本文档介绍了在Google Cloud 中实现的用于执行倾向建模的流水线示例。它面向创建和部署机器学习模型的数据工程师、机器学习工程师或营销科学团队。本文档假定您了解机器学习概念,并且熟悉 Google Cloud、BigQuery、Vertex AI Pipelines、Python 和 Jupyter 笔记本。此外,还假设您了解 Google Analytics 4 和 BigQuery 中的原始导出功能。
您使用的流水线使用 Google Analytics 样本数据。该流水线使用 BigQuery ML 和 XGBoost 构建多个模型,并且您使用 Vertex AI Pipelines 来运行该流水线。本文档介绍了训练模型、评估模型和部署模型的过程。另外还介绍了如何自动执行整个过程。
完整的流水线代码位于 GitHub 代码库中的 Jupyter 笔记本中。
什么是倾向建模?
倾向建模可预测消费者可能执行的操作。倾向建模的示例包括预测哪些消费者可能会购买产品、注册服务,甚至流失并不再是某个品牌的活跃客户。
倾向模型的输出是各消费者的得分(介于 0 到 1 之间),此得分表示消费者执行此操作的概率。推动组织选择倾向建模的关键驱动因素之一是需要使用第一方数据执行更多操作。对于营销使用场景,最佳的倾向模型包括来自在线和离线来源的信号,例如网站分析和 CRM 数据。
此演示使用 BigQuery 中的 GA4 抽样数据。对于您的使用场景,您可能需要考虑其他离线信号。
MLOps 如何简化机器学习流水线
大多数机器学习模型不用于生产环境。模型结果会生成分析洞见,并且数据科学团队完成模型后,机器学习工程或软件工程团队通常需要使用框架(例如 Flask 或 FastAPI)将其封装到代码中以用于生产环境。此过程通常需要在新框架中构建模型,这意味着必须重新转换数据。这项工作可能需要数周或数月的时间,并且许多模型因此无法投入生产。
机器学习操作 (MLOps) 对于从机器学习项目获取价值至关重要,MLOps 现在是数据科学组织不断演变的技能集。为了帮助组织理解此值, Google Cloud发布了 MLOps 从业人员指南,其中简要介绍了 MLOps。
通过使用 MLOps 原则和 Google Cloud,您可以使用自动流程将模型推送到端点,避免手动流程的大部分繁琐操作。本文档中介绍的工具和流程讨论了拥有端到端流水线的方法,这有助于您将模型投入生产。前面提到的从业人员指南文档介绍了一种横向的解决方案,并简要介绍了使用 MLOps 和 Google Cloud可以执行的操作。
什么是 Vertex AI Pipelines?
借助 Vertex AI Pipelines,您可以运行使用 Kubeflow Pipelines SDK 或 TensorFlow Extended (TFX) 构建的机器学习流水线。如果没有 Vertex AI,则要大规模运行这些开源框架之一,您需要设置和维护自己的 Kubernetes 集群。Vertex AI Pipelines 可以应对这一挑战。由于这是一项代管式服务,因此它会按需扩缩,并且不需要持续维护。
Vertex AI Pipelines 流程中的每个步骤都包含一个独立的容器,该容器能够以工件形式获取输入或生成输出。例如,如果该流程中的步骤构建数据集,则输出为数据集工件。此数据集工件可用作下一步的输入。因为每个组件都是单独的容器,所以您需要为流水线的每个组件提供信息,例如基础映像的名称以及任何依赖项列表。
流水线构建过程
本文档中介绍的示例使用 Jupyter 笔记本来创建流水线组件,并对其进行编译、运行和自动化。如前所述,笔记本位于 GitHub 代码库中。
您可以使用 Vertex AI Workbench 用户管理的笔记本实例来运行笔记本代码,以为您处理身份验证。借助 Vertex AI Workbench,您可以使用笔记本来创建机器、构建笔记本并连接到 Git。(Vertex AI Workbench 包含更多功能,但本文档未介绍这些功能。)
流水线运行完成后,Vertex AI Pipelines 中会生成类似于下图的图表:
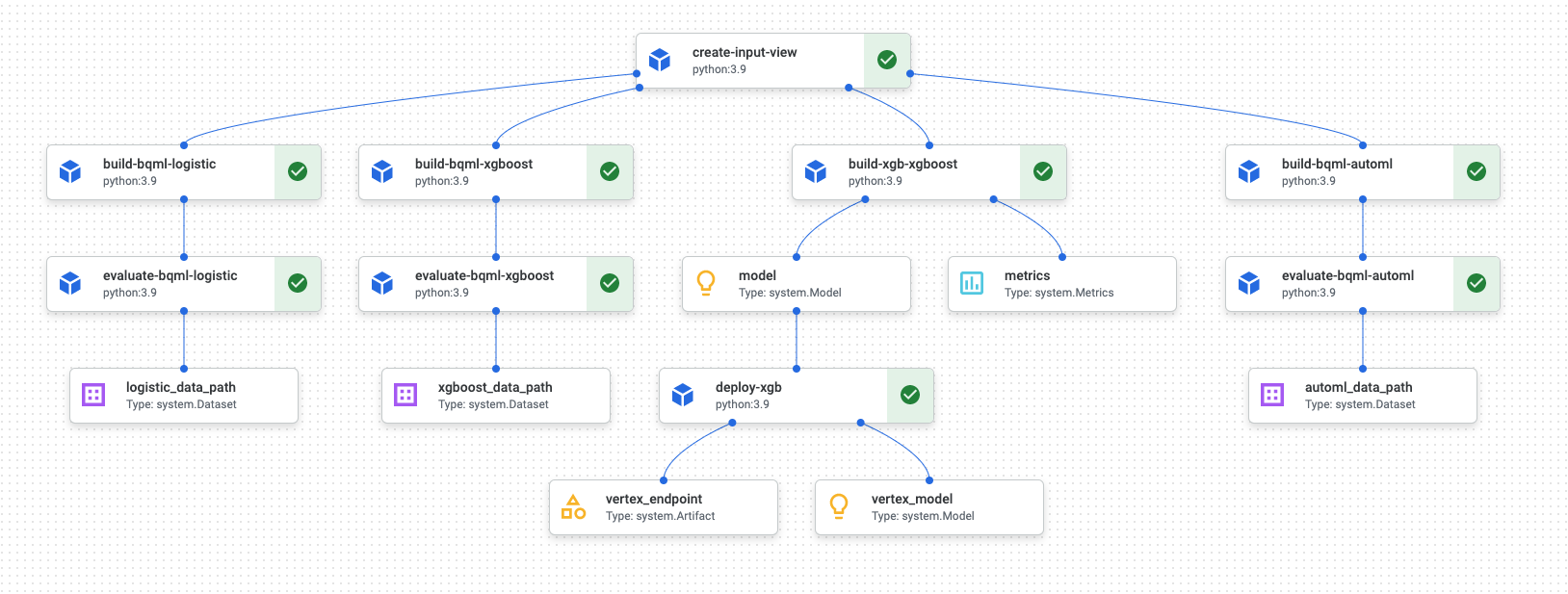
