このドキュメントでは、システム分析情報ダッシュボードを使用して Spanner インスタンスとデータベースをモニタリングする方法について説明します。
システム分析情報について
システム分析情報ダッシュボードには、選択したインスタンスまたはデータベースに関するスコアカードとグラフが表示され、レイテンシ、CPU 使用率、ストレージ、スループットなどのパフォーマンス統計情報が示されます。選択可能な期間のグラフを表示できます。表示期間は過去 1 時間から過去 30 日までの間で設定できます。
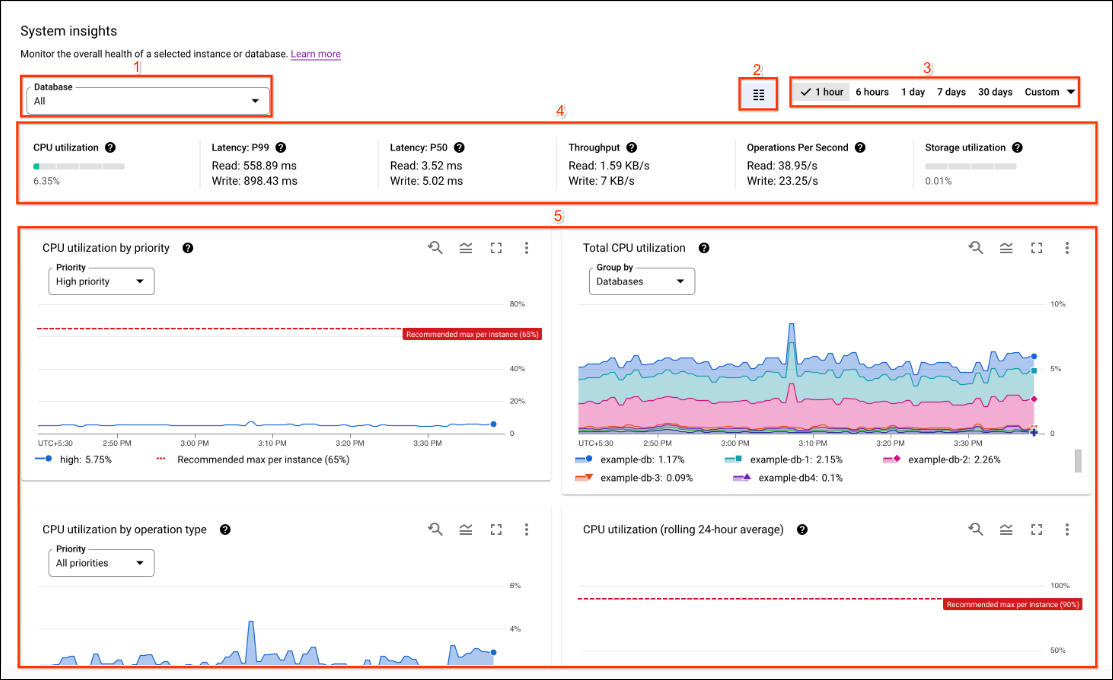
システム分析情報ダッシュボードには、次のセクションがあります。番号は次の UI のスクリーンショットに対応しています。
- 分析情報のセレクタ: ダッシュボードにデータを入力するデータベース、インスタンス パーティション、リージョンを選択します。インスタンスに複数のインスタンス パーティションまたはリージョンがある場合、システム分析情報にはインスタンス パーティションとリージョン選択が表示されます。
- 期間フィルタ: 時間数、日数、カスタム範囲など、期間で統計情報をフィルタします。
- ダッシュボード選択ツール: ユーザーがカスタマイズしたビューを選択するか、システム分析情報をデフォルトの事前定義ビューにリセットします。
- アノテーション: グラフにアノテーションを付ける分析情報アラートのイベントタイプを選択します。
- ダッシュボードをカスタマイズ: ダッシュボード ウィジェットとシステム分析情報ダッシュボードの外観、配置、コンテンツをカスタマイズします。このドキュメントでは、事前定義されたダッシュボードのプレゼンテーションについて説明します。
- スコアカード: 選択した期間の特定の時点における統計情報が表示されます。
- グラフ: CPU 使用率、スループット、レイテンシ、ストレージ使用状況などのグラフが表示されます。アノテーションで設定された分析情報アラートは、ベルのアイコンとともにグラフに表示されます。
必要なロール
分析情報ダッシュボード(カスタム ダッシュボードを含む)の表示または変更に必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するよう管理者に依頼してください。
-
カスタム ダッシュボードを作成して編集する: モニタリング ダッシュボード構成の編集者(
roles/monitoring.dashboardEditor) -
Metrics Explorer のグラフを開いて表示するには:
モニタリング ダッシュボード構成の閲覧者(
roles/monitoring.dashboardViewer) -
Metrics Explorer アラートを作成して編集するには:
モニタリング編集者(
roles/monitoring.editor)
ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
これらの事前定義ロールには、カスタム ダッシュボードを含む分析情報ダッシュボードの表示または変更に必要な権限が含まれています。必要とされる正確な権限については、必要な権限セクションを開いてご確認ください。
必要な権限
カスタム ダッシュボードを含む分析情報ダッシュボードを表示または変更するには、次の権限が必要です。
-
カスタム ダッシュボードを作成するには:
monitoring.dashboards.create -
カスタム ダッシュボードを編集するには:
monitoring.dashboards.update -
カスタム ダッシュボードを表示するには:
monitoring.dashboards.get, monitoring.dashboards.list
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
システム分析情報ダッシュボードをカスタマイズする
システム分析情報ダッシュボードは、自分にとって最も重要な情報を表示するようにカスタマイズできる事前定義のダッシュボードです。新しいグラフを追加すること、レイアウトを変更すること、データをフィルタして特定のリソースに焦点を当てることが可能です。
システム分析情報ダッシュボードの変更は破壊的ではなく、ダッシュボード セレクタを [事前定義] に設定することでリセットできます。
ダッシュボードを変更する
ダッシュボードを変更するには、 [ダッシュボードをカスタマイズ] をクリックします。以下のオプションをご利用いただけます。
