이 가이드에서는 보안 실무자가 보안 분석에 사용할 Google Cloud로그에 대한 온보딩 방법을 보여줍니다. 조직은 보안 분석을 수행하여 멀웨어, 피싱, 랜섬웨어, 잘못 구성된 애셋 등의 위협을 예방 및 감지하고 이에 대응할 수 있습니다.
이 가이드에서는 다음을 수행하는 방법을 보여줍니다.
- 분석할 로그를 사용 설정합니다.
- Log Analytics, BigQuery, Google Security Operations 또는 서드 파티 보안 정보 및 이벤트 관리(SIEM) 기술과 같은 선택한 보안 분석 도구에 따라 이러한 로그를 단일 대상으로 라우팅합니다.
- 커뮤니티 보안 분석(CSA) 프로젝트의 샘플 쿼리를 사용하여 로그를 분석하고 클라우드 사용량을 감사하여 데이터 및 워크로드에 대한 잠재적인 위협을 감지합니다.
이 가이드의 정보는 위협 감지 기능을 개선하기 위해 엔지니어링이 주도하는 감지 및 대응 방식의 혁신과 보안 분석이 포함된 Google Cloud 자동 보안 운영의 일부입니다.
이 가이드에서 로그는 분석할 데이터 소스를 제공합니다. 그러나 Security Command Center의 보안 발견 항목과 같은 Google Cloud의 다른 보완적인 보안 관련 데이터를 분석하는 데 이 가이드의 개념을 적용할 수 있습니다. Security Command Center 프리미엄은 시스템 내부의 위협, 취약점, 잘못된 구성을 거의 실시간으로 식별할 수 있도록 디자인되었고 정기적으로 업데이트되고 관리되는 감지 도구입니다. 이 가이드의 설명에 따라 Security Command Center에서 이러한 신호를 분석하고 이를 보안 분석 도구에서 수집된 로그와 결합하여 잠재적인 보안 위협을 보다 광범위하게 파악할 수 있습니다.
다음 다이어그램은 보안 데이터 소스, 보안 분석 도구, CSA 쿼리가 함께 작동하는 방식을 보여줍니다.
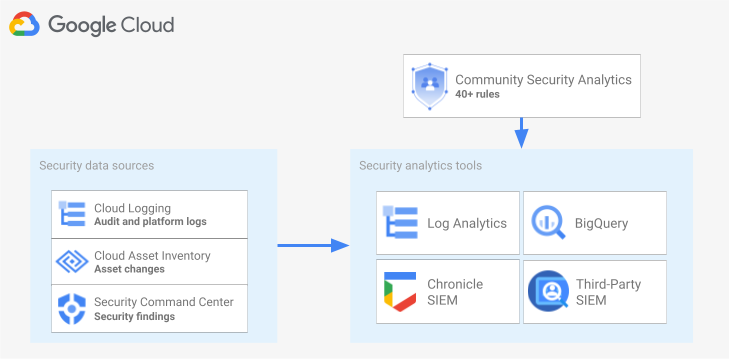
이 다이어그램은 다음과 같은 보안 데이터 소스로 시작합니다. 여기에는 Cloud Logging의 로그, Cloud Asset Inventory의 자산 변경사항, Security Command Center의 보안 발견 항목이 포함됩니다. 그러면 다이어그램에 Cloud Logging, BigQuery, Google Security Operations 또는 서드 파티 SIEM 중 원하는 보안 분석 도구로 라우팅되는 보안 데이터 소스가 표시됩니다. 마지막으로 이 다이어그램은 분석 도구와 함께 CSA 쿼리를 사용하여 대조된 보안 데이터를 분석하는 방법을 보여줍니다.
보안 로그 분석 워크플로
이 섹션에서는Google Cloud에서 보안 로그 분석을 설정하는 단계를 설명합니다. 이 워크플로는 다음 다이어그램과 다음 단락에서 설명하는 세 가지 단계로 구성됩니다.
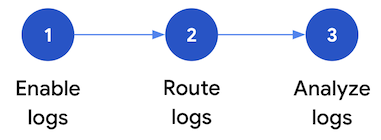
로그 사용 설정:Google Cloud에서는 많은 보안 로그를 사용할 수 있습니다. 각 로그에는 특정 보안 질문에 답하는 데 유용하게 사용할 수 있는 다양한 정보가 있습니다. 관리자 활동 감사 로그와 같은 일부 로그는 기본적으로 사용 설정됩니다. 다른 로그는 Cloud Logging에서 추가 수집 비용이 발생하므로 수동으로 사용 설정해야 합니다. 따라서 이 워크플로에서 첫 번째 단계는 보안 분석 요구와 관련성이 가장 높은 보안 로그를 선별하고 이러한 특정 로그를 개별적으로 사용 설정하는 것입니다.
이 가이드에는 공개 상태 및 위협 감지 범위 측면에서 로그를 평가하는 데 도움이 되는 로그 범위 지정 도구가 포함되어 있습니다. 이 도구는 각 로그를 MITRE ATT&CK® 기업용 매트릭스의 관련 위협 전략과 기법에 매핑합니다. 또한 이 도구는 Security Command Center의 Event Threat Detection 규칙을 관련된 로그에 매핑합니다. 사용하는 분석 도구에 관계없이 로그 범위 지정 도구를 사용하여 로그를 평가할 수 있습니다.
로그 라우팅: 분석할 로그를 식별하고 사용 설정한 후 포함된 폴더, 프로젝트, 결제 계정을 포함하여 조직에서 로그를 라우팅하고 집계하는 단계입니다. 로그를 라우팅하는 방법은 사용하는 분석 도구에 따라 달라집니다.
이 가이드에서는 일반적인 로그 라우팅 대상을 설명하고 Cloud Logging 집계 싱크를 사용하여 분석에 Log Analytics 또는 BigQuery를 사용하는지 여부에 따라 조직 전체 로그를 Cloud Logging 로그 버킷 또는 BigQuery 데이터 세트로 라우팅하는 방법을 보여줍니다.
로그 분석: 로그를 분석 도구로 라우팅한 후 이러한 로그 분석을 수행하여 잠재적인 보안 위협을 식별하는 단계입니다. 라우팅한 로그를 분석하는 방법은 사용하는 분석 도구에 따라 달라집니다. Log Analytics 또는 BigQuery를 사용하는 경우 SQL 쿼리를 사용하여 로그를 분석할 수 있습니다. Google Security Operations를 사용하는 경우 YARA-L 규칙에 따라 로그를 분석합니다. 서드 파티 SIEM 도구를 사용하는 경우에는 해당 도구에서 지정한 쿼리 언어를 사용합니다.
이 가이드에서는 Log Analytics 또는 BigQuery에서 로그를 분석하는 데 사용할 수 있는 SQL 쿼리를 설명합니다. 이 가이드에서 제공하는 SQL 쿼리는 커뮤니티 보안 분석(CSA) 프로젝트에서 제공됩니다. CSA는 사전 빌드된 쿼리 및 규칙의 기준을 제공하도록 설계된 오픈소스 보안 분석 모음으로, Google Cloud 로그 분석을 시작하는 데 재사용할 수 있습니다.
다음 섹션에서는 보안 로그 분석 워크플로에서 각 단계를 설정하고 적용하는 방법을 자세히 설명합니다.
로그 사용 설정
로그를 사용 설정하려면 다음 단계를 따르세요.
- 이 가이드의 로그 범위 지정 도구를 사용하여 필요한 로그를 식별합니다.
