このページでは、Google Cloud コンソールを使用して Spanner データベースをエクスポートする方法について説明します。
REST API または Google Cloud CLI を使用して Spanner データベースをエクスポートするには、このページのはじめにの手順を完了し、Dataflow ドキュメントの Spanner to Cloud Storage Avro で詳細な手順を確認してください。エクスポート プロセスでは、Dataflow を使用して、Cloud Storage バケット内のフォルダにデータを書き込みます。処理後のフォルダには、一連の Avro ファイルと JSON マニフェスト ファイルが格納されます。
始める前に
Spanner データベースをエクスポートするには、まず Spanner、Cloud Storage、Compute Engine、Dataflow API を有効にする必要があります。
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
また、十分な割り当てと必須の IAM 権限も必要です。
割り当て要件
エクスポート ジョブの割り当て要件は次のとおりです。
- Spanner: データベースをエクスポートするために追加のコンピューティング容量は必要ありませんが、ジョブが妥当な時間内に終了するようにコンピューティング容量の追加が必要になる場合があります。詳細については、ジョブを最適化するをご覧ください。
- Cloud Storage: エクスポートするには、エクスポートされたファイル用にバケットを作成する必要があります(まだない場合)。この操作は、 Google Cloud コンソールの Cloud Storage ページで行うことができます。また、Spanner ページでエクスポートを作成するときに行うこともできます。バケットのサイズを設定する必要はありません。
- Dataflow: エクスポート ジョブは、他の Dataflow ジョブと同じ CPU、ディスク使用量、IP アドレスの Compute Engine の割り当てに従います。
Compute Engine: エクスポート ジョブを実行する前に、Dataflow によって使用される Compute Engine の初期割り当てを設定する必要があります。これらの割り当ては、Dataflow でジョブに使用できる最大リソース数を表します。推奨の開始値は次のとおりです。
- CPU: 200
- 使用中の IP アドレス: 200
- 標準永続ディスク: 50 TB
通常、他の調整は必要ありません。Dataflow では自動スケーリングが提供されているため、エクスポート中に実際に使用したリソースに対してのみ料金を支払います。ジョブでより多くのリソースが使用される可能性がある場合、Dataflow UI に警告アイコンが表示されます。警告アイコンが表示されてもジョブは完了します。
必要なロール
データベースのエクスポートに必要な権限を取得するには、Dataflow ワーカーのサービス アカウントに対して次の IAM ロールを付与するよう管理者に依頼します。
- Cloud Spanner 閲覧者(
roles/spanner.viewer) - Dataflow ワーカー(
roles/dataflow.worker) -
ストレージ管理者(
roles/storage.admin) - Spanner データベース読み取り(
roles/spanner.databaseReader) - データベース管理者(
roles/spanner.databaseAdmin)
エクスポート中に Spanner Data Boost の独立したコンピューティング リソースを使用するには、spanner.databases.useDataBoost IAM 権限も必要です。詳細については、Data Boost の概要をご覧ください。
データベースをエクスポートする
上記の割り当て要件と IAM 要件を満たすと、既存の Spanner データベースをエクスポートできます。
Spanner データベースを Cloud Storage バケットにエクスポートするには、次の操作を行います。
Spanner の [インスタンス] ページに移動します。
データベースが含まれているインスタンスの名前をクリックします。
左側のペインで [インポート / エクスポート] メニュー項目をクリックし、[エクスポート] ボタンをクリックします。
[エクスポートの保存場所を選択] で、[参照] をクリックします。
エクスポート用の Cloud Storage バケットがない場合は、次の操作を行います。
- [新しいバケット]
 をクリックします。
をクリックします。 - バケットの名前を入力します。バケット名は、Cloud Storage 全体で一意であることが必要です。
