In un data mesh, una piattaforma di dati self-service consente agli utenti di generare valore dai dati consentendo loro di creare, condividere e utilizzare autonomamente i prodotti di dati. Per sfruttare appieno questi vantaggi, ti consigliamo di utilizzare una piattaforma self-service per i dati che offra le funzionalità descritte in questo documento.
Questo documento fa parte di una serie che descrive come implementare un data mesh su Google Cloud. Si presuppone che tu abbia letto e conosca i concetti descritti in Crea un data mesh moderno e distribuito con Google Cloud e Architettura e funzioni in un data mesh.
La serie è composta dalle seguenti parti:
- Architettura e funzioni in un mesh di dati
- Progettare una piattaforma di dati self-service per un mesh di dati (questo documento)
- Creare prodotti di dati in un data mesh
- Scoprire e utilizzare i prodotti di dati in una data mesh
I team della piattaforma di dati in genere creano piattaforme di dati self-service centrali, come descritto in questo documento. Questo team crea le soluzioni e i componenti che i team di dominio (produttori e consumatori di dati) possono utilizzare per creare e consumare prodotti di dati. I team di dominio rappresentano le parti funzionali di un data mesh. Creando questi componenti, il team della piattaforma di dati consente un'esperienza di sviluppo fluida e riduce la complessità di creazione, deployment e manutenzione di prodotti di dati sicuri e interoperabili.
In definitiva, il team della piattaforma di dati deve consentire ai team di dominio di agire più rapidamente. Aiutano ad aumentare l'efficienza dei team di dominio fornendo loro un insieme limitato di strumenti che soddisfano le loro esigenze. Fornendo questi strumenti, il team della piattaforma di dati elimina l'onere di far creare e reperire questi strumenti al team del dominio. Le scelte degli strumenti devono essere personalizzabili in base alle diverse esigenze e non imporre un modo di lavorare inflessibile ai team del dominio dei dati.
Il team della piattaforma di dati non deve concentrarsi sulla creazione di soluzioni personalizzate per gli orchestratori di pipeline di dati o per i sistemi di integrazione continua e deployment continuo (CI/CD). Soluzioni come i sistemi CI/CD sono facilmente disponibili come servizi cloud gestiti, ad esempio Cloud Build. L'utilizzo di servizi cloud gestiti può ridurre l'overhead operativo per il team della piattaforma di dati e consentire di concentrarsi sulle esigenze specifiche dei team del dominio dei dati in qualità di utenti della piattaforma. Con un overhead operativo ridotto, il team della piattaforma di dati può dedicare più tempo a soddisfare le esigenze specifiche dei team del dominio dei dati.
Architettura
Il seguente diagramma illustra i componenti dell'architettura di una piattaforma di dati self-service. Il diagramma mostra anche come questi componenti possono supportare i team mentre sviluppano e utilizzano i prodotti dati nella data mesh.

Come mostrato nel diagramma precedente, la piattaforma dati self-service fornisce quanto segue:
Soluzioni di piattaforma:queste soluzioni sono costituite da componenti componibili per il provisioning di progetti e risorse, che gli utenti selezionano e assemblano in diverse combinazioni per soddisfare i loro requisiti specifici. Google Cloud Anziché interagire direttamente con i componenti, gli utenti della piattaforma possono interagire con le soluzioni della piattaforma per raggiungere un obiettivo specifico. I team del dominio dei dati devono progettare soluzioni di piattaforma per risolvere i problemi comuni e le aree di attrito che causano rallentamenti nello sviluppo e nel consumo dei prodotti di dati. Ad esempio, i team del dominio dei dati che eseguono l'onboarding nel data mesh possono utilizzare un modello Infrastructure as Code (IaC). L'utilizzo di modelli IaC consente di creare rapidamente un insieme di Google Cloud progetti con autorizzazioni IAM (Identity and Access Management), networking, norme di sicurezza e API pertinenti Google Cloud abilitate per lo sviluppo di prodotti di dati. Consigliamo di accompagnare ogni soluzione con documentazione come istruzioni su "come iniziare" e campioni di codice. Le soluzioni della piattaforma dati e i relativi componenti devono essere sicuri e conformi per impostazione predefinita.