- 나중에 로그 싱크를 구성할 때 사용할 수 있도록 로그 범위 지정 도구에서 생성된 로그 필터를 기록합니다.
- 식별된 각 로그 유형 또는 Google Cloud 서비스에서 로깅을 사용 설정합니다. 서비스에 따라 이 섹션의 뒷부분에 설명된 대로 해당 데이터 액세스 감사 로그를 사용 설정해야 할 수도 있습니다.
로그 범위 지정 도구를 사용하여 로그 식별
이 섹션에 나와 있는 로그 범위 지정 도구를 사용하면 보안 및 규정 준수 요구사항을 충족하는 로그를 식별할 수 있습니다. 이 도구는 Cloud 감사 로그, 액세스 투명성 로그, 네트워크 로그, 여러 플랫폼 로그를 비롯하여Google Cloud 간의 중요한 보안 관련 로그를 나열하는 대화형 테이블을 제공합니다. 이 도구는 각 로그 유형을 다음 영역에 매핑합니다.
- 해당 로그로 모니터링할 수 있는 MITRE ATT&CK 위협 전략 및 기법
- 해당 로그에서 감지할 수 있는 CIS Google Cloud 컴퓨팅 플랫폼 규정 준수 위반
- 해당 로그를 사용하는 Event Threat Detection 규칙
로그 범위 지정 도구는 테이블 바로 뒤에 나타나는 로그 필터도 생성합니다. 필요한 로그를 찾으면 도구에서 로그를 선택하여 해당 로그 필터를 자동으로 업데이트합니다.
아래의 짧은 절차에서는 로그 범위 지정 도구를 사용하는 방법을 설명합니다.
- 로그 범위 지정 도구에서 로그를 선택하거나 삭제하려면 로그 이름 옆에 있는 전환 버튼을 클릭합니다.
- 모든 로그를 선택하거나 삭제하려면 로그 유형 제목 옆에 잇는 전환 버튼을 클릭합니다.
- 각 로그 유형으로 모니터링할 수 있는 MITRE ATT&CK 기법을 확인하려면 MITRE ATT&CK 전략 및 기법 제목 옆에 있는 을 클릭합니다.
로그 범위 지정 도구
로그 필터 기록
로그 범위 지정 도구에서 자동으로 생성되는 로그 필터에는 도구에서 선택한 모든 로그가 포함됩니다. 필터를 그대로 사용하거나 요구사항에 따라 로그 필터를 더 세분화할 수 있습니다. 예를 들어 하나 이상의 특정 프로젝트에만 리소스를 포함(또는 제외)할 수 있습니다. 로깅 요구사항을 충족하는 로그 필터가 준비되었으면 로그를 라우팅할 때 사용할 필터를 저장해야 합니다. 예를 들어 텍스트 편집기에서 필터를 저장하거나 다음과 같이 환경 변수에 저장할 수 있습니다.
- 도구 다음에 표시된 '자동 생성된 로그 필터' 섹션에서 로그 필터에 대한 코드를 복사합니다.
- 선택사항: 복사한 코드를 수정하여 필터를 세분화합니다.
Cloud Shell에서 로그 필터를 저장할 변수를 만듭니다.
export LOG_FILTER='LOG_FILTER'LOG_FILTER를 로그 필터의 코드로 바꿉니다.
서비스별 플랫폼 로그 사용 설정
로그 범위 지정 도구에서 선택한 각 플랫폼 로그 각각에 대해 해당 로그를 서비스별로 사용 설정(일반적으로 리소스 수준)해야 합니다. 예를 들어 Cloud DNS 로그는 VPC 네트워크 수준에서 사용 설정됩니다. 마찬가지로 VPC 흐름 로그는 서브넷에 있는 모든 VM에 대해 서브넷 수준에서 사용 설정되고, 방화벽 규칙 로깅의 로그는 개별 방화벽 규칙 수준에서 사용 설정됩니다.
각 플랫폼 로그에는 로깅 사용 설정 방법에 대한 자체 안내가 포함되어 있습니다. 그러나 로그 범위 지정 도구를 사용하여 각 플랫폼 로그에 대한 관련 안내를 빠르게 열 수 있습니다.
특정 플랫폼 로그에 로깅을 사용 설정하는 방법을 알아보려면 다음을 수행합니다.
- 로그 범위 지정 도구에서 사용 설정하려는 플랫폼 로그를 찾습니다.
- 기본 사용 설정 열에서 원하는 로그에 해당하는 사용 설정 링크를 클릭합니다. 이 링크는 해당 서비스에 대해 로깅을 사용 설정하는 방법에 대한 자세한 안내로 연결됩니다.
데이터 액세스 감사 로그 사용 설정
로그 범위 지정 도구에서 볼 수 있듯이 Cloud 감사 로그의 데이터 액세스 감사 로그는 포괄적인 위협 감지 범위를 제공합니다. 하지만 로그 볼륨이 상당히 클 수 있습니다. 따라서 이러한 데이터 액세스 감사 로그를 사용 설정하면 로그 수집, 저장, 내보내기, 처리와 관련된 추가 비용이 발생할 수 있습니다. 이 섹션에서는 이러한 로그를 사용 설정하는 방법을 설명하고 가치와 비용의 균형을 맞출 수 있도록 몇 가지 권장사항을 제공합니다.
BigQuery를 제외한 데이터 액세스 감사 로그는 기본적으로 사용 중지되어 있습니다. BigQuery 이외의 Google Cloud 서비스에 맞게 데이터 액세스 감사 로그를 구성하려면 Identity and Access Management (IAM) 정책 객체를 수정하도록 Google Cloud 콘솔을 사용하거나 Google Cloud CLI를 사용해서 이를 명시적으로 사용 설정해야 합니다. 데이터 액세스 감사 로그를 사용 설정할 때는 기록되는 작업 유형도 구성할 수 있습니다. 데이터 액세스 감사 로그 유형에는 다음 세 가지가 있습니다.
ADMIN_READ: 메타데이터 또는 구성 정보를 읽는 작업을 기록합니다.DATA_READ: 사용자가 제공한 데이터를 읽는 작업을 기록합니다.DATA_WRITE: 사용자가 제공한 데이터를 쓰는 작업을 기록합니다.
메타데이터 또는 구성 정보를 쓰는 작업인 ADMIN_WRITE 작업 기록은 구성할 수 없습니다. ADMIN_WRITE 작업은 Cloud 감사 로그의 관리자 활동 감사 로그에 포함되므로, 사용 중지할 수 없습니다.
데이터 액세스 감사 로그의 볼륨 관리
데이터 액세스 감사 로그를 사용 설정할 때 목표는 보안 공개 상태 측면의 가치를 극대화하면서 비용 및 관리 오버헤드를 제한하는 것입니다. 이 목적을 달성하기 위해서는 다음을 수행하여 가치가 낮고 볼륨이 큰 로그를 필터링하는 것이 좋습니다.
- 민감한 워크로드, 키, 데이터를 호스팅하는 서비스와 같이 관련 서비스에 우선순위를 지정합니다. 다른 것보다 우선시 하려는 서비스의 특정 예시는 데이터 액세스 감사 로그 구성 예시를 참조하세요.
개발자 및 스테이징 환경을 호스팅하는 프로젝트가 아닌 프로덕션 워크로드를 호스팅하는 프로젝트 등 관련 프로젝트에 우선순위를 지정합니다. 특정 프로젝트의 모든 로그를 필터링하려면 싱크에 대한 로그 필터에 다음 표현식을 추가합니다. PROJECT_ID를 모든 로그를 필터링할 프로젝트의 ID로 바꾸세요.