- ウィジェットを追加する: ダッシュボードのツールバーで (ウィジェットを追加)をクリックし、追加するウィジェットを選択して構成します。
- ウィジェットを編集する: ウィジェットにカーソルを合わせてツールバーを表示し、(ウィジェットを編集)をクリックします。ウィジェットのタイプを変更すること、表示するデータをカスタマイズすることが可能です。
- ウィジェットを複製する: ウィジェットにカーソルを合わせてツールバーを表示し、(その他のグラフ オプション)、[ウィジェットを複製] の順にクリックします。
- ウィジェットを削除する: ウィジェットにカーソルを合わせてツールバーを表示し、(その他のグラフ オプション)、[ウィジェットを削除] の順にクリックします。
- レイアウトを変更する: ウィジェットをドラッグして位置を変更すること、角をドラッグしてサイズを変更することが可能です。
- カスタムビューに名前を付ける: カスタムビューの名前は [カスタムビュー名] ボックスで設定できます。
- ダッシュボードを保存する: [保存] をクリックすると、カスタムビューを保存できます。[編集モードを終了] をクリックして、保存せずに終了することもできます。
システム分析情報のスコアカード、グラフ、指標
システム分析情報ダッシュボードで次のグラフと指標を使用して、インスタンスの現在と過去のステータスを確認できます。ほとんどのグラフと指標はインスタンス レベルで使用できます。インスタンスの特定のデータベースに対して複数のグラフと指標を表示することもできます。
使用可能なスコアカード
| 名前 | 説明 |
|---|---|
| CPU 使用率 | インスタンス内または選択したデータベース内での合計 CPU 使用率。デュアルリージョン インスタンスまたはマルチリージョン インスタンスの場合、この指標は複数のリージョンにおける CPU 使用率の平均を表します。 |
| レイテンシ(p99) | インスタンス内または選択したデータベース内の読み取り / 書き込みオペレーションの P99 レイテンシ(99 パーセンタイル)。これらのオペレーションの 99% が完了するまでの時間を表します。 |
| レイテンシ(p50) | インスタンス内または選択したデータベース内の読み取り / 書き込みオペレーションの P50 レイテンシ(50 パーセンタイル)。これらのオペレーションの 50% が完了するまでの時間を表します。 |
| スループット | インスタンスまたはデータベースで 1 秒間に発生した読み取りまたは書き込みで処理された非圧縮データ量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 |
| 1 秒あたりのオペレーションの回数 | インスタンス内または選択したデータベース内の読み取りと書き込みの 1 秒あたりのオペレーション数(レート)。 |
| ストレージの利用率 | インスタンス レベルでは、インスタンス内のストレージ合計使用率が表示されます。データベース レベルでは、選択したデータベースに使用されているストレージの合計です。 |
使用可能なグラフと指標
オペレーション タイプ別の CPU 使用率というサンプル指標のグラフは次のとおりです。
各グラフのツールバーには、次の標準オプションがあります。グラフの上にポインタを置かないと、一部の要素が非表示になります。
グラフの特定のセクションにズームインするには、表示するセクションにポインタをドラッグします。このアクションでは、期間を自由に設定できます。期間フィルタを使用して調整または元に戻すことができます。
グラフとそのデータの説明を表示するには、help をクリックします。
グラフに適用されているフィルタとグループを表示するには、info をクリックします。
グラフのデータに基づいてアラートを作成するには、add_alert をクリックします。
グラフ内のデータを調べるには、query_stats をクリックします。
その他のグラフのオプションを表示するには、more_vert [その他のグラフ オプション] をクリックします。
グラフを全画面モードで表示するには、[全画面で表示] をクリックします。全画面表示を終了するには、[キャンセル] をクリックするか、Esc キーを押します。
グラフの凡例を開閉するには、[グラフの凡例を開く / 閉じる] をクリックします。
グラフをダウンロードするには、[ダウンロード] をクリックし、ダウンロード形式を選択します。
