Este documento es la tercera parte de una serie sobre la recuperación tras desastres (DR) en Google Cloud. En esta parte se describen algunas situaciones para crear copias de seguridad y recuperar datos.
La serie consta de las siguientes partes:
- Guía de planificación para la recuperación tras fallos
- Componentes básicos de recuperación tras fallos
- Situaciones de recuperación tras fallos con los datos (este documento)
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
Introducción
En tus planes de recuperación ante desastres debes especificar cómo puedes evitar perder datos durante un desastre. El término datos abarca dos situaciones. Crear copias de seguridad y, después, recuperar bases de datos, datos de registro y otros tipos de datos se ajusta a uno de los siguientes casos:
- Copias de seguridad de los datos. Crear una copia de seguridad de los datos consiste en copiar una cantidad determinada de datos de un lugar a otro. Las copias de seguridad se crean como parte de un plan de recuperación para recuperarse de una corrupción de datos, de modo que puedas restaurar un estado correcto conocido directamente en el entorno de producción, o para que puedas restaurar los datos en tu entorno de recuperación ante desastres si tu entorno de producción no funciona. Por lo general, las copias de seguridad de datos tienen un RTO de pequeño a mediano y un RPO pequeño.
- Copias de seguridad de bases de datos. Las copias de seguridad de bases de datos son un poco más complejas, ya que suelen implicar la recuperación hasta un momento determinado. Por lo tanto, además de plantearte cómo crear copias de seguridad de la base de datos y restaurarlas, y de asegurarte de que el sistema de la base de datos de recuperación refleje la configuración de producción (misma versión y configuración de disco reflejada), también debes pensar en cómo crear copias de seguridad de los registros de transacciones. Durante la recuperación, después de restaurar la funcionalidad de la base de datos, debes aplicar la copia de seguridad más reciente de la base de datos y, a continuación, los registros de transacciones recuperados de los que se creó una copia de seguridad después de la última copia de seguridad. Debido a los factores que complican los sistemas de bases de datos (por ejemplo, tener que hacer coincidir las versiones entre los sistemas de producción y recuperación), adoptar un enfoque de alta disponibilidad para minimizar el tiempo de recuperación de una situación que pueda provocar la falta de disponibilidad del servidor de la base de datos le permite conseguir valores de RTO y RPO más pequeños.
Cuando ejecutas cargas de trabajo de producción en Google Cloud, puedes usar un sistema distribuido globalmente para que, si algo va mal en una región, la aplicación siga ofreciendo servicio aunque esté menos disponible. En esencia, esa aplicación invoca su plan de recuperación tras fallos.
En el resto del documento se describen ejemplos de cómo diseñar algunos escenarios de datos y bases de datos que pueden ayudarle a alcanzar sus objetivos de tiempo de recuperación y punto de recuperación.
El entorno de producción es local
En este caso, tu entorno de producción es local y tu plan de recuperación tras fallos implica usar Google Cloud como sitio de recuperación.
Copia de seguridad y recuperación de datos
Puede usar varias estrategias para implementar un proceso que haga copias de seguridad periódicas de los datos locales en Google Cloud. En esta sección se analizan dos de las soluciones más habituales.
Solución 1: Crear una copia de seguridad en Cloud Storage mediante una tarea programada
Este patrón usa los siguientes elementos básicos de recuperación ante desastres:
- Cloud Storage
Una opción para crear copias de seguridad de los datos es crear una tarea programada que ejecute una secuencia de comandos o una aplicación para transferir los datos a Cloud Storage. Puedes automatizar un proceso de copia de seguridad en Cloud Storage mediante el comando de la CLI de Google Cloud gcloud storage o con una de las bibliotecas de cliente de Cloud Storage.
Por ejemplo, el siguiente comando gcloud storage copia todos los archivos de un directorio de origen en un segmento especificado.
gcloud storage cp -r SOURCE_DIRECTORY gs://BUCKET_NAME
Sustituye SOURCE_DIRECTORY por la ruta de tu directorio de origen y BUCKET_NAME por el nombre que quieras darle al segmento.
El nombre debe cumplir los requisitos de nombres de segmentos.
En los pasos que se indican a continuación se describe cómo implementar un proceso de copia de seguridad y recuperación mediante el comando gcloud storage.
