링 메커니즘을 제공하므로 장기 저장 및 분석용으로 내보내려는 측정항목 목록을 필터링할 수 있습니다.
GitHub의 참조 구현은 Python App Engine 앱을 사용하여 측정항목 목록을 가져온 후 각 메시지를 Pub/Sub 주제에 개별적으로 씁니다. 내보내기는 앱을 실행하기 위한 Pub/Sub 알림을 생성하는 Cloud Scheduler에 의해 시작됩니다.
Monitoring API를 호출하는 방법에는 여러 가지가 있으며, 이 경우에는 Google API에 유연하게 액세스할 수 있는 Python용 Google API 클라이언트 라이브러리를 사용하여 Cloud Monitoring 및 Pub/Sub API를 호출합니다.
Timeseries 가져오기
측정항목의 timeseries를 추출한 후 각 timeseries를 Pub/Sub에 씁니다. Monitoring API에서는 project.timeseries.list 메서드를 사용하여 지정된 정렬 기간 동안 측정항목 값을 집계할 수 있습니다. 데이터를 집계하면 처리 부하, 스토리지 요구사항, 쿼리 횟수, 분석 비용이 감소합니다. 데이터 집계는 장기 측정항목 분석을 효율적으로 수행할 수 있게 해주므로 이를 사용하는 것이 좋습니다.
GitHub의 참조 구현에서는 Python App Engine 앱을 사용하여 주제를 구독합니다. 이 때 내보내기의 각 측정항목은 별도의 메시지로 전송됩니다. Pub/Sub는 수신된 각 메시지에 대해 App Engine 앱에 메시지를 푸시합니다. 앱은 입력 구성을 기반으로 집계된 특정 측정항목의 timeseries를 가져옵니다. 이 경우 Cloud Monitoring 및 Pub/Sub API는 Google API 클라이언트 라이브러리를 통해 호출됩니다.
각 측정항목은 1개 이상의 timeseries.를 반환할 수 있습니다. 각 측정항목은 BigQuery에 삽입할 별도의 Pub/Sub 메시지로 전송됩니다. 측정항목 type-to-aligner 및 type-to-reducer 매핑은 참조 구현에 포함되어 있습니다. 다음 표에는 정렬기와 감소기에서 지원하는 측정항목 종류 및 값 유형의 클래스에 따라 참조 구현에 사용되는 매핑이 있습니다.
| 값 유형 | GAUGE |
정렬기 | 감소기 | DELTA |
정렬기 | 감소기 | CUMULATIVE2 |
정렬기 | 감소기 |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
예 |
ALIGN_FRACTION_TRUE
|
없음 | 아니요 | 해당 사항 없음 | 해당 사항 없음 | 아니요 | 해당 사항 없음 | 해당 사항 없음 |
INT64 |
예 |
ALIGN_SUM
|
없음 | 예 |
ALIGN_SUM
|
없음 | 예 | 없음 | 없음 |
DOUBLE |
예 |
ALIGN_SUM
|
없음 | 예 |
ALIGN_SUM
|
없음 | 예 | 없음 | 없음 |
STRING |
예 | 제외 | 제외 | 아니요 | 해당 사항 없음 | 해당 사항 없음 | 아니요 | 해당 사항 없음 | 해당 사항 없음 |
DISTRIBUTION |
예 |
ALIGN_SUM
|
없음 | 예 |
ALIGN_SUM
|
없음 | 예 | 없음 | 없음 |
MONEY |
아니요 | 해당 사항 없음 | 해당 사항 없음 | 아니요 | 해당 사항 없음 | 해당 사항 없음 | 아니요 | 해당 사항 없음 | 해당 사항 없음 |
각 정렬기와 감소기의 특정 valueTypes 및 metricKinds에 대해서만 집계할 수 있으므로 valueType을 정렬기와 감소기에 매핑하는 것은 중요합니다.
