本文說明可匯出 Cloud Monitoring 指標的解決方案,方便您進行長期分析。Cloud Monitoring 提供針對Google Cloud 和 Amazon Web Services (AWS) 的監控解決方案。Cloud Monitoring 會保留指標 6 個星期,因為監控指標中的值通常是有時間限制的。因此,指標記錄中的資料值會隨著時間減少。在 6 個星期過去之後,已匯總指標可能仍然會有可用來進行長期趨勢分析的值,但這些趨勢在短期分析中可能不太明顯。
本解決方案備有指南,協助您瞭解匯出作業的指標詳細資料;另並針對匯出指標到 BigQuery,提供無伺服器參考實作。
《開發運作現狀》報告指出,有哪些功能可提升軟體推送成效。這個解決方案可協助您執行下列功能:
匯出指標的應用實例
Cloud Monitoring 會收集 Google Cloud、AWS 和應用程式檢測設備的指標和中繼資料。您可以透過 API、資訊主頁和 Metrics Explorer 查看 Monitoring 指標資料,深入瞭解雲端應用程式的效能、運作時間和整體健康狀態。這些工具能讓您查看過去 6 個星期的分析用指標值。如有長期指標分析需求,請使用 Cloud Monitoring API 匯出指標資料,以便進行長期儲存。
Cloud Monitoring 會保留過去 6 個星期的指標。這項服務經常用於達成運作目標,例如監控虛擬機器基礎架構 (CPU、記憶體、網路指標) 和應用程式效能指標 (例如要求或回應延遲時間)。如果這些指標超出預先設定的門檻值,系統就會透過快訊觸發特定操作程序。
以長期分析來說,系統擷取的指標可能也相當實用。舉例來說,您可能想要將網購星期一 (Cyber Monday) 或其他高流量事件的應用程式效能指標,與去年的指標比較,好讓您能為下一個高流量事件做準備。另外一種使用案例是,查看整個季度或年份的服務使用情形,以更準確預測成本。 Google Cloud 又或者,您可能也想查看橫跨數月或數年的應用程式效能指標。
在以上使用範例,您都有必要保留長期指標以供分析。而將這些指標匯出到 BigQuery 的做法,為這些範例提供了必要的分析能力。
需求條件
如要對 Monitoring 指標資料執行長期分析,您必須先滿足 3 個主要需求:
- 從 Cloud Monitoring 匯出資料。您必須將 Cloud Monitoring 指標資料匯出為已匯總的指標值。匯總指標資料為必要動作,因為儲存原始的
timeseries資料點在技術上可行,但這並不會帶來更多助益。大多數的長期分析都是在較長時間範圍的匯總層級上進行。每個應用實例的匯總資料精細程度都不同,但建議您至少以 1 小時為匯總時間單位。 - 擷取要分析的資料。您必須將已匯出的 Cloud Monitoring 指標匯入分析引擎,接著才能進行分析。
- 根據資料編寫查詢及建立資訊主頁。您必須取得資訊主頁和標準 SQL 的存取權,才能查詢、分析資料,以及將資料視覺化。
功能性步驟
- 建構要包含在匯出作業中的指標清單。
- 從 Monitoring API 讀取指標。
- 將來自 Monitoring API 的已匯出 JSON 輸出內容的指標,對應到 BigQuery 資料表格式。
- 將指標寫入 BigQuery。
- 建立程式輔助的時間表來定期匯出指標。
架構
這個架構的設計利用代管服務簡化操作及管理工作、降低成本,以及提供依要求進行資源調度的能力。

我們在架構中使用以下技術:
- App Engine:可擴充的平台式服務 (PaaS) 解決方案,可用來呼叫 Monitoring API 及寫入 BigQuery。
- BigQuery:全代管分析引擎,用來擷取及分析
timeseries資料。 - Pub/Sub:全代管即時訊息傳遞服務,用來提供可擴充的非同步處理功能。
- Cloud Storage:開發人員和企業專用的整合式物件儲存空間,用來儲存與匯出狀態相關的中繼資料。
- Cloud Scheduler:Cron 樣式的排程器,用來執行匯出程序。
瞭解 Cloud Monitoring 指標詳細資料
如要瞭解從 Cloud Monitoring 匯出指標資料的最佳方式,您必須先瞭解指標的儲存方式。
指標的類型
您可以匯出的 Cloud Monitoring 指標主要分為 4 種。
- Google Cloud 指標清單: Google Cloud 服務 (例如 Compute Engine 和 BigQuery) 產生的指標。
- 代理程式指標清單:來自執行 Cloud Monitoring 代理程式的 VM 執行個體指標。
- AWS 指標清單:來自 AWS 服務 (例如 Amazon Redshift 和 Amazon CloudFront) 的指標。
- 來自外部來源的指標:來自第三方應用程式的指標,以及使用者定義的指標,包括自訂指標。
