이 튜토리얼에서는 vLLM 제공 프레임워크와 함께 Google Kubernetes Engine(GKE)에서 Tensor Processing Unit(TPU)을 사용하여 대규모 언어 모델(LLM)을 제공하는 방법을 보여줍니다. 이 튜토리얼에서는 Llama 3.1 70b를 제공하고, TPU Trillium을 사용하고, vLLM 서버 측정항목을 사용하여 수평형 포드 자동 확장을 설정합니다.
이 문서는 AI/ML 워크로드를 배포하고 제공할 때 관리형 Kubernetes의 세밀한 제어, 확장성, 복원력, 이동성, 비용 효율성이 필요한 경우 좋은 출발점이 될 수 있습니다.
배경
GKE에서 TPU Trillium을 사용하면 효율적인 확장성 및 더 높은 가용성을 비롯하여 관리형 Kubernetes의 모든 이점을 활용하여 프로덕션에 즉시 사용 가능한 강력한 제공 솔루션을 구현할 수 있습니다. 이 섹션에서는 이 가이드에서 사용되는 주요 기술을 설명합니다.
TPU Trillium
TPU는 Google에서 자체 개발한 ASIC(application-specific integrated circuit)입니다. TPU는 TensorFlow, PyTorch, JAX와 같은 프레임워크를 사용하여 빌드된 머신러닝 및 AI 모델을 가속화하는 데 사용됩니다. 이 튜토리얼에서는 Google의 6세대 TPU인 TPU Trillium을 사용합니다.
GKE에서 TPU를 사용하기 전에 다음 학습 과정을 완료하는 것이 좋습니다.
vLLM
vLLM은 LLM을 제공하기 위한 고도로 최적화된 오픈소스 프레임워크입니다. vLLM은 다음과 같은 기능을 통해 TPU의 제공 처리량을 늘릴 수 있습니다.
- PagedAttention으로 최적화된 Transformer 구현
- 전체 제공 처리량을 개선하기 위한 연속적인 작업 일괄 처리
- 여러 TPU에서 텐서 동시 로드 및 분산 제공
자세한 내용은 vLLM 문서를 참조하세요.
Cloud Storage FUSE
Cloud Storage FUSE는 GKE 클러스터에서 객체 스토리지 버킷에 있는 모델 가중치에 대한 Cloud Storage에 액세스할 수 있도록 지원합니다. 이 튜토리얼에서는 생성된 Cloud Storage 버킷이 처음에 비어 있습니다. vLLM이 시작되면 GKE가 Hugging Face에서 모델을 다운로드하고 가중치를 Cloud Storage 버킷에 캐싱합니다. 포드 재시작 또는 배포 수직 확장 시 후속 모델 부하는 Cloud Storage 버킷에서 캐시된 데이터를 다운로드하여 최적의 성능을 위해 병렬 다운로드를 활용합니다.
자세한 내용은 Cloud Storage FUSE CSI 드라이버 문서를 참조하세요.
GKE 클러스터 만들기
TPU를 활용하여 GKE Autopilot 또는 Standard 클러스터에서 LLM을 제공할 수 있습니다. 완전 관리형 Kubernetes 환경을 위해서는 Autopilot을 사용하는 것이 좋습니다. 워크로드에 가장 적합한 GKE 작업 모드를 선택하려면 GKE 작업 모드 선택을 참조하세요.
Autopilot
GKE Autopilot 클러스터를 만듭니다.
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
GKE Standard 클러스터를 만듭니다.
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverTPU 슬라이스 노드 풀을 만듭니다.
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE는 LLM에 다음 리소스를 만듭니다.
- GKE용 워크로드 아이덴티티 제휴를 사용하고 Cloud Storage FUSE CSI 드라이버가 사용 설정된 GKE Standard 클러스터
ct6e-standard-8t머신 유형이 있는 TPU Trillium 노드 풀. 이 노드 풀에는 노드 1개, TPU 칩 8개가 있으며 자동 확장이 사용 설정되어 있습니다.