예를 들어 pubsub.googleapis.com/subscription/push_request_count metric 유형을 고려합니다. 측정항목 종류가 DELTA이고 값 유형이 INT64이므로 측정항목을 집계할 수 있는 한 가지 방법은 다음과 같습니다.
- 정렬 기간 - 3,600초(1시간)
Aligner = ALIGN_SUM- 정렬 기간의 결과 데이터 포인트는 정렬 기간의 모든 데이터 포인트의 합계입니다.Reducer = REDUCE_SUM- 각 정렬 기간 동안timeseries에서 합계를 계산하여 축소합니다.
정렬 기간, 정렬기, 감소기 값과 함께 project.timeseries.list 메서드에는 다음의 몇 가지 다른 입력이 필요합니다.
filter- 반환할 측정항목을 선택합니다.startTime-timeseries를 반환할 시작 시점을 선택합니다.endTime-timeseries를 반환할 마지막 시점을 선택합니다.groupBy-timeseries응답을 그룹화할 필드를 입력합니다.alignmentPeriod- 측정항목을 정렬할 기간을 입력합니다.perSeriesAligner- 지점을alignmentPeriod로 정의된 균등한 시간 간격으로 정렬합니다.crossSeriesReducer- 라벨 값이 다른 여러 포인트를 시간 간격당 하나의 포인트로 결합합니다.
API에 대한 GET 요청에는 이전 목록에서 설명된 모든 매개변수가 포함됩니다.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
다음 HTTP GET은 입력 매개변수를 사용하여 projects.timeseries.list API 메서드를 호출하는 예를 제시합니다.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
이전 Monitoring API 호출에는 crossSeriesReducer=REDUCE_SUM이 포함되어 있습니다. 즉, 다음 예시와 같이 측정항목이 축소되고 단일 합계로 줄어듭니다.
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
이 집계 수준은 데이터를 단일 데이터 포인트로 집계하므로 전체 Google Cloud 프로젝트에 이상적인 측정항목이 됩니다. 그러나 어떤 리소스가 측정항목에 기여했는지 파악할 수 없습니다. 앞의 예시에서는 어떤 Pub/Sub 구독이 요청 수에 가장 많이 기여했는지 알 수 없습니다.
timeseries를 생성하는 개별 구성 요소의 세부 정보를 검토하려면 crossSeriesReducer 매개변수를 삭제하면 됩니다.
crossSeriesReducer가 없으면 Monitoring API는 다양한 timeseries를 결합하여 단일 값을 생성하지 않습니다.
다음 HTTP GET은 입력 매개변수를 사용하여 projects.timeseries.list API 메서드를 호출하는 예를 제시합니다. crossSeriesReducer는 포함되지 않습니다.
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
timeseries가 그룹화되므로 다음 JSON 응답에서 metric.labels.keys는 모든 결과에서 동일합니다. resource.labels.subscription_ids 값마다 별도의 포인트가 반환됩니다. 다음 JSON에서 metric_export_init_pub 및 metrics_list 값을 검토합니다. 이 집계 수준은 BigQuery 쿼리에 리소스 라벨로 포함된Google Cloud 제품을 사용할 수 있으므로 이 수준을 사용하는 것이 좋습니다.
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
projects.timeseries.list API 호출의 JSON 출력에 있는 각 측정항목은 Pub/Sub에 개별 메시지로 직접 기록됩니다. 1개의 입력 측정항목이 1개 이상의 timeseries를 생성하는 팬아웃 가능성이 있습니다.
Pub/Sub에서는 시간 제한을 초과하지 않고 대량 팬아웃을 흡수할 수 있습니다.
정렬 기간을 입력으로 제공하면 앞의 응답 예시와 같이 관련 기간 값이 단일 값으로 집계됩니다. 또한 정렬 기간은 내보내기 실행 빈도도 정의합니다. 예를 들어 정렬 기간이 3,600초 또는 1시간이면 내보내기가 매시간 실행되어 timeseries를 정기적으로 내보냅니다.
