El almacenamiento de archivos, también conocido como almacenamiento conectado a la red (NAS), proporciona acceso a nivel de archivo a las aplicaciones para leer y actualizar información que se puede compartir entre varias máquinas. Algunas soluciones de almacenamiento de archivos locales tienen una arquitectura de escalabilidad vertical y simplemente añaden almacenamiento a una cantidad fija de recursos de computación. Otras soluciones de almacenamiento de archivos tienen una arquitectura de escalado horizontal en la que la capacidad y la computación (rendimiento) se pueden añadir de forma incremental a un sistema de archivos ya existente según sea necesario. En ambas arquitecturas de almacenamiento, una o varias máquinas virtuales pueden acceder al almacenamiento.
Aunque algunos sistemas de archivos usan un cliente POSIX nativo, muchos sistemas de almacenamiento usan un protocolo que permite a los equipos cliente montar un sistema de archivos y acceder a los archivos como si estuvieran alojados localmente. Los protocolos más habituales para exportar recursos compartidos de archivos son el sistema de archivos de red (NFS) para Linux (y, en algunos casos, Windows) y el bloque de mensajes del servidor (SMB) para Windows.
En este documento se describen las siguientes opciones para compartir archivos:
- Google Cloud Hyperdisk, Persistent Disk o SSD local
- Soluciones gestionadas:
- Soluciones de partners en Google Cloud Marketplace:
Un factor subyacente en el rendimiento y la predictibilidad de todos los servicios de Google Cloud es la pila de red que Google ha desarrollado a lo largo de muchos años. Con Jupiter Fabric, Google ha creado una pila de redes robusta, escalable y estable que puede seguir evolucionando sin afectar a tus cargas de trabajo. A medida que Google mejora y refuerza sus capacidades de red internamente, tu solución de uso compartido de archivos se beneficia del rendimiento adicional.
Una de las funciones de Google Cloud que puede ayudarte a sacar el máximo partido a tu inversión es la posibilidad de especificar tipos de VM personalizados. Al elegir el tamaño de tu archivador, puedes seleccionar la combinación exacta de memoria y CPU para que funcione con un rendimiento óptimo sin estar sobreasignado.
Ten en cuenta que Cloud Storage también es una forma excelente de almacenar petabytes o exabytes de datos con altos niveles de redundancia a un bajo coste, pero Cloud Storage tiene un perfil de rendimiento y una API diferentes a los de los servidores de archivos que se describen en este artículo.
Resumen de las soluciones de servidor de archivos
En la siguiente tabla se resumen las soluciones y las funciones de los servidores de archivos:
| Solución | Conjunto de datos óptimo | Rendimiento | Asistencia gestionada | Protocolos de exportación |
|---|---|---|---|---|
| Filestore Basic | De 1 a 64 TiB | Hasta 1,2 GiB/s | Totalmente gestionado por Google | NFSv3 |
| Filestore Zonal | De 1 a 100 TiB | Hasta 26 GiB/s | Totalmente gestionado por Google | NFSv3 y NFSv4.1 |
| Filestore Regional | De 1 a 100 TiB | Hasta 26 GiB/s | Totalmente gestionado por Google | NFSv3 y NFSv4.1 |
| Managed Lustre | De 18 TiB a 8 PiB | Hasta 1 TB/s | Totalmente gestionado por Google | POSIX |
| NetApp Volumes | De 1 GiB a 1 PiB | De 1 MB/s a 30 GiB/s | Totalmente gestionado por Google | NFSv3, NFSv4.1 y SMB3 |
| Disco persistente de solo lectura | < 64 TB | De 240 a 1200 MBps | No | Adjunto directo |
Discos duraderos y SSD local
Si tienes datos a los que solo necesita acceder una única VM o que no cambian con el tiempo, puedes evitar usar un servidor de archivos por completo usando los discos duraderos que ofrece Compute Engine: Hyperdisk o Persistent Disk. Puedes formatear volúmenes cortos de Hyperdisk y Persistent Disk con un sistema de archivos como Ext4 o XFS, y adjuntarlos a VMs en modo de lectura y escritura o de solo lectura. Esto significa que primero puedes adjuntar un volumen a una instancia, cargarlo con los datos que necesites y, a continuación, adjuntarlo como disco de solo lectura a cientos de VMs simultáneamente. El uso de discos de solo lectura no funciona en todos los casos prácticos, pero puede reducir considerablemente la complejidad en comparación con el uso de un servidor de archivos.
