本文說明如何使用系統洞察資訊主頁監控 Spanner 執行個體和資料庫。
關於系統深入分析
系統洞察資訊主頁會顯示所選執行個體或資料庫的評量表和圖表,並提供延遲、CPU 使用率、儲存空間、輸送量和其他成效統計資料的測量結果。您可以查看可選時間範圍的圖表,範圍從過去 1 小時到過去 30 天。
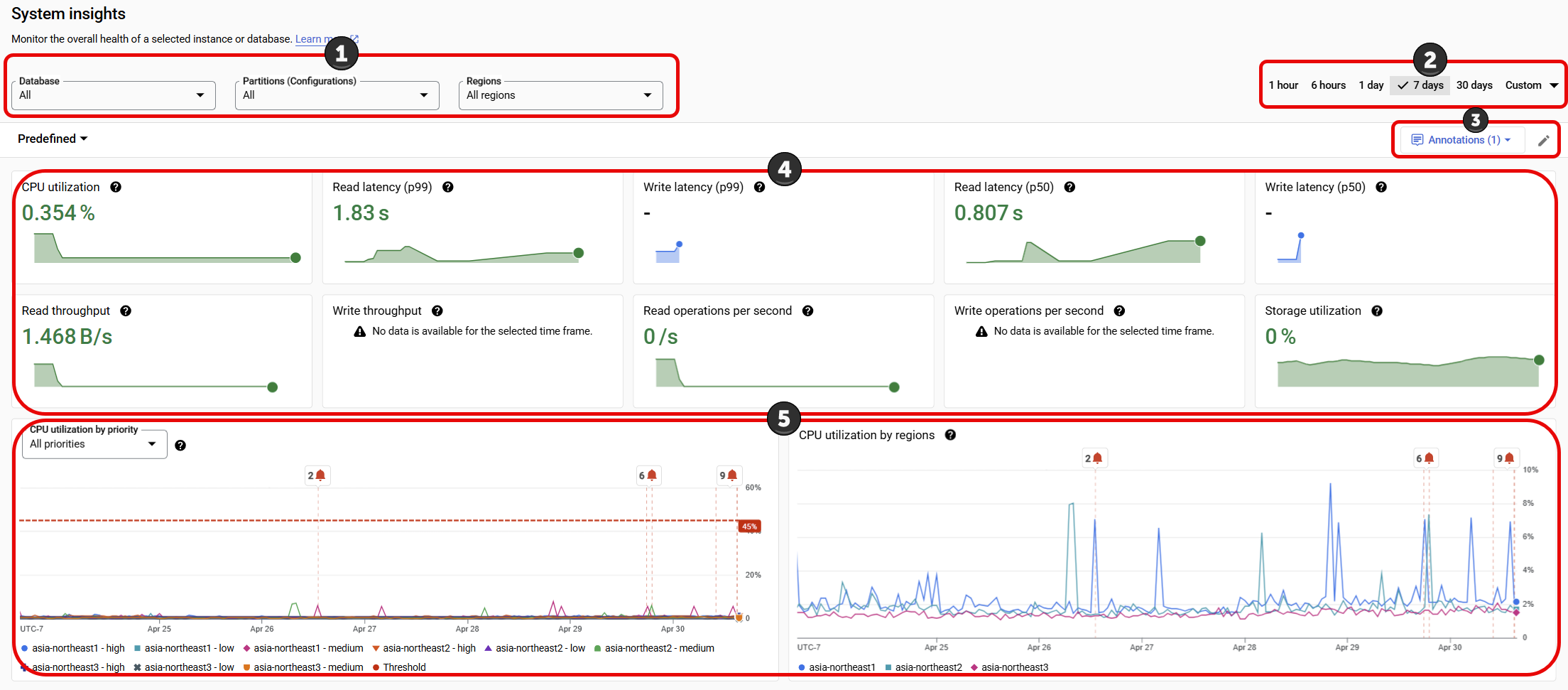
系統洞察資訊主頁包含下列各節,數字對應下方的 UI 螢幕截圖:
- 洞察選取器:選取要填入資訊主頁的資料庫、執行個體分割區和區域。如果執行個體中有多個執行個體分割區或區域,系統洞察會顯示執行個體分割區和區域選項。
- 時間範圍篩選器:依時間範圍篩選統計資料,例如小時、天數或自訂範圍。
- 資訊主頁選取器:選取使用者自訂的檢視畫面,或將系統洞察資料重設為預設的預先定義檢視畫面。
- 註解:選取洞察快訊事件類型,在圖表上加註。
- 自訂資訊主頁:自訂資訊主頁小工具和系統洞察資訊主頁的外觀、位置和內容。這份文件說明預先定義的資訊主頁簡報。
- 評量表:顯示特定時間點的統計資料,以及所選期間的統計資料。
- 圖表:顯示 CPU 使用率、輸送量、延遲時間、儲存空間用量等圖表。註解設定的洞察快訊會以鈴鐺圖示顯示在圖表上。
必要的角色
如要取得查看或修改洞察資訊主控台 (包括自訂主控台) 所需的權限,請要求管理員在專案中授予下列 IAM 角色:
-
如要建立及編輯自訂資訊主頁,請按照下列步驟操作:
Monitoring 資訊主頁設定編輯者 (
roles/monitoring.dashboardEditor) -
如要開啟及查看 Metrics Explorer 圖表:
Monitoring 資訊主頁設定檢視者 (
roles/monitoring.dashboardViewer) -
如要建立及編輯 Metrics Explorer 快訊:
Monitoring 編輯器 (
roles/monitoring.editor)
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
這些預先定義的角色包含查看或修改洞察資訊主頁 (包括自訂資訊主頁) 所需的權限。如要查看確切的必要權限,請展開「必要權限」部分:
所需權限
如要查看或修改洞察資訊主頁 (包括自訂資訊主頁),必須具備下列權限:
-
如要建立自訂資訊主頁:
monitoring.dashboards.create -
如要編輯自訂資訊主頁,請按照下列步驟操作:
monitoring.dashboards.update -
如要查看自訂資訊主頁:
monitoring.dashboards.get, monitoring.dashboards.list
自訂系統洞察資訊主頁
系統洞察資訊主頁是預先定義的資訊主頁,您可以自訂這個頁面,顯示最重要的資訊。您可以新增圖表、變更版面配置,以及篩選資料,著重分析特定資源。
系統洞察資訊主頁的變更不會造成破壞,只要將資訊主頁選取器設為「預先定義」,即可重設。
修改資訊主頁
如要修改資訊主頁,請按一下「自訂資訊主頁」。你可以選擇下列做法:
- 新增小工具:在資訊主頁工具列中,依序點按 「新增小工具」,選取要新增的小工具,然後進行設定。
- 編輯小工具:將游標懸停在小工具上,顯示工具列,然後按一下「編輯」圖示 。您可以變更小工具的類型,並自訂顯示的資料。
- 複製小工具:將游標懸停在小工具上,顯示工具列, 按一下「更多圖表選項」, 然後按一下「複製小工具」。
- 刪除小工具:將游標懸停在小工具上,顯示工具列, 按一下「更多圖表選項」圖示 , 然後按一下「刪除小工具」。
- 變更版面配置:你可以拖曳小工具來重新調整位置,也可以拖曳小工具的角落來調整大小。
- 命名自訂檢視:您可以在「自訂檢視名稱」方塊中設定自訂檢視名稱。
- 儲存資訊主頁:按一下「儲存」,即可儲存自訂檢視畫面。您也可以按一下「結束編輯模式」,在不儲存的情況下結束編輯。
系統洞察資訊評量表、圖表和指標