매장 측정항목
GitHub의 참조 구현은 Python App Engine 앱을 사용하여 각 timeseries를 읽고 레코드를 BigQuery 테이블에 삽입합니다. Pub/Sub는 수신된 각 메시지에 대해 App Engine 앱에 메시지를 푸시합니다. Pub/Sub 메시지에는 Monitoring API에서 내보낸 측정항목 데이터가 JSON 형식으로 포함되어 있으며 BigQuery의 테이블 구조에 매핑되어야 합니다. 이 경우 BigQuery API는 Google API 클라이언트 라이브러리를 통해 호출됩니다.
BigQuery 스키마는 Monitoring API에서 내보낸 JSON과 밀접하게 매핑되도록 설계되었습니다. BigQuery 테이블 스키마를 빌드할 때 한 가지 고려해야 하는 사항은 시간이 경과하면 데이터가 커지므로 데이터 크기를 확장해야 한다는 점입니다.
BigQuery에서는 전체 테이블 검색을 수행하지 않고도 날짜 범위를 선택하여 쿼리를 더 효율적으로 만들 수 있으므로 날짜 필드를 기준으로 테이블의 파티션을 나누는 것이 좋습니다. 내보내기를 정기적으로 실행하려는 경우 수집 날짜를 기준으로 하는 기본 파티션을 안전하게 사용할 수 있습니다.
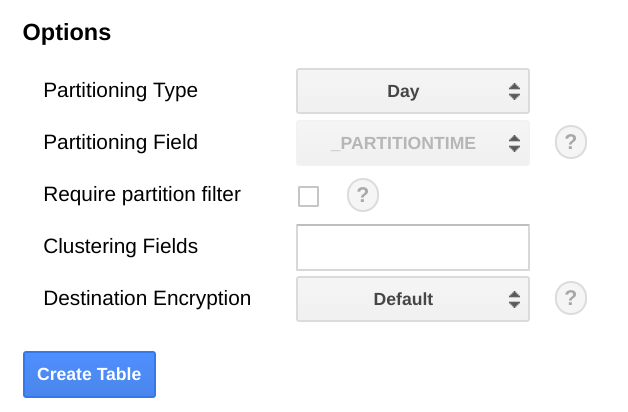
측정항목을 일괄 업로드하거나 정기적으로 내보내기를 실행하지 않으려면 BigQuery 스키마를 변경해야 하는 end_time,의 파티션을 나눕니다. end_time를 스키마의 최상위 필드로 이동하여 파티션 나누기에 사용하거나 스키마에 새 필드를 추가할 수 있습니다. 이 필드는 BigQuery 레코드에 포함되어 있고 파티션 나누기는 최상위 필드에서 수행되어야 하므로 end_time 필드를 이동해야 합니다. 자세한 내용은 BigQuery 파티션 나누기 문서를 참조하세요.
또한 BigQuery에는 일정한 시간이 지나면 데이터 세트, 테이블, 테이블 파티션을 만료하는 기능이 있습니다.
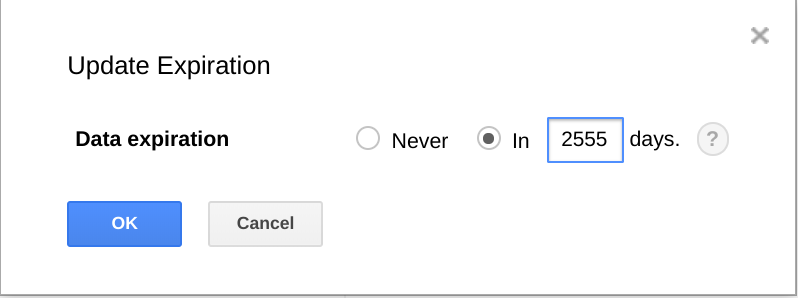
이 기능을 사용하면 데이터가 더 이상 유용하지 않을 때 이전 데이터를 삭제할 수 있습니다. 예를 들어 분석 기간이 3년인 경우 3년보다 오래된 데이터를 삭제하는 정책을 추가할 수 있습니다.