這些指標類型中每個都有指標描述元,其中包含指標類型,以及其他的指標中繼資料。以下指標即為列出 Monitoring API projects.metricDescriptors.list 方法中指標描述元的範例。
{
"metricDescriptors": [
{
"name": "projects/sage-facet-201016/metricDescriptors/pubsub.googleapis.com/subscription/push_request_count",
"labels": [
{
"key": "response_class",
"description": "A classification group for the response code. It can be one of ['ack', 'deadline_exceeded', 'internal', 'invalid', 'remote_server_4xx', 'remote_server_5xx', 'unreachable']."
},
{
"key": "response_code",
"description": "Operation response code string, derived as a string representation of a status code (e.g., 'success', 'not_found', 'unavailable')."
},
{
"key": "delivery_type",
"description": "Push delivery mechanism."
}
],
"metricKind": "DELTA",
"valueType": "INT64",
"unit": "1",
"description": "Cumulative count of push attempts, grouped by result. Unlike pulls, the push server implementation does not batch user messages. So each request only contains one user message. The push server retries on errors, so a given user message can appear multiple times.",
"displayName": "Push requests",
"type": "pubsub.googleapis.com/subscription/push_request_count",
"metadata": {
"launchStage": "GA",
"samplePeriod": "60s",
"ingestDelay": "120s"
}
}
]
}
而在該指標描述元中,您必須要瞭解的重要值為 type、valueType 和 metricKind 欄位。這些欄位會找出指標,還會對指標描述元可能進行的匯總作業造成影響。
指標種類
每個指標都有指標種類和值類型。詳情請參閱「值類型和指標種類」。指標種類和相關聯的值類型相當重要,因為這兩者的組合會影響指標資料的匯總方式。
在上述範例中,pubsub.googleapis.com/subscription/push_request_count metric 指標類型具有 DELTA 指標類型和 INT64 值類型。

在 Cloud Monitoring 中,指標種類和值類型都儲存在 metricsDescriptors,您可以利用 Monitoring API 取得。
時間序列
timeseries 是屬於在不同時間點儲存的各指標類型定期測量結果,其包含指標類型、中繼資料、標籤,和個別的已測量資料點。Monitoring 所自動收集的指標,例如Google Cloud 和 AWS 指標,系統會定期採集。舉例來說,系統每 60 秒會收集 appengine.googleapis.com/http/server/response_latencies 指標一次。
根據資料回報的頻率,以及與指標類型相關聯的任何標籤,針對特定 timeseries 所收集的資料點組規模,可能會隨著時間越來越大。如果您匯出原始的 timeseries 資料點,可能會產生大型的匯出內容。如要減少系統傳回的 timeseries 資料點數量,您可以將特定校正週期內的指標匯總。舉例來說,您可以利用匯總功能,讓每分鐘會有 1 個資料點的特定指標 timeseries,變成每小時傳回 1 個資料點。這會降低已匯出資料點的數量,並減少分析引擎中必要的分析處理作業。在本文中,系統會針對每個已選取指標類型傳回 timeseries。
指標匯總
您可以使用匯總功能,將來自數個 timeseries 的資料合併成單一 timeseries。Monitoring API 提供強大的校正和匯總函式,因此您不必執行匯總作業,只要把校正和匯總參數傳遞給 API 呼叫即可。如要進一步瞭解 Monitoring API 匯總功能的運作方式,請參閱「篩選和匯總」和這篇網誌文章。