클러스터와 통신하도록 kubectl 구성
클러스터와 통신하도록 kubectl을 구성하려면 다음 명령어를 실행합니다.
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Hugging Face 사용자 인증 정보용 Kubernetes 보안 비밀 만들기
네임스페이스를 만듭니다.
default네임스페이스를 사용하는 경우 이 단계를 건너뛸 수 있습니다.kubectl create namespace ${NAMESPACE}다음 명령어를 실행하여 Hugging Face 토큰이 포함된 Kubernetes 보안 비밀을 만듭니다.
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Cloud Storage 버킷 만들기
Cloud Shell에서 다음 명령어를 실행합니다.
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
이 명령어는 Hugging Face에서 다운로드한 모델 파일을 저장하는 Cloud Storage 버킷을 만듭니다.
버킷에 액세스하기 위한 Kubernetes ServiceAccount 설정
Kubernetes ServiceAccount를 만듭니다.
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Cloud Storage 버킷에 액세스하기 위해 Kubernetes ServiceAccount에 읽기/쓰기 액세스 권한을 부여합니다.
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"또는 프로젝트의 모든 Cloud Storage 버킷에 대한 읽기/쓰기 액세스 권한을 부여할 수 있습니다.
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE는 LLM에 다음 리소스를 만듭니다.
- 다운로드한 모델 및 컴파일 캐시를 저장하는 Cloud Storage 버킷. Cloud Storage FUSE CSI 드라이버가 버킷의 콘텐츠를 읽습니다.
- 파일 캐싱이 사용 설정된 볼륨 및 Cloud Storage FUSE의 병렬 다운로드 기능
권장사항: 모델 콘텐츠의 예상 크기(예: 가중치 파일)에 따라
tmpfs또는Hyperdisk / Persistent Disk기반의 파일 캐시를 사용합니다. 이 튜토리얼에서는 RAM을 기반으로 한 Cloud Storage FUSE 파일 캐시를 사용합니다.
vLLM 모델 서버 배포
이 튜토리얼에서는 vLLM 모델 서버를 배포하기 위해 Kubernetes 배포를 사용합니다. 배포는 클러스터에서 노드 간에 배포되는 여러 포드 복제본을 실행할 수 있는 Kubernetes API 객체입니다.
단일 복제본을 사용하는 다음 배포 매니페스트(
vllm-llama3-70b.yaml로 저장됨)를 검사합니다.배포를 여러 복제본으로 수직 확장하면
VLLM_XLA_CACHE_PATH에 대한 동시 쓰기로 인해RuntimeError: filesystem error: cannot create directories오류가 발생합니다. 이 오류를 방지하기 위한 옵션은 두 가지입니다.배포 YAML에서 다음 블록을 삭제하여 XLA 캐시 위치를 삭제합니다. 즉, 모든 복제본이 캐시를 다시 컴파일합니다.
- name: VLLM_XLA_CACHE_PATH value: "/data"배포를
1로 확장하고 첫 번째 복제본이 준비되어 XLA 캐시에 쓸 때까지 기다립니다. 그런 다음 추가 복제본으로 확장합니다. 이렇게 하면 나머지 복제본이 캐시를 쓰려고 시도하지 않고 읽을 수 있습니다.
다음 명령어를 실행하여 매니페스트를 적용합니다.
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}실행 중인 모델 서버에서 로그를 봅니다.
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}출력은 다음과 비슷하게 표시됩니다.
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
모델 제공
VLLM 서비스의 외부 IP 주소를 가져오려면 다음 명령어를 실행합니다.
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})curl을 사용하여 모델과 상호작용합니다.curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'출력은 다음과 비슷하게 표시됩니다.
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
커스텀 자동 확장 처리 설정
이 섹션에서는 커스텀 Prometheus 측정항목을 사용하여 수평형 포드 자동 확장을 설정합니다. vLLM 서버의 Google Cloud Managed Service for Prometheus 측정항목을 사용합니다.