上图是有向无环图 (DAG)。构建和审核 DAG 是了解数据或机器学习流水线的核心步骤。DAG 的关键特性是,组件单向流动(在本例中,从上到下),并且不发生任何循环,也就是说,父级组件不依赖于其子级组件。一些组件可以并行发生,而另一些则可能具有依赖项,因此按顺序发生。
每个组件中的绿色复选框表示代码正常运行。如果发生错误,您会看到红色感叹号。您可以点击图中的每个组件以查看作业的更多详细信息。
DAG 图包含在本文档的这一部分中,充当流水线构建的每个组件的蓝图。以下列表给出了各个组件的说明。
完整的流水线会执行以下步骤,如 DAG 图中所示:
create-input-view:此组件会创建 BigQuery 视图。该组件从 Cloud Storage 存储桶中复制 SQL,并填写您提供的参数值。此 BigQuery 视图是流水线中稍后用于所有模型的输入数据集。build-bqml-logistic:该流水线使用 BigQuery ML 创建逻辑回归模型。此组件完成后,您可以在 BigQuery 控制台中查看新模型。您可以使用此模型对象来查看模型性能,并在以后构建预测。evaluate-bqml-logistic:该流水线使用此组件为逻辑回归创建精确率/召回率曲线(DAG 图中的logistic_data_path)。此工件存储在 Cloud Storage 存储桶中。build-bqml-xgboost:此组件使用 BigQuery ML 创建 XGBoost 模型。此组件完成后,您可以在 BigQuery 控制台中查看新模型对象 (system.Model)。您可以使用此对象来查看模型性能并在以后构建预测。evaluate-bqml-xgboost:此组件用于为 XGBoost 模型创建名为xgboost_data_path的精确率/召回率曲线。此工件存储在 Cloud Storage 存储桶中。build-xgb-xgboost:该流水线会创建 XGBoost 模型。此组件使用 Python 而非 BigQuery ML,因此您可以查看创建模型的不同方法。此组件完成后,它会将模型对象和性能指标存储在 Cloud Storage 存储桶中。deploy-xgb:此组件用于部署 XGBoost 模型。它会创建一个允许批量预测或在线预测的端点。您可以在 Vertex AI 控制台页面的模型标签页中探索该端点。该端点会自动扩缩以匹配流量。build-bqml-automl:该流水线使用 BigQuery ML 创建 AutoML 模型。此组件完成后,您可以在 BigQuery 控制台中查看新模型对象。您可以使用此对象来查看模型性能并在以后构建预测。evaluate-bqml-automl:该流水线用于为 AutoML 模型创建精确率/召回率曲线。工件存储在 Cloud Storage 存储桶中。
请注意,该过程不会将 BigQuery ML 模型推送到端点。这是因为您可以直接从 BigQuery 中的模型对象生成预测。当决定在解决方案中使用 BigQuery ML 还是使用其他库时,请考虑需要如何生成预测。如果每日批量预测可以满足您的需求,那么留在 BigQuery 环境中可以简化您的工作流。但是,如果您需要实时预测,或者您的场景需要其他库中的功能,请按照本文档中的步骤将已保存的模型推送到端点。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用量来估算费用,请使用价格计算器。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- 在 Google Cloud 控制台中,选择要在哪个项目中创建笔记本。
前往 Vertex AI Workbench 页面。
在用户管理的笔记本标签页上,点击新建笔记本。
在笔记本类型列表中,选择一个 Python 3 笔记本。
在新建笔记本对话框中,点击高级选项,然后在机器类型下,选择要使用的机器类型。如果您不确定,请选择 n1-standard-1 (1 cVPU, 3.75 GB RAM)。
点击创建。
创建笔记本环境需要一些时间。
创建笔记本后,选择该笔记本,然后点击打开 Jupyterlab。