您可以將 metric type 對應到 aggregation type,以確保指標已經過校正,且 timeseries 的數量已減少為符合您分析作業的需求。我們提供您可以用來匯總 timeseries 的校正函式和縮減函式清單。校正函式和縮減函式有一組指標數,可讓您用來根據指標種類和值類型來校正或縮減。舉例來說,如果您的匯總週期是 1 小時,則匯總結果就是針對 timeseries 每小時傳回 1 個資料點。
還有一種微調匯總作業的方式,那就是使用 Group By 函式,讓您可以把已匯總的值分組成幾個已匯總 timeseries 的清單。舉例來說,您可以選擇根據 App Engine 模組,來為 App Engine 指標分組。只要您根據 App Engine 模組來分組,搭配匯總到 1 小時的校正函式和縮減函式,就能讓每個 App Engine 模組每小時產生 1 個資料點。
記錄個別資料點會提高成本,但保留足夠資料才能進行詳盡的長期分析;在這種情況下,利用指標匯總方式可讓您魚與熊掌兼得。
參考實作詳細資料
這個參考實作包含的元件,與架構設計圖中所述的元件相同。我們將在下方說明每個步驟中的功能性和相關實作詳細資料。
建立指標清單
Cloud Monitoring 定義了超過一千種的指標類型,可協助您監控 Google Cloud、AWS 和第三方軟體。Monitoring API 提供 projects.metricDescriptors.list 方法,能夠傳回 Google Cloud專案的可用指標清單。Monitoring API 提供篩選機制,讓您能篩選想要匯出進行長期儲存和分析的指標清單。
GitHub 中的參考實作使用 Python App Engine 應用程式取得指標清單,然後分別將每個訊息寫入某個 Pub/Sub 主題。匯出作業由 Cloud Scheduler 展開,而 Cloud Scheduler 會產生 Pub/Sub 通知來執行應用程式。
呼叫 Monitoring API 的方法有很多種,而在這個案例中,我們是利用 適用於 Python 的 Google API 用戶端程式庫呼叫 Cloud Monitoring 和 Pub/Sub API,因為該程式庫可以彈性存取 Google API。
取得時間序列
您將擷取指標的 timeseries,然後將每個 timeseries 寫入 Pub/Sub。有了 Monitoring API,您就能利用 project.timeseries.list 方法匯總在特定校正時間範圍內產生的指標值。將資料匯總可減少您的資料處理負載、儲存空間需求、查詢時間和分析成本。要有效率地進行長期指標分析的最佳做法,就是將資料匯總。
GitHub 中的參考實作使用 Python App Engine 應用程式訂閱主題,而每個匯出指標都會被當做個別訊息傳送到該主題。對於收到的每則訊息,Pub/Sub 會將訊息推送至 App Engine 應用程式。應用程式會根據輸入設定匯總特定指標的 timeseries。在這個案例中,我們是使用 Google API 用戶端程式庫呼叫 Cloud Monitoring 和 Pub/Sub API。
每項指標都能傳回一或多個 timeseries. 每項指標都會透過個別的 Pub/Sub 訊息傳送,以便插入 BigQuery。參考實作已內建指標 type-to-aligner 和指標 type-to-reducer 的對應。以下表格根據校正函式及縮減函式所支援的指標種類和值類型類別,擷取參考實作所用的對應。
| 值類型 | GAUGE |
校正函式 | 縮減函式 | DELTA |
校正函式 | 縮減函式 | CUMULATIVE2 |
校正函式 | 縮減函式 |
|---|---|---|---|---|---|---|---|---|---|
BOOL |
是 |
ALIGN_FRACTION_TRUE
|
無 | 否 | 不適用 | 不適用 | 否 | 不適用 | 不適用 |
INT64 |
是 |
ALIGN_SUM
|
無 | 是 |
ALIGN_SUM
|
無 | 是 | 無 | 無 |
DOUBLE |
是 |
ALIGN_SUM
|
無 | 是 |
ALIGN_SUM
|
無 | 是 | 無 | 無 |
STRING |
是 | 已排除 | 已排除 | 否 | 不適用 | 不適用 | 否 | 不適用 | 不適用 |
DISTRIBUTION |
是 |
ALIGN_SUM
|
無 | 是 |
ALIGN_SUM
|
無 | 是 | 無 | 無 |
MONEY |
否 | 不適用 | 不適用 | 否 | 不適用 | 不適用 | 否 | 不適用 | 不適用 |