グラフの表示形式を変更するには、[モード] をクリックして表示モードを選択します。
Metrics Explorer で指標を表示するには、[Metrics Explorer で表示] をクリックします。Spanner Database リソースタイプを選択すると、Metrics Explorer で他の Spanner 指標を確認できます。
次の表は、システム分析情報ダッシュボードにデフォルトで表示されるグラフを示しています。各グラフの指標タイプが表示されます。指標タイプの文字列は、接頭辞 spanner.googleapis.com/ の後ろに続きます。指標タイプは、モニタリング対象リソースから収集できる測定値を表します。
| グラフ名と指標タイプ |
説明 | インスタンスで利用可能 | データベースで使用可能 |
|---|---|---|---|
|
デュアルリージョン クォーラムの健全性のタイムライン instance/dual_region_quorum_availability |
このグラフは、デュアルリージョン インスタンス構成でのみ表示されます。3 つのクォーラムの健全性(デュアルリージョン クォーラム( Global)と各リージョンのシングルリージョン クォーラム(Sydney や Melbourne など))が表示されます。サービスが中断されると、タイムラインにオレンジ色のバーが表示されます。バーにカーソルを合わせると、中断の開始時間と終了時間が表示されます。このグラフをエラー率とレイテンシ指標とともに使用すると、リージョン障害が発生した場合にセルフマネージド フェイルオーバーのタイミングを決定することに役立ちます。詳細については、フェイルオーバーとフェイルバックをご覧ください。 手動でフェイルオーバーとフェイルバックを行うには、デュアルリージョン クォーラムを変更するをご覧ください。 |
done |
done |
CPU 使用率(優先度別) instance/cpu/utilization_by_priority |
優先度別の高、中、低、すべてのタスクに対するインスタンスの CPU リソースの割合。これらのタスクには、ユーザーが開始するリクエストと、Spanner が直ちに完了する必要があるメンテナンス タスクが含まれます。 デュアルリージョン インスタンスまたはマルチリージョン インスタンスの場合、指標はリージョンと優先度でグループ化されます。 優先度の高いタスクの詳細をご覧ください。 CPU 使用率の詳細をご覧ください。 |
done |
close |
|
リージョン別の CPU 使用率 instance/cpu/utilization_by_priority |
選択したインスタンスまたはデータベースの CPU 使用率(リージョンでグループ化)。 | done |
done |
データベース別の CPU 使用率 instance/cpu/utilization_by_priority |
選択したインスタンスの CPU 使用率(データベースとリージョンでグループ化)。 | done |
close |
|
ユーザー / システム別の CPU 使用率 instance/cpu/utilization_by_priority |
選択したインスタンスまたはデータベースの CPU 使用率(ユーザータスクとシステムタスク、優先度でグループ化)。 | done |
done |
オペレーション タイプ別の CPU 使用率 instance/cpu/utilization_by_operation_type |
読み取り、書き込み、commit などのユーザーが開始したオペレーションでグループ化した、インスタンスの CPU リソースの比率としての CPU 使用率の積み上げグラフ。高 CPU 使用率の調査の説明に沿って、この指標を使用して、CPU 使用率の詳細な内訳を取得し、さらにトラブルシューティングします。 オプション リストを使用して、タスクの優先度でさらにフィルタできます。 デュアルリージョン インスタンスまたはマルチリージョン インスタンスの場合、折れ線グラフの指標はリージョン間の平均パーセンテージを示します。 |
done |
done |
CPU 使用率(24 時間の移動平均値) instance/cpu/smoothed_utilization |
CPU Spanner 使用率の合計の移動平均。インスタンスの各データベースが使用している CPU リソースの使用率で表します。各データポイントは過去 24 時間の平均を表します。 |