系統洞察資訊主頁會提供下列圖表和指標,顯示執行個體目前和過往的狀態。大多數圖表和指標都可在執行個體層級使用。您也可以查看執行個體中單一資料庫的許多圖表和指標。
可用的評量表
| 名稱 | 說明 |
|---|---|
| CPU 使用率 | 執行個體或所選資料庫中的 CPU 用量總計。在雙區域或多區域執行個體中,這項指標代表所有區域的 CPU 平均使用率。 |
| 延遲時間 (第 99 個百分位數) | 執行個體或所選資料庫中,讀取和寫入作業的 P99 延遲時間 (第 99 個百分位數),代表 99% 的這類作業完成所需的時間。 |
| 延遲時間 (第 50 個百分位數) | 執行個體或所選資料庫中,讀取和寫入作業的 P50 延遲時間 (第 50 個百分位數),代表 50% 的作業完成時間。 |
| 處理量 | 每秒從執行個體或資料庫讀取/寫入的未壓縮資料量。這個值是以二進位位元組計算,例如 KiB、MiB 或 GiB。 |
| 每秒作業數 | 執行個體或所選資料庫中的每秒讀取/寫入作業數 (速率)。 |
| 儲存空間使用率 | 在執行個體層級,這是指執行個體中的儲存空間總使用率。在資料庫層級,這是所選資料庫使用的儲存空間總量。 |
可用的圖表和指標
以下是範例指標的圖表,即依作業類型劃分的 CPU 使用率:

每個圖表的工具列都提供下列標準選項。除非將指標懸停在圖表上,否則部分元素會隱藏。
如要放大圖表的特定部分,請將指標拖曳至要檢視的部分。這項操作會設定自訂時間範圍,您可以透過時間範圍篩選器調整或還原。
如要查看圖表和資料的說明,請按一下 help。
如要查看套用至圖表的篩選器和分組,請按一下 info。
如要根據圖表的資料建立快訊,請按一下 add_alert。
如要探索圖表中的資料,請按一下 query_stats。
如要查看其他圖表選項,請按一下 more_vert 「更多圖表選項」。
如要以全螢幕模式查看圖表,請按一下「以全螢幕模式查看」。 如要退出全螢幕模式,請按一下「取消」或按下 Esc 鍵。
如要展開或收合圖表圖例,請按一下「展開/收合圖表圖例」。
如要下載圖表,請按一下「下載」,然後選取下載格式。
如要變更圖表的視覺格式,請按一下「模式」,然後選取檢視模式。
如要在 Metrics Explorer 中查看指標,請按一下「在 Metrics Explorer 中查看」。選取「Spanner Database」資源類型後,您可以在 Metrics Explorer 中查看其他 Spanner 指標。
下表說明系統洞察資訊主控台中預設顯示的圖表。系統會列出每個圖表的指標類型。指標類型字串的前置字串如下:spanner.googleapis.com/。指標類型:說明可從受監控資源收集的測量值。
| 圖表名稱和指標類型 |
說明 | 適用於執行個體 | 適用於資料庫 |
|---|---|---|---|
|
雙區域仲裁健康狀態時間軸 instance/dual_region_quorum_availability |
這個圖表只會顯示雙區域執行個體設定。這張圖表會顯示三個仲裁的健康狀態:雙區域仲裁 ( Global),以及每個區域中的單一區域仲裁 (例如 Sydney 和 Melbourne)。
時間軸中會顯示橘色長條,代表服務中斷。將滑鼠游標懸停在長條上,即可查看中斷的開始和結束時間。搭配錯誤率和延遲時間指標使用這張圖表,有助於您在發生區域性故障時,自行管理何時進行容錯移轉。詳情請參閱「容錯移轉和容錯回復」。 如要手動容錯移轉和容錯回復,請參閱 變更雙重區域仲裁。 |
done |
done |
依優先順序顯示 CPU 使用率 instance/cpu/utilization_by_priority |
執行個體 CPU 資源的百分比,以優先順序區分高、中、低或所有工作。包括您發起的要求,以及 Spanner 必須立即完成的維護工作。 如果是雙區域或多區域執行個體,指標會依區域和優先順序分組。 進一步瞭解高優先順序工作。 進一步瞭解 CPU 使用率。 |
done |
close |