Los discos duraderos ofrecen un rendimiento constante. Todos los volúmenes de Persistent Disk del mismo tamaño (y, en el caso de Persistent Disk SSD, el mismo número de vCPUs) que adjuntes a tu instancia tendrán las mismas características de rendimiento. No es necesario precalentar ni probar los discos antes de usarlos en producción.
El coste de los discos persistentes es fácil de determinar, ya que no hay costes de E/S que tener en cuenta después de aprovisionar el volumen. Los discos persistentes también se pueden cambiar de tamaño cuando sea necesario. De esta forma, puedes empezar con un volumen de bajo coste y baja capacidad, y no tienes que crear instancias ni discos adicionales para aumentar la capacidad.
Si el requisito principal es la capacidad de almacenamiento total, puedes usar discos persistentes estándar de bajo coste. Para obtener el mejor rendimiento y seguir siendo duradero, puedes usar discos persistentes SSD.
Además, es importante que elijas la capacidad de disco persistente de Compute Engine y el número de vCPUs correctos para asegurarte de que los dispositivos de almacenamiento de tu servidor de archivos reciban el ancho de banda de almacenamiento, las IOPS y el ancho de banda de red necesarios. El ancho de banda de la red de las máquinas virtuales depende del tipo de máquina que elijas. Por ejemplo, las VMs A4 tienen un ancho de banda de red máximo de hasta 3600 Gbps. Para obtener más información, consulta la guía de comparación y recursos de las familias de máquinas. Para obtener información sobre cómo optimizar los discos persistentes, consulta Información sobre el rendimiento de los discos persistentes.
Si tus datos son efímeros y requieren una latencia inferior a un milisegundo y un número elevado de operaciones de E/S por segundo (IOPS), puedes aprovechar hasta 9 TB de SSDs locales para obtener un rendimiento extremo. Las unidades SSD locales proporcionan GB/s de ancho de banda y millones de IOPS, y no consumen el ancho de banda de red asignado a tus instancias. Sin embargo, es importante recordar que las unidades SSD locales tienen ciertas desventajas en cuanto a disponibilidad, durabilidad y flexibilidad.
Para obtener más información sobre las opciones de almacenamiento de Compute Engine, consulta el artículo Diseñar una estrategia de almacenamiento óptima para tu carga de trabajo en la nube.
Aspectos que debes tener en cuenta al elegir una solución de almacenamiento de archivos
Para elegir una solución de almacenamiento de archivos, debes sopesar la facilidad de gestión, el coste, el rendimiento y la escalabilidad. Tomar la decisión es más fácil si tienes una carga de trabajo bien definida, lo que no suele ser el caso. En los casos en los que las cargas de trabajo evolucionan con el tiempo o son muy variables, es recomendable sacrificar el ahorro de costes en favor de la flexibilidad y la elasticidad para que la solución se adapte a tus necesidades. Por otro lado, si tienes una carga de trabajo temporal y conocida, puedes crear una arquitectura de almacenamiento de archivos diseñada específicamente para tus necesidades inmediatas, que puedes desmantelar y volver a crear.
Una de las primeras decisiones que debes tomar es si quieres pagar por un servicio de almacenamiento gestionado, una solución que incluya asistencia para el producto o una solución sin asistencia.
