您可以使用术语表来定义特定于您网域的术语。借助词汇表,您可以添加词对,包括源语言词汇和目标语言词汇。 词对可确保 Vertex AI Translation 服务始终如一地翻译您的术语。
以下是一些您可以定义术语表条目的示例:
- 产品名称:用于标识产品名称,以便在翻译中保留这些名称。例如,Google Home 必须翻译为 Google Home。
- 有歧义的字词:指定模糊字词和同音异义词的含义。例如,“bat”一词可能表示一种体育用品或动物。
- 借词:阐明从其他语言中采用的字词的含义。例如,法语中的 bouillabaisse 翻译为英语中的 bouillabaisse,是一种浓味鱼肉汤。
术语表中的术语可以是单个字词(也称为词法单元)或短语,通常少于五个字词。如果字词是停用字词,Vertex AI Translation 会忽略匹配的术语表条目。
Vertex AI Translation 在经过网闸隔离的 Google Distributed Cloud (GDC) 中提供以下词汇表方法:
| 方法 | 说明 |
|---|---|
CreateGlossary |
创建术语表。 |
GetGlossary |
返回存储的术语表。 |
ListGlossaries |
返回项目中的词汇表 ID 列表。 |
DeleteGlossary |
删除不再需要的词汇表。 |
准备工作
在创建术语库以定义翻译术语之前,您必须拥有一个名为 translation-glossary-project 的项目。项目的自定义资源必须如以下示例所示:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
如需获得使用术语库所需的权限,请让项目 IAM 管理员在项目命名空间中向您授予以下角色:
- AI Translation Developer:获取 AI Translation Developer (
ai-translation-developer) 角色,以访问 Vertex AI Translation 服务。 - Project Bucket Admin:获取 Project Bucket Admin (
project-bucket-admin) 角色,以管理存储分区和存储分区中的对象,从而创建和上传文件。
如需详细了解前提条件,请参阅设置翻译项目。
创建术语表文件
您必须创建一个术语库文件来存储源语言和目标语言术语。本部分包含两种不同的词汇表布局,您可以使用它们来定义术语。
下表介绍了 Distributed Cloud 支持的术语表文件限额:
| 说明 | 限制 |
|---|---|
| 文件大小上限 | 1,048.576 万个 UTF-8 字节 |
| 术语库术语的长度上限 | 1,024 个 UTF-8 字节 |
| 项目的术语库资源数上限 | 10000 |
为您的词汇表文件选择以下任一布局:
- 单向术语表:指定特定语言中一对源术语和目标术语的预期翻译。单向术语表支持 TSV、CSV 和 TMX 文件格式。
- 等效术语集术语表:在每一行中指定多种语言的预期翻译。等效术语集术语表支持 CSV 文件格式。
单向术语表
Vertex AI Translation API 接受制表符分隔值 (TSV) 和逗号分隔值 (CSV)。对于这些文件格式,每一行都包含一对由制表符 (\t) 或逗号 (,) 分隔的字词。
Vertex AI Translation API 还接受 Translation Memory eXchange (TMX) 格式,这是一种用于提供翻译的源词和目标词对的标准 XML 格式。支持基于 TMX 版本 1.4 格式的输入文件。
以下示例展示了单向词汇表的 TSV、CSV 和 TMX 文件格式所需的结构:
TSV 和 CSV
下图显示了 TSV 或 CSV 文件中的两列。第一列包含源语言术语,第二列包含目标语言术语。

创建词汇表文件时,您可以定义标题行。术语表请求会使该文件可供 Vertex AI Translation API 使用。
TMX
以下示例展示了 TMX 文件中所需的结构:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
如果您的文件包含此示例中未显示的 XML 标记,Vertex AI Translation API 会忽略这些标记。
在 TMX 文件中添加以下元素,以确保 Vertex AI Translation API 成功处理该文件:
<header>:使用srclang属性标识源语言。<tu>:包含一对具有相同源语言和目标语言的<tuv>元素。这些<tuv>元素符合以下条件:- 每个
<tuv>元素都使用xml:lang属性标识所含文本的语言。使用 ISO-639-1 代码来标识源语言和目标语言。 请参阅支持的语言及其各自的语言代码列表。 - 如果一个
<tu>元素包含两个以上的<tuv>元素,则 Vertex AI Translation API 只会处理与源语言匹配的第一个<tuv>元素和与目标语言匹配的第一个<tuv>元素。该服务会忽略其余的<tuv>元素。 - 如果
<tu>元素没有匹配的<tuv>元素对,则 Vertex AI Translation API 会忽略无效的<tu>元素。
- 每个
<seg>:表示广义的文本字符串。Vertex AI Translation API 会先从<seg>元素中排除标记,然后再处理文件。如果一个<tuv>元素包含多个<seg>元素,则 Vertex AI Translation API 会将文本连接成一个元素,并在文本字符串之间留一个空格。
在单向术语表中确定术语表术语后,请将文件上传到存储桶,然后通过创建和导入术语表,使该文件可用于 Vertex AI Translation API。
等效术语集术语表
Vertex AI Translation API 接受 CSV 格式的等效术语集术语表文件。如需定义等效术语集,您可以创建一个多列 CSV 文件,其中每一行列出一个术语表术语的多种语言版本翻译。请参阅支持的语言及其各自的语言代码列表。
下图展示了一个多列 CSV 文件示例。每一行表示一个术语,每一列表示该术语的不同语言译文。
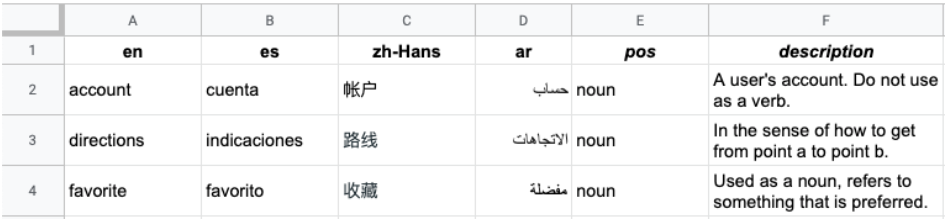
标题是文件中的第一行,用于标识每一列对应的语言。标题行使用 ISO-639-1 或 BCP-47 标准语言代码。Vertex AI Translation API 不使用词性 (pos) 信息,并且不会验证特定的位置值。
后续各行包含标题中所标识语言版本的等效术语表术语。如果该术语仅提供了部分语言版本,则可以将列留空。
