Como se describe en Planes de ejecución de consultas, el compilador de SQL transforma una instrucción de SQL en un plan de ejecución de consultas, que se usa para obtener los resultados de la consulta. En esta página, se describen las prácticas recomendadas para construir instrucciones de SQL que ayuden a Spanner a encontrar planes de ejecución eficientes.
En las instrucciones de SQL de ejemplo que se muestran en esta página, se usa el siguiente esquema de muestra:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para obtener la referencia completa de SQL, consulta Expresiones, funciones y operadores, Estructura léxica y sintaxis y la página sobre la sintaxis de instrucción.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para obtener más información, consulta El lenguaje de PostgreSQL en Spanner.
Usa parámetros de consulta
Spanner admite parámetros de consulta para aumentar el rendimiento y ayudar a evitar la inyección de SQL cuando las consultas se construyen con entradas del usuario. Puedes usar los parámetros de consulta como sustitutos de expresiones arbitrarias, pero no como sustitutos de identificadores, nombres de columnas, nombres de tablas ni otras partes de la consulta.
Los parámetros pueden aparecer en cualquier lugar donde se espere un valor literal. El mismo nombre de parámetro se puede usar más de una vez en una sola instrucción de SQL.
En resumen, los parámetros de consulta admiten la ejecución de consultas de las siguientes maneras:
- Planes optimizados con anterioridad: las consultas que usan parámetros se pueden ejecutar más rápido en cada invocación porque la parametrización facilita que Spanner almacene en caché el plan de ejecución.
- Composición simplificada de la consulta: No es necesario el escape de valores de cadena cuando se proporcionen en los parámetros de consulta. Los parámetros de consulta también reducen el riesgo de errores de sintaxis.
- Seguridad: Los parámetros de consulta hacen que tus consultas sean más seguras, ya que te protegen de varios ataques por inyección de SQL. Esta protección es importante en particular para las consultas que creas a partir de las entradas del usuario.
Comprende cómo Spanner ejecuta consultas
Spanner te permite consultar bases de datos mediante instrucciones de SQL declarativas que especifican los datos que deseas recuperar. Si quieres comprender cómo Spanner obtiene los resultados, examina el plan de ejecución de la consulta. Un plan de ejecución de consultas muestra el costo informático asociado a cada paso de la consulta. Con esos costos, puedes depurar los problemas de rendimiento de las consultas y optimizar tu consulta. Para obtener más información, consulta Planes de ejecución de consultas.
Puedes recuperar planes de ejecución de consultas a través de la Google Cloud consola o de las bibliotecas cliente.
Para obtener un plan de ejecución de consultas para una consulta específica con la consola de Google Cloud , sigue estos pasos:
Abre la página Instancias de Spanner.
Selecciona los nombres de la instancia de Spanner y la base de datos que deseas consultar.
Haz clic en Spanner Studio en el panel de navegación izquierdo.
Escribe la consulta en el campo de texto y, luego, haz clic en Ejecutar consulta.
Haz clic en Explicación
. La Google Cloud consola muestra un plan de ejecución visual para tu consulta.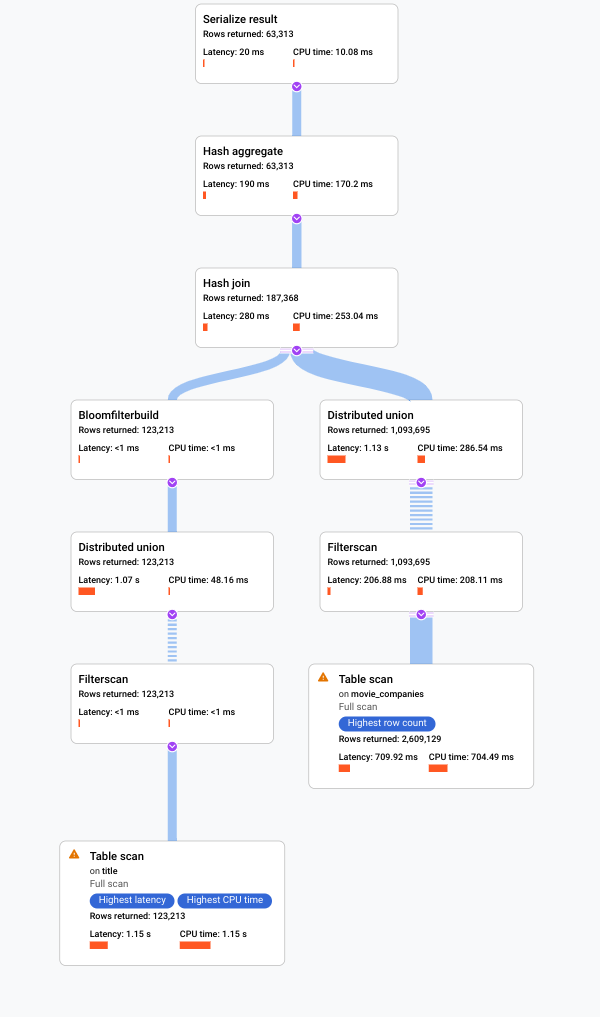
Para obtener más información sobre cómo comprender los planes visuales y usarlos para depurar tus consultas, consulta Cómo ajustar una consulta con el visualizador del plan de consultas.