- Instala
gcloud CLIen la máquina local que usas para subir tus archivos de datos. - Crea un segmento como destino de la copia de seguridad de tus datos.
- Crear cuentas de servicio
- Crea una política de gestión de identidades y accesos (IAM) para restringir quién puede acceder al segmento y a sus objetos. Incluye la cuenta de servicio creada específicamente para este fin. Para obtener información sobre los permisos de acceso a Cloud Storage, consulta Permisos de gestión de identidades y accesos para
gcloud storage. - Usa la suplantación de identidad de la cuenta de servicio para permitir que tu usuario local de Google Cloud(o cuenta de servicio) suplante la identidad de la cuenta de servicio que has creado anteriormente. También puedes crear un usuario nuevo específicamente para este fin.
- Comprueba que puedes subir y descargar archivos en el segmento de destino.
- Programa la secuencia de comandos que usas para subir tus copias de seguridad con herramientas como Linux
crontaby el Programador de tareas de Windows. - Configura un proceso de recuperación que utilice el comando
gcloud storagepara recuperar tus datos en tu entorno de recuperación ante desastres en Google Cloud.
También puedes usar el comando gcloud storage rsync para realizar sincronizaciones incrementales en tiempo real entre tus datos y un segmento de Cloud Storage.
Por ejemplo, el siguiente comando gcloud storage rsync hace que el contenido de un segmento de Cloud Storage sea el mismo que el del directorio de origen copiando los archivos u objetos que falten o aquellos cuyos datos hayan cambiado. Si el volumen de datos que ha cambiado entre sesiones de copia de seguridad sucesivas es pequeño en comparación con el volumen total de los datos de origen, puede ser más eficiente usar gcloud storage rsync que usar el comando gcloud storage cp. Si usas gcloud storage rsync, puedes implementar una programación de copias de seguridad más frecuente y conseguir un RPO más bajo.
gcloud storage rsync -r SOURCE_DIRECTORY gs:// BUCKET_NAME
Para obtener más información, consulta el comando gcloud storage para transferencias más pequeñas de datos on‐premise.
Solución 2: Crear una copia de seguridad en Cloud Storage con el servicio de transferencia de datos on-premise
Este patrón usa los siguientes elementos básicos de recuperación ante desastres:
- Cloud Storage
- Servicio de transferencia de datos on‑premise
Para transferir grandes cantidades de datos a través de una red, a menudo se requiere una planificación cuidadosa y estrategias de ejecución sólidas. Desarrollar secuencias de comandos personalizadas que sean escalables, fiables y fáciles de mantener no es una tarea sencilla. Las secuencias de comandos personalizadas a menudo pueden provocar una reducción de los valores de RPO e incluso un aumento de los riesgos de pérdida de datos.
Para obtener información sobre cómo mover grandes volúmenes de datos de ubicaciones on-premise a Cloud Storage, consulta el artículo Mover o crear copias de seguridad de datos de almacenamiento on-premise.
Solución 3: Crear una copia de seguridad en Cloud Storage mediante una solución de pasarela de partner
Este patrón usa los siguientes elementos básicos de recuperación ante desastres:
- Cloud Interconnect
- Almacenamiento por niveles de Cloud Storage
Las aplicaciones on-premise suelen integrarse con soluciones de terceros que se pueden usar como parte de tu estrategia de copia de seguridad y recuperación de datos. Las soluciones suelen usar un patrón de almacenamiento por niveles en el que las copias de seguridad más recientes se almacenan en un almacenamiento más rápido y las más antiguas se migran lentamente a un almacenamiento más barato (y lento). Cuando usas Google Cloud como destino, tienes varias opciones de clase de almacenamiento disponibles para usar como equivalente del nivel más lento.
Una forma de implementar este patrón es usar una pasarela de partner entre tu almacenamiento local y Google Cloud para facilitar la transferencia de datos a Cloud Storage. En el siguiente diagrama se muestra esta configuración, con una solución de partner que gestiona la transferencia desde el dispositivo NAS o la SAN local.

En caso de fallo, los datos de los que se haya creado una copia de seguridad deben recuperarse en tu entorno de recuperación tras desastres. El entorno de recuperación ante desastres se usa para servir el tráfico de producción hasta que puedas volver a tu entorno de producción. La forma de conseguirlo depende de tu aplicación, de la solución del partner y de su arquitectura. (Algunos casos prácticos de principio a fin se describen en el documento de la solicitud de DR).