- デフォルトのストレージ クラスとロケーションを選択し、[作成] をクリックします。
- バケットをクリックして選択します。
すでにバケットがある場合は、初期リストからバケットを選択するか、[検索]
 をクリックしてリストをフィルタリングしてから、バケットをクリックして選択します。
をクリックしてリストをフィルタリングしてから、バケットをクリックして選択します。- [新しいバケット]
[選択] をクリックします。
[エクスポートするデータベースを選択] プルダウン メニューで、エクスポートするデータベースを選択します。
(省略可)過去の時点のデータベースをエクスポートするには、チェックボックスをオンにしてタイムスタンプを入力します。
[エクスポート ジョブのリージョンを選択] プルダウン メニューで、リージョンを選択します。
省略可: 顧客管理の暗号鍵を使用して Dataflow パイプラインの状態を暗号化するには:
- [暗号化オプションを表示する] をクリックします。
- [顧客管理の暗号鍵(CMEK)を使用する] を選択します。
- プルダウン リストから鍵を選択します。
このオプションは、移行先の Cloud Storage バケットレベルの暗号化には影響しません。Cloud Storage バケットの CMEK を有効にするには、Cloud Storage で CMEK を使用するをご覧ください。
省略可: Spanner Data Boost を使用してエクスポートするには、[Spanner Data Boost を使用する] チェックボックスをオンにします。詳細については、Data Boost の概要をご覧ください。
[料金を確認] にあるチェックボックスをオンにして、既存の Spanner インスタンスによって発生する料金以外に料金が発生することを確認します。
[エクスポート] をクリックします。
Google Cloud コンソールに [Database Import/Export] ページが表示されます。このページのインポート / エクスポート ジョブのリストに、ジョブの経過時間など、エクスポート ジョブの項目が表示されます。
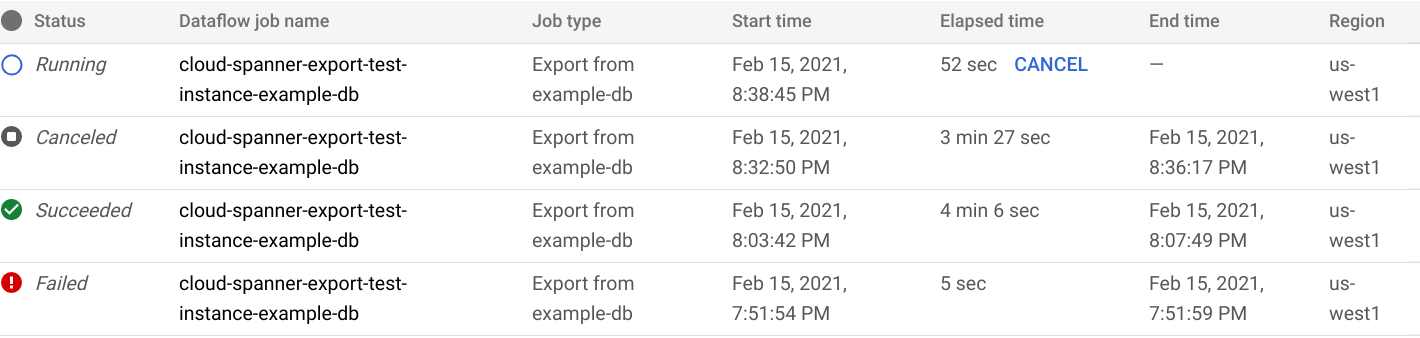
ジョブが完了または終了すると、インポート / エクスポート リストでステータスが更新されます。ジョブが成功すると、「完了」ステータスが表示されます。

ジョブが失敗した場合、「失敗」ステータスが表示されます。

ジョブの Dataflow オペレーションの詳細を表示するには、[Dataflow ジョブ名] 列でジョブの名前をクリックします。
ジョブが失敗した場合は、エラーの詳細についてジョブの Dataflow ログを確認します。
失敗したエクスポート ジョブで作成されたファイルに関する Cloud Storage の料金を回避するには、フォルダとそのファイルを削除します。フォルダの検索方法については、エクスポートを表示するをご覧ください。
生成された列と変更ストリームのエクスポートに関する注意事項
保存済みの生成された列の値はエクスポートされません。列定義は、null 型のレコード フィールドとして Avro スキーマにエクスポートされ、列定義はフィールドのカスタム プロパティとして指定されます。新しく追加される生成された列のバックフィル操作が完了するまで、生成された列はスキーマに存在しないものとして無視されます。
Avro ファイルとしてエクスポートされた変更ストリームには、変更ストリームのスキーマのみが含まれ、データ変更レコードは含まれません。
シーケンスのエクスポートに関する注意事項
シーケンス(GoogleSQL、PostgreSQL)は、一意の整数値の生成に使用するスキーマ オブジェクトです。Spanner は、各スキーマ オブジェクトをレコード フィールドとして Avro スキーマにエクスポートし、シーケンスの種類、スキップ範囲、カウンタをフィールドのプロパティとして使用します。インポート後にシーケンスがリセットされ、重複値の生成を回避するため、スキーマのエクスポート中に、GET_INTERNAL_SEQUENCE_STATE()(GoogleSQL、PostgreSQL)関数によってシーケンス カウンタがキャプチャされます。Spanner はカウンタに 1,000 のバッファを追加し、新しいカウンタ値をレコード フィールドに書き込みます。このアプローチにより、インポート後に発生する可能性のある値の重複エラーを回避できます。データ エクスポート中にソース データベースへの書き込みが増加した場合は、ALTER SEQUENCE(GoogleSQL、PostgreSQL)ステートメントを使用して実際のシーケンス カウンタを調整する必要があります。