También puedes ver muestras de planes de consulta históricos y comparar el rendimiento de una consulta a lo largo del tiempo para ciertas consultas. Para obtener más información, consulta Planes de consulta muestreados.
Usa índices secundarios
Al igual que otras bases de datos relacionales, Spanner ofrece índices secundarios, que puedes usar para recuperar datos mediante una instrucción de SQL o la interfaz de lectura de Spanner. La forma más común de recuperar datos de un índice es usar Spanner Studio. Usar un índice secundario en una consulta de SQL te permite especificar cómo deseas que Spanner obtenga los resultados. Especificar un índice secundario puede acelerar la ejecución de consultas.
Por ejemplo, supongamos que quieres recuperar los IDs de todos los cantantes con un apellido específico. Se puede escribir una consulta de SQL de este tipo de la siguiente forma:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Esta consulta mostrará los resultados que esperas, pero podría tardar mucho tiempo en hacerlo. El tiempo dependerá de la cantidad de filas de la tabla Singers y de cuántas satisfagan el predicado WHERE s.LastName = 'Smith'. Si no hay ningún índice secundario que contenga la columna LastName desde la cual leer, el plan de consulta leerá toda la tabla Singers para encontrar filas que coincidan con el predicado. Leer toda la tabla se denomina análisis completo de la tabla. Un análisis completo de la tabla es una forma costosa de obtener los resultados cuando la tabla solo contiene un pequeño porcentaje de Singers con ese apellido.
Para mejorar el rendimiento de esta consulta, define un índice secundario en la columna de apellido:
CREATE INDEX SingersByLastName ON Singers (LastName);
Dado que el índice secundario SingersByLastName contiene la columna de tabla indexada LastName y la columna de clave primaria SingerId, Spanner puede recuperar todos los datos de la tabla de índice mucho más pequeña en lugar de analizar la tabla Singers completa.
En este caso, Spanner usa automáticamente el índice secundario SingersByLastName cuando ejecuta la consulta (siempre que hayan pasado tres días desde la creación de la base de datos; consulta Nota sobre las bases de datos nuevas). Sin embargo, es mejor establecer de forma explícita que Spanner use ese índice mediante la especificación de una directiva de índice en la cláusula FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Supongamos que también deseas recuperar el nombre del cantante, además del ID. Aunque la columna FirstName no está incluida en el índice, aún debes especificar la directiva de índice como antes:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
También obtienes un beneficio en el rendimiento por usar el índice, ya que Spanner no necesita realizar un análisis completo de la tabla cuando ejecuta el plan de consultas. En su lugar, selecciona el subconjunto de filas que satisfacen el predicado del índice SingersByLastName y, luego, realiza una búsqueda desde la tabla base Singers para recuperar el nombre solo en ese subconjunto de filas.
Si deseas que Spanner no tenga que recuperar filas de la tabla base, puedes almacenar una copia de la columna FirstName en el índice:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
Usar una cláusula STORING (para el dialecto GoogleSQL) o una cláusula INCLUDE (para el dialecto PostgreSQL) como esta tiene un costo adicional de almacenamiento, pero proporciona las siguientes ventajas:
- Las consultas de SQL que usan el índice y seleccionan las columnas almacenadas en la cláusula
STORINGoINCLUDEno requieren una unión adicional para la tabla base. - Las llamadas de operación de lectura que usan el índice pueden leer las columnas almacenadas en la cláusula
STORINGoINCLUDE.