También puedes usar bases de datos Google Cloud gestionadas como destinos de recuperación ante desastres. Por ejemplo, Cloud SQL para SQL Server admite importaciones de registros de transacciones. Puedes exportar los registros de transacciones de tu instancia de SQL Server local, subirlos a Cloud Storage e importarlos a Cloud SQL para SQL Server.
Para obtener más información sobre cómo transferir datos de un entorno local aGoogle Cloud, consulta Transferir conjuntos de Big Data a Google Cloud.
Para obtener más información sobre las soluciones de partners, consulta la página de partners del sitio web de Google Cloud .
Copia de seguridad y recuperación de bases de datos
Puedes usar varias estrategias para implementar un proceso que permita recuperar una base de datos de un sistema local a Google Cloud. En esta sección se analizan dos de las soluciones más habituales.
En este documento no se explica en detalle los distintos mecanismos de copia de seguridad y recuperación integrados que incluyen las bases de datos de terceros. En esta sección se ofrecen directrices generales, que se implementan en las soluciones que se describen en este artículo.
Solución 1: Copia de seguridad y recuperación mediante un servidor de recuperación en Google Cloud
- Crea una copia de seguridad de la base de datos con los mecanismos de copia de seguridad integrados de tu sistema de gestión de bases de datos.
- Conecta tu red local y tu red de Google Cloud .
- Crea un segmento de Cloud Storage como destino de tu copia de seguridad de datos.
- Copia los archivos de copia de seguridad en Cloud Storage mediante
gcloud storagegcloud CLI o una solución de pasarela de partner (consulta los pasos que se han descrito anteriormente en la sección sobre copias de seguridad y recuperación de datos). Para obtener más información, consulta el artículo Migrar a Google Cloud: transferir conjuntos de datos grandes. - Copia los registros de transacciones en tu sitio de recuperación en Google Cloud. Tener una copia de seguridad de los registros de transacciones ayuda a mantener los valores de RPO bajos.
Después de configurar esta topología de copia de seguridad, debes asegurarte de que puedes restaurar el sistema que está en Google Cloud. Este paso suele implicar no solo restaurar el archivo de copia de seguridad en la base de datos de destino, sino también reproducir los registros de transacciones para obtener el valor de RTO más pequeño. Una secuencia de recuperación típica tiene este aspecto:
- Crea una imagen personalizada de tu servidor de base de datos en Google Cloud. El servidor de bases de datos debe tener la misma configuración en la imagen que tu servidor de bases de datos local.
- Implementa un proceso para copiar tus archivos de copia de seguridad y de registro de transacciones locales en Cloud Storage. Consulta la solución 1 para ver un ejemplo de implementación.
- Inicia una instancia de tamaño mínimo a partir de la imagen personalizada y adjunta los discos persistentes que necesites.
- Define la marca de eliminación automática como false en los discos persistentes.
- Aplica el archivo de copia de seguridad más reciente que se haya copiado anteriormente en Cloud Storage. Para ello, sigue las instrucciones del sistema de tu base de datos para recuperar archivos de copia de seguridad.
- Aplica el conjunto más reciente de archivos de registro de transacciones que se hayan copiado en Cloud Storage.
- Sustituye la instancia mínima por una más grande que pueda aceptar tráfico de producción.
- Cambia los clientes para que apunten a la base de datos recuperada en Google Cloud.
Cuando tu entorno de producción esté en funcionamiento y pueda admitir cargas de trabajo de producción, tendrás que invertir los pasos que has seguido para conmutar por error al entorno de recuperaciónGoogle Cloud . Una secuencia habitual para volver al entorno de producción sería la siguiente:
- Crea una copia de seguridad de la base de datos que se ejecuta en Google Cloud.
- Copia el archivo de copia de seguridad en tu entorno de producción.
- Aplica el archivo de copia de seguridad a tu sistema de base de datos de producción.
- Impide que los clientes se conecten al sistema de base de datos enGoogle Cloud. Por ejemplo, deteniendo el servicio del sistema de base de datos. A partir de este momento, tu aplicación no estará disponible hasta que termines de restaurar el entorno de producción.