프로젝트 로그 필터 표현식 지정된 프로젝트에서 모든 로그 제외 NOT logName =~ "^projects/PROJECT_ID"
최소한의 기록 작업 세트에는
ADMIN_READ,DATA_READ또는DATA_WRITE와 같은 데이터 액세스 작업 하위 집합의 우선순위를 지정합니다. 예를 들어 Cloud DNS와 같은 일부 서비스는 세 가지 작업 유형을 모두 기록하지만ADMIN_READ작업에만 로깅을 사용 설정할 수 있습니다. 이러한 세 가지 데이터 액세스 작업 유형 중 하나를 구성한 다음 특히 볼륨이 높은 특정 작업을 제외할 수 있습니다. 싱크의 로그 필터를 수정하여 이러한 높은 볼륨의 작업을 제외할 수 있습니다. 예를 들어 일부 중요한 스토리지 서비스에서DATA_READ작업을 포함하여 전체 데이터 액세스 감사 로깅을 사용 설정한다고 가정해보세요. 이 상황에서 트래픽이 많은 특정 데이터 읽기 작업을 제외하려면 다음 권장 로그 필터 표현식을 싱크의 로그 필터에 추가할 수 있습니다.서비스 로그 필터 표현식 Cloud Storage의 대용량 로그 제외 NOT (resource.type="gcs_bucket" AND (protoPayload.methodName="storage.buckets.get" OR protoPayload.methodName="storage.buckets.list"))
Cloud SQL의 대용량 로그 제외 NOT (resource.type="cloudsql_database" AND protoPayload.request.cmd="select")
가장 민감한 워크로드와 데이터를 호스팅하는 리소스 등 관련 리소스에 우선순위를 지정합니다. 리소스가 처리하는 데이터의 가치와 외부에서 액세스할 수 있는지 여부와 같은 보안 위험에 따라 리소스를 분류할 수 있습니다. 데이터 액세스 감사 로그가 서비스별로 사용 설정되지만 로그 필터를 통해 특정 리소스 또는 리소스 유형을 필터링할 수 있습니다.
데이터 액세스가 기록되지 않도록 특정 주 구성원을 제외합니다. 예를 들어 내부 테스트 계정의 작업 기록을 면제할 수 있습니다. 자세한 내용은 데이터 액세스 감사 로그 문서에서 예외 설정을 참조하세요.
데이터 액세스 감사 로그 구성 예시
다음 표는 Google Cloud 프로젝트가 중요한 보안 공개 상태를 확보하면서 로그 볼륨을 제한하는 데 사용할 수 있는 기본 데이터 액세스 감사 로그 구성을 제공합니다.
| 등급 | 서비스 | 데이터 액세스 감사 로그 유형 | MITRE ATT&CK 전략 |
|---|---|---|---|
| 인증 및 승인 서비스 | IAM IAP(Identity-Aware Proxy)1 Cloud KMS Secret Manager Resource Manager |
ADMIN_READ DATA_READ |
탐색 사용자 인증 정보 액세스 권한 에스컬레이션 |
| 스토리지 서비스 | BigQuery (기본 사용 설정됨) Cloud Storage1, 2 |
DATA_READ DATA_WRITE |
수집 유출 |
| 인프라 서비스 | Compute Engine 조직 정책 |
ADMIN_READ | 탐색 |
1 IAP 또는 Cloud Storage의 데이터 액세스 감사 로그를 사용 설정하면 IAP로 보호되는 웹 리소스나 Cloud Storage에 대한 트래픽이 많은 경우 로그 볼륨이 커질 수 있습니다.
2 Cloud Storage에 대해 데이터 액세스 감사 로그를 사용 설정하면 비공개 객체에 대한 인증된 브라우저 다운로드 사용이 중단될 수 있습니다. 이 문제에 대한 자세한 내용과 제안된 해결 방법은 Cloud Storage 문제 해결 가이드를 참조하세요.
예시 구성에서는 기본 데이터, 메타데이터 또는 구성을 기반으로 서비스가 민감도 계층별로 그룹화되는 방법을 확인합니다. 이러한 계층은 데이터 액세스 감사 로깅에 대한 다음과 같은 권장 세부사항을 보여줍니다.
- 인증 및 승인 서비스: 이 서비스 계층의 경우 모든 데이터 액세스 작업을 감사하는 것이 좋습니다. 이 수준의 감사는 민감한 키, 보안 비밀, IAM 정책에 대한 액세스를 모니터링하는 데 도움이 됩니다. 이 액세스를 모니터링하면 검색, 사용자 인증 정보 액세스, 권한 에스컬레이션과 같은 MITRE ATT&CK 전략을 감지하는 데 도움이 됩니다.
- 스토리지 서비스: 이 서비스 계층의 경우 사용자 제공 데이터와 관련된 데이터 액세스 작업을 감사하는 것이 좋습니다. 이 수준의 감사는 중요하고 민감한 정보에 대한 액세스를 모니터링하는 데 도움이 됩니다. 이 액세스를 모니터링하면 데이터에 대한 컬렉션 및 유출과 같은 MITRE ATT&CK 전략을 감지하는 데 도움이 됩니다.
- 인프라 서비스: 이 서비스 계층의 경우 메타데이터 또는 구성 정보와 관련된 데이터 액세스 작업을 감사하는 것이 좋습니다. 이러한 감사 수준은 인프라 구성 스캔을 모니터링하는 데 도움이 됩니다. 이 액세스를 모니터링하면 워크로드에 대해 탐색과 같은 MITRE ATT&CK 전략을 감지할 수 있습니다.
로그 라우팅
로그를 식별하고 사용 설정하면 다음 단계는 로그를 단일 대상으로 라우팅하는 것입니다. 라우팅 대상, 경로, 복잡성은 다음 다이어그램과 같이 사용하는 분석 도구에 따라 달라집니다.
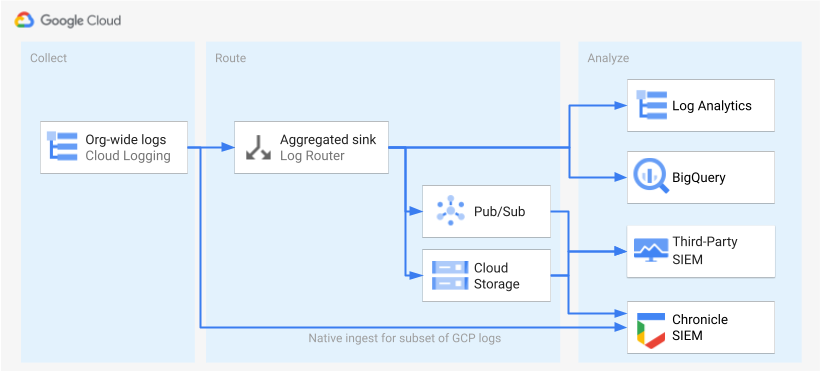
이 다이어그램은 다음 라우팅 옵션을 보여줍니다.
Log Analytics를 사용하는 경우 Google Cloud 조직의 로그를 단일 Cloud Logging 버킷으로 집계하려면 집계 싱크가 필요합니다.
BigQuery를 사용하는 경우 Google Cloud 조직의 로그를 단일 BigQuery 데이터 세트로 집계하려면 집계 싱크가 필요합니다.