- Los servicios de almacenamiento de archivos gestionados son los más fáciles de usar, ya que Google o un partner se encargan de todas las operaciones. Estos servicios pueden incluso proporcionar un acuerdo de nivel de servicio (ANS) de disponibilidad, como la mayoría de los demás servicios de Google Cloud .
- Las soluciones no gestionadas, pero compatibles, ofrecen más flexibilidad. Los partners pueden ayudar con cualquier problema, pero el funcionamiento diario de la solución de almacenamiento depende del usuario.
- Las soluciones no compatibles requieren el mayor esfuerzo para implementarse y mantenerse, y dejan todos los problemas al usuario. Estas soluciones no se tratan en este documento.
La siguiente decisión consiste en determinar los requisitos de durabilidad y disponibilidad de la solución. La mayoría de las soluciones de archivos son zonales y no ofrecen protección de forma predeterminada si la zona falla. Por lo tanto, es importante plantearse si se necesita una solución de recuperación tras fallos que proteja frente a fallos de zona. También es importante conocer los requisitos de la aplicación en cuanto a durabilidad y disponibilidad. Por ejemplo, la elección de SSDs locales o discos persistentes en tu implementación tiene un gran impacto, al igual que la configuración del software de la solución de archivos. Cada solución requiere una planificación cuidadosa para conseguir una alta durabilidad y disponibilidad, e incluso protección frente a fallos zonales y regionales.
Por último, ten en cuenta las ubicaciones (es decir, las zonas, las regiones y los centros de datos locales) en las que necesitas acceder a los datos. Las ubicaciones de las granjas de servidores que acceden a tus datos influyen en tu elección de solución de archivador, ya que solo algunas soluciones permiten el acceso híbrido local y en la nube.
Soluciones de almacenamiento de archivos gestionadas
En esta sección se describen las soluciones gestionadas por Google para el almacenamiento de archivos.
Filestore Basic
Las instancias Básicas de Filestore son adecuadas para compartir archivos, desarrollar software y cargas de trabajo de GKE. Puedes elegir entre HDD o SSD para almacenar datos. Las SSD ofrecen un mejor rendimiento. Con cualquiera de las dos opciones, la capacidad se amplía de forma incremental y puedes proteger los datos mediante copias de seguridad.
Filestore Zonal
Filestore Zonal simplifica el almacenamiento empresarial y la gestión de datos en Google Cloud y en nubes híbridas. Filestore Zonal ofrece un acceso paralelo de alto rendimiento y rentable a los datos globales, al tiempo que mantiene una coherencia estricta gracias a un sistema de archivos distribuido y escalable de forma dinámica. Con Filestore Zonal, las aplicaciones NFS y los flujos de trabajo NAS se pueden ejecutar en la nube sin necesidad de refactorización, pero conservando las ventajas de los servicios de datos empresariales (por ejemplo, las instantáneas y las copias de seguridad). El controlador CSI de Filestore permite que las cargas de trabajo contenerizadas persistan, se porten y se compartan los datos de forma fluida.
Puedes escalar las instancias zonales de Filestore bajo demanda. De esta forma, puedes crear y ampliar la infraestructura del sistema de archivos cuando sea necesario, lo que garantiza que el rendimiento y la capacidad de almacenamiento siempre se ajusten a los requisitos dinámicos de tu flujo de trabajo. A medida que se amplía un clúster zonal de Filestore, el rendimiento de los metadatos y de las E/S se escala de forma lineal. Este escalado te permite mejorar y acelerar una amplia gama de flujos de trabajo que requieren muchos datos, como la computación de alto rendimiento, las analíticas, la agregación de datos entre sitios, DevOps y muchos más. Por lo tanto, Filestore Zonal es ideal para usarlo en sectores centrados en los datos, como las ciencias biológicas (por ejemplo, la secuenciación del genoma), los servicios financieros y los medios audiovisuales y el entretenimiento.