Servizi comuni: questi servizi forniscono rilevabilità, gestione, condivisione e osservabilità dei prodotti di dati. Questi servizi facilitano la fiducia dei consumatori nei prodotti di dati e sono un modo efficace per i produttori di dati di avvisare i consumatori di dati in merito a problemi con i loro prodotti di dati.
Le soluzioni della piattaforma di dati e i servizi comuni potrebbero includere quanto segue:
- Modelli IaC per configurare ambienti di sviluppo dello spazio di lavoro del prodotto di dati di base, che includono quanto segue:
- IAM
- Logging e monitoraggio
- Networking
- Barriere di protezione per la sicurezza e la conformità
- Tagging delle risorse per l'attribuzione della fatturazione
- Archiviazione, trasformazione e pubblicazione dei prodotti di dati
- Registrazione, catalogazione e tagging dei metadati dei prodotti di dati
- Modelli IaC che seguono le misure di salvaguardia della sicurezza e le best practice dell'organizzazione che possono essere utilizzati per eseguire il deployment delle risorse Google Cloud negli spazi di lavoro di sviluppo dei prodotti di dati esistenti.
- Modelli di pipeline di applicazioni e dati che possono essere utilizzati per il bootstrap
di nuovi progetti o come riferimento per progetti esistenti. Ecco alcuni esempi di questi modelli:
- Utilizzo di librerie e framework comuni
- Integrazione con gli strumenti di logging, monitoraggio e osservabilità della piattaforma
- Strumenti di build e test
- Gestione della configurazione
- Pipeline di packaging e CI/CD per il deployment
- Autenticazione, deployment e gestione delle credenziali
- Servizi comuni per fornire osservabilità e governance dei prodotti di dati
che possono includere quanto segue:
- Controlli di uptime per mostrare lo stato generale dei prodotti di dati.
- Metriche personalizzate per fornire indicatori utili sui prodotti di dati.
- Supporto operativo da parte del team centrale in modo che i team di consumer di dati vengano avvisati delle modifiche ai prodotti di dati che utilizzano.
- Prospetti dei prodotti per mostrare il rendimento dei prodotti dati.
- Un catalogo di metadati per scoprire i prodotti dati.
- Un insieme di criteri di calcolo definiti centralmente che possono essere applicati a livello globale in tutta la mesh di dati.
- Un marketplace di dati per facilitare la condivisione dei dati tra i team di dominio.
Crea componenti e soluzioni della piattaforma utilizzando i modelli IaC illustra i vantaggi dei modelli IaC per esporre ed eseguire il deployment dei prodotti di dati. Fornire servizi comuni spiega perché è utile fornire ai team di dominio componenti di infrastruttura comuni che sono stati creati e vengono gestiti dal team della piattaforma dati.
Crea componenti e soluzioni della piattaforma utilizzando i modelli IaC
L'obiettivo dei team della piattaforma di dati è configurare piattaforme di dati self-service per ottenere più valore dai dati. Per creare queste piattaforme, creano e forniscono ai team di dominio modelli di infrastruttura verificati, sicuri e self-service. I team di dominio utilizzano questi modelli per implementare gli ambienti di sviluppo e consumo dei dati. I modelli IaC aiutano i team della piattaforma dati a raggiungere questo obiettivo e consentono di scalare. L'utilizzo di modelli IaC verificati e attendibili semplifica il processo di deployment delle risorse per i team di dominio, consentendo loro di riutilizzare le pipeline CI/CD esistenti. Questo approccio consente ai team di dominio di iniziare rapidamente e diventare produttivi all'interno del data mesh.