Google Security Operations를 사용 중이고 이 미리 정의된 로그 집합이 보안 분석 요구를 충족할 경우 기본 제공되는 Google Security Operations 수집을 사용하여 Google Security Operations 계정에 로그를 자동으로 집계할 수 있습니다. 또한 로그 범위 지정 도구의 Google Security Operations로 직접 내보내기 열을 통해 사전 정의된 이 로그 세트를 볼 수 있습니다. 미리 정의된 로그 내보내기에 대한 자세한 내용은 Google Security Operations에 Google Cloud 로그 수집을 참조하세요.
BigQuery 또는 서드 파티 SIEM을 사용하거나 확장된 로그 세트를 Google Security Operations로 내보내려는 경우 이 다이어그램은 로그를 사용 설정하는 단계와 해당 로그를 분석하는 단계 사이에 추가 단계가 필요함을 보여줍니다. 이 추가 단계는 선택한 로그를 적절하게 라우팅하는 집계 싱크를 구성하는 것이 포함됩니다. BigQuery를 사용하는 경우 이 싱크만 있으면 로그를 BigQuery로 라우팅할 수 있습니다. 서드 파티 SIEM을 사용하는 경우 싱크에서 Pub/Sub 또는 Cloud Storage에서 선택한 로그를 집계해야 로그를 분석 도구로 가져올 수 있습니다.
Google Security Operations 및 서드 파티 SIEM의 라우팅 옵션은 이 가이드에서 다루지 않습니다. 그러나 다음 섹션에서는 로그를 Log Analytics 또는 BigQuery로 라우팅하는 세부 단계를 설명합니다.
- 단일 대상 설정
- 집계 로그 싱크 만들기
- 싱크에 액세스 권한 부여
- 대상에 읽기 액세스 구성
- 로그가 대상으로 라우팅되는지 확인
단일 대상 설정
로그 애널리틱스
로그를 집계하려는 Google Cloud 프로젝트에서 Google Cloud 콘솔을 엽니다.
Cloud Shell 터미널에서 다음
gcloud명령어를 실행하여 로그 버킷을 만듭니다.gcloud logging buckets create BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID다음을 바꿉니다.
PROJECT_ID: 집계된 로그가 저장될 Google Cloud 프로젝트의 ID입니다.BUCKET_NAME: 새 Logging 버킷의 이름입니다.BUCKET_LOCATION: 새 Logging 버킷의 지리적 위치입니다. 지원되는 위치는global,us또는eu입니다. 이러한 스토리지 리전에 대한 자세한 내용은 지원되는 리전을 참조하세요. 위치를 지정하지 않으면global리전이 사용되며 이는 로그가 모든 리전에 물리적으로 위치할 수 있다는 뜻입니다.
버킷이 생성되었는지 확인합니다.
gcloud logging buckets list --project=PROJECT_ID(선택사항) 버킷에 있는 로그의 보관 기간을 설정합니다. 다음 예시에서는 버킷에 저장된 로그 보관을 365일로 연장합니다.
gcloud logging buckets update BUCKET_NAME \ --location=BUCKET_LOCATION \ --project=PROJECT_ID \ --retention-days=365이 단계에 따라 Log Analytics를 사용하도록 새 버킷을 업그레이드합니다.
BigQuery
로그를 집계하려는 Google Cloud 프로젝트에서 Google Cloud 콘솔을 엽니다.
Cloud Shell 터미널에서 다음
bq mk명령어를 실행하여 데이터 세트를 만듭니다.bq --location=DATASET_LOCATION mk \ --dataset \ --default_partition_expiration=PARTITION_EXPIRATION \ PROJECT_ID:DATASET_ID다음을 바꿉니다.
PROJECT_ID: 집계된 로그가 저장될 Google Cloud 프로젝트의 ID입니다.DATASET_ID: 새 BigQuery 데이터 세트의 ID입니다.DATASET_LOCATION: 데이터 세트의 지리적 위치입니다. 데이터 세트가 생성된 후에는 위치를 변경할 수 없습니다.PARTITION_EXPIRATION: 로그 싱크에서 만들고 파티션을 나눈 테이블의 파티션 기본 수명(초)입니다. 다음 섹션에서 로그 싱크를 구성합니다. 사용자가 구성한 로그 싱크는 로그 항목의 타임스탬프를 기준으로 날짜별로 분할된 파티션을 나눈 테이블을 사용합니다. 파티션(연결된 로그 항목 포함)은 파티션 날짜로부터PARTITION_EXPIRATION초 후에 삭제됩니다.
집계 로그 싱크 만들기
조직 수준에서 집계 싱크를 만들어 조직 로그를 대상으로 라우팅합니다. 로그 범위 지정 도구에서 선택한 모든 로그를 포함하려면 로그 범위 지정 도구로 생성된 로그 필터로 싱크를 구성합니다.
로그 애널리틱스
Cloud Shell 터미널에서 다음
gcloud명령어를 실행하여 조직 수준에서 집계 싱크를 만듭니다.gcloud logging sinks create SINK_NAME \ logging.googleapis.com/projects/PROJECT_ID/locations/BUCKET_LOCATION/buckets/BUCKET_NAME \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --include-children다음을 바꿉니다.
SINK_NAME: 로그를 라우팅하는 싱크의 이름입니다.PROJECT_ID: 집계된 로그가 저장될 Google Cloud 프로젝트의 ID입니다.BUCKET_LOCATION: 로그 스토리지용으로 만든 Logging 버킷의 위치입니다.BUCKET_NAME: 로그 스토리지용으로 만든 Logging 버킷의 이름입니다.LOG_FILTER: 로그 지정 범위 도구에서 저장한 로그 필터입니다.ORGANIZATION_ID: 조직의 리소스 ID입니다.
--include-children플래그는 중요하므로 조직 내 모든Google Cloud 프로젝트의 로그도 포함됩니다. 자세한 내용은 조직 수준 로그를 취합하여 지원되는 대상으로 라우팅을 참고하세요.싱크가 만들어졌는지 확인합니다.
gcloud logging sinks list --organization=ORGANIZATION_ID방금 만든 싱크와 연결된 서비스 계정의 이름을 가져옵니다.
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_ID결과는 다음과 유사합니다.
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`serviceAccount:로 시작하는
writerIdentity의 전체 문자열을 복사합니다. 이 식별자는 싱크의 서비스 계정입니다. 이 서비스 계정에 로그 버킷에 대한 쓰기 액세스 권한을 부여하기 전까지 이 싱크에서 수행되는 로그 라우팅은 실패합니다. 다음 섹션에서 싱크의 작성자 ID에 쓰기 액세스 권한을 부여합니다.
BigQuery
Cloud Shell 터미널에서 다음
gcloud명령어를 실행하여 조직 수준에서 집계 싱크를 만듭니다.gcloud logging sinks create SINK_NAME \ bigquery.googleapis.com/projects/PROJECT_ID/datasets/DATASET_ID \ --log-filter="LOG_FILTER" \ --organization=ORGANIZATION_ID \ --use-partitioned-tables \ --include-children다음을 바꿉니다.
SINK_NAME: 로그를 라우팅하는 싱크의 이름입니다.PROJECT_ID: 로그를 집계할 Google Cloud 프로젝트의 ID입니다.DATASET_ID: 만든 BigQuery 데이터 세트의 ID입니다.LOG_FILTER: 로그 지정 범위 도구에서 저장한 로그 필터입니다.ORGANIZATION_ID: 조직의 리소스 ID입니다.