done |
close |
レイテンシ api/request_latencies |
読み取りリクエストまたは書き込みリクエストの処理に Spanner が要した時間。この測定は、Spanner がリクエストを受信すると開始され、Spanner がレスポンスの送信を開始すると終了します。 レイテンシ指標は、オプション リストを使用して 50 パーセンタイルと 99 パーセンタイルで確認できます。 |
close |
done |
データベース別のレイテンシ api/request_latencies |
Spanner が読み取りまたは書き込みリクエストの処理に要した時間(データベースごとにグループ化)。この測定は、Spanner がリクエストを受信すると開始され、Spanner がレスポンスの送信を開始すると終了します。 このグラフのビューリストを使用して、50 パーセンタイル レイテンシと 99 パーセンタイル レイテンシの指標を確認できます。 |
done |
close |
API メソッド別のレイテンシ api/request_latencies |
Spanner がリクエストの処理に要した時間(Spanner API メソッドごとにグループ化)。この測定は、Spanner がリクエストを受信すると開始され、Spanner がレスポンスの送信を開始すると終了します。 このグラフのビューリストを使用して、50 パーセンタイルと 99 パーセンタイルのレイテンシの指標を確認できます。 |
close |
done |
トランザクション レイテンシ api/request_latencies_by_transaction_type |
Spanner がトランザクションの処理に要した時間。読み取り / 書き込み型と読み取り専用型のトランザクションの指標を表示できます。 レイテンシ チャートとトランザクション レイテンシ チャートの主な違いは、トランザクション レイテンシ チャートで、読み取り専用タイプへのリーダーの関与を確認できる点です。リーダーが関与している読み取りでは、レイテンシが増加する可能性があります。このグラフを使用すると、タイムスタンプ バウンドが少なくとも 15 秒であると仮定して、リーダーと通信せずに stale read を使用すべきかどうかを評価できます。読み取り / 書き込みトランザクションの場合、リーダーは常にトランザクションに関与するため、グラフに表示されるデータには、リクエストがリーダーに到達してレスポンスを受信するまでの時間が常に含まれます。ロケーションは、Cloud Spanner API フロントエンドのリージョンに対応します。 このグラフのビューリストを使用して、50 パーセンタイルと 99 パーセンタイルのレイテンシの指標を確認できます。 |
close |
done |
データベース別のトランザクション レイテンシ api/request_latencies_by_transaction_type |
Spanner がトランザクションの処理に要した時間。 レイテンシ チャートとデータベース グラフによるトランザクション レイテンシの主な違いは、データベース トランザクション レイテンシ チャートで、読み取り専用タイプへのリーダーの関与を確認できる点です。リーダーが関与している読み取りでは、レイテンシが増加する可能性があります。このグラフを使用すると、タイムスタンプ バウンドが少なくとも 15 秒であると仮定して、リーダーと通信せずに stale read を使用すべきかどうかを評価できます。読み取り / 書き込みトランザクションの場合、リーダーは常にトランザクションに関与するため、グラフに表示されるデータには、リクエストがリーダーに到達してレスポンスを受信するまでの時間が常に含まれます。ロケーションは、Cloud Spanner API フロントエンドのリージョンに対応します。 このグラフのビューリストを使用して、50 パーセンタイルと 99 パーセンタイルのレイテンシの指標を確認できます。 |
done |
close |
API メソッド別のトランザクション レイテンシ api/request_latencies_by_transaction_type |
