本頁面說明如何使用 CPU 使用率指標和圖表,以及其他內省工具,調查資料庫中的高 CPU 使用率。
找出系統或使用者工作是否導致 CPU 使用率偏高
Google Cloud 主控台提供多種 Spanner 監控工具,可讓您查看執行個體最重要的指標狀態。其中一個圖表是「CPU 使用率 - 總計」。這張圖表會顯示 CPU 總使用率 (以執行個體 CPU 資源百分比表示),並依工作優先順序和作業類型細分。工作分為兩種:使用者工作 (例如讀取和寫入),以及系統工作,後者涵蓋壓縮和索引回填等自動化背景工作。
圖 1 顯示「CPU 使用率 - 總計」圖表的範例。
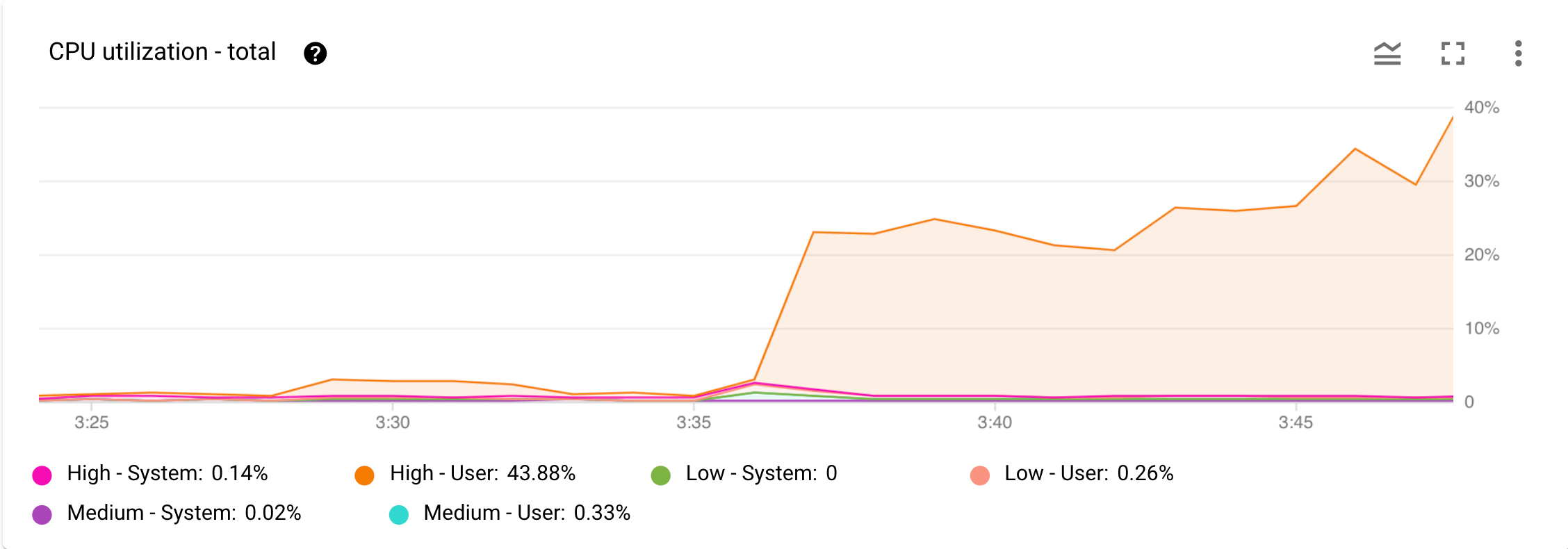
圖 1. Google Cloud 主控台「監控」資訊主頁的「CPU 使用率 - 總計」圖表。
假設您收到 Cloud Monitoring 發出的警報,指出 CPU 用量大幅增加。您在 Google Cloud 控制台中為執行個體開啟「Monitoring」資訊主頁,並查看 Cloud 控制台中的「CPU Utilization - Total」圖表。如圖 1所示,您可以看到高優先順序使用者工作導致 CPU 使用率增加。接下來,請找出哪些高優先順序使用者作業導致 CPU 使用率升高。
您可以使用「查詢深入分析」資訊主頁,以視覺化方式呈現這項指標和其他指標的時間序列。這些預先建構的資訊主頁可協助您查看 CPU 使用率尖峰,並找出效率不佳的查詢。
找出導致 CPU 使用率飆升的使用者操作
圖 1 中的「CPU 使用率 - 總計」圖表顯示,高優先順序使用者工作是導致 CPU 用量增加的原因。
接下來,您將在 Cloud 控制台中查看「CPU 使用率 (按照作業類型顯示)」圖表。這張圖表顯示 CPU 使用率,並依據使用者啟動的高、中、低優先順序作業進行細分。
什麼是使用者啟動的作業?