- Copia los archivos de registro de transacciones en el entorno de producción y aplícalos.
- Redirige las conexiones de cliente al entorno de producción.
Solución 2: Replicación en un servidor de reserva en Google Cloud
Una forma de conseguir valores de RTO y RPO muy bajos es replicar (no solo crear copias de seguridad) los datos y, en algunos casos, el estado de la base de datos en tiempo real en una réplica del servidor de la base de datos.
- Conecta tu red local y tu red de Google Cloud .
- Crea una imagen personalizada de tu servidor de base de datos en Google Cloud. El servidor de bases de datos debe tener la misma configuración en la imagen que el servidor de bases de datos local.
- Inicia una instancia a partir de la imagen personalizada y adjunta los discos persistentes que necesites.
- Define la marca de eliminación automática como false en los discos persistentes.
- Configura la replicación entre tu servidor de bases de datos local y el servidor de bases de datos de destino en Google Cloud siguiendo las instrucciones específicas del software de la base de datos.
- Los clientes se configuran en funcionamiento normal para que apunten al servidor de la base de datos local.
Después de configurar esta topología de replicación, cambia los clientes para que apunten al servidor de espera que se ejecuta en tu Google Cloud red.
Cuando tu entorno de producción vuelva a estar operativo y pueda admitir cargas de trabajo de producción, tendrás que volver a sincronizar el servidor de la base de datos de producción con el servidor de la base de datosGoogle Cloud y, a continuación, cambiar los clientes para que vuelvan a apuntar al entorno de producción.
El entorno de producción es Google Cloud
En este caso, tanto el entorno de producción como el de recuperación tras desastres se ejecutan en Google Cloud.
Copia de seguridad y recuperación de datos
Un patrón habitual para las copias de seguridad de datos es usar un patrón de almacenamiento por niveles. Cuando la carga de trabajo de producción está Google Cloudactivada Google Cloud, el sistema de almacenamiento por niveles tiene el aspecto del siguiente diagrama. Migras los datos a un nivel con costes de almacenamiento más bajos, ya que es menos probable que necesites acceder a los datos de la copia de seguridad.
Este patrón usa los siguientes elementos básicos de recuperación ante desastres:
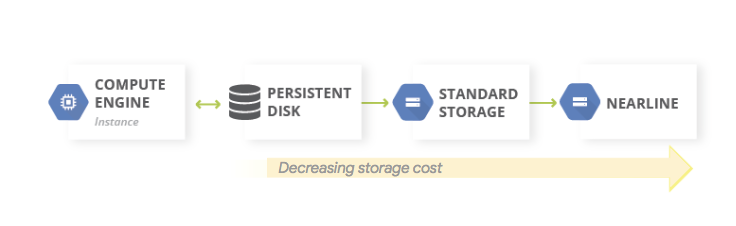
Como las clases de almacenamiento Nearline, Coldline y Archive sirven para almacenar datos a los que no se accede a menudo, se aplican otros cargos si extraes datos o metadatos almacenados en estas clases. También se aplica un cargo por tiempo mínimo de almacenamiento.
Copia de seguridad y recuperación de bases de datos
Cuando usas una base de datos autogestionada (por ejemplo, has instalado MySQL, PostgreSQL o SQL Server en una instancia de Compute Engine), se aplican las mismas consideraciones operativas que al gestionar bases de datos de producción on-premise, pero ya no tienes que gestionar la infraestructura subyacente.
El Servicio de Backup y DR es una solución centralizada y nativa de la nube para crear copias de seguridad y recuperar cargas de trabajo en la nube y en entornos híbridos. Ofrece una recuperación de datos rápida y facilita la reanudación de las operaciones empresariales esenciales.
Para obtener más información sobre cómo usar Backup y DR en escenarios de bases de datos autogestionadas en Google Cloud, consulta lo siguiente:
También puedes configurar la alta disponibilidad usando las funciones de los componentes básicos de recuperación ante desastres adecuadas para mantener un RTO bajo. Puedes diseñar la configuración de tu base de datos para que sea posible restaurarla a un estado lo más parecido posible al anterior al desastre. De esta forma, los valores de RPO serán pequeños. Google Cloud ofrece una amplia variedad de opciones para este caso.