자세한 내용은 Google Cloud Managed Service for Prometheus를 참조하세요. 이는 GKE 클러스터에서 기본적으로 사용 설정되어야 합니다.
클러스터에서 커스텀 측정항목 Stackdriver 어댑터를 설정합니다.
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml커스텀 측정항목 Stackdriver 어댑터가 사용하는 서비스 계정에 모니터링 뷰어 역할을 추가합니다.
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapter다음 매니페스트를
vllm_pod_monitor.yaml로 저장합니다.클러스터에 적용합니다.
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
vLLM 엔드포인트에 부하 만들기
GKE가 커스텀 vLLM 측정항목을 사용하여 자동 확장되는 방식을 테스트하기 위해 vLLM 서버에 부하를 만듭니다.
bash 스크립트(
load.sh)를 실행하여 vLLM 엔드포인트에N개의 동시 요청을 전송합니다.#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitPARALLEL_PROCESSES을 실행하려는 병렬 프로세스 수로 바꿉니다.
bash 스크립트를 실행합니다.
chmod +x load.sh nohup ./load.sh &
Google Cloud Managed Service for Prometheus가 측정항목을 수집하는지 확인
Google Cloud Managed Service for Prometheus가 측정항목을 스크래핑하고 vLLM 엔드포인트에 부하를 추가하면 Cloud Monitoring에서 측정항목을 볼 수 있습니다.
Google Cloud 콘솔에서 측정항목 탐색기 페이지로 이동합니다.
< > PromQL을 클릭합니다.
다음 쿼리를 입력하여 트래픽 측정항목을 관찰합니다.
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
선 그래프에는 시간 경과에 따라 측정된 vLLM 측정항목 (num_requests_waiting)이 표시됩니다. vLLM 측정항목은 0(부하 전)에서 값(부하 후)으로 확장됩니다. 이 그래프를 통해 vLLM 측정항목이 Google Cloud Managed Service for Prometheus에 수집되고 있는지 확인할 수 있습니다. 다음 예시 그래프는 부하 전 시작 값이 0이며 1분 이내에 부하 후 최댓값인 400에 도달하는 것을 보여줍니다.
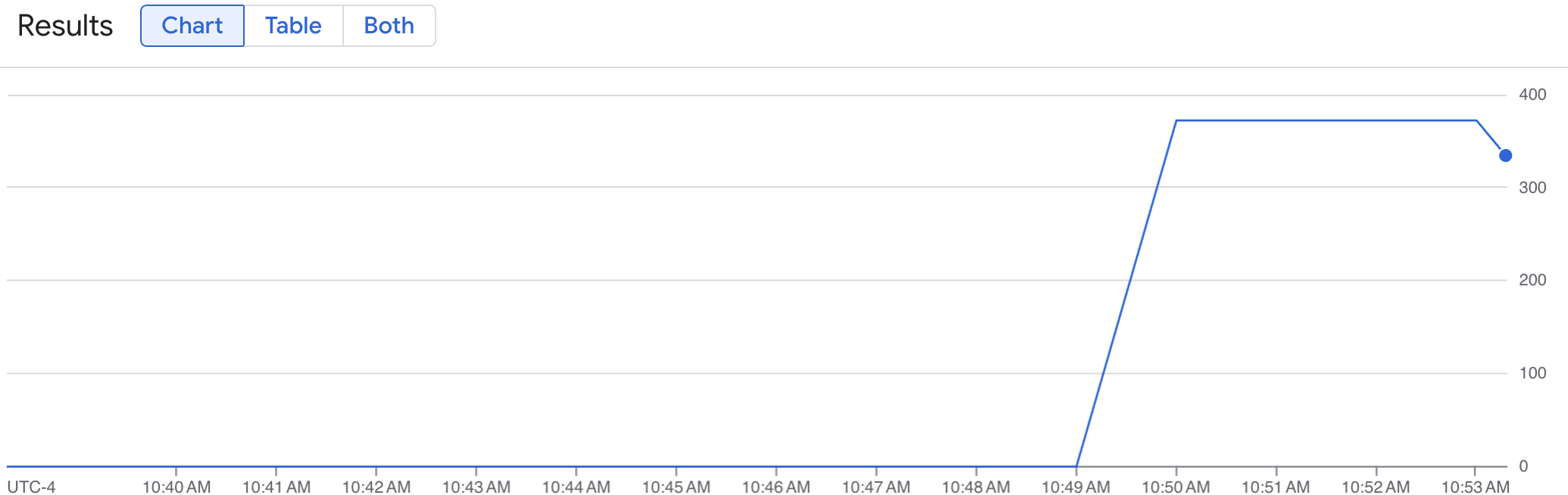
수평형 포드 자동 확장 처리 구성 배포
자동 확장할 측정항목을 결정할 때는 vLLM TPU에 다음 측정항목을 사용하는 것이 좋습니다.