インポート時に、シーケンスはスキーマで見つかったカウンタではなく、この新しいカウンタから開始されます。また、ALTER SEQUENCE(GoogleSQL、PostgreSQL)ステートメントを使用し、新しいカウンタでシーケンスを更新することもできます。
Cloud Storage でエクスポートを表示する
エクスポートしたデータベースが格納されたフォルダをGoogle Cloud コンソールで表示するには、Cloud Storage ブラウザに移動し、前に選択したバケットを選択します。
バケットには、エクスポートしたデータベースが格納されたフォルダが含まれています。フォルダ名は、インスタンスの ID、データベース名、エクスポート ジョブのタイムスタンプで始まります。フォルダには以下が含まれています。
spanner-export.jsonファイル- エクスポートしたデータベースの各テーブルの
TableName-manifest.jsonファイル。 1 つ以上の
TableName.avro-#####-of-#####ファイル。拡張子.avro-#####-of-#####の最初の数字は 0 から始まる Avro ファイルのインデックスを表します。2 番目の数字は各テーブルに対して生成された Avro ファイルの数を表します。たとえば、
Songs.avro-00001-of-00002は、Songsテーブルのデータを含む 2 つのファイルのうちの 2 番目のファイルです。エクスポートしたデータベースの変更ストリームごとの
ChangeStreamName-manifest.jsonファイル。変更ストリームごとに 1 つの
ChangeStreamName.avro-00000-of-00001ファイル。このファイルには、変更ストリームの Avro スキーマのみを含む空のデータが含まれています。
インポート ジョブのリージョンを選択する
Cloud Storage バケットのロケーションに基づいて、別のリージョンを選択する場合があります。アウトバウンド データ転送料金が発生しないようにするには、Cloud Storage バケットのロケーションと一致するリージョンを選択します。
Cloud Storage バケットのロケーションがリージョンである場合、リージョンが利用可能であれば、インポート ジョブに同じリージョンを選択することで、無料のネットワーク使用量を利用できます。
Cloud Storage バケットのロケーションがデュアルリージョンである場合、いずれかのリージョンが使用可能であるならば、インポート ジョブにデュアルリージョンを構成する 2 つのリージョンのいずれかを選択して、無料のネットワーク使用量を利用できます。
- 併置リージョンがインポート ジョブで利用できない場合、または Cloud Storage バケットのロケーションがマルチリージョンである場合は、アウトバウンド データ転送料金が適用されます。データ転送料金が最も低いリージョンを選択するには、Cloud Storage のデータ転送の料金をご覧ください。
テーブルのサブセットをエクスポートする
データベース全体ではなく、特定のテーブルのデータのみをエクスポートする場合は、エクスポート時にそのテーブルを指定できます。この場合、Spanner は、指定したテーブルのデータを含むデータベースのスキーマ全体をエクスポートします。他のすべてのテーブルはそのままですが、エクスポート ファイルは空になります。
Google Cloud コンソールの [Dataflow] ページまたは gcloud CLI を使用して、エクスポートするテーブルのサブセットを指定できます([Spanner] ページには、このアクションがありません)。
別のテーブルの子であるテーブルのデータをエクスポートする場合は、その親テーブルのデータもエクスポートする必要があります。親がエクスポートされていない場合、エクスポート ジョブは失敗します。
テーブルのサブセットをエクスポートするには、Dataflow の Cloud Spanner to Cloud Storage Avro テンプレートを使用してエクスポートを開始し、以下で説明するように、 Google Cloud コンソールの [Dataflow] ページまたは gcloud CLI を使用してテーブルを指定します。
コンソール
Google Cloud コンソールの Dataflow ページを使用している場合、Cloud Spanner のテーブル名パラメータは、[テンプレートからジョブを作成] ページの [オプション パラメータ] セクションにあります。複数のテーブルを指定する場合は、カンマ区切り形式で指定します。
gcloud
gcloud dataflow jobs run コマンドを実行し、tableNames 引数を指定します。次に例を示します。