Spanner がトランザクションの処理に要した時間。 レイテンシ グラフと API メソッド別のトランザクション レイテンシ グラフの主な違いは、API メソッド別のトランザクション レイテンシのグラフで読み取り専用タイプへのリーダーの関与を確認できることです。リーダーが関与している読み取りでは、レイテンシが高くなる可能性があります。このグラフを使用すると、タイムスタンプ バウンドが少なくとも 15 秒であると仮定して、リーダーと通信せずに stale read を使用すべきかどうかを評価できます。読み取り / 書き込みトランザクションの場合、リーダーは常にトランザクションに関与するため、グラフに表示されるデータには、リクエストがリーダーに到達してレスポンスを受信するまでの時間が常に含まれます。ロケーションは、Cloud Spanner API フロントエンドのリージョンに対応します。 |
close |
done |
1 秒あたりのオペレーション数 api/api_request_count |
Spanner が 1 秒間に実行する読み取りオペレーションと書き込みオペレーションの数。または、1 秒あたりの Spanner サーバーエラーの数。 グラフに表示するオペレーションを選択できます。
|
close |
done |
データベース別の 1 秒あたりのオペレーション数 api/api_request_count |
Spanner が 1 秒間に実行する読み取りオペレーションと書き込みオペレーションの数。または、1 秒あたりの Spanner サーバーエラーの数。このグラフはデータベースごとにグループ化されています。 グラフに表示するオペレーションを選択できます。
|
done |
close |
API メソッド別の 1 秒あたりのオペレーション数 api/api_request_count |
Spanner が 1 秒間に実行したオペレーションの数(Spanner API メソッドでグループ化) |
close |
done |
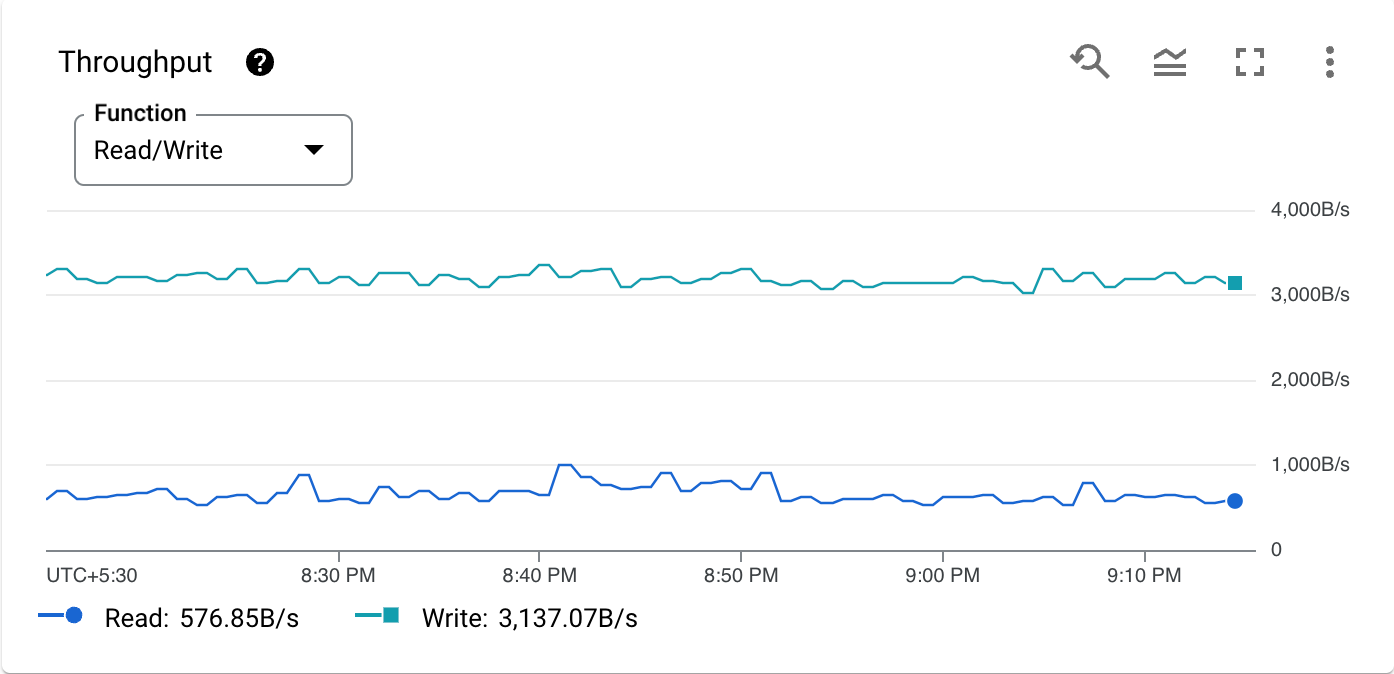
スループット api/sent_bytes_count(読み取り) api/received_bytes_count(書き込み) |
データベースで 1 秒間に発生した読み取りまたは書き込みで処理された非圧縮データ量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 読み取りスループットには、読み取り API のメソッドと SQL クエリに対するリクエストとレスポンスが含まれます。また、DML ステートメントに対するリクエストとレスポンスも含まれます。 書き込みスループットには、Mutation API によるデータの commit に対するリクエストとレスポンスが含まれます。DML ステートメントに対するリクエストとレスポンスは除外されます。 |
close |
done |
データベース別のスループット api/sent_bytes_count(読み取り) api/received_bytes_count(書き込み) |
データベースごとにグループ化された、インスタンスで 1 秒間に発生した読み取りまたは書き込みで処理された非圧縮データ量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 読み取りスループットには、読み取り API のメソッドと SQL クエリに対するリクエストとレスポンスが含まれます。また、DML ステートメントに対するリクエストとレスポンスも含まれます。 書き込みスループットには、Mutation API によるデータの commit に対するリクエストとレスポンスが含まれます。DML ステートメントに対するリクエストとレスポンスは除外されます。 |
done |
close |
API メソッド別のスループット api/sent_bytes_count(読み取り) api/received_bytes_count(書き込み) |
API メソッドごとにグループ化された、インスタンスまたはデータベースで 1 秒間に発生した読み取りまたは書き込みで処理された非圧縮データ量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 読み取りスループットには、読み取り API のメソッドと SQL クエリに対するリクエストとレスポンスが含まれます。また、DML ステートメントに対するリクエストとレスポンスも含まれます。 書き込みスループットには、Mutation API によるデータの commit に対するリクエストとレスポンスが含まれます。DML ステートメントに対するリクエストとレスポンスは除外されます。 |
close |
done |