num_requests_waiting: 이 측정항목은 모델 서버의 큐에서 대기 중인 요청 수와 관련이 있습니다. 이 수는 kv 캐시가 가득 차면 눈에 띄게 증가하기 시작합니다.gpu_cache_usage_perc: 이 측정항목은 모델 서버에서 특정 추론 주기에 처리되는 요청 수와 직접적인 상관관계가 있는 kv 캐시 사용률과 관련이 있습니다. 이 측정항목은 GPU 명명 스키마와 관련이 있지만 GPU와 TPU에서 동일하게 작동합니다.
처리량과 비용을 최적화할 때와 모델 서버의 최대 처리량으로 지연 시간 목표를 달성할 수 있는 경우 num_requests_waiting을 사용하는 것이 좋습니다.
큐 기반 확장이 요구사항을 충족할 만큼 빠르지 않은 지연 시간에 민감한 워크로드가 있는 경우 gpu_cache_usage_perc를 사용하는 것이 좋습니다.
자세한 설명은 TPU를 사용하여 대규모 언어 모델(LLM) 추론 워크로드를 자동 확장하기 위한 권장사항을 참조하세요.
HPA 구성의 averageValue 목표를 선택할 때는 실험적으로 결정해야 합니다. 이 부분을 최적화하는 방법에 관한 추가 아이디어를 얻으려면 GPU 비용 절감: GKE 추론 워크로드의 더 스마트한 자동 확장 블로그 게시물을 참조하세요. 이 블로그 게시물에서 사용된 profile-generator는 vLLM TPU에서도 작동합니다.
다음 안내에서는 num_requests_waiting 측정항목을 사용하여 HPA 구성을 배포합니다. 시연을 위해 HPA 구성이 vLLM 복제본을 2개로 확장하도록 측정항목을 낮은 값으로 설정합니다. num_requests_waiting을 사용하여 수평형 포드 자동 확장 처리 구성을 배포하려면 다음 단계를 따르세요.
다음 매니페스트를
vllm-hpa.yaml로 저장합니다.Google Cloud Managed Service for Prometheus의 vLLM 측정항목은
vllm:metric_name형식을 따릅니다.권장사항: 처리량 확장에
num_requests_waiting을 사용합니다. 지연 시간에 민감한 TPU 사용 사례에는gpu_cache_usage_perc를 사용합니다.수평형 포드 자동 확장 처리 구성을 배포합니다.
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE는 배포할 다른 포드를 예약합니다. 그러면 두 번째 vLLM 복제본을 배포하기 전에 노드 풀 자동 확장 처리가 두 번째 노드를 추가합니다.
포드 자동 확장 진행 상황을 확인합니다.
kubectl get hpa --watch -n ${NAMESPACE}출력은 다음과 비슷합니다.
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77s10분 동안 기다린 후 Google Cloud Managed Service for Prometheus가 측정항목을 수집하는지 확인 섹션의 단계를 반복합니다. 이제 Google Cloud Managed Service for Prometheus가 두 vLLM 엔드포인트의 측정항목을 수집합니다.