일정 내보내기
Cloud Scheduler는 완전 관리형 크론 작업 스케줄러입니다. Cloud Scheduler를 사용하면 표준 크론 일정 형식을 사용하여 App Engine 앱을 트리거하거나 Pub/Sub를 사용하여 메시지를 보내거나 임의의 HTTP 엔드포인트로 메시지를 보낼 수 있습니다.
GitHub의 참조 구현에서 Cloud Scheduler는 App Engine의 구성과 일치하는 토큰과 함께 Pub/Sub 메시지를 전송하여 매시간 list-metrics App Engine 앱을 트리거합니다. 앱 구성의 기본 집계 기간은 3,600초 또는 1시간이며, 이는 앱이 트리거되는 빈도와 서로 관련됩니다. 최소 1시간 집계는 데이터 볼륨을 줄이면서 충실도 높은 데이터를 유지할 수 있으므로 이를 사용하는 것이 좋습니다. 다른 정렬 기간을 사용할 경우 내보내기 빈도를 정렬 주기에 맞게 변경합니다. 참조 구현은 Cloud Storage에 마지막 end_time 값을 저장하고 start_time이 매개변수로 전달되지 않는 한 이 값을 후속 start_time으로 사용합니다.
Cloud Scheduler의 다음 스크린샷은 Google Cloud 콘솔을 사용하여 Cloud Scheduler에서 매시간 list-metrics App Engine 앱을 호출하도록 구성하는 방법을 보여줍니다.
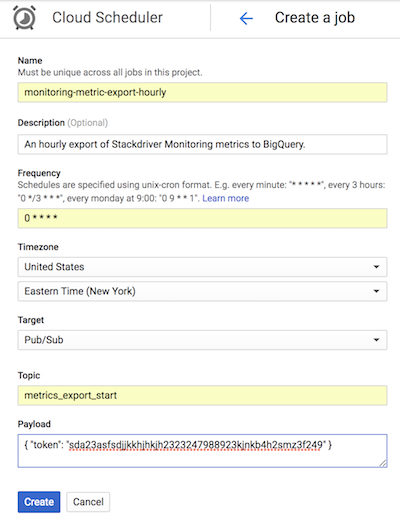
빈도 필드는 크론 스타일 문법을 사용하여 Cloud Scheduler에 앱 실행 빈도를 알려줍니다. 대상은 생성되는 Pub/Sub 메시지를 지정하고 페이로드 필드에는 Pub/Sub 메시지에 포함된 데이터가 포함됩니다.
내보낸 측정항목 사용
이제 BigQuery에서 내보낸 데이터를 대상으로 표준 SQL을 사용하여 쿼리하거나 대시보드를 빌드하여 시간 경과에 따른 측정항목 동향을 시각화할 수 있습니다.
샘플 쿼리: App Engine 지연 시간
다음 쿼리는 App Engine 앱의 평균 지연 시간 측정항목 값의 최솟값, 최댓값, 평균을 찾습니다. metric.type은 App Engine 측정항목을 식별하고 라벨은 project_id 라벨 값을 기반으로 App Engine 앱을 식별합니다. 이 측정항목은 BigQuery의 distribution_value 필드에 매핑되는 Monitoring API의 DISTRIBUTION 값이므로 point.value.distribution_value.mean이 사용됩니다. end_time 필드는 지난 30일 동안의 값을 다시 확인합니다.
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
샘플 쿼리: BigQuery 쿼리 수
다음 쿼리는 프로젝트에서 하루에 수행된 BigQuery에 대한 쿼리 수를 반환합니다. 이 측정항목이 BigQuery의 int64_value 필드에 매핑되는 Monitoring API의 INT64 값이므로 int64_value 필드가 사용됩니다. metric.type은 BigQuery 측정항목을 식별하고 라벨은 project_id 라벨 값을 기준으로 프로젝트를 식별합니다. end_time 필드는 지난 30일 동안의 값을 다시 확인합니다.