|
各區域的 CPU 使用率 instance/cpu/utilization_by_priority |
所選執行個體或資料庫中的 CPU 使用率,以區域分組。 | done |
done |
|
各資料庫的 CPU 使用率 instance/cpu/utilization_by_priority |
所選執行個體中的 CPU 使用率,以資料庫和區域分組。 | done |
close |
|
各使用者/系統的 CPU 使用率 instance/cpu/utilization_by_priority |
所選執行個體或資料庫中的 CPU 使用率,以使用者和系統工作,以及優先順序分組。 | done |
done |
CPU 使用率 (以作業類型分組) instance/cpu/utilization_by_operation_type |
CPU 使用率的堆疊圖表 (以執行個體 CPU 資源百分比表示),並依使用者啟動的作業 (例如讀取、寫入和提交) 分組。如「調查 CPU 使用率偏高問題」一文所述,您可以使用這項指標取得 CPU 使用率的詳細細目,並進一步排解問題。 您可以使用選項清單,依工作優先順序進一步篩選。 如果是雙區域或多區域執行個體,折線圖中的指標會顯示區域間的平均百分比。 |
done |
done |
CPU 使用率 (24 小時累計平均值) instance/cpu/smoothed_utilization |
每個資料庫的CPU Spanner 使用率累計平均值,以執行個體 CPU 資源的百分比表示。每個資料點都是過去 24 小時的平均值。 |
done |
close |
延遲時間 api/request_latencies |
Spanner 處理讀取或寫入要求所需的時間。這項指標的計算方式是從 Spanner 收到要求開始,到 Spanner 開始傳送回應時結束。 您可以使用選項清單,查看第 50 和第 99 個百分位數的延遲時間指標。 |
close |
done |
各資料庫的延遲時間 api/request_latencies |
Spanner 處理讀取或寫入要求所需的時間 (按資料庫分組)。這項指標的計算方式是從 Spanner 收到要求開始,到 Spanner 開始傳送回應時結束。 您可以使用這張圖表上的檢視清單,查看第 50 和第 99 個百分位數延遲的指標。 |
done |
close |
延遲時間 (以 API 方法分組) api/request_latencies |
Spanner 處理要求所需的時間 (按 Spanner API 方法分組)。這項指標的計算時間從 Spanner 收到要求開始,到 Spanner 開始傳送回應為止。 您可以使用這張圖表上的檢視清單,查看第 50 和第 99 個百分位數延遲的指標。 |
close |
done |
交易延遲 api/request_latencies_by_transaction_type |
Spanner 處理交易所需的時間。 您可以選取要查看讀寫和唯讀類型交易的指標。 「延遲時間」圖表和「交易延遲時間」圖表的主要差異在於,「交易延遲時間」圖表可讓您查看唯讀類型的領導者參與情形。涉及領導者的讀取作業可能會出現較長的延遲時間。您可以根據這張圖表評估是否應使用過時讀取,而不需要與領導者通訊,假設時間戳記界限至少為 15 秒。對於讀寫交易,領導者一律會參與交易,因此圖表上顯示的資料一律包含要求抵達領導者並收到回應所花費的時間。這個位置對應至 Cloud Spanner API 前端的區域。 您可以使用這張圖表上的檢視清單,查看第 50 和第 99 個百分位數延遲的指標。 |
close |
done |
各資料庫的交易延遲 api/request_latencies_by_transaction_type |