使用者啟動的作業,是指透過 API 要求啟動的作業。Spanner 會將這些要求分組為作業類型或類別,您可以在「依作業類型劃分的 CPU 使用率」圖表中,以線條的形式顯示每個作業類型。下表說明各個作業類型所包含的 API 方法。
| 作業 | API 方法 | 說明 |
|---|---|---|
| read_readonly | 讀取 StreamingRead |
包括使用索引鍵查詢和掃描從資料庫擷取資料列的讀取作業。 |
| read_readwrite | 讀取 StreamingRead |
包括在讀寫交易中執行的讀取作業。 |
| read_withpartitiontoken | 讀取 StreamingRead |
包括使用一組分區符記執行的讀取作業。 |
| executesql_select_readonly | ExecuteSql ExecuteStreamingSql |
包括執行 Select SQL 陳述式和變更串流查詢。 |
| executesql_select_readwrite | ExecuteSql ExecuteStreamingSql |
在讀寫交易中執行 Select 陳述式。 |
| executesql_select_withpartitiontoken | ExecuteSql ExecuteStreamingSql |
包含使用一組分區符記執行的執行 Select 陳述式。 |
| executesql_dml_readwrite | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
包括執行 DML SQL 陳述式。 |
| executesql_dml_partitioned | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
包括執行分區 DML SQL 陳述式。 |
| beginorcommit | BeginTransaction Commit Rollback |
包括開始、提交和復原交易。 |
| 其他 | PartitionQuery PartitionRead GetSession CreateSession |
包括 PartitionQuery、PartitionRead、Create Database、Create Instance、工作階段相關作業、內部時間敏感的服務作業等等。 |
以下是「CPU 使用率 (以作業類型分組)」指標的範例圖表。
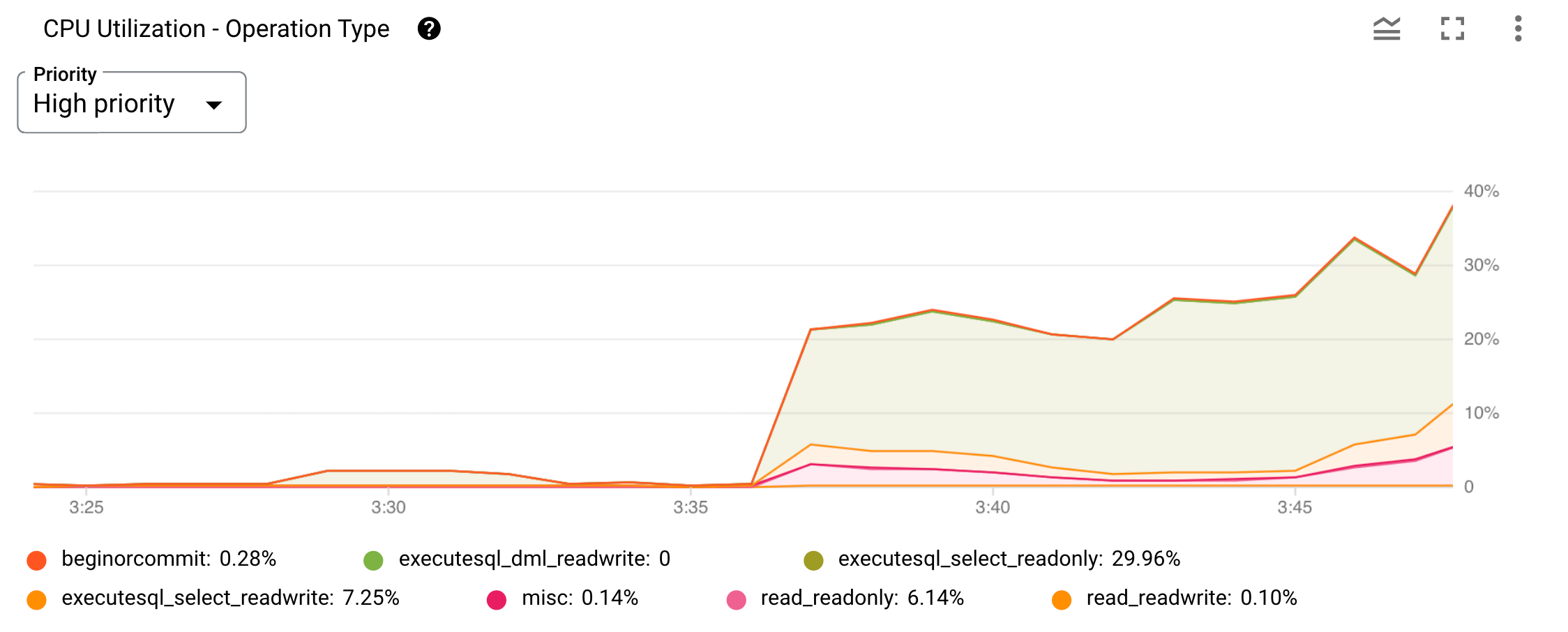
圖 2: Google Cloud 控制台中的CPU 使用率 (按照作業類型顯示) 圖表。
您可以使用圖表頂端的「Priority」選單,將顯示範圍限制為特定優先順序。並在折線圖上標示每個作業類型或類別。圖表下方列出的類別可用來識別每個圖表。您可以選取或取消選取各個類別篩選器,隱藏或顯示各個圖表。
或者,您也可以在 Metrics Explorer 中建立這張圖表,步驟如下:
在 Metrics Explorer 中,依據作業類型建立 CPU 使用率圖表
- 在 Google Cloud 控制台中,選取「Monitoring」,或使用下列按鈕:
- 在導覽窗格中選取「Metrics Explorer」。
-
在「Find resource type and metric」欄位中輸入
spanner.googleapis.com/instance/cpu/utilization_by_operation_type值,然後選取方塊下方顯示的資料列。 -
在「Filter」欄位中輸入值
instance_id,然後輸入要檢查的執行個體 ID,並按一下「> 套用」。 -
