Te recomendamos que diseñes tu malla de datos para que admita una amplia variedad de casos prácticos de consumo de datos. En este documento se describen los casos prácticos de consumo de datos más habituales en una organización. En el documento también se explica qué información deben tener en cuenta los consumidores de datos a la hora de determinar el producto de datos adecuado para su caso práctico, así como la forma en que descubren y usan los productos de datos. Conocer estos factores puede ayudar a las organizaciones a asegurarse de que cuentan con las directrices y las herramientas adecuadas para ayudar a los consumidores de datos.
Este documento forma parte de una serie en la que se describe cómo implementar una malla de datos en Google Cloud. Se da por hecho que has leído y conoces los conceptos descritos en Arquitectura y funciones de una malla de datos y Crea una malla de datos moderna y distribuida con Google Cloud.
La serie consta de las siguientes partes:
- Arquitectura y funciones de una malla de datos
- Diseñar una plataforma de datos de autoservicio para una malla de datos
- Crear productos de datos en una malla de datos
- Descubrir y consumir productos de datos en una malla de datos (este documento)
El diseño de una capa de consumo de datos, en concreto, cómo usan los consumidores basados en dominios de datos los productos de datos, depende de los requisitos de los consumidores de datos. Como requisito previo, se presupone que los consumidores tienen un caso práctico en mente. Se presupone que han identificado los datos que necesitan y pueden buscar en el catálogo de productos de datos central para encontrarlos. Si esos datos no están en el catálogo o no se encuentran en el estado preferido (por ejemplo, si la interfaz no es adecuada o los acuerdos de nivel de servicio no son suficientes), el consumidor debe ponerse en contacto con el productor de datos.
Por otro lado, el consumidor puede ponerse en contacto con el centro de excelencia (COE) de la malla de datos para recibir asesoramiento sobre qué dominio es el más adecuado para producir ese producto de datos. Los consumidores de datos también pueden preguntar cómo hacer su solicitud. Si tu organización es grande, debe haber un proceso para hacer solicitudes de productos de datos de forma autónoma.
Los consumidores de datos usan los productos de datos a través de las aplicaciones que ejecutan. El tipo de estadísticas que se necesiten determinará el diseño de la aplicación que consuma los datos. Cuando se desarrolla el diseño de la aplicación, el consumidor de datos también identifica el uso que prefiere dar a los productos de datos en la aplicación. De esta forma, se genera la confianza necesaria en la fiabilidad de esos datos. Los consumidores de datos pueden establecer una vista de las interfaces y los SLAs del producto de datos que requiere la aplicación.
Casos prácticos de consumo de datos
Para que los consumidores de datos puedan crear aplicaciones de datos, las fuentes pueden ser uno o varios productos de datos y, quizás, los datos del propio dominio del consumidor de datos. Como se describe en el artículo Crear productos de datos en una malla de datos, los productos de datos analíticos se pueden crear a partir de productos de datos basados en varios repositorios de datos físicos.
Aunque el consumo de datos puede producirse en el mismo dominio, los patrones de consumo más habituales son aquellos que buscan el producto de datos adecuado, independientemente del dominio, como fuente de la aplicación. Cuando el producto de datos adecuado se encuentra en otro dominio, el patrón de consumo requiere que configures el mecanismo posterior para acceder a los datos y usarlos en los distintos dominios. El consumo de productos de datos creados en dominios distintos del dominio de consumo se explica en la sección Pasos para consumir datos.
Arquitectura
En el siguiente diagrama se muestra un ejemplo de situación en la que los consumidores usan productos de datos a través de una serie de interfaces, incluidos conjuntos de datos autorizados y APIs.