En los ejemplos anteriores, se ilustra cómo los índices secundarios pueden acelerar las consultas cuando las filas que eligió la cláusula WHERE de una consulta se pueden identificar con rapidez mediante el índice secundario.
Otra situación en la que los índices secundarios pueden ofrecer beneficios de rendimiento es para determinadas consultas que muestran resultados ordenados. Por ejemplo, supongamos que quieres recuperar todos los títulos de los álbumes y sus fechas de lanzamiento en orden ascendente según la fecha de lanzamiento y en orden descendente según el título del álbum. Puedes escribir una consulta SQL de la siguiente manera:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Sin un índice secundario, esta consulta requiere un paso de clasificación potencialmente costoso en el plan de ejecución. Para acelerar la ejecución de consultas, define este índice secundario:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Luego, vuelve a escribir la consulta para usar el índice secundario:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Esta definición de índice y consulta cumple con los siguientes criterios:
- Para quitar el paso de ordenamiento, asegúrate de que la lista de columnas en la cláusula
ORDER BYsea un prefijo de la lista de claves del índice. - Para evitar volver a unirte desde la tabla base para recuperar las columnas faltantes, asegúrate de que el índice abarque todas las columnas de la tabla que usa la consulta.
Aunque los índices secundarios pueden acelerar las consultas comunes, agregar índices secundarios puede agregar latencia a tus operaciones de confirmación, ya que cada índice secundario suele requerir el involucramiento de un nodo adicional en cada confirmación. Para la mayoría de las cargas de trabajo, está bien tener unos pocos índices secundarios. Sin embargo, debes considerar si tienes que preocuparte más por la latencia de lectura o escritura y qué operaciones son más importantes para tu carga de trabajo. Compara tu carga de trabajo para asegurarte de que su rendimiento sea el esperado.
Para obtener la referencia completa de los índices secundarios, consulta la página sobre los índices secundarios.
Optimiza las búsquedas
Algunas consultas de Spanner podrían beneficiarse del uso de un método de procesamiento orientado a lotes cuando se analizan datos en lugar del método de procesamiento orientado a filas más común. Procesar análisis por lotes es una forma más eficiente de procesar grandes volúmenes de datos a la vez y permite que las consultas tengan una latencia y un uso de CPU más bajos.
La operación de análisis de Spanner siempre inicia la ejecución en el método orientado a filas. Durante este tiempo, Spanner recopila varias métricas del tiempo de ejecución. Luego, Spanner aplica un conjunto de heurísticas según el resultado de estas métricas para determinar el método de análisis óptimo. Cuando sea apropiado, Spanner cambiará a un método de procesamiento orientado a lotes para mejorar el rendimiento y la capacidad de procesamiento de análisis.
Casos de uso habituales
Las consultas con las siguientes características suelen beneficiarse del uso del procesamiento orientado a lotes:
- Escaneos grandes de datos que no se actualizan con frecuencia
- Realiza análisis con predicados en columnas de ancho fijo.
- Análisis con grandes recuentos de búsqueda (un salto usa un índice para recuperar registros).
Casos de uso sin mejoras de rendimiento
No todas las consultas se benefician del procesamiento por lotes. Los siguientes tipos de consulta tienen un mejor rendimiento con el procesamiento de análisis orientado a filas:
- Búsqueda de puntos: Son consultas que solo recuperan una fila.
- Consultas de análisis pequeñas: análisis de tablas que solo analizan algunas filas, a menos que tengan recuentos de búsqueda grandes.
- Consultas que usan
LIMIT - Consultas que leen datos de deserción alta: Consultas en las que más del 10% de los datos leídos se actualizan con frecuencia.
- Búsquedas con filas que contienen valores grandes: Las filas de valores grandes son aquellas que contienen valores superiores a 32,000 bytes (antes de la compresión) en una sola columna.
Cómo verificar el método de análisis que usa una consulta
Para verificar si tu consulta usa el procesamiento por lotes, el procesamiento orientado a filas o cambia automáticamente entre los dos métodos de análisis, haz lo siguiente:
Ve a la página Instancias de Spanner en la consola deGoogle Cloud .
Haz clic en el nombre de la instancia con la consulta que deseas investigar.
En la tabla Bases de datos, haz clic en la base de datos con la consulta que deseas investigar.