En esta sección se describen dos enfoques habituales para diseñar la arquitectura de recuperación de bases de datos autogestionadas en Google Cloud .
Recuperar un servidor de bases de datos sin sincronizar el estado
Un patrón habitual es habilitar la recuperación de un servidor de base de datos que no requiera que el estado del sistema se sincronice con una réplica de espera actualizada.
Este patrón usa los siguientes elementos básicos de recuperación ante desastres:
- Compute Engine
- Grupos de instancias administradas
- Cloud Load Balancing (balanceo de carga interno)
En el siguiente diagrama se muestra una arquitectura de ejemplo que aborda el escenario. Al implementar esta arquitectura, dispondrá de un plan de recuperación tras fallos que reacciona automáticamente ante un fallo sin necesidad de realizar una recuperación manual.

En los siguientes pasos se explica cómo configurar este caso:
- Crea una red VPC.
Crea una imagen personalizada que esté configurada con el servidor de la base de datos siguiendo estos pasos:
- Configura el servidor para que los archivos de base de datos y los archivos de registro se escriban en un disco persistente estándar conectado.
- Crea una captura del disco persistente conectado.
- Configura una secuencia de comandos de inicio para crear un disco persistente a partir de la captura y montar el disco.
- Crea una imagen personalizada del disco de arranque.
Crea una plantilla de instancia que use la imagen.
Con la plantilla de instancia, configura un grupo de instancias gestionado con un tamaño objetivo de 1.
Configura la comprobación del estado mediante métricas de Cloud Monitoring.
Configura el balanceo de carga interno con el grupo de instancias gestionado.
Configura una tarea programada para crear capturas periódicas del disco persistente.
Si es necesario sustituir una instancia de base de datos, esta configuración hará lo siguiente automáticamente:
- Abre otro servidor de base de datos con la versión correcta en la misma zona.
- Adjunta un disco persistente que tiene los archivos de copia de seguridad y de registro de transacciones más recientes a la instancia del servidor de base de datos recién creada.
- Minimiza la necesidad de volver a configurar los clientes que se comunican con el servidor de bases de datos en respuesta a un evento.
- Asegura que los Google Cloud controles de seguridad (políticas de gestión de identidades y accesos, configuración del cortafuegos) que se aplican al servidor de la base de datos de producción se apliquen al servidor de la base de datos recuperado.
Como la instancia de sustitución se crea a partir de una plantilla de instancia, los controles que se aplicaron a la original se aplican a la instancia de sustitución.
En este caso, se aprovechan algunas de las funciones de alta disponibilidad disponibles enGoogle Cloud. No tienes que iniciar ningún paso de conmutación por error, ya que se producen automáticamente en caso de desastre. El balanceador de carga interno se asegura de que, incluso cuando se necesita una instancia de sustitución, se utilice la misma dirección IP para el servidor de la base de datos. La plantilla de instancia y la imagen personalizada aseguran que la instancia de sustitución se configure de forma idéntica a la instancia que sustituye. Si haces capturas periódicas de los discos persistentes, te aseguras de que, cuando se vuelvan a crear los discos a partir de las capturas y se adjunten a la instancia de sustitución, esta use los datos recuperados según un valor de RPO determinado por la frecuencia de las capturas. En esta arquitectura, los archivos de registro de transacciones más recientes que se escribieron en el disco persistente también se restauran automáticamente.
El grupo de instancias gestionado proporciona alta disponibilidad en profundidad. Proporciona mecanismos para reaccionar ante fallos a nivel de aplicación o de instancia, y no tienes que intervenir manualmente si se produce alguno de estos casos. Si defines un tamaño objetivo de uno, te aseguras de que solo haya una instancia activa que se ejecute en el grupo de instancias gestionado y que sirva tráfico.
Los discos persistentes estándar son zonales, por lo que, si se produce un fallo en una zona, se necesitan instantáneas para volver a crear los discos. Las capturas también están disponibles en todas las regiones, lo que te permite restaurar un disco no solo en la misma región, sino también en otra.
Una variante de esta configuración es usar discos persistentes regionales en lugar de discos persistentes estándar. En este caso, no es necesario que restaures la captura como parte del paso de recuperación.
La variación que elijas dependerá de tu presupuesto y de los valores de RTO y RPO.