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=table1,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
gcloud で複数のテーブルを指定するには、dictionary タイプの引数のエスケープが必要です。次の例では、| をエスケープ文字として使用しています。
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='^|^instanceId=test-instance|databaseId=example-db|tableNames=table1,table2|outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
shouldExportRelatedTables パラメータは、選択したテーブルのすべての親テーブルを自動的にエクスポートできる便利なオプションです。たとえば、Singers、Albums、Songs テーブルのあるスキーマ階層では Songs を指定するだけですみます。Songs は両方の子孫であるため、shouldExportRelatedTables オプションは Singers と Albums もエクスポートします。
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=Songs,shouldExportRelatedTables=true,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Dataflow UI でのジョブの表示またはトラブルシューティング
エクスポート ジョブの開始後、 Google Cloud コンソールの Dataflow セクションで、ジョブの詳細(ログなど)を表示できます。
Dataflow ジョブの詳細を表示する
現在実行中のジョブを含む過去 1 週間以内のインポートまたはエクスポート ジョブの詳細を表示するには、次の操作を行います。
- データベースの [データベースの概要] ページに移動します。
- 左ペインのメニュー項目 [インポート / エクスポート] をクリックします。データベースの [インポート / エクスポート] ページに、最近のジョブのリストが表示されます。
データベースの [インポート / エクスポート] ページで、[Dataflow ジョブ名] 列のジョブ名をクリックします。
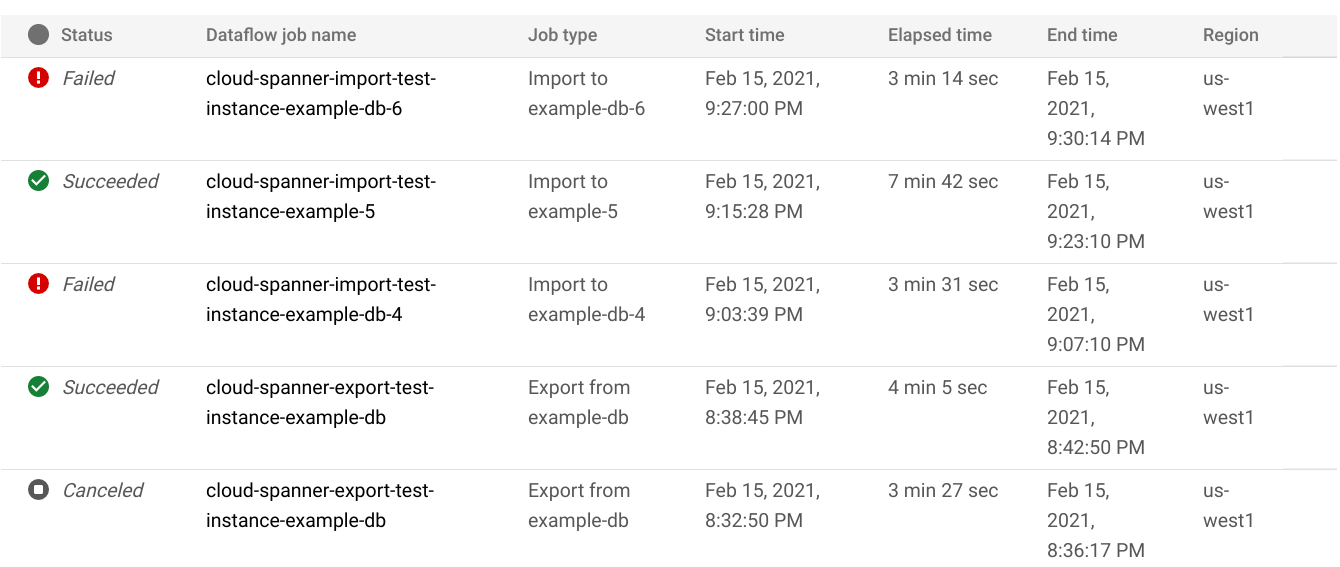
Google Cloud コンソールに Dataflow ジョブの詳細が表示されます。
1 週間以上前に実行したジョブを表示するには:
Google Cloud コンソールの Dataflow ジョブページに移動します。
リスト内でジョブを見つけ、その名前をクリックします。
Google Cloud コンソールに Dataflow ジョブの詳細が表示されます。
ジョブの Dataflow ログを表示する
Dataflow ジョブのログを表示するには、ジョブの詳細ページに移動し、ジョブ名の右側にある [ログ] をクリックします。
ジョブが失敗した場合は、ログでエラーを探します。エラーがある場合、エラー数が [ログ] の横に表示されます。
![[ログ] ボタンの横のエラー数の例](https://cloud-dot-devsite-v2-prod.appspot.com/static/spanner/docs/images/dataflow_error_count.png?hl=ja)
ジョブエラーを表示するには:
[ログ] の横のエラー数をクリックします。
Google Cloud コンソールにジョブのログが表示されます。エラーを表示するには、スクロールが必要な場合があります。
エラーアイコン
 が表示されているエントリを見つけます。
が表示されているエントリを見つけます。個別のログエントリをクリックして、その内容を展開します。
Dataflow ジョブのトラブルシューティングの詳細については、パイプラインをトラブルシューティングするをご覧ください。
失敗したエクスポート ジョブのトラブルシューティング
ジョブログに次のエラーが表示された場合:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Google Cloud コンソールで Spanner データベースの [モニタリング] タブで、99% の読み取りレイテンシを確認します。高い値(数秒)が表示されている場合は、インスタンスが過負荷状態になっており、読み取りがタイムアウトになって失敗します。
レイテンシが高くなる原因の一つは、多すぎるワーカーを使用して Dataflow ジョブが実行しているため、Spanner インスタンスに負荷がかかりすぎることです。