En el menú de navegación, haz clic en Spanner Studio.
Para abrir una pestaña nueva, haz clic en Nueva pestaña del editor de SQL o Nueva pestaña.
Escribe tu consulta cuando aparezca el editor de consultas.
Haz clic en Ejecutar.
Spanner ejecuta la consulta y muestra los resultados.
Haz clic en la pestaña Explanation debajo del editor de consultas.
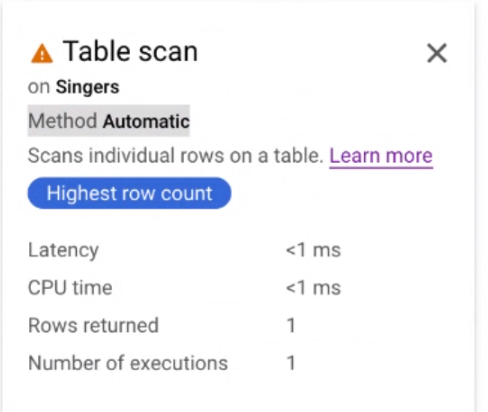
Spanner muestra un visualizador de planes de ejecución de consultas. Cada tarjeta del gráfico representa un iterador.
Haz clic en la tarjeta del iterador Análisis de tablas para abrir un panel de información.
El panel de información muestra información contextual sobre el análisis seleccionado. El método de análisis se muestra en esta tarjeta. Automático indica que Spanner determina el método de análisis. Otros valores posibles son Batch para el procesamiento orientado a lotes y Row para el procesamiento orientado a filas.
Aplica el método de análisis que usa una consulta
Para optimizar el rendimiento de las consultas, Spanner elige el método de análisis óptimo para tu consulta. Te recomendamos que uses este método de análisis predeterminado. Sin embargo, puede haber situaciones en las que desees aplicar un tipo específico de método de análisis.
Aplica el análisis orientado a lotes
Puedes aplicar el análisis orientado a lotes a nivel de la tabla y de la sentencia.
Para aplicar el método de análisis orientado a lotes a nivel de la tabla, usa una sugerencia de tabla en tu consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Para aplicar el método de análisis orientado a lotes a nivel de la sentencia, usa una sugerencia de sentencia en tu consulta:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Inhabilita el análisis automático y aplica el análisis orientado a filas
Aunque no recomendamos inhabilitar el método de análisis automático que establece Spanner, puedes decidir inhabilitarlo y usar el método de análisis orientado a filas para solucionar problemas, como diagnosticar latencia.
Para inhabilitar el método de análisis automático y aplicar el procesamiento de filas a nivel de la tabla, usa una sugerencia de tabla en tu consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Para inhabilitar el método de análisis automático y aplicar el procesamiento de filas a nivel de la instrucción, usa una sugerencia de instrucción en tu consulta:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Optimiza la ejecución de consultas
Además de optimizar las exploraciones, también puedes optimizar la ejecución de consultas aplicando el método de ejecución a nivel de la sentencia. Esto solo funciona para algunos operadores y es independiente del método de búsqueda, que solo usa el operador de búsqueda.
De forma predeterminada, la mayoría de los operadores se ejecutan en el método orientado a filas, que procesa los datos una fila a la vez. Los operadores vectorizados se ejecutan en el método orientado a lotes para ayudar a mejorar el rendimiento y la capacidad de procesamiento de la ejecución. Estos operadores procesan los datos un bloque a la vez. Cuando un operador necesita procesar muchas filas, el método de ejecución orientado a lotes suele ser más eficiente.
Método de ejecución en comparación con el método de análisis
El método de ejecución de consultas es independiente del método de análisis de consultas. Puedes configurar uno, ambos o ninguno de estos métodos en tu sugerencia de consulta.
El método de ejecución de consultas hace referencia a la forma en que los operadores de consulta procesan los resultados intermedios y cómo interactúan entre sí, mientras que el método de análisis hace referencia a la forma en que el operador de análisis interactúa con la capa de almacenamiento de Spanner.
Aplica el método de ejecución que usa la consulta
Para optimizar el rendimiento de las consultas, Spanner elige el método de ejecución óptimo para tu consulta en función de varias heurísticas. Te recomendamos que use este método de ejecución predeterminado. Sin embargo, puede haber situaciones en las que desees aplicar un tipo específico de método de ejecución.
