Puedes usar un glosario para definir la terminología específica de tu dominio. Con un glosario, puedes agregar pares de términos, incluido un término en el idioma de origen y otro en el idioma de destino. Los pares de términos garantizan que el servicio de Vertex AI Translation traduzca tu terminología de manera coherente.
A continuación, se incluyen ejemplos de casos en los que puedes definir entradas de glosario:
- Nombres de productos: Identifica los nombres de productos para conservarlos en la traducción. Por ejemplo, Google Home debe traducirse como Google Home.
- Palabras ambiguas: Especifica el significado de palabras vagas y homónimos. Por ejemplo, banco puede referirse a un asiento o a una empresa dedicada a realizar operaciones financieras.
- Palabras tomadas de otros idiomas: Se aclara el significado de las palabras adoptadas de otro idioma. Por ejemplo, bouillabaisse en francés se traduce como bouillabaisse en inglés, un guiso de pescado.
Los términos de un glosario pueden ser palabras individuales (también denominadas tokens) o frases cortas, generalmente de menos de cinco palabras. Vertex AI Translation ignora las entradas del glosario coincidentes si las palabras son palabras irrelevantes.
Vertex AI Translation ofrece los siguientes métodos de glosario disponibles en Google Distributed Cloud (GDC) aislado:
| Método | Descripción |
|---|---|
CreateGlossary |
Crea un glosario. |
GetGlossary |
Devuelve un glosario almacenado. |
ListGlossaries |
Devuelve una lista de IDs de glosario en un proyecto. |
DeleteGlossary |
Borra un glosario que ya no necesites. |
Antes de comenzar
Antes de crear un glosario para definir tu terminología de traducción, debes tener un proyecto llamado translation-glossary-project. El recurso personalizado del proyecto debe verse como en el siguiente ejemplo:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
Para obtener los permisos que necesitas para usar un glosario, pídele al administrador de IAM del proyecto que te otorgue los siguientes roles en el espacio de nombres del proyecto:
- Desarrollador de AI Translation: Obtén el rol de desarrollador de AI Translation (
ai-translation-developer) para acceder al servicio de Vertex AI Translation. - Administrador de buckets del proyecto: Obtén el rol de administrador de buckets del proyecto (
project-bucket-admin) para administrar los buckets de almacenamiento y los objetos dentro de los buckets, lo que te permite crear y subir archivos.
Para obtener más información sobre los requisitos previos, consulta Configura un proyecto de traducción.
Crea un archivo de glosario.
Debes crear un archivo de glosario para almacenar los términos de los idiomas fuente y objetivo. En esta sección, se incluyen los dos diseños de glosario diferentes que puedes usar para definir tus términos.
En la siguiente tabla, se describen los límites admitidos en Distributed Cloud para los archivos de glosario:
| Descripción | Límite |
|---|---|
| Tamaño máximo de archivo | 10.4 millones (10,485,760) de bytes UTF-8 |
| Longitud máxima de un término del glosario | 1,024 bytes UTF-8 |
| Cantidad máxima de recursos de glosario para un proyecto | 10,000 |
Elige uno de los siguientes diseños para tu archivo de glosario:
- Glosario unidireccional: Especifica la traducción esperada para un par de términos de origen y destino en un idioma específico. Los glosarios unidireccionales admiten los formatos de archivo TSV, CSV y TMX.
- Glosario de conjunto de términos equivalentes: Especifica la traducción esperada en varios idiomas en cada fila. Los glosarios de conjuntos de términos equivalentes admiten formatos de archivo CSV.
Glosario unidireccional
La API de Vertex AI Translation acepta valores separados por tabulaciones (TSV) y valores separados por comas (CSV). Cada fila contiene un par de términos separados por una tabulación (\t) o una coma (,) para estos formatos de archivo.
La API de Vertex AI Translation también acepta el formato de intercambio de memoria de traducción (TMX), un formato XML estándar para proporcionar los pares de términos de origen y destino de la traducción. Los archivos de entrada admitidos tienen un formato basado en la versión 1.4 de TMX.
En los siguientes ejemplos, se muestra la estructura requerida para los formatos de archivo TSV, CSV y TMX de los glosarios unidireccionales:
TSV y CSV
En la siguiente imagen, se muestran dos columnas en un archivo TSV o CSV. La primera columna contiene el término en el idioma de origen y la segunda columna contiene el término en el idioma de destino.

Cuando creas un archivo de glosario, puedes definir una fila de encabezado. La solicitud de glosario hace que el archivo esté disponible para la API de Vertex AI Translation.
TMX
En el siguiente ejemplo, se ilustra la estructura requerida en un archivo TMX:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
Si tu archivo contiene etiquetas XML que no se muestran en este ejemplo, la API de Vertex AI Translation las ignora.