JupyterLab 环境会在浏览器中打开。
如需启动终端标签页,请选择文件 > 新建 > 启动器。
点击启动器标签页中的终端图标。
在终端中,克隆
mlops-on-gcpGitHub 代码库:git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
命令完成后,您会在文件浏览器中看到
cloud-for-marketing文件夹。- 创建 Cloud Storage 存储桶,笔记本可以在其中存储流水线工件。存储桶的名称必须保持全局唯一。
- 在
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/文件夹中,打开Propensity_Pipeline.ipynb笔记本。 - 在笔记本中,将
PROJECT_ID变量的值设置为要在其中运行流水线的 Google Cloud 项目的 ID。 - 将
BUCKET_NAME变量的值设置为您刚刚创建的存储桶的名称。 - 创建输入数据集。
- 使用 BigQuery ML 以及 Python 的 XGBoost 训练数个模型。
- 分析模型结果。
- 部署 XGBoost 模型。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 如需了解如何使用 MLOps 创建可用于生产用途的机器学习系统,请参阅 MLOps 从业人员指南。
- 如需了解 Vertex AI,请参阅 Vertex AI 文档。
- 如需了解 Kubeflow Pipelines,请参阅 KFP 文档。
- 如需了解 TensorFlow Extended,请参阅 TFX 用户指南。
- 如需简要了解 Google Cloud中特定于 AI 和机器学习工作负载的架构原则和建议,请参阅 Well-Architected Framework 中的 AI 和机器学习视角。
- 如需查看更多参考架构、图表和最佳实践,请浏览 Cloud 架构中心。
适合此场景的 Jupyter 笔记本
用于创建和构建流水线的任务内置在 GitHub 代码库中的 Jupyter 笔记本中。
如需执行这些任务,您需要获取笔记本,然后按顺序运行笔记本中的代码单元。本文档中介绍的流程假定您在 Vertex AI Workbench 中运行笔记本。
打开 Vertex AI Workbench 环境
首先,将 GitHub 代码库克隆到 Vertex AI Workbench 环境中。
配置笔记本设置
在运行笔记本之前,您必须对其进行配置。笔记本需要一个 Cloud Storage 存储桶来存储流水线工件,因此您首先要创建该存储桶。
本文档的其余部分介绍了对于了解流水线工作原理非常重要的代码段。如需了解完整实现,请参阅 GitHub 代码库。
构建 BigQuery 视图
流水线的第一步是生成输入数据,输入数据将用于构建每个模型。此 Vertex AI Pipelines 组件会生成一个 BigQuery 视图。为了简化创建视图的过程,已生成一些 SQL 并将其保存在 GitHub 中的文本文件中。
每个组件的代码首先会修饰(通过属性修改父类或函数)Vertex AI Pipelines 组件类。然后,该代码定义了 create_input_view 函数,这是流水线中的一个步骤。
该函数需要多个输入。其中一些值当前会硬编码到代码中,例如开始日期和结束日期。自动执行流水线时,您可以修改代码以使用合适的值(例如,对日期使用 CURRENT_DATE 函数),也可以更新组件以将这些值作为参数,而不是对其进行硬编码。您还必须将 ga_data_ref 的值更改为 GA4 表的名称,并将 conversion 变量的值设置为您的转换值。(此示例使用公共 GA4 抽样数据。)
下面是 create-input-view 组件的代码。
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
构建 BigQuery ML 模型