Puedes aplicar de manera forzosa tu método de ejecución a nivel de la sentencia. EXECUTION_METHOD es una sugerencia de consulta en lugar de una directiva. En última instancia, el optimizador de consultas decide qué método usar para cada operador individual.
Para aplicar el método de ejecución orientado a lotes a nivel de la sentencia, usa una sugerencia de sentencia en tu consulta:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Aunque no recomendamos inhabilitar el método de ejecución automática que establece Spanner, puedes decidir inhabilitarlo y usar el método de ejecución orientado a filas para solucionar problemas, como diagnosticar la latencia.
Para inhabilitar el método de ejecución automática y aplicar el método de ejecución orientado a filas a nivel de la sentencia, usa una sugerencia de sentencia en tu consulta:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Verifica qué método de ejecución está habilitado
No todos los operadores de Spanner admiten métodos de ejecución orientados a lotes y a filas. Para cada operador, el visualizador de planes de ejecución de consultas muestra el método de ejecución en la tarjeta del iterador. Si el método de ejecución está orientado a lotes, se muestra Batch. Si está orientado a filas, se muestra Row.
Si los operadores de tu consulta se ejecutan con diferentes métodos de ejecución, los adaptadores de métodos de ejecución DataBlockToRowAdapter y RowToDataBlockAdapter aparecen entre los operadores para mostrar el cambio en el método de ejecución.
Cómo optimizar las búsquedas de claves de rango
Un uso común de una consulta de SQL es leer varias filas de Spanner según una lista de claves conocidas.
Las siguientes prácticas recomendadas te ayudan a escribir consultas eficientes cuando se recuperan datos mediante un rango de claves:
Si la lista de claves es dispersa y no adyacente, usa los parámetros de consulta y
UNNESTpara construir tu consulta.Por ejemplo, si tu lista de claves es
{1, 5, 1000}, escribe la consulta de la manera siguiente:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Notas:
El operador de arreglo UNNEST compacta un arreglo de entrada en filas de elementos.
El parámetro de consulta, que es
@KeyListpara GoogleSQL y$1para PostgreSQL, puede acelerar tu consulta, como se explica en la práctica recomendada anterior.
Si la lista de claves es adyacente y está dentro de un rango, especifica los límites inferior y superior del rango de clave en la cláusula
WHERE.Por ejemplo, si tu lista de claves es
{1,2,3,4,5}, construye la consulta de la siguiente manera:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Esta consulta solo es más eficiente si las claves del rango de claves son adyacentes. En otras palabras, si tu lista de claves es
{1, 5, 1000}, no especifiques los límites inferior y superior como en la consulta anterior porque la consulta resultante analizará todos los valores entre 1 y 1,000.
Optimiza las uniones
Las operaciones de unión pueden ser costosas porque pueden aumentar de forma significativa la cantidad de filas que tu consulta necesita analizar, lo que genera consultas más lentas. Además de las técnicas que sueles usar en otras bases de datos relacionales para optimizar las consultas de unión, estas son algunas prácticas recomendadas para lograr una operación JOIN más eficiente cuando se usa SQL en Spanner:
Si es posible, une los datos de las tablas intercaladas por clave primaria. Por ejemplo:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
Se garantiza que las filas de la tabla intercalada
Albumsse almacenarán de manera física en las mismas divisiones que la fila superior enSingers, como se explica en Esquema y modelo de datos. Por lo tanto, las uniones se pueden completar de forma local sin enviar muchos datos a través de la red.Usa la directiva de unión si quieres forzar el orden de la unión. Por ejemplo:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
La directiva de unión
FORCE_JOIN_ORDERle indica a Spanner que use el orden de unión especificado en la consulta (es decir,Singers JOIN Albums, noAlbums JOIN Singers). Los resultados que se muestran son los mismos, sin importar el orden que elija Spanner. Sin embargo, puedes usar esta directiva de unión si observas en el plan de consulta que Spanner cambió el orden de unión y generó consecuencias no deseadas, como resultados intermedios más grandes, o perdió oportunidades para buscar filas.Usa una directiva de unión para elegir una implementación de unión. Cuando usas SQL para consultar varias tablas, Spanner usa automáticamente un método de unión que puede hacer que la consulta sea más eficiente. Sin embargo, Google te recomienda que realices pruebas con diferentes algoritmos de unión. Elegir el algoritmo de unión correcto puede mejorar la latencia, el consumo de memoria o ambos. En esta consulta, se muestra la sintaxis para usar una directiva JOIN con la sugerencia
JOIN_METHODpara elegir unHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Si usas un
HASH JOINoAPPLY JOINy tienes una cláusulaWHEREque es muy selectiva a un lado de tuJOIN, coloca la tabla que produzca el menor número de filas como la tabla primera en la cláusulaFROMde la unión. Esta estructura ayuda porque, enHASH JOIN, Spanner siempre elige la tabla del lado izquierdo como compilación y la tabla del lado derecho como sondeo. Del mismo modo, paraAPPLY JOIN, Spanner elige la tabla del lado izquierdo como externa y la del lado derecho como interior. Obtén más información sobre estos tipos de uniones: unión de hash y unión de aplicación.Para las consultas que son críticas en tu carga de trabajo, especifica el método de unión más eficaz y el orden de unión en tus instrucciones de SQL para un rendimiento más coherente.