Recuperación de daños parciales en bases de datos muy grandes
La replicación asíncrona de Persistent Disk ofrece replicación de almacenamiento en bloques con un RPO y un RTO bajos para la recuperación tras fallos activa-pasiva entre regiones. Esta opción de almacenamiento te permite gestionar la replicación de cargas de trabajo de Compute Engine a nivel de infraestructura, en lugar de a nivel de carga de trabajo.
Si usas una base de datos capaz de almacenar petabytes de datos, es posible que se produzca una interrupción que afecte a algunos de los datos, pero no a todos. En ese caso, te interesa minimizar la cantidad de datos que necesitas restaurar. No es necesario (ni recomendable) recuperar toda la base de datos solo para restaurar algunos datos.
Puedes adoptar varias estrategias de mitigación:
- Almacena tus datos en diferentes tablas durante periodos específicos. Este método asegura que solo tengas que restaurar un subconjunto de datos en una tabla nueva, en lugar de todo un conjunto de datos.
Almacena los datos originales en Cloud Storage. Con este método, puedes crear una tabla y volver a cargar los datos que no estén dañados. Desde ahí, puedes ajustar tus aplicaciones para que apunten a la nueva tabla.
Además, si tu RTO lo permite, puedes impedir el acceso a la tabla que tiene los datos dañados dejando tus aplicaciones sin conexión hasta que los datos no dañados se hayan restaurado en una tabla nueva.
Servicios de bases de datos gestionados en Google Cloud
En esta sección se describen algunos métodos que puedes usar para implementar mecanismos de copia de seguridad y recuperación adecuados para los servicios de bases de datos gestionados enGoogle Cloud.
Las bases de datos gestionadas se han diseñado para escalar, por lo que los mecanismos tradicionales de copia de seguridad y restauración que se ven en los SGBDR tradicionales no suelen estar disponibles. Al igual que en el caso de las bases de datos autogestionadas, si utilizas una base de datos que puede almacenar petabytes de datos, te interesa minimizar la cantidad de datos que necesitas restaurar en un escenario de recuperación ante desastres. Hay varias estrategias para cada base de datos gestionada que te ayudarán a conseguir este objetivo.
Bigtable ofrece la replicación de Bigtable. Una base de datos de Bigtable replicada puede proporcionar una mayor disponibilidad que un solo clúster, un mayor rendimiento de lectura y una mayor durabilidad y resiliencia en caso de fallos de zonas o regiones.
Las copias de seguridad de Bigtable son un servicio totalmente gestionado que te permite guardar una copia del esquema y los datos de una tabla, y luego restaurarla en una tabla nueva más adelante.
También puedes exportar tablas de Bigtable como una serie de archivos de secuencia de Hadoop. Después, puedes almacenar estos archivos en Cloud Storage o usarlos para importar los datos a otra instancia de Bigtable. Puedes replicar tu conjunto de datos de Bigtable de forma asíncrona en diferentes zonas de una Google Cloud región.
BigQuery. Si quieres archivar datos, puedes aprovechar el almacenamiento a largo plazo de BigQuery. Si no se edita una tabla durante 90 días consecutivos, el precio de almacenamiento de esa tabla disminuirá automáticamente en un 50 %. Cuando se considera que una tabla está almacenada a largo plazo, no se produce ninguna degradación del rendimiento, la durabilidad, la disponibilidad ni de ninguna otra funcionalidad. Sin embargo, si se edita la tabla, el precio cambia al del almacenamiento habitual y la cuenta atrás de 90 días vuelve a empezar.
BigQuery se replica en dos zonas de una misma región, pero esto no te ayudará a evitar que se dañen tus tablas. Por lo tanto, debes tener un plan para poder recuperarte de esa situación. Por ejemplo, puedes hacer lo siguiente:
- Si la corrupción se detecta en un plazo de 7 días, consulta la tabla en un momento anterior para recuperarla antes de que se produjera la corrupción mediante decoradores de instantánea.
- Exporta los datos de BigQuery y crea una tabla que contenga los datos exportados, pero que excluya los datos dañados.
- Almacena tus datos en diferentes tablas durante periodos específicos. Este método asegura que solo tengas que restaurar un subconjunto de datos en una tabla nueva, en lugar de todo el conjunto de datos.