在「Group By」欄位中,從下拉式清單中選取「
category」。圖表會顯示使用者工作的 CPU 使用率,並依作業類型或類別分組。
雖然前一個章節的 依優先順序劃分的 CPU 使用率指標有助於判斷使用者或系統工作是否導致 CPU 資源使用率上升,但您可以透過 依作業類型劃分的 CPU 使用率指標,進一步瞭解導致 CPU 使用率上升的使用者啟動作業類型。
找出導致 CPU 使用率上升的使用者要求
如要判斷哪個特定使用者要求導致 圖 2 所示 executesql_select_readonly 作業類型圖表中的 CPU 使用率激增,您可以使用內建的自省統計資料表格,進一步瞭解問題。
請參考下表,根據導致 CPU 使用率偏高的作業類型,判斷要查詢哪個統計資料表。
| 作業類型 | 查詢 | 讀取 | 交易 |
|---|---|---|---|
| read_readonly | 否 | 是 | 否 |
| read_readwrite | 否 | 是 | 是 |
| read_withpartitiontoken | 否 | 是 | 否 |
| executesql_select_readonly | 是 | 否 | 否 |
| executesql_select_withpartitiontoken | 是 | 否 | 否 |
| executesql_select_readwrite | 是 | 否 | 是 |
| executesql_dml_readwrite | 是 | 否 | 是 |
| executesql_dml_partitioned | 否 | 否 | 是 |
| beginorcommit | 否 | 否 | 是 |
舉例來說,如果 read_withpartitiontoken 有問題,請使用讀取統計資料進行疑難排解。
在這種情況下,executesql_select_readonly 作業似乎是導致 CPU 使用率增加的原因。根據上表,您應該查看查詢統計資料,找出哪些查詢耗用大量資源、執行頻率高或掃描大量資料。
如要找出前一小時中 CPU 使用率最高的查詢,您可以在 query_stats_top_hour 統計資料表上執行下列查詢。
SELECT text,
execution_count AS count,
avg_latency_seconds AS latency,
avg_cpu_seconds AS cpu,
execution_count * avg_cpu_seconds AS total_cpu
FROM spanner_sys.query_stats_top_hour
WHERE interval_end =
(SELECT MAX(interval_end)
FROM spanner_sys.query_stats_top_hour)
ORDER BY total_cpu DESC;
輸出結果會顯示依 CPU 使用率排序的查詢。找出 CPU 使用率最高的查詢後,您可以嘗試下列選項進行調整。
查看查詢執行計畫,找出可能導致 CPU 使用率過高的效率問題。
查看查詢,確認是否遵循 SQL 最佳做法。
查看資料庫結構定義設計,並更新結構定義,以便更有效率地執行查詢。
針對 Spanner 在間隔期間執行查詢的次數,建立基準。您可以使用這個基準,偵測並調查任何與正常行為的異常偏差原因。
如果您無法找出 CPU 密集查詢,請為執行個體新增運算資源。增加運算容量可提供更多 CPU 資源,讓 Spanner 處理更大量的工作負載。詳情請參閱「增加運算能力」。
後續步驟
瞭解 CPU 使用率指標。
瞭解其他內省工具。
進一步瞭解 Spanner 的 SQL 最佳做法。
請參閱 Spanner 的指標清單。