保存容量の合計 instance/storage/used_bytes |
データベースに保存されているデータの量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 |
close |
done |
データベース別のデータベース ストレージの合計 instance/storage/used_bytes |
インスタンスに保存されているデータの量(データベース別にグループ化)。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 |
done |
close |
バックアップ ストレージの合計 instance/backup/used_bytes |
データベースに関連付けられているバックアップに保存されているデータの量。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 |
close |
done |
ロック待機時間 lock_stat/total/lock_wait_time |
トランザクションのロック待機時間は、別のトランザクションによって保持されているリソースのロック取得に必要な時間です。 ロック競合のロック待機時間の合計が、データベース全体で記録されます。 |
close |
done |
データベース別のロック待機時間 lock_stat/total/lock_wait_time |
トランザクションのロック待機時間は、別のトランザクションによって保持されているリソースのロック取得に必要な時間です(データベースでグループ化)。 ロック競合のロック待機時間の合計が、インスタンス全体で記録されます。 |
done |
close |
データベース別のバックアップ ストレージの合計 instance/backup/used_bytes |
インスタンスに関連付けられたバックアップに保存されているデータの量(データベース別にグループ化)。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 |
done |
close |
コンピューティング容量 instance/processing_units instance/nodes |
コンピューティング容量は、インスタンスで使用可能な処理ユニットまたはノードの数です。容量は処理ユニットまたはノードの数で表示できます。 |
done |
close |
リーダー分布 instance/leader_percentage_by_region |
デュアルリージョン インスタンスまたはマルチリージョン インスタンスの場合、指定された地域でリーダーの過半数(50% 以上)を占めるデータベースの数を表示できます。[リージョン] リストメニューで特定のリージョンを選択すると、リーダー リージョンとして選択したリージョンを持つそのインスタンス内のデータベースの合計数がグラフに表示されます。[リージョン] リストメニューで [すべてのリージョン] を選択すると、グラフにはリージョンごとに 1 つの線が表示され、各線にはそのリージョンがリーダー リージョンであるインスタンス内のデータベースの合計数が表示されます。 デュアルリージョン インスタンスまたはマルチリージョン インスタンスのデータベースの場合、リージョン別にグループ化されたリーダーの割合を確認できます。たとえば、データベースに 5 つのリーダーがあり、ある時点で us-west1 に 1 つ us-east1 に 4 つある場合、[すべてのリージョン] グラフには、2 本の線が表示されます(リージョンごとに 1 本の線)。us-west1 の 1 本の線は 20% で、us-east1 のもう 1 本の線は 80% です。us-west1 グラフには 20% に 1 行が表示され、us-east1 グラフには 80% に 1 行が表示されます。データベースが最近作成されたか、リーダー リージョンが最近変更された場合、グラフはすぐに安定しない可能性があります。 このグラフは、デュアルリージョン インスタンスとマルチリージョン インスタンスでのみ使用できます。 |
done |
done |
ピーク スプリットの CPU 使用率スコア instance/peak_split_peak |