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
샘플 쿼리: Compute Engine 인스턴스
다음 쿼리에서는 프로젝트의 Compute Engine 인스턴스에 대한 CPU 사용량 측정항목 값의 주간 최솟값, 최댓값, 평균값을 찾습니다. metric.type은 Compute Engine 측정항목을 식별하고 라벨은 project_id 라벨 값을 기준으로 인스턴스를 식별합니다. end_time 필드는 지난 30일 동안의 값을 다시 확인합니다.
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
데이터 시각화
BigQuery에는 데이터 시각화에 사용할 수 있는 다양한 도구가 통합되어 있습니다.
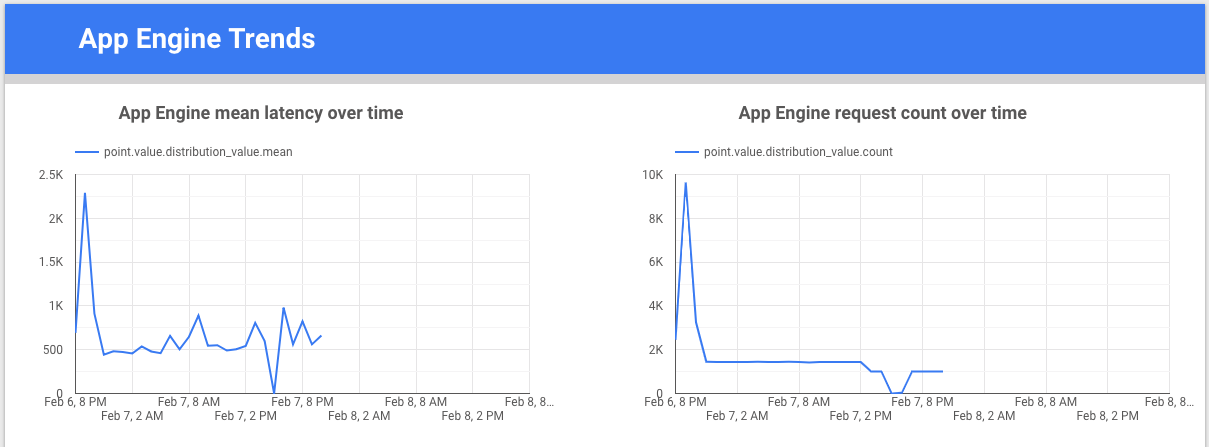
Looker Studio는 데이터 차트와 대시보드를 빌드하여 측정항목 데이터를 시각화한 후 팀과 공유할 수 있는 Google의 무료 도구입니다. 다음 예시는 시간 경과에 따른 appengine.googleapis.com/http/server/response_latencies 측정항목의 지연 시간과 개수를 나타내는 추세선 차트를 보여줍니다.