Para proteger aún más los datos críticos, Filestore Zonal también te permite hacer y conservar instantáneas periódicas, crear copias de seguridad y replicar en otra región. Con Filestore, puedes recuperar un archivo concreto o un sistema de archivos completo en menos de 10 minutos desde cualquiera de los puntos de recuperación anteriores.
Filestore Regional
Filestore Regional es una solución de NFS nativa de la nube totalmente gestionada que te permite desplegar aplicaciones críticas basadas en archivos en Google Cloud, respaldada por un acuerdo de nivel de servicio que ofrece una disponibilidad regional del 99,99 %. Filestore Regional, que ofrece un acuerdo de nivel de servicio con una disponibilidad regional del 99,99 %, está diseñado para aplicaciones que requieren una alta disponibilidad. Con solo unos clics del ratón (o unos cuantos comandos de gcloud o llamadas a la API), puedes aprovisionar recursos compartidos de NFS que se replican de forma síncrona en tres zonas de una región. Si alguna zona de la región deja de estar disponible, Filestore Regional seguirá proporcionando datos de forma transparente a la aplicación sin necesidad de intervención operativa.
Para proteger aún más los datos críticos, Filestore Regional también te permite hacer y conservar capturas periódicas, crear copias de seguridad y replicar en otra región. Con Filestore, puedes recuperar un archivo concreto o un sistema de archivos completo en menos de 10 minutos desde cualquiera de los puntos de recuperación anteriores.
Para proteger aún más los datos críticos, Filestore también te permite hacer y conservar copias periódicas del sistema de archivos. Con Filestore, puedes recuperar un archivo concreto o un sistema de archivos completo en menos de 10 minutos desde cualquiera de los puntos de recuperación anteriores.
En el caso de las aplicaciones críticas, como SAP, tanto la base de datos como los niveles de aplicación deben tener una alta disponibilidad. Para cumplir este requisito, puedes implementar el nivel de base de datos de SAP en Google Cloud Hyperdisk Extreme, en varias zonas mediante la alta disponibilidad de la base de datos integrada. Del mismo modo, el nivel de aplicación NetWeaver, que requiere ejecutables compartidos en muchas máquinas virtuales, se puede desplegar en Filestore Regional, que replica los datos de NetWeaver en varias zonas de una región. El resultado final es una arquitectura de aplicación esencial de tres niveles de alta disponibilidad.
Las organizaciones de TI también están desplegando cada vez más aplicaciones con estado en contenedores en Google Kubernetes Engine (GKE). Esto a menudo les lleva a replantearse qué infraestructura de almacenamiento deben usar para admitir esas aplicaciones. Puedes usar el almacenamiento en bloques (Hyperdisk o Persistent Disk), el almacenamiento de archivos (Filestore Basic, Zonal o Regional) o el almacenamiento de objetos (Cloud Storage). Filestore Basic HDD para GKE y Filestore multishares para GKE, combinados con el controlador CSI de Filestore, permiten que las organizaciones que necesitan varios pods de GKE tengan acceso a archivos compartidos, lo que proporciona un mayor nivel de disponibilidad para las cargas de trabajo críticas.
Managed Lustre
Managed Lustre es un servicio gestionado por Google que proporciona almacenamiento de alto rendimiento y baja latencia para cargas de trabajo de HPC estrechamente acopladas. Acelera significativamente las cargas de trabajo de HPC, así como el entrenamiento y la inferencia de la IA, al proporcionar un acceso de alta capacidad y baja latencia a conjuntos de datos masivos. Para obtener información sobre cómo usar Managed Lustre en cargas de trabajo de IA y aprendizaje automático, consulta Diseñar almacenamiento para cargas de trabajo de IA y aprendizaje automático en Google Cloud. Lustre gestionado distribuye los datos en varios nodos de almacenamiento, lo que permite que muchas VMs accedan a ellos de forma simultánea. Este acceso en paralelo elimina los cuellos de botella que se producen con los sistemas de archivos convencionales y permite que las cargas de trabajo ingieran y procesen rápidamente las enormes cantidades de datos que se necesitan.
