Pengenalan Karakter Optik (OCR) adalah salah satu dari tiga API pra-latih Vertex AI di Google Distributed Cloud (GDC) yang terisolasi. Layanan OCR mendeteksi teks dalam berbagai jenis file, seperti gambar, file dokumen, dan teks tulisan tangan.
OCR menawarkan metode berikut yang tersedia di Distributed Cloud untuk mengenali teks:
| Metode | Deskripsi |
|---|---|
BatchAnnotateImages |
Mendeteksi teks dari batch gambar JPEG atau PNG yang disediakan dalam permintaan inline. |
BatchAnnotateFiles |
Mendeteksi teks dari batch file PDF atau TIFF yang diberikan dalam permintaan inline. |
AsyncBatchAnnotateFiles |
Mendeteksi teks dari batch file PDF atau TIFF dalam bucket penyimpanan untuk permintaan offline. |
Pelajari lebih lanjut bahasa yang didukung yang terdeteksi oleh fitur pengenalan teks.
Fitur pengenalan karakter optik
OCR API dapat mendeteksi dan mengekstrak teks dari gambar. Dua fitur anotasi berikut mendukung pengenalan karakter optik:
TEXT_DETECTIONmendeteksi dan mengekstrak teks dari gambar apa pun. Misalnya, foto mungkin berisi rambu jalan atau rambu lalu lintas. Layanan OCR menampilkan file JSON dengan string yang diekstrak, setiap kata, dan kotak pembatasnya.
Gambar 1. Foto rambu jalan yang mendeteksi kata dan kotak pembatasnya menggunakan OCR API.
DOCUMENT_TEXT_DETECTIONjuga mengekstrak teks dari gambar, tetapi layanan ini mengoptimalkan respons untuk teks dan dokumen yang padat. Misalnya, gambar teks yang diketik dan dipindai dapat berisi beberapa paragraf dan judul. Layanan OCR menampilkan file JSON dengan informasi halaman, blok, paragraf, kata, dan jeda.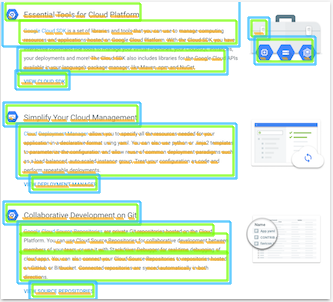
Gambar 2. Gambar yang dipindai dari teks yang diketik, tempat OCR API mendeteksi informasi seperti kata, halaman, dan paragraf.
Teks tulisan tangan
Gambar 3 adalah gambar teks tulisan tangan. OCR API mendeteksi dan mengekstrak teks dari gambar ini. Untuk mengetahui daftar skrip tulisan tangan yang mendukung pengenalan tulisan tangan, lihat Skrip tulisan tangan.

Gambar 3. Gambar tulisan tangan tempat OCR API mendeteksi teks.
Batas pengenalan karakter optik
Metode API BatchAnnotateImages dan BatchAnnotateFiles hanya mendukung satu permintaan per panggilan batch.
Tabel berikut mencantumkan batas layanan OCR saat ini di Distributed Cloud.
| Batas file untuk OCR | Nilai |
|---|---|
| Jumlah maksimum halaman | Lima |
| Ukuran file maksimal | 20 MB |
| Ukuran gambar maksimum | 20 juta piksel (panjang x lebar) |
File yang dikirimkan untuk OCR API yang melebihi jumlah halaman maksimum atau ukuran file maksimum akan menampilkan error. File yang dikirimkan yang melebihi ukuran gambar maksimum akan diperkecil hingga 20 juta piksel.
Jenis file yang didukung untuk OCR
API OCR yang telah dilatih sebelumnya mendeteksi dan mentranskripsikan teks dari jenis file berikut:
- TIFF
- JPG
- PNG
Anda harus menyimpan file secara lokal di lingkungan Distributed Cloud. Anda tidak dapat mengakses file yang dihosting di Cloud Storage atau file yang tersedia secara publik untuk deteksi teks.