--include-children플래그는 중요하므로 조직 내 모든Google Cloud 프로젝트의 로그도 포함됩니다. 자세한 내용은 조직 수준 로그를 취합하여 지원되는 대상으로 라우팅을 참고하세요.--use-partitioned-tables플래그는 로그 항목의timestamp필드를 기준으로 날짜별로 데이터 파티션이 나뉘도록 하는 데 중요합니다. 이렇게 하면 데이터 쿼리가 간소화되고 쿼리로 스캔하는 데이터 양이 줄어들어 쿼리 비용을 절감할 수 있습니다. 파티션을 나눈 테이블의 또 다른 이점은 로그 보관 요구사항을 충족하도록 데이터 세트 수준에서 기본 파티션 만료 시간을 설정할 수 있다는 점입니다. 이전 섹션에서 데이터 세트 대상을 만들 때 기본 파티션 만료 시간을 이미 설정했습니다. 개별 테이블 수준에서 파티션 만료 시간 설정을 선택하여 로그 유형에 따라 세분화된 데이터 보관 제어 기능을 제공할 수도 있습니다.싱크가 만들어졌는지 확인합니다.
gcloud logging sinks list --organization=ORGANIZATION_ID방금 만든 싱크와 연결된 서비스 계정의 이름을 가져옵니다.
gcloud logging sinks describe SINK_NAME --organization=ORGANIZATION_ID결과는 다음과 유사합니다.
writerIdentity: serviceAccount:p1234567890-12345@logging-o1234567890.iam.gserviceaccount.com`serviceAccount:로 시작하는
writerIdentity의 전체 문자열을 복사합니다. 이 식별자는 싱크의 서비스 계정입니다. 이 서비스 계정에 BigQuery 데이터 세트에 대한 쓰기 액세스 권한을 부여하기 전까지 이 싱크에서 수행되는 로그 라우팅은 실패합니다. 다음 섹션에서 싱크의 작성자 ID에 쓰기 액세스 권한을 부여합니다.
싱크에 액세스 권한 부여
로그 싱크를 만든 후에는 대상 위치(Logging 버킷 또는 BigQuery 데이터 세트)에 쓸 수 있는 액세스 권한을 싱크에 부여해야 합니다.
로그 애널리틱스
싱크의 서비스 계정에 권한을 추가하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 IAM 페이지로 이동합니다.
중앙 로그 스토리지용으로 만든 Logging 버킷이 포함된 대상 Google Cloud 프로젝트를 선택했는지 확인합니다.
person_add액세스 권한 부여를 클릭합니다.
새 주 구성원 필드에
serviceAccount:프리픽스 없이 싱크의 서비스 계정을 입력합니다. 이 ID는 싱크를 만든 후 이전 섹션에서 가져온writerIdentity필드에서 비롯된 것입니다.역할 선택 드롭다운 메뉴에서 로그 버킷 작성자를 선택합니다.
IAM 조건 추가를 클릭하여 생성한 로그 버킷으로만 서비스 계정의 액세스를 제한합니다.
조건의 제목 및 설명을 입력합니다.
조건 유형 드롭다운 메뉴에서 리소스 > 이름을 선택합니다.
연산자 드롭다운 메뉴에서 다음으로 종료를 선택합니다.
값 필드에 다음과 같이 버킷의 위치와 이름을 입력합니다.
locations/BUCKET_LOCATION/buckets/BUCKET_NAME저장을 클릭하여 조건을 추가합니다.
저장을 클릭하여 권한을 설정합니다.
BigQuery
싱크의 서비스 계정에 권한을 추가하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery로 이동합니다.
중앙 로그 스토리지용으로 만든 BigQuery 데이터 세트를 엽니다.
데이터 세트 정보 탭에서 공유keyboard_arrow_down 드롭다운 메뉴를 클릭한 다음 권한을 클릭합니다.
데이터 세트 권한 측면 패널에서 주 구성원 추가를 클릭합니다.
새 주 구성원 필드에
serviceAccount:프리픽스 없이 싱크의 서비스 계정을 입력합니다. 이 ID는 싱크를 만든 후 이전 섹션에서 가져온writerIdentity필드에서 비롯된 것입니다.역할 드롭다운 메뉴에서 BigQuery 데이터 편집기를 선택합니다.
저장을 클릭합니다.
싱크에 액세스 권한을 부여하면 로그 항목이 싱크 대상(Logging 버킷 또는 BigQuery 데이터 세트)을 채우기 시작합니다.
대상에 읽기 액세스 구성
이제 로그 싱크가 전체 조직의 로그를 단일 대상으로 라우팅하므로 이러한 모든 로그를 검색할 수 있습니다. IAM 권한을 사용하여 권한을 관리하고 필요에 따라 액세스 권한을 부여합니다.
로그 애널리틱스
새 로그 버킷의 로그를 보고 쿼리할 수 있는 액세스 권한을 부여하려면 다음 단계를 수행합니다.
Google Cloud 콘솔에서 IAM 페이지로 이동합니다.
로그 집계에 사용할 Google Cloud 프로젝트를 선택했는지 확인합니다.
person_add추가를 클릭합니다.
새 주 구성원 필드에 이메일 계정을 추가합니다.
역할 선택 드롭다운 메뉴에서 로그 뷰 접근자를 선택합니다.
이 역할은 새로 추가된 주 구성원에게 Google Cloud 프로젝트에 있는 버킷의 모든 보기에 대한 읽기 권한을 제공합니다. 사용자 액세스를 제한하려면 사용자가 새 버킷에서만 읽기를 수행할 수 있게 하는 조건을 추가합니다.
조건 추가를 클릭합니다.
조건의 제목 및 설명을 입력합니다.
조건 유형 드롭다운 메뉴에서 리소스 > 이름을 선택합니다.
연산자 드롭다운 메뉴에서 다음으로 종료를 선택합니다.
값 필드에 다음과 같이 버킷 위치 및 이름과 기본 로그 뷰
_AllLogs를 입력합니다.locations/BUCKET_LOCATION/buckets/BUCKET_NAME/views/_AllLogs저장을 클릭하여 조건을 추가합니다.
저장을 클릭하여 권한을 설정합니다.
BigQuery
BigQuery 데이터 세트의 로그를 보고 쿼리할 수 있는 액세스 권한을 부여하려면 BigQuery 문서의 데이터 세트에 대한 액세스 권한 부여 섹션의 단계를 따르세요.
로그가 대상으로 라우팅되는지 확인
로그 애널리틱스
Log Analytics로 업그레이드된 로그 버킷으로 로그를 라우팅하면 모든 로그 유형에 대한 통합 스키마가 있는 단일 로그 뷰를 통해 모든 로그 항목을 보고 쿼리할 수 있습니다. 로그가 올바르게 라우팅되는지 확인하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 로그 분석 페이지로 이동합니다.
로그 집계에 사용할 Google Cloud 프로젝트를 선택했는지 확인합니다.
로그 뷰 탭을 클릭합니다.