請務必考慮將 valueType 對應到校正函式和縮減函式,因為只有在每個校正函式和縮減函式都有特定的 valueTypes 和 metricKinds 時,匯總作業才有可能執行。
例如,請考量 pubsub.googleapis.com/subscription/push_request_count metric 類型。根據 DELTA 指標種類和 INT64 值類型,您唯一能匯總指標的方式就是:
- 校正週期:3600 秒 (1 小時)
Aligner = ALIGN_SUM:在校正週期中產生的資料點,就是該校正週期中所有資料點的總和。Reducer = REDUCE_SUM:藉由計算每個校正週期的timeseries總和來縮減。
除了校正週期、校正函式和縮減函式的值以外,project.timeseries.list 方法還需要其他幾項輸入內容:
filter:選取要傳回的指標。startTime:選取要傳回timeseries的起始時間點。endTime:選取要傳回timeseries的最終時間點。groupBy:輸入做為timeseries回應分組依據的欄位。alignmentPeriod:輸入您希望指標校正的時間週期。perSeriesAligner:將資料點校正到由alignmentPeriod定義的對等時間間隔。crossSeriesReducer:把擁有不同標籤值的數個資料點,合併成每個時間間隔 1 個資料點。
對於 API 的 GET 要求包含在以上清單中所述的所有參數。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=START_TIME_VALUE&
interval.endTime=END_TIME_VALUE&
aggregation.alignmentPeriod=ALIGNMENT_VALUE&
aggregation.perSeriesAligner=ALIGNER_VALUE&
aggregation.crossSeriesReducer=REDUCER_VALUE&
filter=FILTER_VALUE&
aggregation.groupByFields=GROUP_BY_VALUE
以下 HTTP GET 利用輸入參數,提供針對 projects.timeseries.list API 方法的呼叫範例:
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z&
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
aggregation.crossSeriesReducer=REDUCE_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+&
aggregation.groupByFields=metric.labels.key
上述 Monitoring API 呼叫包含 crossSeriesReducer=REDUCE_SUM,代表系統已收合各個指標,並縮減成單一總和,如以下範例所示。
{
"timeSeries": [
{
"metric": {
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"resource": {
"type": "pubsub_subscription",
"labels": {
"project_id": "sage-facet-201016"
}
},
"metricKind": "DELTA",
"valueType": "INT64",
"points": [
{
"interval": {
"startTime": "2019-02-08T14:00:00.311635Z",
"endTime": "2019-02-08T15:00:00.311635Z"
},
"value": {
"int64Value": "788"
}
}
]
}
]
}
這個匯總層級會把資料匯總成單一資料點,使該資料點成為最適合您整體 Google Cloud 專案的指標。然而,這個資料點卻無法讓您深入瞭解是哪些資源造就了這個指標。在上述範例中,您無法分辨在要求數中,哪個 Pub/Sub 訂閱占比最大。
如果您要查看產生 timeseries 的個別元件詳細資料,請移除 crossSeriesReducer 參數。沒有 crossSeriesReducer 時,Monitoring API 不會合併各個 timeseries 來建立單一值。
以下 HTTP GET 利用輸入參數,提供針對 projects.timeseries.list API 方法的呼叫範例,但其中並不包含 crossSeriesReducer。
https://monitoring.googleapis.com/v3/projects/sage-facet-201016/timeSeries?