I modelli IaC possono essere creati utilizzando uno strumento IaC. Sebbene esistano più strumenti IaC, tra cui Cloud Config Connector, Pulumi, Chef e Ansible, questo documento fornisce esempi per strumenti IaC basati su Terraform. Terraform è uno strumento IaC open source che consente al team della piattaforma dati di creare in modo efficiente componenti e soluzioni della piattaforma componibili per le risorseGoogle Cloud . Utilizzando Terraform, il team della piattaforma di dati scrive codice che specifica lo stato finale scelto e consente allo strumento di capire come raggiungere questo stato. Questo approccio dichiarativo consente al team della piattaforma di dati di trattare le risorse dell'infrastruttura come artefatti immutabili per il deployment in vari ambienti. Inoltre, contribuisce a ridurre il rischio di incoerenze tra le risorse di cui è stato eseguito il deployment e il codice dichiarato nel controllo del codice sorgente (noto come deviazione della configurazione). La deriva della configurazione causata da modifiche manuali e ad hoc all'infrastruttura ostacola l'implementazione sicura e ripetibile dei componenti IaC negli ambienti di produzione.
I modelli IaC comuni per i componenti della piattaforma componibili includono l'utilizzo di moduli Terraform per il deployment di risorse come un set di dati BigQuery, un bucket Cloud Storage o un database Cloud SQL. I moduli Terraform possono essere combinati in soluzioni end-to-end per il deployment di progetti Google Cloud completi, incluse le risorse pertinenti di cui è stato eseguito il deployment utilizzando i moduli componibili. Puoi trovare moduli Terraform di esempio in Progetti base Terraform per Google Cloud.
Per impostazione predefinita, ogni modulo Terraform deve soddisfare le misure di salvaguardia della sicurezza e le norme di conformità utilizzate dalla tua organizzazione. Queste misure di salvaguardia e norme possono anche essere espresse come codice e automatizzate utilizzando strumenti di verifica della conformità automatizzati come lo Google Cloud strumento di convalida delle norme.
La tua organizzazione deve testare continuamente i moduli Terraform forniti dalla piattaforma, utilizzando gli stessi guardrail di conformità automatizzati che utilizza per promuovere le modifiche in produzione.
Per rendere i componenti e le soluzioni IaC rilevabili e utilizzabili per i team di dominio con un'esperienza minima con Terraform, ti consigliamo di utilizzare servizi come Service Catalog. Gli utenti con requisiti di personalizzazione significativi devono poter creare le proprie soluzioni di deployment a partire dagli stessi modelli Terraform componibili utilizzati dalle soluzioni esistenti.
Quando utilizzi Terraform, ti consigliamo di seguire le best practice di Google Cloudcome descritto in Best practice per l'utilizzo di Terraform.
Per illustrare come Terraform può essere utilizzato per creare componenti della piattaforma, le sezioni seguenti descrivono esempi di come Terraform può essere utilizzato per esporre interfacce di consumo e per utilizzare un prodotto di dati.
Esporre un'interfaccia di consumo
Un'interfaccia di consumo per un prodotto di dati è un insieme di garanzie sulla qualità dei dati e sui parametri operativi forniti dal team del dominio di dati per consentire ad altri team di scoprire e utilizzare i propri prodotti di dati. Ogni interfaccia di consumo include anche un modello di assistenza e la documentazione del prodotto. Un prodotto di dati può avere diversi tipi di interfacce di consumo, come API o stream, come descritto in Creare prodotti di dati in una data mesh. L'interfaccia di consumo più comune potrebbe essere un set di dati, una vista o una funzione autorizzati di BigQuery. Questa interfaccia espone una tabella virtuale di sola lettura, espressa come query nel mesh di dati. L'interfaccia non concede le autorizzazioni di lettura per accedere direttamente ai dati sottostanti.
Google fornisce un esempio di
modulo Terraform per la creazione di viste autorizzate
senza concedere ai team le autorizzazioni per i set di dati autorizzati sottostanti. Il
seguente codice di questo modulo Terraform concede queste autorizzazioni IAM
nella vista autorizzata dataset_id:
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
Se devi concedere agli utenti l'accesso a più viste, concedere l'accesso a ogni vista autorizzata può richiedere molto tempo ed essere più difficile da gestire. Anziché creare più visualizzazioni autorizzate, puoi utilizzare un set di dati autorizzato per autorizzare automaticamente qualsiasi visualizzazione creata nel set di dati autorizzato.