データベースのすべてのスプリット全体で観測されたピーク スプリットの最大 CPU 使用率。この指標は、スプリットで使用されている処理ユニット リソースの割合を示します。割合が 50% を超える場合はウォーム スプリットです。つまり、スプリットがホストサーバーの処理ユニット リソースの半分を使用しています。割合が 100% の場合はホット スプリットです。ホストサーバーの処理ユニット リソースの大部分を使用しているスプリットです。Spanner は、負荷に応じた分割を使用してホットスポットを解決し、負荷を分散します。ただし、アプリケーション内の問題のあるパターンが原因で、分割を複数回試行しても、Spanner で負荷を分散できない場合があります。そのため、ホットスポットが 10 分以上続く場合は、さらにトラブルシューティングを行い、アプリケーションの変更が必要になる可能性があります。詳細については、スプリット内のホットスポットを見つけるをご覧ください。 | done |
done |
|
リモート サービス呼び出し query_stat/total/remote_service_calls_count |
リモート サービス呼び出し数(サービスとレスポンス コード別)。 HTTP レスポンス コード(200 や 500 など)で応答します。 |
done |
done |
|
レイテンシ: リモート サービス呼び出し query_stat/total/remote_service_calls_latencies |
リモート サービス呼び出しのレイテンシ(サービス別)。 レイテンシ指標は、オプション リストを使用して 50 パーセンタイルと 99 パーセンタイルで確認できます。 |
done |
done |
|
リモート サービスで処理された行 query_stat/total/remote_service_processed_rows_count |
リモート サービスによって処理された行の数。サービス名とレスポンス コード別にグループ化されます。 HTTP レスポンス コード(200 や 500 など)で応答します。 |
done |
done |
|
レイテンシ: リモート サービス行 query_stat/total/remote_service_processed_rows_latencies |
リモート サービスによって処理された行の数。サービス名とレスポンス コード別にグループ化されます。 レイテンシ指標は、オプション リストを使用して 50 パーセンタイルと 99 パーセンタイルで確認できます。 |
done |
done |
|
リモート サービス ネットワークのバイト数 query_stat/total/remote_service_network_bytes_sizes |
リモート サービスとネットワーク間の送受信バイト数(サービスと方向別)。 この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 方向は、送信または受信されるトラフィックを指します。 ネットワーク バイト交換の 50 パーセンタイルと 99 パーセンタイルの指標は、オプション リストを使用して確認できます。 |
done |
done |
|
マイクロサービス呼び出し query_stat/total/remote_service_calls_count |
マイクロサービス呼び出しの数(マイクロサービスとレスポンス コード別)。 | done |
done |
|
レイテンシ: マイクロサービス呼び出し query_stat/total/remote_service_calls_latencies |
マイクロサービス呼び出しのレイテンシ(マイクロサービス別)。 | done |
done |
テーブル別のデータベース ストレージ (なし) |
インスタンスまたはデータベースに保存されているデータの量(選択したデータベース内のテーブル別にグループ化)。この値は、KiB、MiB、GiB などのバイナリバイト単位で測定されます。 このグラフは、 SPANNER_SYS.TABLE_SIZES_STATS_1HOUR にクエリを実行してデータを取得します。詳細については、
テーブルサイズの統計情報をご覧ください。 |
close |
done |
オペレーションで最も使用されているテーブル (なし) |
読み取り、書き込みまたは削除のオペレーションの数によって決定される、インスタンスまたはデータベースで最も使用される 15 個のテーブルとインデックス。 このグラフは、テーブル オペレーションの統計情報テーブルにクエリを実行してデータを取得します。詳細については、テーブル オペレーションの統計情報をご覧ください。 |
close |
done |