아직 펼치지 않은 경우 생성한 로그 버킷(즉,
BUCKET_NAME)에서 로그 뷰를 펼칩니다.기본 로그 뷰
_AllLogs를 선택합니다. 이제 다음 스크린샷과 같이 오른쪽 패널에서 전체 로그 스키마를 검사할 수 있습니다.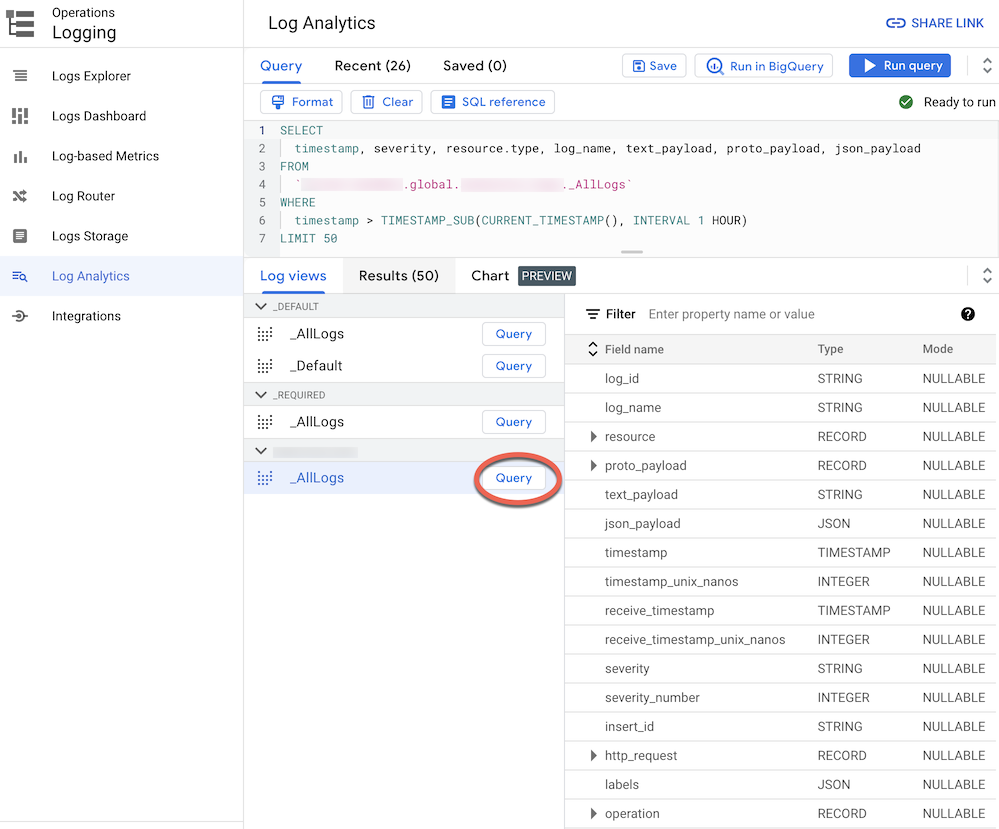
_AllLogs옆의 쿼리를 클릭합니다. 그러면 쿼리 편집기가 SQL 샘플 쿼리로 채워져 최근에 라우팅된 로그 항목을 검색합니다.쿼리 실행을 클릭하여 최근에 라우팅된 로그 항목을 확인합니다.
조직의 Google Cloud 프로젝트 활동 수준에 따라 일부 로그가 생성될 때까지 몇 분 정도 기다린 다음 로그 버킷으로 라우팅해야 할 수 있습니다.
BigQuery
BigQuery 데이터 세트로 로그를 라우팅하면 Cloud Logging이 다음 스크린샷에 표시된 것처럼 라우팅한 로그 항목을 저장할 BigQuery 테이블을 만듭니다.
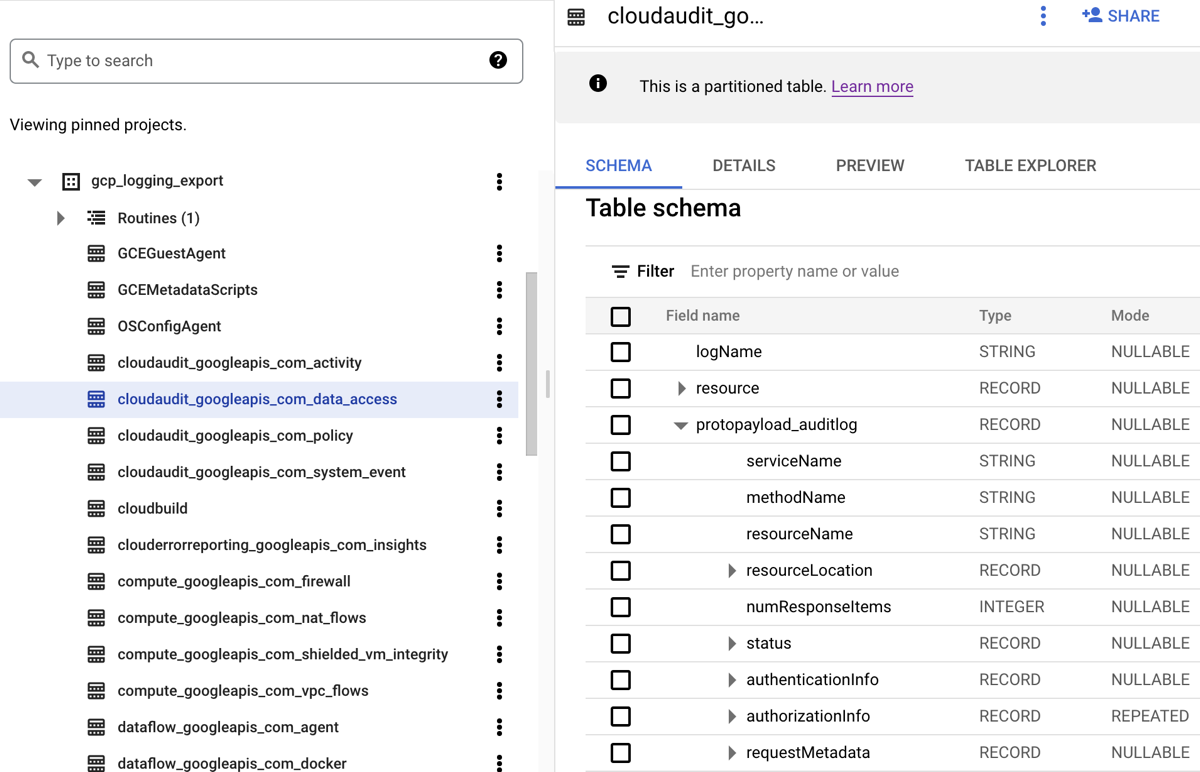
이 스크린샷은 로그 항목이 포함되는 로그 이름을 기준으로 Cloud Logging이 각 BigQuery 테이블 이름을 지정하는 방법을 보여줍니다. 예를 들어 스크린샷에서 선택한 cloudaudit_googleapis_com_data_access 테이블에는 해당 로그 ID가 cloudaudit.googleapis.com%2Fdata_access인 데이터 액세스 감사 로그가 포함됩니다. 해당 로그 항목을 기준으로 이름을 지정하는 것 외에도 각 로그 항목에 대한 타임스탬프를 기준으로 각 테이블의 파티션을 나눕니다.
조직의 Google Cloud 프로젝트 활동 수준에 따라 일부 로그가 생성될 때까지 몇 분 정도 기다린 다음 BigQuery 데이터 세트로 라우팅해야 할 수 있습니다.