Spanner 處理交易所需的時間。 「延遲時間」圖表與「各資料庫的交易延遲」圖表的主要差異在於,「各資料庫的交易延遲」圖表可顯示唯讀類型的領導者參與情形。涉及領導者的讀取作業可能會發生較長的延遲時間。假設時間戳記界線至少為 15 秒,您可以使用這張圖表評估是否應使用過時讀取,而不與領導者通訊。對於讀寫交易,領導者一律會參與交易,因此圖表上顯示的資料一律包含要求抵達領導者並收到回應所花費的時間。這個位置對應至 Cloud Spanner API 前端的區域。 您可以使用這張圖表上的檢視清單,查看第 50 和第 99 個百分位數延遲的指標。 |
done |
close |
各 API 方法的交易延遲 api/request_latencies_by_transaction_type |
Spanner 處理交易所需的時間。 「延遲時間」圖表與「各 API 方法的交易延遲時間」圖表的主要差異在於,「各 API 方法的交易延遲時間」圖表會顯示唯讀類型的領導者參與情形。涉及領導者的讀取作業可能會出現較高的延遲時間。假設時間戳記界限至少為 15 秒,您可以使用這張圖表評估是否應使用過時讀取,而不與領導者通訊。如果是讀寫交易,領導者一律會參與交易,因此圖表上顯示的資料一律會包含要求抵達領導者並收到回應所花費的時間。這個位置對應至 Cloud Spanner API 前端的區域。 |
close |
done |
每秒作業數 api/api_request_count |
Spanner 每秒執行的讀取和寫入作業數,或每秒發生的 Spanner 伺服器錯誤數。 您可以選擇要在這張圖表中查看哪些作業:
|
close |
done |
每秒作業數 (以資料庫分組) api/api_request_count |
Spanner 每秒執行的讀取和寫入作業數,或每秒發生的 Spanner 伺服器錯誤數。這張圖表會依資料庫分組。 您可以選擇要在這張圖表中查看哪些作業:
|
done |
close |
每秒作業數 (以 API 方法分組) api/api_request_count |
Spanner 每秒執行的作業數,依 Spanner API 方法分組 |
close |
done |
輸送量 api/sent_bytes_count (讀取) api/received_bytes_count (寫入) |
每秒從資料庫讀取及寫入的未壓縮資料量。這個值是以二進位位元組表示,例如 KiB、MiB 或 GiB。 讀取輸送量包括 read API 中方法的要求和回應,以及 SQL 查詢。也包括 DML 陳述式的要求和回應。 寫入輸送量包括透過突變 API 提交資料的要求和回應。 不包括 DML 陳述式的要求和回應。 |
close |
done |
資料庫的輸送量 api/sent_bytes_count (讀取) api/received_bytes_count (寫入) |
從執行個體讀取和寫入的未壓縮資料量 (每秒),並依資料庫分組。這個值是以二進位位元組計算,例如 KiB、MiB 或 GiB。 讀取輸送量包括 read API 中方法的要求和回應,以及 SQL 查詢。也包括 DML 陳述式的要求和回應。 寫入輸送量包括透過突變 API 提交資料的要求和回應。 不包括 DML 陳述式的要求和回應。 |
done |
close |
依 API 方法計算的輸送量 api/sent_bytes_count (讀取) api/received_bytes_count (寫入) |
每秒從例項或資料庫讀取或寫入的未壓縮資料量,以 API 方法分組。這個值是以二進位位元組表示,例如 KiB、MiB 或 GiB。 讀取輸送量包括 read API 中方法的要求和回應,以及 SQL 查詢。也包括 DML 陳述式的要求和回應。 寫入輸送量包括透過突變 API 提交資料的要求和回應。 不包括 DML 陳述式的要求和回應。 |
close |
done |
儲存空間總容量 instance/storage/used_bytes |
儲存在資料庫中的資料量。 這個值是以二進位位元組為單位,例如 KiB、MiB 或 GiB。 |
close |
done |