NetApp Volumes
NetApp Volumes es un servicio de Google totalmente gestionado que te permite montar rápidamente almacenamiento de archivos compartido en tus instancias de cálculo de Google Cloud . NetApp Volumes admite el acceso SMB, NFS y multiprotocolo. NetApp Volumes ofrece un alto rendimiento a tus aplicaciones con baja latencia y sólidas funciones de protección de datos: capturas, copias, replicación entre regiones y copias de seguridad. El servicio es adecuado para aplicaciones que requieren cargas de trabajo secuenciales y aleatorias, que pueden escalarse en cientos o miles de instancias de Compute Engine. En cuestión de segundos, se pueden aprovisionar y proteger volúmenes de entre GiBs y PiBs con sólidas funciones de protección de datos. Con varios niveles de servicio (Flex, Standard, Premium y Extreme), NetApp Volumes ofrece el rendimiento adecuado para tu carga de trabajo sin afectar a la disponibilidad.
Soluciones de partners en Cloud Marketplace
Las siguientes soluciones proporcionadas por partners están disponibles en Cloud Marketplace.
NetApp Cloud Volumes ONTAP
Cloud Volumes ONTAP de NetApp (CVO de NetApp) es una solución basada en la nube y gestionada por el cliente que ofrece todas las funciones de ONTAP, el sistema operativo de gestión de datos líder de NetApp, en Google Cloud. NetApp CVO se implementa en tu VPC, con facturación y asistencia de Google. El software ONTAP se ejecuta en una VM de Compute Engine y usa una combinación de discos persistentes y segmentos de Cloud Storage (si la creación de niveles está habilitada) para almacenar los datos de NAS. El gestor de archivos integrado se adapta a los volúmenes NAS mediante el aprovisionamiento ligero, de modo que solo pagas por el almacenamiento que utilizas. A medida que aumentan los datos, se añaden discos persistentes adicionales al grupo de capacidad agregada.
NetApp CVO abstrae la infraestructura subyacente y te permite crear volúmenes de datos virtuales a partir del pool agregado que sean coherentes con todos los demás volúmenes de ONTAP en cualquier nube o entorno local. Los volúmenes de datos que crees admiten todas las versiones de NFS, SMB, NFS/SMB multiprotocolo e iSCSI. Admiten una amplia gama de cargas de trabajo basadas en archivos, incluido contenido web y multimedia enriquecido, que se utilizan en muchos sectores, como la automatización de diseño electrónico (EDA) y los medios de comunicación y el entretenimiento.
NetApp CVO admite capturas de un momento dado instantáneas y que ahorran espacio, copias de seguridad incrementales y permanentes a nivel de bloque en Cloud Storage, y replicación asíncrona entre regiones para la recuperación tras fallos. La opción de seleccionar el tipo de instancia de Compute Engine y los discos persistentes te permite conseguir el rendimiento que quieres para tus cargas de trabajo. Incluso cuando se utiliza una configuración de alto rendimiento, NetApp CVO implementa eficiencias de almacenamiento, como la desduplicación, la compactación y la compresión, así como la asignación automática de niveles de datos que no se usan con frecuencia al bucket de Cloud Storage, lo que te permite almacenar petabytes de datos y, al mismo tiempo, reducir significativamente los costes de almacenamiento generales.
DDN Infinia
Si necesitas una orquestación de datos de IA avanzada, puedes usar DDN Infinia, que está disponible en Google Cloud Marketplace. Infinia ofrece una solución de inteligencia de datos basada en IA que está optimizada para la inferencia, el entrenamiento y las analíticas en tiempo real. Permite la ingestión de datos ultrarrápida, la indexación con metadatos y la integración perfecta con frameworks de IA como TensorFlow y PyTorch.
Estas son las principales características de DDN Infinia:
- Alto rendimiento: ofrece una latencia inferior a un milisegundo y un rendimiento de varios TB/s.