로그 분석
감사 및 플랫폼 로그에 대해 다양한 쿼리를 실행할 수 있습니다. 다음 목록은 자체 로그에 질문할 수 있는 일련의 샘플 보안 질문을 보여줍니다. 이 목록의 각 질문에는 해당 CSA 쿼리의 두 가지 버전이 있습니다. 하나는 Log Analytics용이고 다른 하나는 BigQuery용입니다. 이전에 설정한 싱크 대상과 일치하는 쿼리 버전을 사용하세요.
로그 애널리틱스
아래의 SQL 쿼리를 사용하기 전에 MY_PROJECT_ID를 로그 버킷을 만든 Google Cloud 프로젝트의 ID로 바꾸고 PROJECT_ID)를 해당 로그 버킷의 리전 및 이름(BUCKET_LOCATION.BUCKET_NAME)으로 바꿉니다.MY_DATASET_ID
BigQuery
아래의 SQL 쿼리를 사용하기 전에 MY_PROJECT_ID를 BigQuery 데이터 세트를 만든 Google Cloud 프로젝트의 ID (PROJECT_ID))로 바꾸고 MY_DATASET_ID를 해당 데이터 세트의 이름인 DATASET_ID로 바꿉니다.
로그인 및 액세스 관련 질문
이러한 샘플 쿼리는 Google Cloud 환경에 대한 의심스러운 로그인 시도 또는 초기 액세스 시도를 감지하기 위해 분석을 수행합니다.
Google Workspace에서 신고한 의심스러운 로그인 시도가 있나요?
다음 쿼리는 Google Workspace 로그인 감사에 포함된 Cloud ID 로그를 검색하여 Google Workspace에서 플래그 지정된 의심스러운 로그인 시도를 감지합니다. 이러한 로그인 시도는 Google Cloud 콘솔, Admin 콘솔 또는 gcloud CLI에서 수행될 수 있습니다.
로그 애널리틱스
BigQuery
사용자 ID로 인한 로그인 실패가 과도하게 발생하나요?
다음 쿼리는 Google Workspace 로그인 감사에 포함된 Cloud ID 로그를 검색하여 이전 24시간 내에 세 번 이상의 연속적인 로그인 실패가 발생한 사용자를 감지합니다.
로그 애널리틱스
BigQuery
VPC 서비스 제어를 위반하는 액세스 시도가 있나요?
다음 쿼리는 Cloud 감사 로그에서 거부된 정책 감사 로그를 분석하여 VPC 서비스 제어로 차단된 액세스 시도를 감지합니다. 모든 쿼리 결과는 도난 당한 사용자 인증 정보를 사용하여 승인되지 않은 네트워크에서 발생하는 액세스 시도와 같은 잠재적으로 악의적인 활동을 나타낼 수 있습니다.
로그 애널리틱스
BigQuery
IAP 액세스 제어를 위반하는 액세스 시도가 있나요?
다음 쿼리는 외부 애플리케이션 부하 분산기 로그를 분석하여 IAP에 의해 차단된 액세스 시도를 감지합니다. 쿼리 결과를 보면 초기 액세스 시도 또는 취약점 악용 시도가 있을 수 있습니다.
로그 애널리틱스
BigQuery
권한 변경사항 관련 질문
이러한 샘플 쿼리는 IAM 정책의 변경사항, 그룹 및 그룹 멤버십, 서비스 계정, 모든 연관된 키를 포함하여 권한을 변경하는 관리자 활동에 대한 분석을 수행합니다. 이러한 권한 변경은 민감한 정보 또는 환경에 대해 높은 액세스 수준을 제공할 수 있습니다.
상위 권한이 부여된 그룹에 추가된 사용자가 있나요?
다음 쿼리는 Google Workspace 관리자 감사 감사 로그를 분석하여 쿼리에 나열된 높은 권한이 부여된 그룹에 추가된 사용자를 감지합니다. 쿼리에서 정규 표현식을 사용하여 모니터링할 그룹(예: admin@example.com 또는 prod@example.com)을 정의합니다. 모든 쿼리 결과는 악의적이거나 우연적인 권한 에스컬레이션을 나타낼 수 있습니다.
로그 애널리틱스
BigQuery
서비스 계정을 통해 부여된 권한이 있나요?
다음 쿼리는 Cloud 감사 로그에서 관리자 활동 감사 로그를 분석하여 서비스 계정을 통해 주 구성원에 부여된 모든 권한을 감지합니다. 부여될 수 있는 권한 예시에는 서비스 계정을 가장하는 권한 또는 서비스 계정 키 생성 권한이 있습니다. 모든 쿼리 결과는 권한 에스컬레이션 사례 또는 사용자 인증 정보 유출 위험을 나타낼 수 있습니다.
로그 애널리틱스
BigQuery
승인되지 않은 ID로 생성된 서비스 계정 또는 키가 있나요?
다음 쿼리는 관리자 활동 감사 로그를 분석하여 사용자가 수동으로 만든 서비스 계정 또는 키를 감지합니다. 예를 들어 자동화된 워크플로의 일부로 승인된 서비스 계정에 의해서만 서비스 계정을 만들도록 권장사항을 따라야 할 수 있습니다. 따라서 이 워크플로 외부의 서비스 계정 생성은 규정을 준수하지 않고 악의적인 것으로 고려됩니다.
로그 애널리틱스
BigQuery
민감한 IAM 정책에 추가되거나 삭제되는 사용자가 있나요?
다음 쿼리는 관리자 활동 감사 로그를 검색하여 Compute Engine 백엔드 서비스와 같은 IAP 보안 리소스에 대해 사용자 또는 그룹 액세스 변경을 감지합니다. 다음 쿼리는 IAM 역할 roles/iap.httpsResourceAccessor가 관련된 IAP 리소스에 대한 모든 IAM 정책 업데이트를 검색합니다. 이 역할은 HTTPS 리소스 또는 백엔드 서비스에 액세스하기 위한 권한을 제공합니다. 모든 쿼리 결과는 인터넷에 노출될 수 있는 백엔드 서비스 방어를 우회하려는 시도를 나타낼 수 있습니다.
로그 애널리틱스
BigQuery
프로비저닝 활동 관련 질문
이러한 샘플 쿼리는 리소스 프로비저닝 및 구성과 같은 의심스럽거나 이상한 관리자 활동을 감지하는 분석을 수행합니다.
로깅 설정에 변경된 사항이 있나요?
다음 쿼리는 관리자 활동 감사 로그를 검색하여 로깅 설정에 대한 변경사항을 감지합니다. 로깅 설정을 모니터링하면 사고로 인한 또는 악의적인 감사 로그 사용 중지 및 비슷한 방어 회피 기술을 감지하는 데 도움이 됩니다.
로그 애널리틱스
BigQuery
사용 중지된 VPC 흐름 로그가 있나요?
다음 쿼리는 관리자 활동 감사 로그를 검색하여 VPC 흐름 로그가 명시적으로 사용 중지된 서브넷을 감지합니다. VPC 흐름 로그 설정을 모니터링하면 사고로 인한 또는 악의적인 VPC 흐름 로그 사용 중지 및 비슷한 방어 회피 기술을 감지하는 데 도움이 됩니다.
로그 애널리틱스
BigQuery
지난주 수정한 방화벽 규칙이 비정상적으로 많나요?