儲存空間總量 (以資料庫分組) instance/storage/used_bytes |
執行個體中儲存的資料量,以資料庫分組。 這個值是以二進位位元組為單位,例如 KiB、MiB 或 GiB。 |
done |
close |
備份儲存空間總計 instance/backup/used_bytes |
與資料庫相關聯的備份所儲存的資料量。這個值是以二進位位元組表示,例如 KiB、MiB 或 GiB。 |
close |
done |
鎖定等待時間 lock_stat/total/lock_wait_time |
交易的鎖定等待時間是指取得另一項交易持有的資源鎖定所需的時間。 系統會記錄整個資料庫的鎖定衝突總等待時間。 |
close |
done |
鎖定等待時間 (以資料庫分組) lock_stat/total/lock_wait_time |
交易的鎖定等待時間是指取得其他交易持有的資源鎖定所需的時間,並以資料庫分組。 系統會記錄整個執行個體的鎖定衝突總鎖定等待時間。 |
done |
close |
備份儲存空間總量 (以資料庫分組) instance/backup/used_bytes |
與執行個體相關聯的備份所儲存的資料量 (以資料庫分組)。這個值是以二進位位元組表示,例如 KiB、MiB 或 GiB。 |
done |
close |
運算容量 執行個體/處理單元 執行個體/節點 |
運算資源 是指執行個體中可用的處理單元或節點數量。您可以選擇以處理單元或節點顯示容量。 |
done |
close |
主要元件分布情形 instance/leader_percentage_by_region |
如果是雙區域或多區域執行個體,您可以查看在特定區域內含有大多數元件 (>=50%) 的資料庫數量。在「區域」清單選單下方,如果您選取特定區域,圖表會顯示該執行個體中,以所選區域做為領導者區域的資料庫總數。如果您在「Regions」(區域) 清單選單中選取「All regions」(所有區域),圖表會為每個區域顯示一條線,每條線會顯示執行個體中以該區域做為領導者區域的資料庫總數。 如果是雙區域或多區域執行個體中的資料庫,您可以查看按區域分組的主要元件百分比。舉例來說,如果資料庫有五個領導者,其中一個位於 us-west1,四個位於 us-east1,則「所有區域」圖表會顯示兩條線 (每個區域各一條)。us-west1 的線條位於 20%,us-east1 的線條則位於 80%。us-west1 圖表會顯示一條 20% 的線,而 us-east1 圖表會顯示一條 80% 的線。請注意,如果資料庫是最近建立,或是最近修改了領導者區域,圖表可能不會立即穩定。 這個圖表僅適用於雙區域和多區域執行個體。 |
done |
done |
最高的分割 CPU 用量分數 instance/peak_split_peak |
資料庫中所有分割所觀察到的最高分割 CPU 用量。這項指標會顯示在分割中使用的處理單元資源百分比。如果百分比超過 50%,表示分割區很熱門,也就是分割區正在使用主機伺服器一半的處理單元資源。百分比為 100% 代表分割相當熱門,也就是分割正在使用主機伺服器的大部分處理單元資源。Spanner 會依負載進行分割,解決熱點問題並平衡負載。不過,由於應用程式中的模式有問題,即使多次嘗試分割,Spanner 可能仍無法平衡負載。因此,如果熱點持續至少 10 分鐘,可能需要進一步疑難排解,甚至可能需要變更應用程式。詳情請參閱找出分割中的熱點。 | done |
done |
|
遠端服務呼叫 query_stat/total/remote_service_calls_count |
遠端服務呼叫數量,按照服務和回應代碼分組。 回應 HTTP 回應碼,例如 200 或 500。 |
done |
done |
|
延遲時間:遠端服務呼叫 query_stat/total/remote_service_calls_latencies |
遠端服務呼叫的延遲時間,按照服務分組。 您可以使用選項清單,查看第 50 和第 99 個百分位數的延遲時間指標。 |