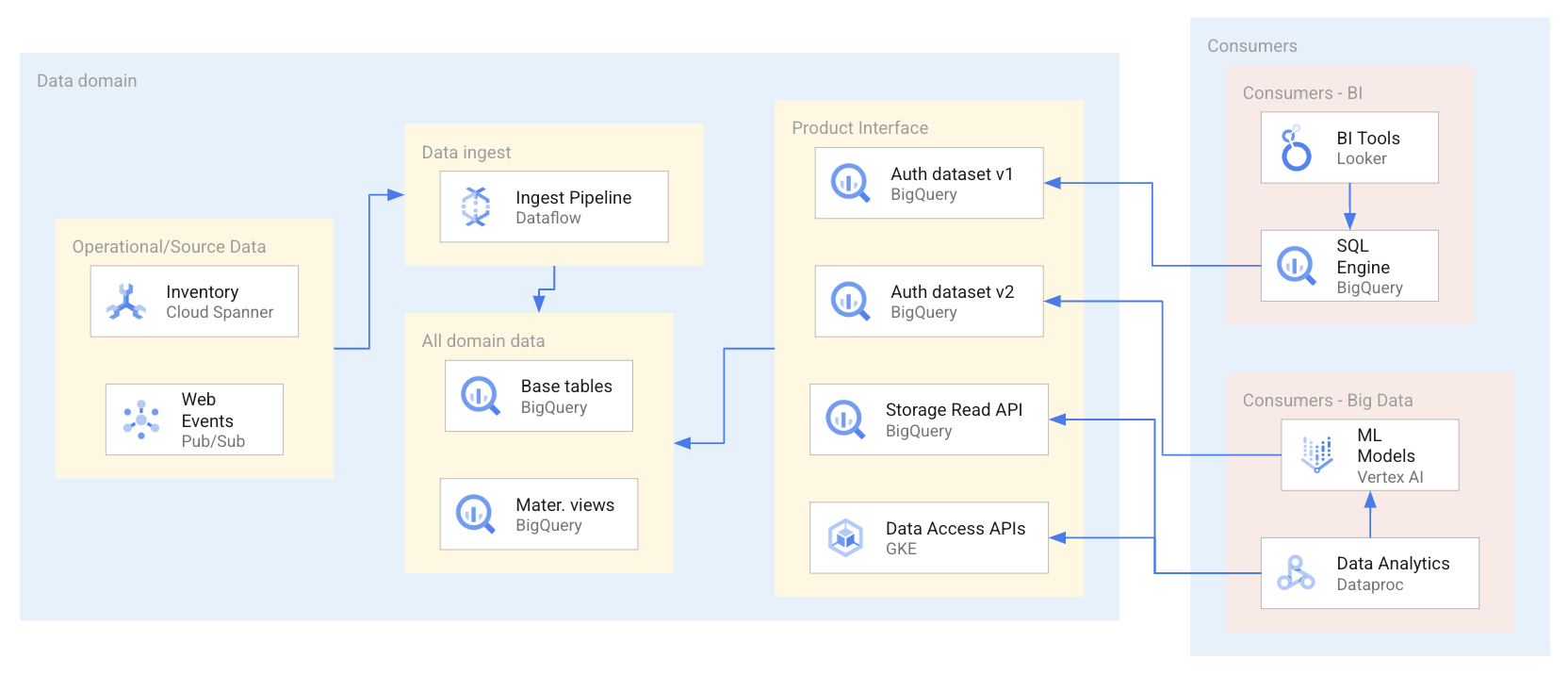
Como se muestra en el diagrama anterior, el productor de datos ha expuesto cuatro interfaces de producto de datos: dos conjuntos de datos autorizados de BigQuery, un conjunto de datos de BigQuery expuesto por la API de lectura de almacenamiento de BigQuery y APIs de acceso a datos alojadas en Google Kubernetes Engine. Al usar los productos de datos, los consumidores de datos utilizan una serie de aplicaciones que consultan o acceden directamente a los recursos de datos de los productos de datos. En este caso, los consumidores de datos acceden a los recursos de datos de dos formas diferentes en función de sus requisitos de acceso a los datos específicos. En la primera, Looker usa BigQuery SQL para consultar un conjunto de datos autorizado. En la segunda forma, Dataproc accede directamente a un conjunto de datos a través de la API de BigQuery y, a continuación, procesa los datos ingeridos para entrenar un modelo de aprendizaje automático.
El uso de una aplicación de consumo de datos no siempre da como resultado un informe de inteligencia empresarial (BI) o un panel de control de BI. El consumo de datos de un dominio también puede dar lugar a modelos de aprendizaje automático que mejoren aún más los productos analíticos, que se usen en el análisis de datos o que formen parte de procesos operativos, como la detección de fraudes.
Estos son algunos de los casos prácticos típicos de consumo de productos de datos:
- Informes de BI y análisis de datos: en este caso, las aplicaciones de datos se crean para consumir datos de varios productos de datos. Por ejemplo, los consumidores de datos del equipo de gestión de relaciones con los clientes (CRM) necesitan acceder a datos de varios dominios, como ventas, clientes y finanzas. La aplicación CRM desarrollada por estos consumidores de datos puede necesitar consultar una vista autorizada de BigQuery en un dominio y extraer datos de una API de lectura de Cloud Storage en otro dominio. Para los consumidores de datos, los factores de optimización que influyen en su interfaz de consumo preferida son los costes de computación y cualquier procesamiento de datos adicional que se requiera después de consultar el producto de datos. En los casos prácticos de BI y análisis de datos, es probable que las vistas autorizadas de BigQuery sean las más utilizadas.