Utilizzare un prodotto di dati
Per la maggior parte dei casi d'uso di Analytics, i pattern di consumo sono determinati dall'applicazione in cui vengono utilizzati i dati. L'utilizzo principale di un ambiente di consumo fornito centralmente è l'esplorazione dei dati prima che vengano utilizzati all'interno dell'applicazione di consumo. Come descritto in Scoprire e utilizzare i prodotti in un data mesh, SQL è il metodo più comunemente utilizzato per eseguire query sui prodotti di dati. Per questo motivo, la piattaforma di dati deve fornire ai consumatori di dati un'applicazione SQL per l'esplorazione dei dati.
A seconda del caso d'uso di Analytics, potresti essere in grado di utilizzare Terraform per eseguire il deployment dell'ambiente di consumo per i consumatori di dati. Ad esempio, la scienza dei dati è un caso d'uso comune per i consumatori di dati. Puoi utilizzare Terraform per eseguire il deployment di notebook Vertex AI gestiti dall'utente da utilizzare come ambiente di sviluppo di data science. Dai notebook di data science, i consumatori di dati possono utilizzare le proprie credenziali per accedere al data mesh ed esplorare i dati a cui hanno accesso e sviluppare modelli ML basati su questi dati.
Per scoprire come utilizzare Terraform per eseguire il deployment e contribuire a proteggere un ambiente notebook su Google Cloud, consulta Creare ed eseguire il deployment di modelli di AI generativa e machine learning in un'azienda.
Fornire servizi comuni
Oltre a componenti e soluzioni IaC self-service, il team della piattaforma dati potrebbe anche assumersi la responsabilità di creare e gestire servizi di piattaforma condivisi comuni utilizzati da più team di domini di dati. Esempi comuni di servizi di piattaforma condivisi includono software di terze parti self-hosted come strumenti di visualizzazione di business intelligence o un cluster Kafka. In Google Cloud, il team della piattaforma di dati potrebbe scegliere di gestire risorse come Dataplex Universal Catalog e i sink Cloud Logging per conto dei team del dominio dei dati. La gestione delle risorse per i team del dominio dei dati consente al team della piattaforma di dati di facilitare la gestione e il controllo centralizzati delle norme in tutta l'organizzazione.
Le sezioni seguenti mostrano come utilizzare Dataplex Universal Catalog per la gestione e la governance centralizzate all'interno di un mesh di dati su Google Cloude l'implementazione delle funzionalità di osservabilità dei dati in un mesh di dati.
Dataplex Universal Catalog per la governance dei dati
Dataplex Universal Catalog fornisce una piattaforma di gestione dei dati che ti aiuta a creare domini di dati indipendenti all'interno di un mesh di dati che si estende all'intera organizzazione. Dataplex Universal Catalog consente di mantenere controlli centrali per la governance e il monitoraggio dei dati nei vari domini.
Con Dataplex Universal Catalog, un'organizzazione può organizzare logicamente i propri dati (origini dati supportate) e gli artefatti correlati, come codice, blocchi note e log, in un lake Dataplex Universal Catalog che rappresenta un dominio di dati. Nel seguente diagramma, un dominio di vendita utilizza Dataplex Universal Catalog per organizzare i propri asset, tra cui log e metriche di qualità dei dati, in zone Dataplex Universal Catalog.