- Haz copias de tu conjunto de datos en periodos específicos. Puedes usar estas copias si se produce un evento de corrupción de datos que no se puede capturar con una consulta de un momento concreto (por ejemplo, si ha ocurrido hace más de 7 días). También puede copiar un conjunto de datos de una región a otra para asegurarse de que los datos estén disponibles en caso de que se produzcan fallos en una región.
- Almacena los datos originales en Cloud Storage, lo que te permite crear una tabla y volver a cargar los datos sin daños. Desde ahí, puedes ajustar tus aplicaciones para que apunten a la nueva tabla.
Firestore. El servicio de importación y exportación gestionado te permite importar y exportar entidades de Firestore mediante un segmento de Cloud Storage. Después, puedes implementar un proceso que se pueda usar para recuperar datos que se hayan eliminado por accidente.
Cloud SQL. Si usas Cloud SQL, la base de datos MySQL totalmente gestionada, debes habilitar las copias de seguridad automáticas y el registro binario de tus instancias de Cloud SQL.Google Cloud Este enfoque te permite realizar una recuperación a un momento dado, que restaura tu base de datos a partir de una copia de seguridad y la recupera en una instancia de Cloud SQL nueva. Para obtener más información, consulta Acerca de las copias de seguridad de Cloud SQL y Acerca de la recuperación tras desastres en Cloud SQL.
También puedes configurar Cloud SQL en una configuración de alta disponibilidad y réplicas interregionales para maximizar el tiempo de actividad en caso de que se produzca un fallo en una zona o una región.
Si has habilitado el mantenimiento programado con un tiempo de inactividad casi nulo en Cloud SQL, puedes evaluar el impacto de los eventos de mantenimiento en tus instancias simulando eventos de mantenimiento programado con un tiempo de inactividad casi nulo en Cloud SQL para MySQL y en Cloud SQL para PostgreSQL.
En la edición Enterprise Plus de Cloud SQL, puedes usar la recuperación tras fallos (DR) avanzada para simplificar los procesos de recuperación y de conmutación por error con cero pérdida de datos después de realizar una conmutación por error entre regiones.
Spanner. Puedes usar plantillas de Dataflow para hacer una exportación completa de tu base de datos a un conjunto de archivos Avro en un segmento de Cloud Storage y usar otra plantilla para reimportar los archivos exportados en una nueva base de datos de Spanner.
Para hacer copias de seguridad de forma más controlada, el conector de Dataflow te permite escribir código para leer y escribir datos en Spanner en una canalización de Dataflow. Por ejemplo, puede usar el conector para copiar datos de Spanner a Cloud Storage como destino de la copia de seguridad. La velocidad a la que se pueden leer datos de Spanner (o escribir datos en él) depende del número de nodos configurados. Esto tiene un impacto directo en los valores de RTO.
La función marca de tiempo de confirmación de Spanner puede ser útil para las copias de seguridad incrementales, ya que te permite seleccionar solo las filas que se han añadido o modificado desde la última copia de seguridad completa.
En el caso de las copias de seguridad gestionadas, Copia de seguridad y restauración de Spanner te permite crear copias de seguridad coherentes que se pueden conservar durante un máximo de 1 año. El valor de RTO es inferior en comparación con la exportación porque la operación de restauración monta directamente la copia de seguridad sin copiar los datos.
En el caso de valores de RTO pequeños, puedes configurar una instancia de Spanner en espera activa con el número mínimo de nodos necesario para cumplir tus requisitos de almacenamiento y de rendimiento de lectura y escritura.
La recuperación a un momento dado (PITR) de Spanner te permite recuperar datos de un momento específico del pasado. Por ejemplo, si un operador escribe datos por error o si el lanzamiento de una aplicación daña la base de datos, con PITR puedes recuperar los datos de un momento determinado del pasado, hasta un máximo de 7 días.
Cloud Composer. Puedes usar Cloud Composer (una versión gestionada de Apache Airflow) para programar copias de seguridad periódicas de varias bases de datos deGoogle Cloud . Puedes crear un gráfico acíclico dirigido (DAG) para que se ejecute de forma programada (por ejemplo, a diario) y copie los datos en otro proyecto, conjunto de datos o tabla (en función de la solución utilizada) o para exportar los datos a Cloud Storage.
Para exportar o copiar datos, puedes usar los distintos operadores de Cloud Platform.