Incluye los siguientes elementos en tu archivo TMX para garantizar que la API de Vertex AI Translation lo procese correctamente:
<header>: Identifica el idioma de origen con el atributosrclang.<tu>: Incluye un par de elementos<tuv>con los mismos idiomas de origen y de destino. Estos elementos<tuv>cumplen con lo siguiente:- Cada elemento
<tuv>identifica el idioma del texto contenido con el atributoxml:lang. Usa códigos ISO-639-1 para identificar los idiomas fuente y objetivo. Consulta la lista de idiomas admitidos y sus respectivos códigos de idioma. - Si un elemento
<tu>contiene más de dos elementos<tuv>, la API de Vertex AI Translation solo procesa el primer elemento<tuv>que coincide con el idioma de origen y el primer elemento<tuv>que coincide con el idioma de destino. El servicio ignora el resto de los elementos<tuv>. - Si un elemento
<tu>no tiene un par coincidente de elementos<tuv>, la API de Vertex AI Translation ignora el elemento<tu>no válido.
- Cada elemento
<seg>: Representan cadenas de texto generalizadas. La API de Vertex AI Translation excluye las etiquetas de lenguaje de marcado de un elemento<seg>antes de procesar el archivo. Si un elemento<tuv>contiene más de un elemento<seg>, la API de Vertex AI Translation concatena el texto en un solo elemento con un espacio entre las cadenas de texto.
Después de identificar los términos del glosario en tu glosario unidireccional, sube el archivo a un bucket de almacenamiento y haz que esté disponible para la API de Vertex AI Translation creando e importando un glosario.
Glosario de conjuntos de términos equivalentes
La API de Vertex AI Translation acepta archivos de glosario para conjuntos de términos equivalentes en formato CSV. Para definir conjuntos de términos equivalentes, crea un archivo CSV de varias columnas en el que, en cada fila, se enumere un único término del glosario en varios idiomas. Consulta la lista de idiomas admitidos y sus respectivos códigos de idioma.
En la siguiente imagen, se muestra un ejemplo de un archivo CSV con varias columnas. Cada fila representa un término del glosario, y cada columna representa una traducción del término a diferentes idiomas.
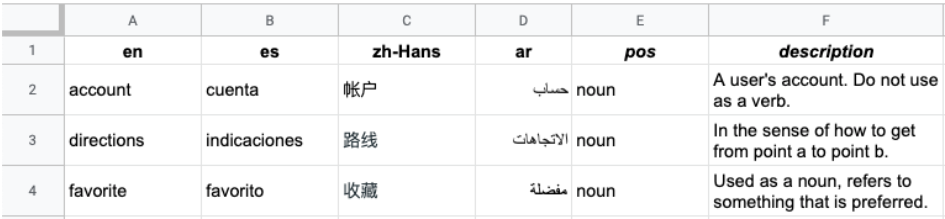
El encabezado es la primera fila del archivo, que identifica el idioma de cada columna. La fila de encabezado usa los códigos de idioma estándar ISO-639-1 o BCP-47. La API de Vertex AI Translation no usa información de partes del discurso (pos), y no se validan valores de posición específicos.
Cada fila posterior contiene términos del glosario equivalentes en los idiomas identificados en el encabezado. Puedes dejar columnas en blanco si el término no está disponible en todos los idiomas.
Después de identificar los términos del glosario en tu conjunto de términos equivalentes, sube el archivo a un bucket de almacenamiento y haz que esté disponible para la API de Vertex AI Translation creando e importando un glosario.
Sube tu archivo de glosario a un bucket de almacenamiento
Sigue estos pasos para subir tu archivo de glosario a un bucket de almacenamiento:
- Configura la CLI de gcloud para el almacenamiento de objetos.
Crea un bucket de almacenamiento en el espacio de nombres de tu proyecto. Usa una clase de almacenamiento
Standard.Puedes crear el bucket de almacenamiento implementando un recurso
Bucketen el espacio de nombres de tu proyecto:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Otorga permisos de
readen el bucket a la cuenta de servicio (ai-translation-system-sa) que usa el servicio de Vertex AI Translation.Puedes seguir estos pasos para crear el rol y la vinculación del rol con recursos personalizados:
Para crear el rol, implementa un recurso
Roleen el espacio de nombres del proyecto:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectImplementa un recurso
RoleBindingen el espacio de nombres del proyecto para crear la vinculación del rol:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
Sube tu archivo de glosario al bucket de almacenamiento que creaste. Para obtener más información, consulta Cómo subir y descargar objetos de almacenamiento en proyectos.
Crea un glosario
El método CreateGlossary crea un glosario y devuelve el identificador a la operación de larga duración que genera el glosario.