interval.startTime=2019-02-19T20%3A00%3A01.593641Z&
interval.endTime=2019-02-19T21%3A00%3A00.829121Z
aggregation.alignmentPeriod=3600s&
aggregation.perSeriesAligner=ALIGN_SUM&
filter=metric.type%3D%22kubernetes.io%2Fnode_daemon%2Fmemory%2Fused_bytes%22+
在以下的 JSON 回應中,metric.labels.keys 在兩個結果中都是相同的,這是因為 timeseries 已經分組。系統會針對每個 resource.labels.subscription_ids 值傳回個別的資料點。請查看下列 JSON 中的 metric_export_init_pub 和 metrics_list 值。我們建議您使用這個匯總層級,因為它可讓您在 BigQuery 查詢中使用已包含為資源標籤的Google Cloud 產品。
{
"timeSeries": [
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "1"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metric_export_init_pub"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
},
{
"metric": {
"labels": {
"delivery_type": "gae",
"response_class": "ack",
"response_code": "success"
},
"type": "pubsub.googleapis.com/subscription/push_request_count"
},
"metricKind": "DELTA",
"points": [
{
"interval": {
"endTime": "2019-02-19T21:00:00.829121Z",
"startTime": "2019-02-19T20:00:00.829121Z"
},
"value": {
"int64Value": "803"
}
}
],
"resource": {
"labels": {
"project_id": "sage-facet-201016",
"subscription_id": "metrics_list"
},
"type": "pubsub_subscription"
},
"valueType": "INT64"
}
]
}
projects.timeseries.list API 呼叫的 JSON 輸出內容各指標,系統都直接寫入 Pub/Sub 做為個別訊息。但這可能會產生擴散傳遞的情況,也就是 1 個輸入指標產生 1 或多個 timeseries。Pub/Sub 可在不逾時的情況下,承擔潛在的大型擴散傳遞。
將校正週期做為輸入項目來提供,代表該時間範圍內的各個值已經匯總成單一值,如以上回應範例中所示。校正週期也定義了匯出作業的執行頻率。舉例來說,如果您的校正週期為 3600 秒或 1 小時,則匯出作業會每個小時執行一次來定期匯出 timeseries。
儲存指標
GitHub 中的參考實作使用 Python App Engine 應用程式讀取每個 timeseries,然後將記錄插入 BigQuery 資料表中。Pub/Sub 會把收到的每個訊息推送給 App Engine 應用程式。Pub/Sub 訊息包含從 Monitoring API 中匯出,採用 JSON 格式的指標資料,且該訊息也必須對應到 BigQuery 中的資料表結構。在這個案例中,系統利用 Google API 用戶端程式庫來呼叫 BigQuery API。
BigQuery 結構定義被設計成會緊密地對應到從 Monitoring API 匯出的 JSON。當您建構 BigQuery 資料表結構定義時,必須要考慮到資料大小的擴充能力,因為資料會隨時間成長。
在 BigQuery 中,我們建議您根據日期欄位來為資料表分區,因為它能提高查詢的效率,方法就是在不讓系統對資料表進行完整掃描的情況下,選取日期範圍。如果您計劃要定期執行匯出作業,即可安心地根據擷取日期來使用預設的分區功能。

如果您計劃要上傳大量的指標,或是會不定期地執行匯出作業,請根據需要變更 BigQuery 結構定義的 end_time, 來分區。您可以把 end_time 移動到結構定義的某個頂層欄位中,讓您能用來分區;或者,您也可以為結構定義新增欄位。end_time 欄位的移動是必需的,因為該欄位包含在 BigQuery 記錄中,且分區必須根據某個頂層欄位來進行。詳情請參閱 BigQuery 分區說明文件。