done |
done |
|
遠端服務處理的資料列 query_stat/total/remote_service_processed_rows_count |
遠端服務處理的資料列數,按照服務人員和回應代碼分組。 以 HTTP 回應碼 (例如 200 或 500) 回應。 |
done |
done |
|
延遲時間:遠端服務資料列 query_stat/total/remote_service_processed_rows_latencies |
遠端服務處理的資料列數,按照服務和回應代碼分組。 您可以使用選項清單,查看第 50 和第 99 個百分位數的延遲指標。 |
done |
done |
|
遠端服務網路位元組數 query_stat/total/remote_service_network_bytes_sizes |
與遠端服務交換的網路位元組數,按照服務和方向分組。 這個值是以二進位位元組計算,例如 KiB、MiB 或 GiB。 方向是指傳送或接收的流量。 您可以使用選項清單,查看網路位元組交換的第 50 和第 99 個百分位數指標。 |
done |
done |
|
微服務呼叫 query_stat/total/remote_service_calls_count |
微服務呼叫的數量,按照微服務和回應代碼分組。 | done |
done |
|
延遲時間:微服務呼叫 query_stat/total/remote_service_calls_latencies |
微服務呼叫的延遲時間,按照微服務分組。 | done |
done |
資料庫儲存空間 (以資料表分組) (無) |
執行個體或資料庫中儲存的資料量,以所選資料庫中的資料表分組。 這個值是以二進位位元組為單位,例如 KiB、MiB 或 GiB。 這個圖表會查詢 SPANNER_SYS.TABLE_SIZES_STATS_1HOUR,詳情請參閱「
資料表大小統計資料」。 |
close |
done |
最常用的資料表 (以作業分組) (無) |
執行個體或資料庫中最常用的 15 個資料表和索引,判斷依據為讀取、寫入或刪除作業的數量。 這張圖表會查詢資料表作業統計資料表,藉此取得資料。 詳情請參閱「 資料表作業統計資料」。 |
close |
done |
最少使用的資料表 (以作業分組) (無) |
執行個體或資料庫中,使用次數最少的 15 個資料表和索引,判斷依據為讀取、寫入或刪除作業的次數。 這張圖表會查詢資料表作業統計資料表,藉此取得資料。 詳情請參閱「 資料表作業統計資料」。 |
close |
done |
代管式自動調度資源圖表和指標
除了上一節顯示的選項外,如果執行個體已啟用代管自動調度器,運算容量圖表會顯示「查看記錄」按鈕。按一下這個按鈕,即可查看受管理自動配置器的記錄。
如果執行個體已啟用受管理自動調度器,則可使用下列指標。
| 指標名稱和類型 | 說明 |
|---|---|
| 運算容量 | 選取節點。 |
|
instance/autoscaling/min_node_count |
自動配置器設定要分配給執行個體的節點數量下限。 |
|
instance/autoscaling/max_node_count |
自動調度器設定分配給執行個體的節點數量上限。 |
|
instance/autoscaling/recommended_node_count_for_cpu |
根據執行個體的 CPU 用量,建議的節點數量。 |
|
instance/autoscaling/recommended_node_count_for_storage |
根據執行個體的儲存空間用量,建議的節點數量。 |
| 運算容量 | 選取處理單元。 |
|
instance/autoscaling/min_processing_units |
自動配置器設定要分配給執行個體的處理單元數量下限。 |
|
instance/autoscaling/max_processing_units |