- Escalabilidad: admite el escalado de terabytes a exabytes y puede alojar más de 100.000 GPUs y un millón de clientes simultáneos en una sola implementación.
- Arquitectura multicliente con calidad del servicio (QoS) predecible: ofrece entornos seguros y aislados para varios clientes con una QoS predecible que proporciona un rendimiento constante en todas las cargas de trabajo.
- Acceso unificado a los datos: permite una integración fluida con las aplicaciones y los flujos de trabajo actuales gracias a la compatibilidad multiprotocolo integrada, que incluye Amazon S3, CSI y Cinder.
- Seguridad avanzada: incluye cifrado integrado, codificación de borrado consciente del dominio de errores y copias de seguridad que ayudan a garantizar la protección de los datos y el cumplimiento de las normativas.
Nasuni Cloud File Storage
Nasuni sustituye los servidores de archivos y los dispositivos NAS empresariales, así como todas las infraestructuras asociadas, incluido el hardware de copias de seguridad y recuperación ante desastres, por una alternativa en la nube más sencilla y económica. Nasuni usa el Google Cloud almacenamiento de objetos para ofrecer una solución de almacenamiento de software como servicio (SaaS) más eficiente que se adapta para gestionar el rápido crecimiento de los datos de archivos no estructurados. Nasuni se ha diseñado para gestionar los recursos compartidos de archivos y los flujos de trabajo de aplicaciones de departamentos, proyectos y organizaciones para todos los empleados, independientemente de dónde trabajen.
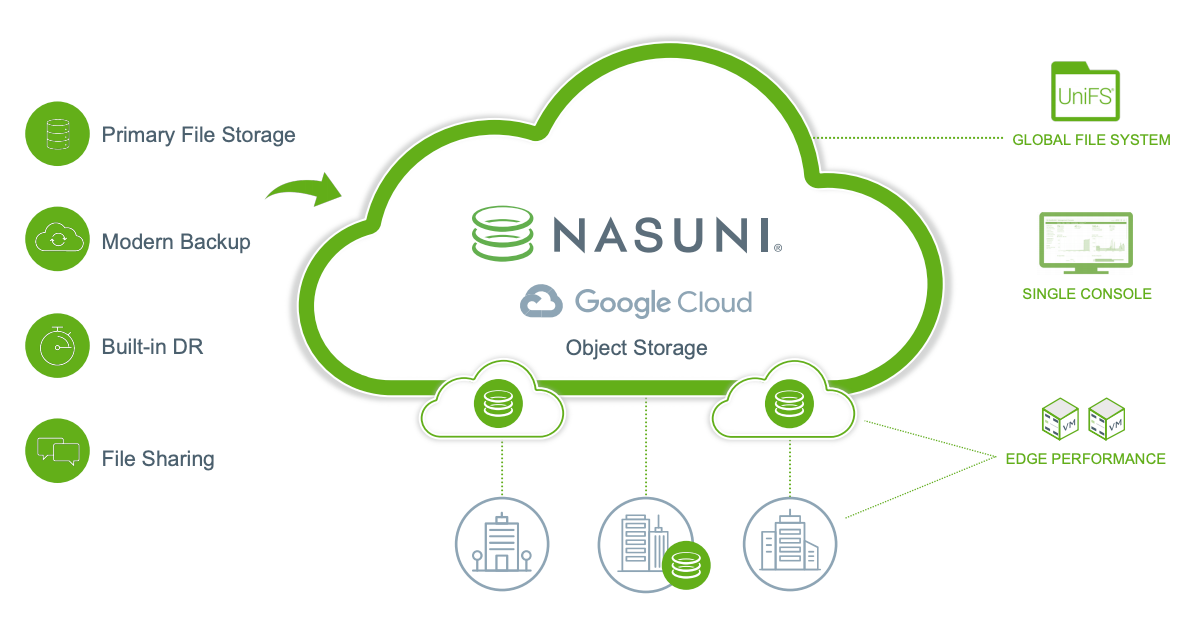
Nasuni ofrece tres paquetes con precios para empresas y organizaciones de todos los tamaños, de modo que puedan crecer y expandirse según sea necesario.