BigQuery 也提供讓資料集、資料表和資料表分區在經過一段時間之後到期的功能。

當較舊的資料不再有用時,這功能是讓您清除那些資料的好方法。舉例來說,如果您的分析涵蓋 3 年的時間,即可新增政策來刪除 3 年之前的資料。
安排匯出作業的執行時間
Cloud Scheduler 是全代管的 Cron 工作排程器。Cloud Scheduler 可讓您使用標準的 Cron 排程格式來觸發 App Engine 應用程式、利用 Pub/Sub 來傳送訊息,或是將訊息傳送給任意 HTTP 端點。
在 GitHub 的參考實作中,Cloud Scheduler 藉由傳送擁有與 App Engine 設定相符之代碼的 Pub/Sub 訊息,以便每小時觸發 list-metrics App Engine 應用程式一次。在應用程式設定中,預設的匯總週期為 3600 秒或 1 小時,這與應用程式的觸發頻率相關聯。我們建議您最少 1 小時匯總一次,因為這種頻率可讓您在降低資料量和保留高精確度資料之間取得平衡。如果您使用不同的校正週期,請改變匯出頻率來配合校正週期。參考實作會把最終的 end_time 值儲存在 Cloud Storage 中,並將該值當做接下來的 start_time,除非您已經傳遞 start_time 來做為參數。
以下的 Cloud Scheduler 螢幕截圖呈現了如何使用 Google Cloud 控制台設定 Cloud Scheduler,以便每小時叫用 list-metrics App Engine 應用程式一次。

「Frequency」(頻率) 欄位使用 Cron 樣式的語法,告訴 Cloud Scheduler 執行應用程式的頻率。「Target」(目標) 指定某個已產生的 Pub/Sub 訊息,而「Payload」(酬載)欄位則包含該 Pub/Sub 訊息中的資料。
使用已匯出的指標
現在您只要利用 BigQuery 中的已匯出資料,就能使用標準 SQL 來查詢資料,或是建構資訊主頁,以便將指標中隨時間的趨勢視覺化。
查詢範例:App Engine 延遲
以下查詢會找出某個 App Engine 應用程式的平均延遲指標的最小值、最大值和平均值。metric.type 會找出 App Engine 指標,而標籤能根據 project_id 標籤值來找出 App Engine 應用程式。我們使用 point.value.distribution_value.mean,是因為這個指標是在 Monitoring API 中的 DISTRIBUTION 值,而它會對應到 BigQuery 中的 distribution_value 欄位物件。end_time 欄位會回顧過去 30 天的值。
SELECT
metric.type AS metric_type,
EXTRACT(DATE FROM point.INTERVAL.start_time) AS extract_date,
MAX(point.value.distribution_value.mean) AS max_mean,
MIN(point.value.distribution_value.mean) AS min_mean,
AVG(point.value.distribution_value.mean) AS avg_mean
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'appengine.googleapis.com/http/server/response_latencies'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
GROUP BY
metric_type,
extract_date
ORDER BY
extract_date
查詢範例:BigQuery 查詢數
以下查詢會傳回某個專案中每天針對 BigQuery 的查詢數。我們使用 int64_value 欄位,是因為這個指標是在 Monitoring API 中的 INT64 值,而它會對應到 BigQuery 中的 int64_value 欄位。metric.type 會找出 BigQuery 指標,而標籤能根據 project_id 標籤值來找出專案。end_time 欄位會回顧過去 30 天的值。
SELECT
EXTRACT(DATE FROM point.interval.end_time) AS extract_date,
sum(point.value.int64_value) as query_cnt