在等效术语集中确定术语表术语后,请将文件上传到存储桶,并通过创建和导入术语表,使该文件可用于 Vertex AI Translation API。
将词汇表文件上传到存储桶
请按照以下步骤将词汇表文件上传到存储桶:
- 为对象存储配置 gdcloud CLI。
在项目命名空间中创建存储桶。使用
Standard存储类别。您可以通过在项目命名空间中部署
Bucket资源来创建存储桶:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90向 Vertex AI Translation 服务使用的服务账号 (
ai-translation-system-sa) 授予对相应存储桶的read权限。您可以按照以下步骤使用自定义资源创建角色和角色绑定:
通过在项目命名空间中部署
Role资源来创建角色:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-object通过在项目命名空间中部署
RoleBinding资源来创建角色绑定:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
将词汇表文件上传到您创建的存储桶。如需了解详情,请参阅在项目中上传和下载存储对象。
创建术语表
CreateGlossary 方法会创建词汇表,并返回生成该词汇表的长时间运行的操作的标识符。
如需创建词汇表,请先替换以下内容,然后再使用任何请求数据:
ENDPOINT:您组织使用的 Vertex AI Translation 端点。如需了解详情,请查看服务状态和端点。PROJECT_ID:您的项目 ID。GLOSSARY_ID:您的术语表 ID,即您的资源名称。BUCKET_NAME:术语表文件所在的存储桶的名称。GLOSSARY_FILENAME:存储桶中术语表文件的名称。
以下是用于创建词汇表的 HTTP 请求的语法:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
根据您创建的术语表文件,选择以下选项之一来创建术语表:
单向
如需创建单向术语表,请指定包含源语言 (source_language_code) 和目标语言 (target_language_code) 的语言对 (language_pair)。
请按照以下步骤创建单向词汇表:
将以下请求正文保存在名为
request.json的 JSON 文件中:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }替换以下内容:
发出请求。以下示例使用的是 REST API 方法和命令行,但您也可以使用客户端库创建单向术语表。
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
将 TOKEN 替换为您获得的身份验证令牌。
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
将 TOKEN 替换为您获得的身份验证令牌。
您必须收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
等效术语集
如需创建等效术语集术语表,请指定包含术语表语言代码 (language_codes) 的语言集 (language_codes_set)。
如需创建等效术语集术语表,请按以下步骤操作:
将以下请求正文保存在名为
request.json的 JSON 文件中:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }将
LANGUAGE_CODE替换为术语表的语言代码。请参阅支持的语言及其各自的语言代码列表。发出请求:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
将 TOKEN 替换为您获得的身份验证令牌。
您必须收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
将 TOKEN 替换为您获得的身份验证令牌。
您必须收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
将以下代码添加到您创建的 Python 脚本中:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...保存 Python 脚本。
运行 Python 脚本:
python SCRIPT_NAME
将 SCRIPT_NAME 替换为您为 Python 脚本指定的名称,例如 glossary.py。
如需详细了解 create_glossary 方法,请参阅 Python 客户端库。
创建术语表通常需要不到 10 分钟的时间,具体取决于术语表文件的大小。 您可以检索此操作的状态,以了解其完成时间。
获取术语表
GetGlossary 方法会返回存储的词汇表。如果词汇表不存在,输出会返回 NOT_FOUND 值。如需调用 GetGlossary 方法,请指定项目 ID 和词汇表 ID。CreateGlossary 和 ListGlossaries 方法都会返回词库 ID。
例如,以下请求会返回项目中特定术语库的相关信息:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
将 TOKEN 替换为您获得的身份验证令牌。
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
列出术语表
ListGlossaries 方法会返回项目中的术语库 ID 列表。如果不存在词汇表,则输出会返回 NOT_FOUND 值。如需调用 ListGlossaries 方法,请指定您的项目 ID 和 Vertex AI Translation 端点。
例如,以下请求会返回项目中的术语库 ID 列表:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
将 TOKEN 替换为您获得的身份验证令牌。
删除术语表
DeleteGlossary 方法可删除术语表。如果词汇表不存在,则输出返回 NOT_FOUND 值。如需调用 DeleteGlossary 方法,请指定项目 ID、术语库 ID 和 Vertex AI Translation 端点。CreateGlossary 和 ListGlossaries 方法都会返回词库 ID。
例如,以下请求会从您的项目中删除术语表:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
将 TOKEN 替换为您获得的身份验证令牌。