Por ejemplo, puedes crear un DAG para hacer lo siguiente:
- Exporta una tabla de BigQuery a Cloud Storage mediante el operador BigQueryToCloudStorageOperator.
- Exporta Firestore en modo Datastore (Datastore) a Cloud Storage con el operador DatastoreExportOperator.
- Exporta tablas de MySQL a Cloud Storage con el operador MySqlToGoogleCloudStorageOperator.
- Exporta tablas de Postgres a Cloud Storage con el operador PostgresToGoogleCloudStorageOperator.
El entorno de producción es otra nube
En este caso, tu entorno de producción usa otro proveedor de servicios en la nube y tu plan de recuperación tras desastres incluye el uso de Google Cloud como sitio de recuperación.
Copia de seguridad y recuperación de datos
La transferencia de datos entre almacenes de objetos es un caso práctico habitual en escenarios de recuperación ante desastres. Storage Transfer Service es compatible con Amazon S3 y es la forma recomendada de transferir objetos de Amazon S3 a Cloud Storage.
Puedes configurar un trabajo de transferencia para programar la sincronización periódica de la fuente de datos con el sumidero de datos mediante filtros avanzados basados en las fechas de creación, los filtros de nombres de archivos y las horas del día a las que prefieres transferir los datos. Para conseguir el RPO que quieras, debes tener en cuenta los siguientes factores:
Tasa de cambio. Cantidad de datos que se generan o actualizan durante un periodo determinado. Cuanto mayor sea la tasa de cambio, más recursos se necesitarán para transferir los cambios al destino en cada periodo de transferencia incremental.
Rendimiento de las transferencias. El tiempo que se tarda en transferir los archivos. En el caso de las transferencias de archivos grandes, suele depender del ancho de banda disponible entre el origen y el destino. Sin embargo, si un trabajo de transferencia consta de un gran número de archivos pequeños, las consultas por segundo pueden convertirse en un factor limitante. Si es así, puedes programar varias tareas simultáneas para escalar el rendimiento siempre que haya suficiente ancho de banda disponible. Te recomendamos que midas el rendimiento de la transferencia con un subconjunto representativo de tus datos reales.
Frecuencia Intervalo entre tareas de copia de seguridad. La actualización de los datos del destino es tan reciente como la última vez que se programó una tarea de transferencia. Por lo tanto, es importante que los intervalos entre las tareas de transferencia sucesivas no sean más largos que tu objetivo de RPO. Por ejemplo, si el objetivo de RPO es de 1 día, el trabajo de transferencia debe programarse al menos una vez al día.
Monitorización y alertas. El Servicio de transferencia de Storage ofrece notificaciones de Pub/Sub sobre una gran variedad de eventos. Te recomendamos que te suscribas a estas notificaciones para gestionar fallos inesperados o cambios en los tiempos de finalización de los trabajos.
Copia de seguridad y recuperación de bases de datos
En este documento no se describen en detalle los distintos mecanismos de copia de seguridad y recuperación integrados que incluyen las bases de datos de terceros ni las técnicas de copia de seguridad y recuperación que se utilizan en otros proveedores de servicios en la nube. Si utilizas bases de datos no gestionadas en los servicios de computación, puedes aprovechar las funciones de alta disponibilidad que ofrece tu proveedor de nube de producción. Puedes ampliar estas opciones para incorporar una implementación de alta disponibilidad en Google Cloudo usar Cloud Storage como destino final para el almacenamiento en frío de tus archivos de copia de seguridad de la base de datos.
Siguientes pasos
- Consulta información sobre Google Cloud geografía y regiones.
Lee otros documentos de esta serie de recuperación ante desastres:
- Guía de planificación para la recuperación tras fallos
- Componentes básicos de recuperación tras fallos
- Situaciones de recuperación tras fallos de aplicaciones
- Diseñar la recuperación tras fallos para cargas de trabajo con restricciones de localidad
- Casos prácticos de recuperación ante desastres: aplicaciones de analíticas de datos restringidas por localidad
- Diseñar la recuperación tras fallos para las interrupciones de la infraestructura de la nube
- Arquitecturas de alta disponibilidad de clústeres de MySQL en Compute Engine
Consulta arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Centro de arquitectura de Cloud.