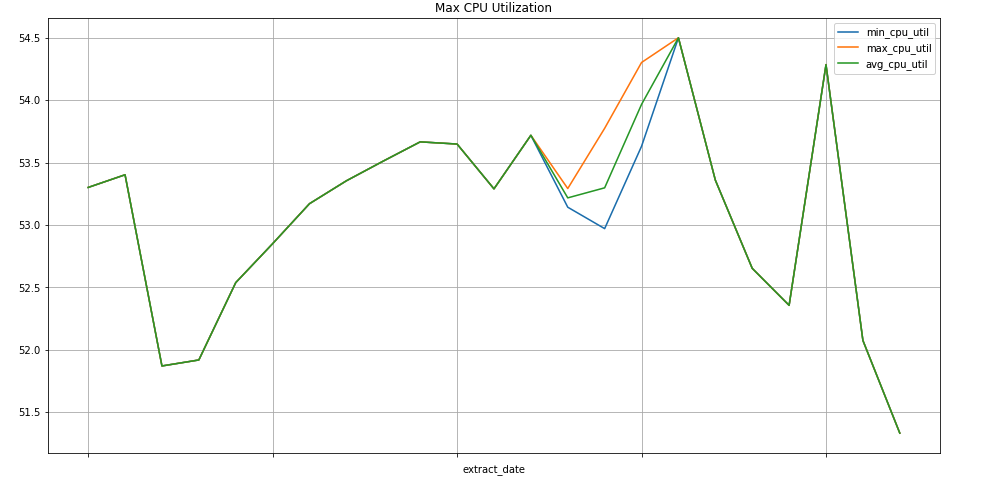
Colaboratory는 머신러닝 학습 및 연구용 연구 도구입니다. 별도의 설정 없이 BigQuery에서 데이터를 사용하고 액세스할 수 있는 호스팅된 Jupyter 노트북 환경입니다. Colab 노트북, Python 명령어, SQL 쿼리를 사용하면 자세한 분석과 시각화를 개발할 수 있습니다.
내보내기 참조 구현 모니터링
내보내기를 실행 중일 때는 이를 모니터링해야 합니다. 모니터링할 측정항목을 결정하는 한 가지 방법은 서비스 수준 목표(SLO)를 설정하는 것입니다. SLO는 측정항목에서 측정되는 서비스 수준의 목표 값 또는 값 범위입니다. 사이트 안정성 엔지니어링 설명서에서는 가용성, 처리량, 오류율, 지연 시간 등 4가지 SLO 주요 부분을 설명합니다. 데이터 내보내기의 경우 처리량과 오류율은 두 가지 주요 고려사항이며 다음 측정항목을 통해 모니터링될 수 있습니다.
- 처리량 -
appengine.googleapis.com/http/server/response_count - 오류율 -
logging.googleapis.com/log_entry_count