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
CROSS JOIN
UNNEST(resource.labels) AS resource_labels
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
and metric.type = 'bigquery.googleapis.com/query/count'
AND resource_labels.key = "project_id"
AND resource_labels.value = "sage-facet-201016"
group by extract_date
order by extract_date
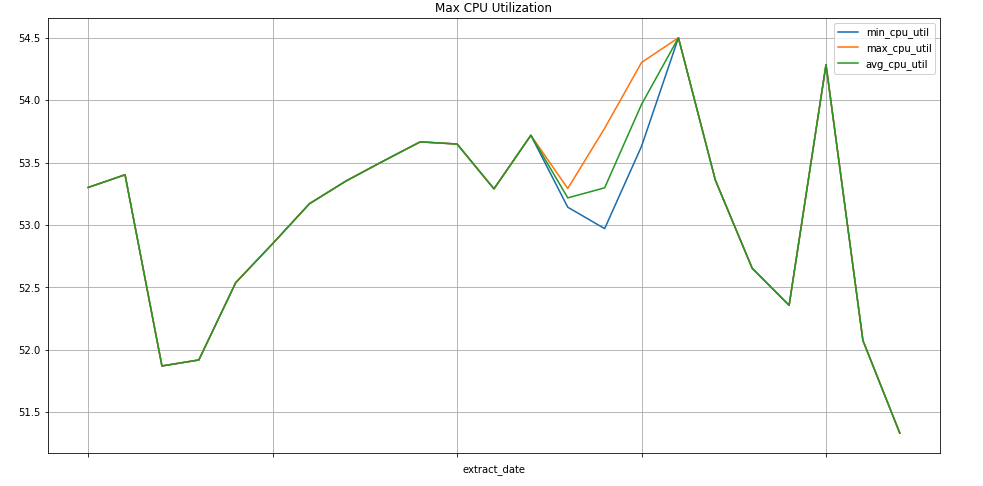
查詢範例:Compute Engine 執行個體
以下查詢會針對某個專案的 Compute Engine 執行個體,尋找 CPU 用量指標值的每星期最小值、最大值和平均值。metric.type 會找出 Compute Engine 指標,而標籤能根據 project_id 標籤值來找出執行個體。end_time 欄位會回顧過去 30 天的值。
SELECT
EXTRACT(WEEK FROM point.interval.end_time) AS extract_date,
min(point.value.double_value) as min_cpu_util,
max(point.value.double_value) as max_cpu_util,
avg(point.value.double_value) as avg_cpu_util
FROM
`sage-facet-201016.metric_export.sd_metrics_export`
WHERE
point.interval.end_time > TIMESTAMP(DATE_SUB(CURRENT_DATE, INTERVAL 30 DAY))
AND point.interval.end_time <= CURRENT_TIMESTAMP
AND metric.type = 'compute.googleapis.com/instance/cpu/utilization'
group by extract_date
order by extract_date
資料視覺化
BigQuery 已經與許多可用來將資料視覺化的工具整合。
Looker Studio 是 Google 建構的免費工具,可讓您建構資料圖表和資訊主頁來將指標資料視覺化,然後與您的團隊分享。以下範例顯示 appengine.googleapis.com/http/server/response_latencies 指標隨時間的延遲和計數趨勢線圖表。

Colaboratory 是用於機器學習教育和研究的研究工具。它是託管的 Jupyter 筆記本環境,不用設定就能使用及存取 BigQuery 中的資料。您只要使用 Colab 筆記本、Python 指令和 SQL 查詢,就能產生詳細的分析和視覺化效果。
監控匯出參考實作
當系統執行匯出作業時,您必須監控匯出作業。而決定要監控哪些指標的方法,就是設置服務等級目標 (SLO)。SLO 就是藉由指標來測量的服務等級目標值或值範圍。網站穩定性工程一書說明 SLO 的主要範圍有 4 種:可用性、總處理量、錯誤率和延遲。對於資料匯出作業來說,總處理量和錯誤率是兩個主要的考量,而您可以透過以下的指標來監控:
- 處理量 -
appengine.googleapis.com/http/server/response_count - 錯誤率 -
logging.googleapis.com/log_entry_count
舉例來說,您可以使用 log_entry_count 指標,並篩選嚴重性為 ERROR 的 App Engine 應用程式 (list-metrics、get-timeseries、write-metrics),藉此監控錯誤率。接著,您可以使用 Cloud Monitoring 中的快訊政策,在匯出應用程式發生錯誤時發出快訊。

快訊 UI 中會顯示一張圖表,方便您比較 log_entry_count 指標與產生快訊的門檻值差距。

後續步驟
- 查看 GitHub 中的實作參考資料。
- 參閱 Cloud Monitoring 說明文件。
- 參閱 Cloud Monitoring v3 API 說明文件。
- 如需更多參考架構、圖表和最佳做法,請瀏覽 雲端架構中心。
- 參閱DevOps相關資源。
進一步瞭解與這項解決方案相關的開發運作功能:
進行開發運作快速檢驗,瞭解貴機構與同業相比的表現。