Optimiza las consultas con la baja del predicado de marca de tiempo
La transferencia de predicados de marca de tiempo es una técnica de optimización de consultas que se usa en Spanner para mejorar la eficiencia de las consultas que usan marcas de tiempo y datos con una política de almacenamiento en niveles basada en la antigüedad. Cuando habilitas esta optimización, las operaciones de filtrado en las columnas de marca de tiempo se realizan lo antes posible en el plan de ejecución de consultas. Esto puede reducir de forma significativa la cantidad de datos que se procesan y mejora el rendimiento general de las consultas.
Con la eliminación de predicados de marca de tiempo, el motor de la base de datos analiza la consulta y identifica el filtro de marca de tiempo. Luego, “empujará” este filtro a la capa de almacenamiento, de modo que solo se lean de la SSD los datos relevantes según los criterios de la marca de tiempo. Esto minimiza la cantidad de datos que se procesan y se transfieren, lo que genera una ejecución de consultas más rápida.
Para optimizar las consultas de modo que solo accedan a los datos almacenados en la SSD, se debe cumplir lo siguiente:
- La consulta debe tener habilitado el descenso del predicado de marca de tiempo. Para obtener más información, consulta Sugerencias de sentencias de GoogleSQL y Sugerencias de sentencias de PostgreSQL.
- La consulta debe usar una restricción basada en la antigüedad igual o inferior a la especificada en la política de volcado de datos (configurada con la opción
ssd_to_hdd_spill_timespanen la sentencia DDLCREATE LOCALITY GROUPoALTER LOCALITY GROUP). Para obtener más información, consulta las sentenciasLOCALITY GROUPde GoogleSQL y las sentenciasLOCALITY GROUPde PostgreSQL. La columna que se filtra en la consulta debe ser una columna de marca de tiempo que contenga la marca de tiempo de confirmación. Para obtener detalles sobre cómo crear una columna de marca de tiempo de confirmación, consulta Marcas de tiempo de confirmación en GoogleSQL y Marcas de tiempo de confirmación en PostgreSQL. Estas columnas deben actualizarse junto con la columna de marca de tiempo y residir en el mismo grupo de localidad, que tiene una política de almacenamiento en niveles basada en la antigüedad.
Si, para una fila determinada, algunas de las columnas que se consultan residen en SSD y otras en HDD (debido a que las columnas se actualizan en diferentes momentos y se transfieren al HDD en diferentes momentos), el rendimiento de la consulta podría ser peor cuando usas la sugerencia. Esto se debe a que la consulta debe completar los datos de las diferentes capas de almacenamiento. Como resultado del uso de la sugerencia, Spanner envejece los datos a nivel de la celda individual (nivel de granularidad de fila y columna) según la marca de tiempo de confirmación de cada celda, lo que ralentiza la consulta. Para evitar este problema, asegúrate de actualizar de forma periódica todas las columnas que se consultan con esta técnica de optimización en la misma transacción, de modo que todas las columnas compartan la misma marca de tiempo de confirmación y se beneficien de la optimización.