예를 들어 log_entry_count 측정항목을 사용하고 심각도가 ERROR인 App Engine 앱(list-metrics, get-timeseries, write-metrics)을 필터링하면 오류율을 모니터링할 수 있습니다. 그런 다음 Cloud Monitoring의 알림 정책을 사용하여 내보내기 앱에서 발생한 오류를 알릴 수 있습니다.
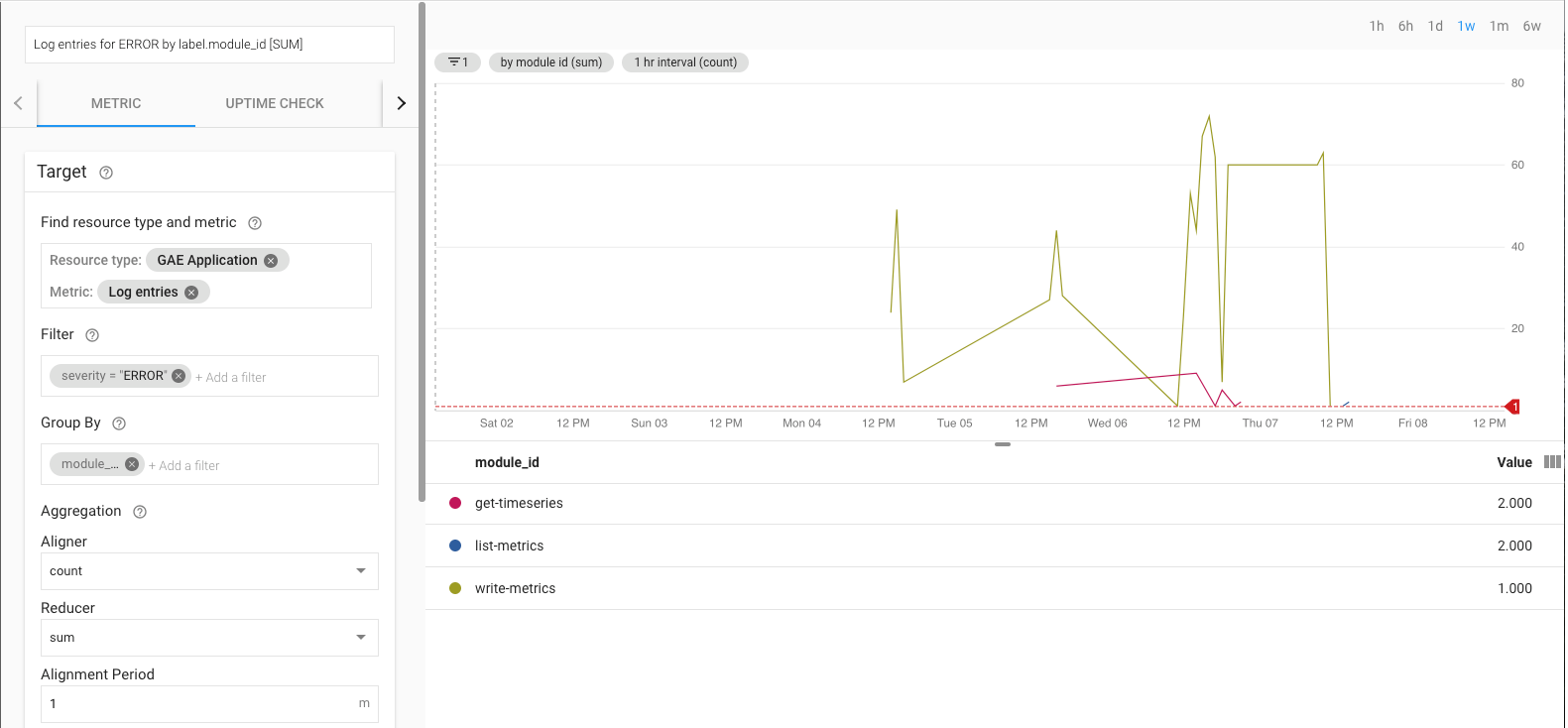
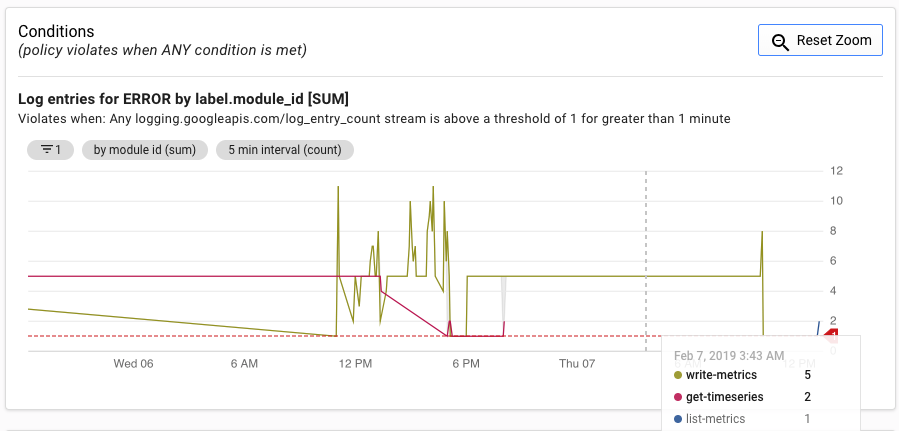
알림 UI에는 알림 생성 기준과 비교하여 log_entry_count 측정항목의 그래프가 표시됩니다.
다음 단계
- GitHub에서 참조 구현 보기
- Cloud Monitoring 문서 읽어보기
- Cloud Monitoring v3 API 문서 살펴보기
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 Cloud 아키텍처 센터를 확인하세요.
- DevOps에 대한 리소스를 읽어보기
이 솔루션과 관련된 DevOps 기능에 대해 자세히 알아보기
DevOps 빠른 점검을 사용하여 업계와 비교되는 자신의 현재 상태를 파악하세요.