自動調度器可分配給執行個體的處理單元數量上限。 |
|
instance/autoscaling/recommended_processing_units_for_cpu |
建議的處理單元數量。這項建議是根據執行個體先前的 CPU 使用量而定。 |
|
instance/autoscaling/recommended_processing_units_for_storage |
建議使用的處理單元數量。這項建議是根據執行個體先前的儲存空間用量而定。 |
| 依優先順序顯示 CPU 使用率 | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
用於自動調度資源的高優先順序 CPU 使用率目標。 |
| 儲存空間總容量 | 選取處理單元。 |
|
instance/storage/limit_bytes |
執行個體的儲存空間上限,以位元組為單位。 |
|
instance/autoscaling/storage_utilization_target |
用於自動調度資源的儲存空間使用率目標。 |
分層儲存空間圖表和指標
使用分層儲存空間的執行個體可使用下列指標。
| 指標名稱和類型 | 說明 |
|---|---|
| instance/storage/used_bytes | 儲存在 SSD 和 HDD 儲存空間的資料總位元組數。 |
| instance/storage/combined/limit_bytes | SSD 和 HDD 儲存空間的總限制。 |
| instance/storage/combined/limit_per_processing_unit | 每個處理單元的 SSD 和 HDD 儲存空間總限制。 |
| instance/storage/combined/utilization | 與儲存空間總量上限相比,SSD 和 HDD 儲存空間的總使用量。 |
| instance/disk_load | HDD 負載用量。 |
資料保留
系統洞察資訊主頁上多數指標的資料保留期限上限為 6 週。不過,在「資料表資料庫儲存空間」圖表中,資料是從資料表 (而非 Spanner) 取用,最多保留 30 天。SPANNER_SYS.TABLE_SIZES_STATS_1HOUR詳情請參閱「資料保留」。
查看系統洞察資訊主頁
如要查看系統洞察頁面,除了Spanner 權限,以及執行個體和資料庫層級的 Spanner 權限外,您還需要下列身分與存取權管理 (IAM) 權限:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
如要進一步瞭解 Spanner IAM 權限,請參閱「使用 IAM 控管存取權」。
如果您在執行個體上啟用代管自動調度器,您也需要 logging.logEntries.list、logging.logs.list 和 logging.logServices.list 權限,才能查看代管自動調度器記錄。
如要進一步瞭解這項權限,請參閱預先定義的角色。
如要查看系統洞察資訊主頁,請按照下列步驟操作:
在 Google Cloud 控制台中,開啟 Spanner 執行個體清單。
執行下列其中一個步驟:
如要查看執行個體的指標,請按一下要瞭解的執行個體名稱,然後在導覽選單中點選「系統洞察」。
如要查看資料庫的指標,請按一下執行個體名稱,選取資料庫,然後按一下導覽選單中的「系統洞察」。
選用:如要查看其他時間範圍的歷史資料,請找出頁面右上方的按鈕,然後點選要查看的時間範圍。
選用:如要控管圖表中顯示的資料,請按一下圖表中的其中一個清單。舉例來說,如果執行個體使用雙區域或多區域設定,部分圖表會提供清單,方便您查看特定區域的資料。並非所有圖表都有清單檢視畫面。
後續步驟
- 瞭解 Spanner 的 CPU 使用率和延遲指標。
- 使用 Monitoring 設定自訂圖表和快訊。
- 進一步瞭解各類 Spanner 執行個體。