Para habilitar la transferencia de predicados de marca de tiempo a nivel de la sentencia, usa una sugerencia de sentencia en tu consulta. Por ejemplo:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Evita lecturas extensas en las transacciones de lectura y escritura
Las transacciones de lectura y escritura permiten una secuencia de cero o más lecturas o consultas de SQL y pueden incluir un conjunto de mutaciones antes de una llamada para confirmar. Para mantener la coherencia de tus datos, Spanner adquiere bloqueos cuando lee y escribe filas en tus tablas y en los índices. Para obtener más información sobre el bloqueo, consulta Ciclo de vida de las operaciones de lectura y escritura.
Debido a la forma en la que funciona el bloqueo en Spanner, realizar una consulta de lectura o de SQL que lea una gran cantidad de filas (por ejemplo, SELECT * FROM Singers) significa que ninguna otra transacción puede escribir en las filas leídas hasta que tu transacción se confirme o se anule.
Además, debido a que tu transacción procesa una gran cantidad de filas, es probable que demore más que una transacción que lee un rango de filas mucho más pequeño (por ejemplo, SELECT LastName FROM Singers WHERE SingerId = 7), lo que agrava el problema y reduce la capacidad de procesamiento del sistema.
Por lo tanto, intenta evitar las operaciones de lectura grandes (por ejemplo, los análisis completos de tablas o las operaciones de unión masivas) en tus transacciones, a menos que estés dispuesto a aceptar una capacidad de procesamiento de escritura menor.
En algunos casos, el siguiente patrón puede producir mejores resultados:
- Haz tus lecturas grandes dentro de una transacción de solo lectura. Las transacciones de solo lectura permiten una mayor capacidad de procesamiento de agregación porque no usan bloqueos.
- Opcional: Realiza cualquier procesamiento necesario en los datos que acabas de leer.
- Inicia una transacción de lectura y escritura.
- Verifica que los valores de las filas críticas no hayan cambiado desde que realizaste la transacción de solo lectura en el paso 1.
- Si las filas cambiaron, revierte la transacción y comienza de nuevo en el paso 1.
- Si todo sale bien, confirma tus mutaciones.
Una forma de evitar las lecturas grandes en las transacciones de lectura y escritura es observar los planes de ejecución que generan tus consultas.
Usa la cláusula ORDER BY para garantizar el orden de tus resultados de SQL
Si deseas obtener un orden determinado para los resultados de una consulta SELECT, debes incluir la cláusula ORDER BY de forma explícita. Por ejemplo, si quieres crear una lista de todos los cantantes en el orden de la clave primaria, usa esta consulta:
SELECT * FROM Singers
ORDER BY SingerId;
Spanner garantiza el orden de los resultados solo si la cláusula ORDER BY está presente en la consulta. En otras palabras, considera esta consulta sin ORDER
BY:
SELECT * FROM Singers;
Spanner no garantiza que los resultados de esta consulta estén en el orden de la clave primaria. Además, el orden de los resultados puede cambiar en cualquier momento y no se garantiza que sea coherente de una invocación a otra. Si una consulta tiene una cláusula ORDER BY y Spanner usa un índice que proporciona el orden requerido, Spanner no ordena los datos de forma explícita. Por lo tanto, no te preocupes por el impacto en el rendimiento de incluir esta cláusula. Puedes verificar si se incluye una operación de ordenamiento explícita en la
ejecución mirando el plan de consulta.
Usa STARTS_WITH en lugar de LIKE
Dado que Spanner no evalúa los patrones LIKE con parámetros hasta el momento de la ejecución, Spanner debe leer todas las filas y evaluarlas con la expresión LIKE para filtrar las filas que no coinciden.
Cuando un patrón LIKE tiene la forma foo% (por ejemplo, comienza con una cadena fija y termina con un solo comodín porcentual) y la columna está indexada, usa STARTS_WITH en lugar de LIKE. Esta opción permite que Spanner optimice de manera más eficiente el plan de ejecución de consultas.
No se recomienda lo siguiente:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Se recomienda lo siguiente:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Usa marcas de tiempo de confirmación
Si tu aplicación necesita consultar datos escritos después de una hora en particular,
agrega columnas de marca de tiempo de confirmación a las tablas relevantes. Las marcas de tiempo de confirmación habilitan una optimización de Spanner que puede reducir la E/S de las consultas cuyas cláusulas WHERE restringen los resultados a filas escritas más recientemente que un momento específico.
Obtén más información sobre esta optimización con bases de datos de dialecto de Google SQL o con bases de datos de dialecto de PostgreSQL.