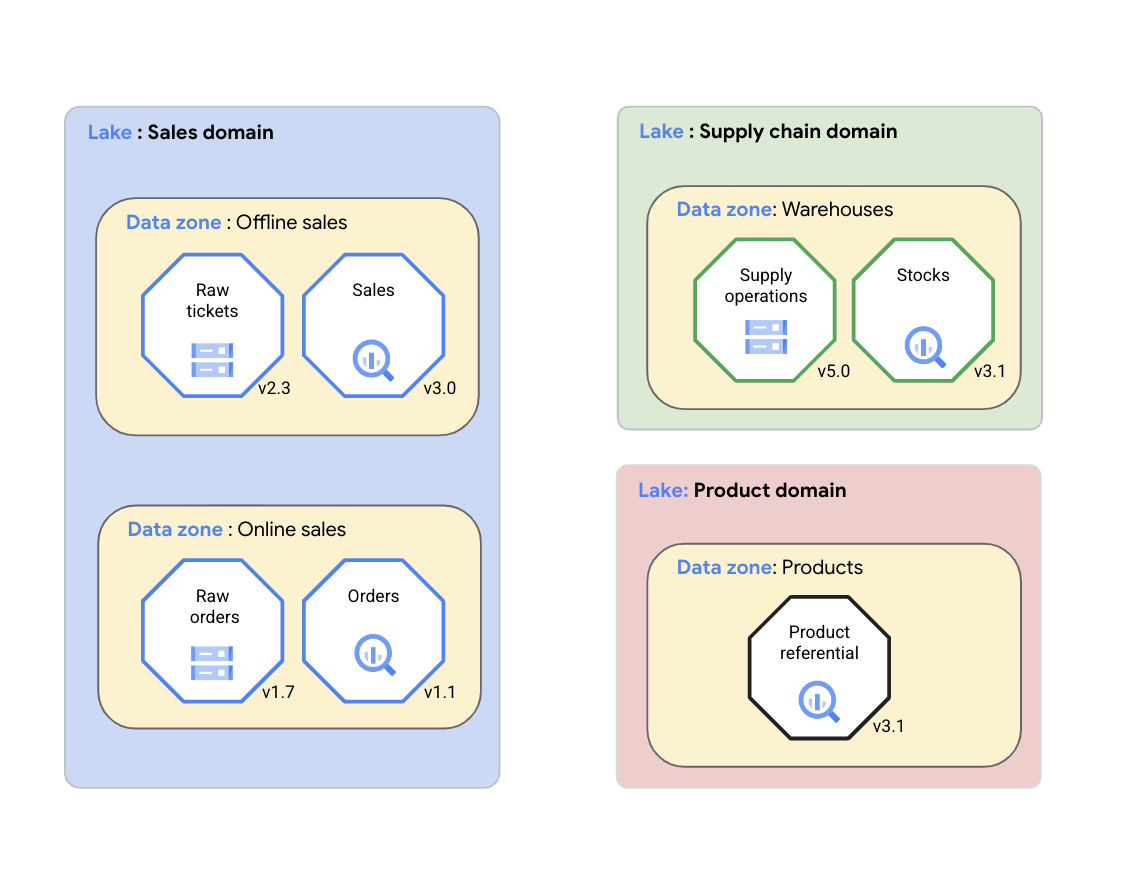
Come mostrato nel diagramma precedente, Dataplex Universal Catalog può essere utilizzato per gestire i dati di dominio nei seguenti asset:
- Dataplex Universal Catalog consente ai team del dominio di dati di gestire in modo coerente i propri asset di dati in un gruppo logico chiamato lake Dataplex Universal Catalog. Il team del dominio dei dati può organizzare gli asset di Dataplex Universal Catalog all'interno dello stesso lake Dataplex Universal Catalog senza spostare fisicamente i dati o archiviarli in un unico sistema di archiviazione. Gli asset Dataplex Universal Catalog possono fare riferimento a bucket Cloud Storage e set di dati BigQuery archiviati in più progetti Google Cloud diversi dal progettoGoogle Cloud contenente il lake Dataplex Universal Catalog. Gli asset di Dataplex Universal Catalog possono essere strutturati o non strutturati oppure archiviati in un data lake o data warehouse analitico. Nel diagramma sono presenti data lake per il dominio delle vendite, il dominio della supply chain e il dominio dei prodotti.