创建视图后,运行名为 build_bqml_logistic 的组件来构建 BigQuery ML 模型。该笔记本块是核心组件。使用您在第一个块中创建的训练视图,它会构建 BigQuery ML 模型。在此示例中,笔记本使用逻辑回归。
如需了解模型类型和可用的超参数,请参阅 BigQuery ML 参考文档。
下面是此组件的代码。
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
使用 XGBoost 代替 BigQuery ML
上一部分所述组件使用 BigQuery ML。笔记本的下一部分将介绍如何在 Python 中直接使用 XGBoost,而不是使用 BigQuery ML。
运行名为 build_bqml_xgboost 的组件以构建该组件,从而运行带有网格搜索的标准 XGBoost 分类模型。然后,代码会将该模型保存为您创建的 Cloud Storage 存储桶中的工件。该函数支持输出工件的其他参数(metrics 和 model);Vertex AI Pipelines 需要这些参数。
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
构建端点
运行名为 deploy_xgb 的组件以使用上一部分中的 XGBoost 模型来构建端点。该组件接受之前的 XGBoost 模型工件,构建容器,然后部署端点,同时提供端点网址作为工件,以便您查看。完成此步骤后,Vertex AI 端点已创建,您可以在 Vertex AI 控制台页面中查看该端点。
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
定义流水线
要定义流水线,请根据之前创建的组件定义每个操作。如果组件中未显式调用流水线元素的顺序,那么您可以指定该顺序。
例如,笔记本中的以下代码定义了一个流水线。在本例中,该代码要求 build_bqml_logistic_op 组件在 create_input_view_op 组件之后运行。
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
编译并运行流水线
您现在可以编译并运行流水线。
笔记本中的以下代码将 enable_caching 值设置为 true,以启用缓存。启用缓存后,任何之前已成功完成组件的运行不会重新运行。此标志在测试流水线时特别有用,因为启用缓存后,运行会更快地完成并会使用更少的资源。
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
自动执行流水线
在此阶段,您已经启动了第一个流水线。您可以在控制台中查看 Vertex AI Pipelines 页面以查看此作业的状态。您可以在构建和运行每个容器时进行观察。您还可以通过点击本部分中每个特定组件来跟踪其错误。
如需安排流水线,请构建一个 Cloud Run 函数,并使用类似于 Cron 作业的调度程序。
笔记本的最后一部分中的代码将安排流水线每天运行一次,如以下代码段所示:
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
在生产环境中使用已完成的流水线
已完成的流水线已执行以下任务:
您还可以使用 Cloud Run functions 和 Cloud Scheduler 将流水线自动化,使其每天运行一次。
在笔记本中定义的流水线旨在说明创建各种模型的方法。您不会运行该流水线,因为它当前在生产场景中构建。不过,您可以将此流水线用作指导,并根据需要修改组件。例如,您可以修改特征创建过程以利用您的数据、修改日期范围,也许还可以构建替代模型。此外,您还可以从所展示的最适合您的生产要求的模型中进行选择。
当流水线准备好投入生产时,您可以实现其他任务。例如,您可以实现一个冠军/挑战者模型,即每天创建一个新模型,并根据新数据对新模型(挑战者)和现有模型(冠军)进行评分。只有在新模型的性能优于当前模型的性能时,您才将新模型投入生产。如需监控系统进度,您还可以记录每天的模型性能,并直观呈现趋势性能。
清理
后续步骤
贡献者
作者:Tai Conley | Cloud 客户工程师
其他贡献者:Lars Ahlfors | Cloud 客户工程师