Entre sus ventajas se incluyen las siguientes:
Almacenamiento de archivos principal en la nube con un ahorro de hasta el 70 %. La arquitectura de Nasuni aprovecha las políticas de gestión del ciclo de vida de los objetos integradas. Estas políticas permiten una flexibilidad total para usar las clases de Cloud Storage, incluidas Standard, Nearline, Coldline y Archive. Si usas la clase Archive de acceso inmediato para el almacenamiento principal con Nasuni, puedes ahorrar hasta un 70%.
Sistemas de archivos departamentales y organizativos compartidos en la nube. La arquitectura basada en la nube de Nasuni ofrece un único espacio de nombres global enGoogle Cloud regiones, sin límites en el número de archivos, el tamaño de los archivos o las copias de seguridad, lo que te permite almacenar archivos directamente desde tu escritorio enGoogle Cloud mediante protocolos estándar de asignación de unidades NAS (SMB).
Copia de seguridad y recuperación tras desastres integradas. Las operaciones de "configurar y olvidarse" de Nasuni simplifican la gestión del almacenamiento de archivos global. Backup and DR está incluido y una única consola de gestión te permite supervisar y controlar el entorno en cualquier lugar y momento.
Sustituye a los servidores de archivos antiguos. Nasuni simplifica la migración de servidores de archivos de Microsoft Windows y otros sistemas de almacenamiento de archivos a Google Cloud, lo que reduce los costes y la complejidad de la gestión de estos entornos.
Para obtener más información, consulta las siguientes secciones:
- Visita guiada de Nasuni
- Colaboración con Nasuni Google Cloud
- Resumen de la solución Nasuni Enterprise File Storage para Google Cloud (PDF)
- Nasuni Cloud File Storage en Cloud Marketplace
- Blog de Nasuni y Google Cloud
Plataforma de almacenamiento de datos inteligente de Sycomp
La plataforma de almacenamiento de datos inteligente de Sycomp, disponible en Google Cloud Marketplace, te permite ejecutar tus cargas de trabajo de computación de alto rendimiento (HPC), IA y aprendizaje automático, y Big Data en Google Cloud. Con Sycomp Storage, puedes acceder simultáneamente a datos de miles de máquinas virtuales, reducir costes gestionando automáticamente los niveles de almacenamiento y ejecutar tu aplicación de forma local o en Google Cloud. Sycomp Storage se puede implementar rápidamente y admite el acceso a tus datos a través de NFS y del cliente de IBM Storage Scale.
IBM Storage Scale es un sistema de archivos paralelo que ayuda a gestionar de forma segura grandes volúmenes (PBs) de datos. Sycomp Storage Scale es un sistema de archivos paralelo que se adapta bien a la informática de alto rendimiento, la IA, el aprendizaje automático, el Big Data y otras aplicaciones que requieren un sistema de archivos compartido compatible con POSIX. Gracias a la capacidad de almacenamiento adaptable y al escalado del rendimiento, Sycomp Storage puede admitir cargas de trabajo de HPC, IA y aprendizaje automático de pequeño y gran tamaño.
Después de implementar un clúster en Google Cloud, puedes decidir cómo quieres usarlo. Elige si quieres usar el clúster solo en la nube o en modo híbrido conectándote a clústeres de IBM Storage Scale locales, soluciones NAS NFS de terceros u otras soluciones de almacenamiento basadas en objetos.
Colaboradores
Autor: Sean Derrington | Responsable de grupo de producto, almacenamiento
Otros colaboradores:
- Dean Hildebrand | Director técnico de la oficina del CTO
- Kumar Dhanagopal | Desarrollador de soluciones entre productos