オペレーションで最も使用されていないテーブル (なし) |
読み取り、書き込みまたは削除のオペレーションの数によって決定される、インスタンスまたはデータベースでの使用が最も少ない 15 個のテーブルとインデックス。 このグラフは、テーブル オペレーションの統計情報テーブルにクエリを実行してデータを取得します。詳細については、テーブル オペレーションの統計情報をご覧ください。 |
close |
done |
マネージド オートスケーラーのグラフと指標
前のセクションで説明したオプションに加えて、インスタンスでマネージド オートスケーラーが有効になっている場合、コンピューティング容量グラフに [ログを表示] ボタンが表示されます。このボタンをクリックすると、マネージド オートスケーラーのログが表示されます。
マネージド オートスケーラーが有効になっているインスタンスでは、次の指標を使用できます。
階層型ストレージのグラフと指標
階層型ストレージを使用するインスタンスでは、次の指標を使用できます。
| 指標名とタイプ | 説明 |
|---|---|
| instance/storage/used_bytes | SSD ストレージと HDD ストレージに保存されているデータの合計バイト数。 |
| instance/storage/combined/limit_bytes | SSD と HDD の合計ストレージの上限。 |
| instance/storage/combined/limit_per_processing_unit | 各処理ユニットの SSD と HDD の合計ストレージの上限。 |
| instance/storage/combined/utilization | SSD と HDD の使用されている合計ストレージと、合計ストレージの上限の比較。 |
| instance/disk_load | HDD の負荷使用量。 |
データの保持
システム分析情報ダッシュボードのほとんどの指標の最大データ保持期間は 6 週間です。ただし、テーブルごとのデータベース ストレージ グラフの場合、データは(Spanner ではなく)SPANNER_SYS.TABLE_SIZES_STATS_1HOUR テーブルから消費され、最大保持期間は 30 日です。詳細については、データの保持をご覧ください。
システム分析情報ダッシュボードを表示する
システム分析情報ページを表示するには、インスタンスとデータベース レベルで Spanner の権限と Spanner の権限に加えて、次の Identity and Access Management(IAM)権限が必要です。
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Spanner IAM 権限の詳細については、IAM を使用したアクセス制御をご覧ください。
インスタンスでマネージド オートスケーラーを有効にする場合は、マネージド オートスケーラーのログを表示するための logging.logEntries.list、logging.logs.list、logging.logServices.list 権限も必要です。
この権限の詳細については、事前定義ロールをご覧ください。
システム分析情報ダッシュボードを表示するには、次の手順を実施します。
Google Cloud コンソールで、Spanner インスタンスのリストを開きます。
次のいずれかを行います。
インスタンスの指標を表示するには、確認するインスタンスの名前をクリックし、ナビゲーション メニューで [システム分析情報] をクリックします。
データベースの指標を表示するには、インスタンスの名前をクリックしてデータベースを選択し、ナビゲーション メニューで [システム分析情報] をクリックします。
省略可: 期間を変えて履歴データを表示するには、ページの右上にあるボタンを探し、表示したい期間をクリックします。
省略可: グラフに表示されるデータを制御するには、グラフのリストのいずれかをクリックします。たとえば、インスタンスがデュアルリージョンまたはマルチリージョン構成を使用している場合、一部のグラフではリストを使用して特定のリージョンのデータを表示できます。すべてのグラフにビューリストがあるわけではありません。
次のステップ
- Spanner の CPU 使用率とレイテンシの指標について理解する。
- Monitoring でカスタマイズされたグラフとアラートを設定する。
- Spanner インスタンスの種類について詳しく調べる。