- Casos prácticos de ciencia de datos y entrenamiento de modelos: en este caso, el equipo que consume los datos utiliza los productos de datos de otros dominios para enriquecer su propio producto de datos analíticos, como un modelo de aprendizaje automático. Al usarGoogle Cloud sin servidor para Apache Spark Google Cloud ,se proporcionan funciones de preprocesamiento de datos y de ingeniería de funciones para habilitar el enriquecimiento de datos antes de ejecutar tareas de aprendizaje automático. Los aspectos clave son la disponibilidad de cantidades suficientes de datos de entrenamiento a un coste razonable y la confianza en que los datos de entrenamiento sean los adecuados. Para mantener los costes bajos, es probable que las interfaces de consumo preferidas sean APIs de lectura directa. Un equipo que consume datos puede crear un modelo de aprendizaje automático como producto de datos y, a su vez, convertirse en un nuevo equipo que produce datos.
- Procesos del operador: el consumo forma parte del proceso operativo del dominio de consumo de datos. Por ejemplo, un consumidor de datos de un equipo que se ocupa del fraude puede usar datos de transacciones procedentes de fuentes de datos operacionales del dominio del comerciante. Si se usa un método de integración de datos, como la captura de datos de cambios, estos datos de transacciones se interceptan casi en tiempo real. Después, puede usar Pub/Sub para definir un esquema para estos datos y exponer esa información como eventos. En este caso, las interfaces adecuadas serían los datos expuestos como temas de Pub/Sub.
Pasos para consumir datos
Los productores de datos documentan su producto de datos en el catálogo central, incluidas las directrices sobre cómo consumir los datos. En una organización con varios dominios, este enfoque de documentación crea una arquitectura diferente de la canalización ELT/ETL tradicional, que se crea de forma centralizada y en la que los procesadores generan resultados sin tener en cuenta los límites de los dominios empresariales. Los consumidores de datos de una malla de datos deben tener una capa de descubrimiento y consumo bien diseñada para crear un ciclo de vida de consumo de datos. La capa debe incluir lo siguiente:
Paso 1: Descubra productos de datos mediante la búsqueda declarativa y la exploración de especificaciones de productos de datos: los consumidores de datos pueden buscar cualquier producto de datos que los productores de datos hayan registrado en el catálogo central. En todos los productos de datos, la etiqueta de producto de datos especifica cómo hacer solicitudes de acceso a datos y el modo de consumir datos de la interfaz de producto de datos obligatoria. Los campos de las etiquetas de los productos de datos se pueden buscar mediante una aplicación de búsqueda. Las interfaces de productos de datos implementan URIs de datos, lo que significa que no es necesario mover los datos a una zona de consumo independiente para atender a los consumidores. En situaciones en las que no se necesitan datos en tiempo real, los consumidores consultan productos de datos y crean informes con los resultados que se generan.
Paso 2: Explorar los datos mediante el acceso interactivo a los datos y la creación de prototipos: los consumidores de datos usan herramientas interactivas, como BigQuery Studio y los cuadernos de Jupyter, para interpretar los datos y experimentar con ellos. De esta forma, pueden perfeccionar las consultas que necesitan para la producción. Las consultas interactivas permiten a los consumidores de datos explorar nuevas dimensiones de los datos y mejorar la precisión de las estadísticas generadas en escenarios de producción.
Paso 3: Consumir el producto de datos a través de una aplicación, con acceso programático y producción:
- Informes de BI Los informes y los paneles de control por lotes y casi en tiempo real son el grupo más habitual de casos prácticos de analíticas que necesitan los consumidores de datos. Es posible que los informes requieran acceso a datos de varios productos para facilitar la toma de decisiones. Por ejemplo, una plataforma de datos de clientes requiere consultar mediante programación tanto los pedidos como los productos de datos de CRM de forma programada. Los resultados de este enfoque proporcionan una visión integral del cliente a los usuarios empresariales que consumen los datos.
- Modelo de IA o aprendizaje automático para predicciones por lotes y en tiempo real. Los científicos de datos usan principios comunes de MLOps para crear y mantener modelos de aprendizaje automático que consumen productos de datos que ponen a su disposición los equipos de productos de datos. Los modelos de aprendizaje automático ofrecen funciones de inferencia en tiempo real para casos prácticos transaccionales, como la detección de fraudes. Del mismo modo, con el análisis exploratorio de datos, los consumidores de datos pueden enriquecer los datos de origen. Por ejemplo, el análisis exploratorio de datos sobre las ventas y las campañas de marketing muestra segmentos de clientes demográficos en los que se espera que las ventas sean más altas y, por lo tanto, donde se deben llevar a cabo las campañas.
Siguientes pasos
- Consulta una implementación de referencia de la arquitectura de malla de datos.
- BigQuery
- Consulta más información sobre Vertex AI.
- Consulta información sobre la ciencia de datos en Dataproc.
- Para ver más arquitecturas de referencia, diagramas y prácticas recomendadas, consulta el centro de arquitectura de Cloud.