- Le zone Dataplex Universal Catalog consentono al team del dominio dei dati di organizzare ulteriormente gli asset di dati in sottogruppi più piccoli all'interno dello stesso lake Dataplex Universal Catalog e di aggiungere strutture che acquisiscono gli aspetti chiave del sottogruppo. Ad esempio, le zone di Dataplex Universal Catalog possono essere utilizzate per raggruppare gli asset di dati associati in un prodotto di dati. Il raggruppamento degli asset di dati in una singola zona del Catalogo universale Dataplex consente ai team del dominio dei dati di gestire le norme di accesso e le norme di governance dei dati in modo coerente in tutta la zona come unico prodotto di dati. Nel diagramma sono presenti zone di dati per vendite offline, vendite online, magazzini della supply chain e prodotti.
I lake e le zone di Dataplex Universal Catalog consentono a un'organizzazione di unificare i dati distribuiti e organizzarli in base al contesto aziendale. Questa disposizione costituisce la base per attività come la gestione dei metadati, la configurazione dei criteri di governance e il monitoraggio della qualità dei dati. Queste attività consentono all'organizzazione di gestire i propri dati distribuiti su larga scala, ad esempio in un data mesh.
Osservabilità dei dati
Ogni dominio di dati deve implementare i propri meccanismi di monitoraggio e avviso, idealmente utilizzando un approccio standardizzato. Ogni dominio può applicare le pratiche di monitoraggio descritte in Concetti relativi al monitoraggio dei servizi, apportando le modifiche necessarie ai domini di dati. L'osservabilità è un argomento ampio e non rientra nell'ambito di questo documento. Questa sezione tratta solo i pattern utili nelle implementazioni di data mesh.
Per i prodotti con più consumatori di dati, fornire informazioni tempestive a ciascun consumatore sullo stato del prodotto può diventare un onere operativo. Le soluzioni di base, come le distribuzioni di email gestite manualmente, sono in genere soggette a errori. Possono essere utili per informare i consumatori di interruzioni pianificate, lanci di prodotti imminenti e ritiri, ma non forniscono consapevolezza operativa in tempo reale.
I servizi centrali possono svolgere un ruolo importante nel monitoraggio dell'integrità e della qualità dei prodotti nel data mesh. Sebbene non sia un prerequisito per l'implementazione riuscita di un data mesh, l'implementazione di funzionalità di osservabilità può migliorare la soddisfazione dei produttori e dei consumatori di dati e ridurre i costi operativi e di assistenza complessivi. Il seguente diagramma mostra un'architettura di osservabilità del mesh di dati basata su Cloud Monitoring.

Le sezioni seguenti descrivono i componenti mostrati nel diagramma, che sono i seguenti:
- Controlli dell'uptime per mostrare lo stato generale dei prodotti di dati.
- Metriche personalizzate per fornire indicatori utili sui prodotti di dati.
- Supporto operativo del team della piattaforma dati centrale per avvisare i consumatori di dati delle modifiche ai prodotti di dati che utilizzano.
- Schede di valutazione dei prodotti e dashboard per mostrare il rendimento dei prodotti di dati.
Controlli di uptime
I prodotti di dati possono creare semplici applicazioni personalizzate che implementano controlli di uptime. Questi controlli possono fungere da indicatori di alto livello dello stato generale del prodotto. Ad esempio, se il team del prodotto di dati rileva un calo improvviso della qualità dei dati del prodotto, può contrassegnarlo come non integro. I controlli dell'uptime quasi in tempo reale sono particolarmente importanti per i consumatori di dati che hanno derivato prodotti che si basano sulla costante disponibilità dei dati nel prodotto di dati upstream. I produttori di dati devono creare i controlli dell'uptime in modo da includere il controllo delle dipendenze upstream, fornendo così un quadro accurato dello stato del loro prodotto ai consumatori di dati.
