我们建议您设计数据网格,以支持各种各样的数据使用场景。本文档介绍了组织中最常见的数据使用场景。此外,本文档还讨论了使用者在确定适合其场景的数据产品时必须考虑的信息,以及他们发现和使用数据产品的方式。了解这些因素可以帮助组织确保提供合适的指导和工具来支持数据使用者。
本文档是系列文章中的一篇,该系列介绍了如何在 Google Cloud上实现数据网格。本文档假定您已阅读并熟悉数据网格中的架构和职能以及使用 Google Cloud构建现代分布式数据网格所述的概念。
本系列文章包含以下部分:
- 数据网格中的架构和职能
- 为数据网格设计自助式数据平台
- 在数据网格中构建数据产品
- 发现和使用数据网格中的数据产品(本文档)
数据使用层的设计(具体地说,是基于数据领域的使用者使用数据产品的方式)取决于数据使用者要求。但前提条件是假设使用者考虑到了使用场景。假设他们已确定所需的数据,可以搜索中央数据产品目录来找到这些数据。如果数据不在目录中或未处于偏好状态(例如,如果接口不合适或 SLA 不足),则使用方必须联系数据提供方。
或者,使用者可以联系数据网格的卓越中心 (COE),以获得有关哪个网域最适合生产该数据产品的建议。数据使用者也可以询问如何发出请求。如果您的组织很大,则应实施以自助方式发出数据产品请求的流程。
数据使用者通过他们运行的应用使用数据产品。所需的数据洞见类型促进选择哪种使用数据的应用设计。在开发应用设计时,数据使用者还会确定他们在应用中使用数据产品的首选方式。他们建立对于这些数据的可信度和可靠性的所需信心。然后,数据使用者可以了解应用所需的数据产品接口和 SLA。
数据使用场景
为了让数据使用者创建数据应用,来源可以是一个或多个数据产品,也可以是数据使用者自己的网域中的数据。如在数据网格中构建数据产品中所述,分析数据产品可能会从基于各种物理数据存储区的数据产品构建。
虽然数据使用可以在同一网域中发生,但最常见的使用模式是搜索合适的数据产品(无论网域如何)作为应用的来源。当合适的数据产品存在于另一个网域中时,使用模式要求您设置后续机制,以跨网域访问和使用数据。数据使用步骤中讨论了如何使用在使用网域以外的网域中创建的数据产品。
架构
下图展示了一个示例场景,在此场景中,使用者通过一系列接口(包括已获授权的数据集和 API)使用数据产品。
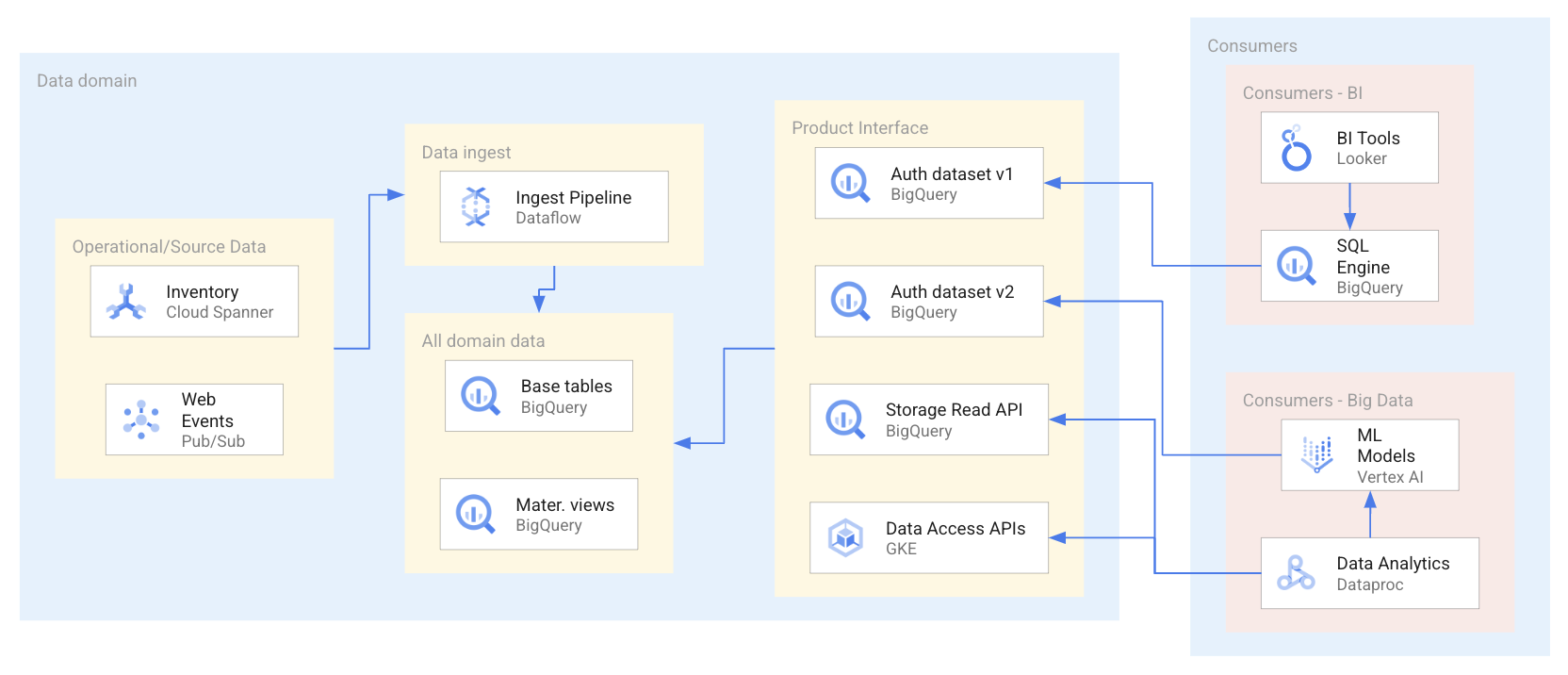
如上图所示,数据生产者公开了四个数据产品接口:两个 BigQuery 已获授权的数据集、一个通过 BigQuery Storage Read API 公开的 BigQuery 数据集和一个托管在 Google Kubernetes Engine 上的数据访问 API。使用数据产品时,数据使用者使用一系列查询或直接访问数据产品中的数据资源的应用。对于此场景,数据使用者根据其特定的数据访问要求采用两种不同的方法之一来访问数据资源。在第一种方法中,Looker 使用 BigQuery SQL 来查询已获授权的数据集。在第二种方法中,Dataproc 通过 BigQuery API 直接访问数据集,然后处理提取的数据以训练机器学习 (ML) 模型。
使用某个使用数据的应用并不总是能产生商业智能 (BI) 报告或 BI 信息中心。使用来自某个网域的数据还可能会导致机器学习模型进一步丰富分析产品、用于数据分析或成为运营流程的一部分(例如欺诈检测)。
一些典型的数据产品使用场景如下:
- BI 报告和数据分析:在本例中,构建数据应用以使用来自多个数据产品的数据。例如,来自客户关系管理 (CRM) 团队的数据使用者需要访问来自多个网域(如销售、客户和财务)的数据。这些数据使用方开发的 CRM 应用可能需要在一个网域中查询 BigQuery 授权视图,并在另一个网域中从 Cloud Storage Read API 中提取数据。对于数据使用者,影响其首选使用接口的优化因素是计算费用和查询数据产品后所需的任何其他数据处理。在 BI 和数据分析使用场景中,BigQuery 已授权的视图很可能最常使用。
- 数据科学使用场景和模型训练:在本例中,数据使用团队使用来自其他领域的数据产品来丰富自己的分析数据产品(如机器学习模型)。通过使用Google Cloud Serverless for Apache Spark for Spark, Google Cloud 提供了数据预处理和特征工程功能,以便在运行机器学习任务之前丰富数据。重要考虑因素是以合理的费用获得足够数量的训练数据,以及训练数据是合适的数据的信心。为了控制费用,首选使用接口可能是直接读取 API。数据使用团队可以将机器学习模型构建为数据产品,数据使用团队也转而成为新的数据生产团队。
- 运营流程:使用是数据使用网域中运营流程的一部分。例如,处理欺诈的团队中的数据使用者可能会使用来自商家网域中的运营数据源的交易数据。通过使用更改数据捕获等数据集成方法,此交易数据会近乎实时地被拦截。然后,您可以使用 Pub/Sub 定义此数据的架构并将该信息公开为事件。在本例中,合适的接口将是公开为 Pub/Sub 主题的数据。
数据使用步骤
数据生产者将其数据产品记录在中央目录中,包括有关如何使用数据的指导。对于具有多个网域的组织,此记录方法会创建一个与传统的集中构建的 ELT/ETL 流水线不同的架构,其中处理方会创建没有业务网域边界的输出。数据网格中的数据使用者必须具有精心设计的发现和使用层,才能创建数据使用生命周期。该层应包含以下内容:
第 1 步:通过声明式搜索和探索数据产品规范来发现数据产品:数据使用者可以搜索数据生产者在中央目录中注册的任何数据产品。对于所有数据产品,数据产品标记都指定如何发出数据访问请求以及从所需的数据产品接口使用数据的模式。数据产品标记中的字段可以使用搜索应用进行搜索。数据产品接口实现数据 URI,这意味着无需将数据移动到单独的使用区以供使用者使用。在不需要实时数据的情况下,使用者会查询数据产品并使用生成的结果创建报告。
第 2 步:通过交互式数据访问和原型设计来探索数据:数据使用者使用 BigQuery Studio 和 Jupyter Notebooks 等交互式工具解读和试验数据,以优化生产使用所需的查询。通过交互式查询,数据使用者可以探索较新的数据维度,并提高在生产场景中生成的数据分析的正确性。
第 3 步:通过应用使用数据产品(通过程序化访问和生产):
- BI 报告。近乎实时的批量报告和信息中心是数据使用者所需的最常见的分析使用场景组。报告可能需要跨数据产品访问权限,以帮助您做出决策。例如,客户数据平台需要按计划以编程方式查询订单和 CRM 数据产品。这种方法的结果是为使用数据的商家用户提供全面的客户视图。
- 用于实时批量预测的 AI/ML 模型。数据科学家使用常见的 MLOps 原则来构建和提供机器学习模型以使用数据产品团队提供的数据产品。机器学习模型为事务性使用场景(例如欺诈检测)提供实时推断功能。同样,通过探索性数据分析,数据使用者可以丰富来源数据。例如,关于销售和营销活动数据的探索性数据分析显示预计销售量最高的人口统计学特征客户细分,因此应举办营销活动。
后续步骤
- 查看数据网格架构的参考实现。
- 详细了解 BigQuery。
- 详细了解 Vertex AI。
- 了解 Dataproc 上的数据科学。
- 如需查看更多参考架构、图表和最佳做法,请浏览云架构中心。