Dataflow ワーカーの数に対する制限を指定するには、 Google Cloud コンソールの Spanner データベースのインスタンス詳細ページで [インポート / エクスポート] タブを使用するのではなく、Dataflow の Spanner to Cloud Storage Avro テンプレートを使用して、次のようにワーカーの最大数を指定します。コンソール
Dataflow コンソールを使用している場合、[最大ワーカー数] パラメータは、[テンプレートからジョブを作成] ページの [オプションのパラメータ] セクションにあります。
gcloud
gcloud dataflow jobs run コマンドを実行し、max-workers 引数を指定します。例:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
ネットワーク エラーのトラブルシューティング
Spanner データベースをエクスポートすると、次のエラーが発生することがあります。
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
このエラーは、Dataflow ジョブと同じプロジェクトで default という名前の自動モード VPC ネットワークを使用する予定であると Spanner が想定しているために発生します。プロジェクト内にデフォルトの VPC ネットワークがない場合や、VPC ネットワークがカスタムモードの VPC ネットワークにある場合は、Dataflow ジョブを作成し、代替のネットワークまたはサブネットワークを指定する必要があります。
実行速度が遅いエクスポート ジョブを最適化する
初期設定の提案に従っている場合は、通常、他の調整は必要ありません。ジョブの実行速度が遅い場合は、その他の最適化を試すことができます。
ジョブとデータのロケーションの最適化: Spanner インスタンスと Cloud Storage バケットが配置されている同じリージョン内で Dataflow ジョブを実行します。
十分な Dataflow リソースの確保: 関連する Compute Engine の割り当てによって Dataflow ジョブのリソースが制限されている場合、 Google Cloud コンソールのジョブの Dataflow ページに警告アイコン
 とログメッセージが表示されます。
とログメッセージが表示されます。
この場合、CPU、使用中の IP アドレス、標準永続ディスクの割り当てを増やすと、ジョブの実行時間が短くなる可能性がありますが、Compute Engine の追加料金が発生する場合があります。
Spanner の CPU 使用率の確認: インスタンスの CPU 使用率が 65% を超えている場合は、そのインスタンスのコンピューティング容量を増やすことができます。容量を追加すると Spanner のリソースが増加し、ジョブの実行速度は速くなりますが、Spanner の追加料金が発生します。
エクスポート ジョブのパフォーマンスに影響する要素
エクスポート ジョブの完了にかかる時間には、いくつかの要素が影響します。
Spanner データベースのサイズ: 処理するデータ量が増加すると、必要となる時間とリソースも多くなります。
Spanner データベース スキーマ: 次のものを含む。
- テーブルの数
- 行のサイズ
- セカンダリ インデックスの数
- 外部キーの数
- 変更ストリームの数
データのロケーション: データは、Dataflow を使用して Spanner と Cloud Storage の間で転送されます。3 つのコンポーネントがすべて同じリージョン内にあることが理想的です。コンポーネントが同じリージョン内にない場合は、リージョン間のデータの移動によってジョブは遅くなります。
Dataflow ワーカーの数: パフォーマンスの向上には、最適な Dataflow ワーカーが必要です。自動スケーリングを使用することにより、Dataflow では、処理する必要がある作業量に応じてジョブのワーカー数が選択されます。ただし、ワーカーの数は CPU、使用中の IP アドレス、標準永続ディスクの割り当てによって制限されます。割り当ての上限に達すると、Dataflow UI に警告アイコンが表示されます。この状況では、進捗は遅くなりますがジョブは完了します。
Spanner に対する既存の負荷: 通常、エクスポート ジョブによって Spanner インスタンスに対する負荷が若干上昇します。インスタンスにすでに相当な負荷がかかっている場合、このジョブの実行速度はさらに遅くなります。
Spanner のコンピューティング容量: インスタンスの CPU 使用率が 65% を超えると、ジョブの実行速度はさらに低下します。