Para crear un glosario, reemplaza lo siguiente antes de usar cualquiera de los datos de la solicitud:
ENDPOINT: Es el extremo de Vertex AI Translation que usas para tu organización. Para obtener más información, consulta el estado y los extremos del servicio.PROJECT_ID: el ID de tu proyectoGLOSSARY_ID: Es el ID de tu glosario, que es el nombre de tu recurso.BUCKET_NAME: Es el nombre del bucket de almacenamiento en el que se encuentra tu archivo de glosario.GLOSSARY_FILENAME: Es el nombre de tu archivo de glosario en el bucket de almacenamiento.
A continuación, se muestra la sintaxis de una solicitud HTTP para crear un glosario:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
Según el archivo de glosario que creaste, elige una de las siguientes opciones para crear un glosario:
Unidireccional
Para crear un glosario unidireccional, especifica un par de idiomas (language_pair) con un idioma de origen (source_language_code) y un idioma objetivo (target_language_code).
Sigue estos pasos para crear un glosario unidireccional:
Guarda el siguiente cuerpo de la solicitud en un archivo JSON llamado
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Reemplaza lo siguiente:
SOURCE_LANGUAGE: Es el código de idioma del idioma fuente del glosario. Consulta la lista de idiomas admitidos y sus respectivos códigos de idioma.TARGET_LANGUAGE: Es el código de idioma del idioma de destino del glosario. Consulta la lista de idiomas admitidos y sus respectivos códigos de idioma.
Realiza la solicitud. En los siguientes ejemplos, se usan un método de la API de REST y la línea de comandos, pero también puedes usar bibliotecas cliente para crear un glosario unidireccional.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Reemplaza TOKEN por el token de autenticación que obtuviste.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Reemplaza TOKEN por el token de autenticación que obtuviste.
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Conjunto de términos equivalentes
Para crear un glosario de conjunto de términos equivalentes, especifica un conjunto de idiomas (language_codes_set) con los códigos de idioma (language_codes) del glosario.
Sigue estos pasos para crear un glosario de conjunto de términos equivalentes:
Guarda el siguiente cuerpo de la solicitud en un archivo JSON llamado
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Reemplaza
LANGUAGE_CODEpor el código del idioma o los idiomas del glosario. Consulta la lista de idiomas admitidos y sus respectivos códigos de idioma.Realiza la solicitud:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Reemplaza TOKEN por el token de autenticación que obtuviste.
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Reemplaza TOKEN por el token de autenticación que obtuviste.
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
Instala la versión más reciente de la biblioteca cliente de Vertex AI Translation.
Configura las variables de entorno necesarias en una secuencia de comandos de Python.
Agrega el siguiente código a la secuencia de comandos de Python que creaste:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Guarda la secuencia de comandos de Python.
Ejecuta la secuencia de comandos de Python:
python SCRIPT_NAME
Reemplaza SCRIPT_NAME por el nombre que le diste a tu secuencia de comandos de Python, como glossary.py.
Para obtener más información sobre el método create_glossary, consulta la biblioteca cliente de Python.
Según el tamaño del archivo de glosario, la creación de un glosario suele tardar menos de 10 minutos en completarse. Puedes recuperar el estado de esta operación para saber cuándo finaliza.
Obtén un glosario
El método GetGlossary devuelve un glosario almacenado. Si el glosario no existe, el resultado devuelve el valor NOT_FOUND. Para llamar al método GetGlossary, especifica el ID del proyecto y el ID del glosario. Los métodos CreateGlossary y ListGlossaries devuelven el ID del glosario.
Por ejemplo, las siguientes solicitudes devuelven información sobre un glosario específico de tu proyecto:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Reemplaza TOKEN por el token de autenticación que obtuviste.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
Enumerar glosarios
El método ListGlossaries devuelve una lista de los IDs del glosario en un proyecto. Si no existe un glosario, el resultado devuelve el valor NOT_FOUND. Para llamar al método ListGlossaries, especifica el ID de tu proyecto y el extremo de Vertex AI Translation.
Por ejemplo, la siguiente solicitud devuelve una lista de los IDs del glosario en tu proyecto:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
Reemplaza TOKEN por el token de autenticación que obtuviste.
Borra un glosario
El método DeleteGlossary borra un glosario. Si el glosario no existe, el resultado muestra el valor NOT_FOUND. Para llamar al método DeleteGlossary, especifica el ID de tu proyecto, el ID del glosario y el extremo de Vertex AI Translation.
Los métodos CreateGlossary y ListGlossaries devuelven el ID del glosario.
Por ejemplo, la siguiente solicitud borra un glosario de tu proyecto:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Reemplaza TOKEN por el token de autenticación que obtuviste.