I consumatori di dati possono includere i controlli dell'uptime del prodotto nel loro trattamento. Ad esempio, un job di composizione che genera un report basato sui dati forniti da un prodotto di dati può, come primo passaggio, verificare se il prodotto è nello stato "In esecuzione". Ti consigliamo di fare in modo che l'applicazione di controllo dell'uptime restituisca un payload strutturato nel corpo del messaggio della risposta HTTP. Questo payload strutturato deve indicare se si è verificato un problema, la causa principale del problema in formato leggibile e, se possibile, il tempo stimato per il ripristino del servizio. Questo payload strutturato può anche fornire informazioni più dettagliate sullo stato del prodotto. Ad esempio, può contenere le informazioni sanitarie per ciascuna delle visualizzazioni nel set di dati autorizzato esposto come prodotto.
Metriche personalizzate
I prodotti di dati possono avere varie metriche personalizzate per misurarne l'utilità. I team di produzione dei dati possono pubblicare queste metriche personalizzate nei progetti specifici per il dominio Google Cloud designati. Per creare un'esperienza di monitoraggio unificata in tutti i prodotti di dati, è possibile concedere l'accesso a questi progetti specifici del dominio a un progetto di monitoraggio del mesh di dati centrale.
Ogni tipo di interfaccia di consumo dei prodotti di dati ha metriche diverse per misurarne l'utilità. Le metriche possono anche essere specifiche del dominio aziendale. Ad esempio, le metriche per le tabelle BigQuery esposte tramite viste o tramite l'API Storage Read possono essere le seguenti:
- Il numero di righe.
- Aggiornamento dati (espresso come numero di secondi prima dell'ora di misurazione).
- Il punteggio di qualità dei dati.
- I dati disponibili. Questa metrica può indicare che i dati sono disponibili per le query. Un'alternativa è utilizzare i controlli di uptime menzionati in precedenza in questo documento.
Queste metriche possono essere visualizzate come indicatori del livello del servizio (SLI) per un determinato prodotto.
Per i flussi di dati (implementati come argomenti Pub/Sub), questo elenco può contenere le metriche Pub/Sub standard, disponibili tramite gli argomenti.
Assistenza operativa del team della piattaforma dati centrale
Il team della piattaforma dati centrale può mostrare dashboard personalizzate per visualizzare diversi livelli di dettaglio per i consumatori di dati. Un semplice dashboard di stato che elenca i prodotti nel data mesh e lo stato di uptime di questi prodotti può contribuire a rispondere a più richieste degli utenti finali.
Il team centrale può anche fungere da hub di distribuzione delle notifiche per informare i consumatori di dati su vari eventi nei prodotti di dati che utilizzano. In genere, questo hub viene creato tramite policy di avviso. La centralizzazione di questa funzione può ridurre il lavoro che deve essere svolto da ogni team di produttori di dati. La creazione di queste norme non richiede la conoscenza dei domini di dati e dovrebbe contribuire a evitare colli di bottiglia nel consumo di dati.
Lo stato finale ideale per il monitoraggio del data mesh è che il modello di tag del prodotto di dati esponga gli SLI e gli obiettivi del livello di servizio (SLO) supportati dal prodotto quando diventa disponibile. Il team centrale può quindi eseguire automaticamente il deployment degli avvisi corrispondenti utilizzando il monitoraggio dei servizi con l'API Monitoring.
Prospetti prodotto
Nell'ambito dell'accordo di governance centrale, le quattro funzioni di un data mesh possono definire i criteri per creare prospetti per i prodotti di dati. Questi prospetti possono diventare una misurazione oggettiva del rendimento dei prodotti di dati.
Molte delle variabili utilizzate per calcolare i prospetti sono la percentuale di tempo in cui i prodotti di dati soddisfano il loro SLO. Criteri utili possono essere la percentuale di uptime, i punteggi medi di qualità dei dati e la percentuale di prodotti con aggiornamento dei dati che non scende al di sotto di una soglia. Per calcolare automaticamente queste metriche utilizzando il linguaggio di query Prometheus (PromQL), le metriche personalizzate e i risultati dei controlli di uptime del progetto di monitoraggio centrale dovrebbero essere sufficienti.
Passaggi successivi
- Scopri di più su BigQuery.
- Scopri di più su Dataplex.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.