다음 쿼리는 관리자 활동 감사 로그를 검색하여 이전 주의 특정 일자에 비정상적으로 높게 발생한 방화벽 규칙 변경사항을 감지합니다. 이 쿼리는 이상점이 있는지 확인하기 위해 일별 방화벽 규칙 변경 횟수에 대해 통계적 분석을 수행합니다. 평균 및 표준 편차는 전환 확인 기간이 90일인 이전 일일 개수를 살펴봄으로써 각 날짜에 대해 계산됩니다. 일별 횟수가 평균 이상의 2개의 표준 편차보다 크면 이상점이 있다고 고려됩니다. 표준 편차 계수 및 전환 확인 기간을 포함하여 클라우드 프로비저닝 활동 프로필에 맞게 그리고 거짓양성을 최소화하도록 쿼리를 구성할 수 있습니다.
로그 애널리틱스
BigQuery
지난주에 삭제된 VM이 있나요?
다음 쿼리는 관리자 활동 감사 로그를 검색하여 이전 주에 삭제된 모든 Compute Engine 인스턴스를 나열합니다. 이 쿼리는 리소스 삭제를 감사하고 잠재적인 악의적인 활동을 감지하는 데 도움이 됩니다.
로그 애널리틱스
BigQuery
워크로드 사용 관련 질문
이러한 샘플 쿼리는 클라우드 워크로드 및 API를 소비 중인 사용자 및 항목을 이해하기 위해 분석을 수행하고, 내부 또는 외부적으로 잠재적인 악의적인 행동을 감지하는 데 도움이 됩니다.
지난주에 사용자 ID에 의한 API 사용량이 크게 증가했나요?
모든 Cloud 감사 로그를 분석하면 다음 쿼리는 지난주 특정 날짜의 사용자 ID에 따라 비정상적으로 높은 API 사용량을 감지합니다. 이렇게 비정상적으로 높은 사용량은 잠재적인 API 남용, 내부자 위협, 사용자 인증 정보 누출을 나타낼 수 있습니다. 이상점이 있는지 확인하기 위해 이 쿼리는 주 구성원별로 수행되는 일별 작업 수에 대해 통계적 분석을 수행합니다. 평균 및 표준 편차는 전환 확인 기간이 60일인 이전 일일 개수를 살펴봄으로써 각 날짜 및 각 주 구성원에 대해 계산됩니다. 사용자의 일별 개수가 평균 이상의 3개 표준 편차보다 크면 이상점이 있다고 고려됩니다. 표준 편차 계수 및 전환 확인 기간을 포함하여 클라우드 프로비저닝 활동 프로필에 맞게 그리고 거짓양성을 최소화하도록 쿼리를 구성할 수 있습니다.
로그 애널리틱스
BigQuery
지난달의 일일 자동 확장 사용량은 얼마인가요?
다음 쿼리는 관리자 활동 감사 로그를 분석하여 지난 달 일별 자동 확장 사용량을 보고합니다. 이 쿼리는 추가적인 보안 조사를 보장하는 패턴 또는 이상점을 식별하기 위해 사용할 수 있습니다.
로그 애널리틱스
BigQuery
데이터 액세스 관련 질문
이러한 샘플 쿼리는 분석을 통해 Google Cloud에서 데이터를 액세스 또는 수정하는 사람을 파악합니다.
지난 주 데이터에 가장 많이 액세스한 사용자
다음 쿼리는 데이터 액세스 감사 로그를 사용하여 지난주 BigQuery 테이블 데이터에 가장 자주 액세스한 사용자 ID를 찾습니다.
로그 애널리틱스
BigQuery
지난 달 'accounts' 테이블에서 데이터에 액세스한 사용자
다음 쿼리는 데이터 액세스 감사 로그를 사용하여 지난달에 지정된 accounts 테이블을 가장 많이 쿼리한 사용자 ID를 찾습니다.
다음 쿼리는 BigQuery 내보내기 대상의 MY_DATASET_ID 및 MY_PROJECT_ID 자리표시자 이외에 DATASET_ID 및 PROJECT_ID 자리표시자를 사용합니다. 이 예시의 accounts 테이블과 같은 액세스를 분석하는 대상 테이블을 지정하려면 DATASET_ID 및 PROJECT_ID 자리표시자로 바꿔야 합니다.
로그 애널리틱스
BigQuery
가장 많이 액세스된 테이블과 액세스한 사용자
다음 쿼리는 데이터 액세스 감사 로그를 사용하여 지난달 동안 가장 자주 읽고 수정한 데이터가 포함된 BigQuery 테이블을 찾습니다. 데이터를 읽은 횟수와 수정한 총 횟수를 분석하여 관련 사용자 ID를 표시합니다.
로그 애널리틱스
BigQuery
지난주 BigQuery에서 수행된 최상위 10개 쿼리
다음 쿼리는 데이터 액세스 감사 로그를 사용하여 지난주 동안 가장 일반적인 쿼리를 찾습니다. 또한 해당 사용자와 참조된 테이블이 나열됩니다.
로그 애널리틱스
BigQuery
지난달 데이터 액세스 로그에 기록된 가장 일반적인 작업
다음 쿼리는 Cloud 감사 로그의 모든 로그를 사용하여 지난달에 기록된 가장 많이 발생한 작업 100개를 찾습니다.
로그 애널리틱스
BigQuery
네트워크 보안 관련 질문
이 샘플 쿼리는 Google Cloud에서 네트워크 활동에 대한 분석을 수행합니다.
새 IP 주소에서 특정 서브네트워크로의 연결이 있나요?
다음 쿼리는 VPC 흐름 로그를 분석하여 새로운 소스 IP 주소에서 지정된 서브넷으로의 연결을 감지합니다. 이 예시에서 전환 확인 기간 60일의 마지막 24시간 동안에 처음 표시된 소스 IP 주소는 새 IP로 간주됩니다. PCI와 같은 특정 규정 준수 요구사항을 충족하는 범위에 있는 서브넷에서 이 쿼리를 사용하고 조정할 수 있습니다.
로그 애널리틱스
BigQuery
Google Cloud Armor에서 차단한 연결이 있나요?
다음 쿼리를 사용하면 외부 애플리케이션 부하 분산기 로그를 분석하여 Google Cloud Armor에 구성된 보안 정책에서 차단한 연결을 찾아 잠재적 악용 시도를 감지할 수 있습니다. 이 쿼리는 외부 애플리케이션 부하 분산기에 대해 Google Cloud Armor 보안 정책을 구성했다고 가정합니다. 또한 이 쿼리는 로그 범위 지정 도구에서 사용 설정 링크로 제공된 안내에 설명된 대로 외부 애플리케이션 부하 분산기 로깅을 사용 설정했다고 가정합니다.
로그 애널리틱스
BigQuery
Cloud IDS에서 감지된 심각도가 높은 바이러스나 멀웨어
다음 쿼리에서는 Cloud IDS 위협 로그를 검색하여 Cloud IDS에서 감지한 심각도가 높은 바이러스나 멀웨어를 보여줍니다. 이 쿼리에서는 Cloud IDS 엔드포인트가 구성되어 있다고 가정합니다.
로그 애널리틱스
BigQuery
VPC 네트워크에서 최상위 Cloud DNS 쿼리 도메인
다음 쿼리에서는 지난 60일 동안 VPC 네트워크의 Cloud DNS 쿼리 도메인 상위 10개를 나열합니다. 이 쿼리에서는 로그 범위 지정 도구의 사용 설정 링크로 제공된 안내에 설명된 대로 VPC 네트워크에 대해 Cloud DNS 로깅을 사용 설정했다고 가정합니다.
로그 애널리틱스
BigQuery
다음 단계
Google Cloud 에서 Splunk로 로그 스트리밍 방법 알아보기
Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기