En una malla de datos, una plataforma de datos de autoservicio permite a los usuarios generar valor a partir de los datos, ya que les permite crear, compartir y usar productos de datos de forma autónoma. Para aprovechar al máximo estos beneficios, te recomendamos que tu plataforma de datos de autoservicio proporcione las capacidades que se describen en este documento.
Este documento forma parte de una serie en la que se describe cómo implementar una malla de datos en Google Cloud. Se supone que leíste y conoces los conceptos descritos en Compila una malla de datos moderna y distribuida con Google Cloud y Arquitectura y funciones en una malla de datos.
La serie tiene las siguientes partes:
- Arquitectura y funciones en una malla de datos
- Diseña una plataforma de datos de autoservicio para una malla de datos (este documento)
- Compila productos de datos en una malla de datos
- Descubre y consume productos de datos en una malla de datos
Por lo general, los equipos de la plataforma de datos crean plataformas de datos centrales de autoservicio, como se describe en este documento. Este equipo crea las soluciones y los componentes que los equipos de dominio (tanto los productores como los consumidores de datos) pueden usar para crear y consumir productos de datos. Los equipos de dominio representan partes funcionales de una malla de datos. Mediante la compilación de estos componentes, el equipo de la plataforma de datos permite una experiencia de desarrollo sin problemas y reduce la complejidad de compilar, implementar y mantener productos de datos interoperables y seguros.
En última instancia, el equipo de la plataforma de datos debe permitir que los equipos de dominio avancen más rápido. Ayudan a aumentar la eficiencia de los equipos de dominio, ya que les proporcionan un conjunto limitado de herramientas que satisfacen sus necesidades. Cuando se proporcionan estas herramientas, el equipo de la plataforma de datos evita que el equipo de dominio tenga que compilar y obtener estas herramientas. Las opciones de herramientas deben personalizarse según las diferentes necesidades y no forzar una forma inflexible de trabajar en los equipos de dominios de datos.
El equipo de la plataforma de datos no debe enfocarse en crear soluciones personalizadas para los orquestadores de canalizaciones de datos ni para los sistemas de integración continua y de implementación continua (CI/CD). Las soluciones como los sistemas de CI/CD están disponibles como servicios en la nube administrados, por ejemplo, Cloud Build. Usar los servicios de nube administrados puede reducir las sobrecargas operativas para el equipo de la plataforma de datos y permitirles enfocarse en las necesidades específicas de los equipos de dominios de datos como los usuarios de la plataforma. Con una sobrecarga operativa menor, el equipo de la plataforma de datos puede enfocarse más en abordar las necesidades específicas de los equipos del dominio de datos.
Arquitectura
En el siguiente diagrama, se ilustran los componentes de la arquitectura de una plataforma de datos de autoservicio. El diagrama también muestra cómo estos componentes pueden ayudar a los equipos a medida que desarrollan y consumen productos de datos en toda la malla de datos.

Como se muestra en el diagrama anterior, la plataforma de datos de autoservicio proporciona lo siguiente:
Soluciones de plataforma: Estas soluciones constan de componentes componibles para aprovisionar Google Cloud proyectos y recursos, que los usuarios seleccionan y ensamblan en diferentes combinaciones para satisfacer sus requisitos específicos. En lugar de interactuar directamente con los componentes, los usuarios de la plataforma pueden interactuar con las soluciones de la plataforma para lograr un objetivo específico. Los equipos de dominios de datos deben diseñar soluciones de plataforma para resolver los problemas comunes y las áreas de fricción que causan demoras en el desarrollo y el consumo de productos de datos. Por ejemplo, los equipos de dominios de datos que se integran en la malla de datos pueden usar una plantilla de infraestructura como código (IaC). Usar las plantillas de IaC les permite crear con rapidez un conjunto de proyectos deGoogle Cloud con permisos estándar de Identity and Access Management (IAM), herramientas de redes, políticas de seguridad y APIs de Google Cloudrelevantes habilitadas para el desarrollo de productos de datos. Recomendamos que cada solución esté acompañada de documentación, como orientación sobre cómo comenzar y muestras de código. Las soluciones de la plataforma de datos y sus componentes deben ser seguros y cumplir con los requisitos de forma predeterminada.
Servicios comunes: Estos servicios proporcionan observabilidad, administración, uso compartido y capacidad de descubrimiento de productos de datos. Estos servicios facilitan la confianza de los consumidores de datos en los productos de datos y son una forma eficaz para que los productores de datos alerten a los consumidores de datos sobre problemas con sus productos de datos.
Las soluciones de plataformas de datos y los servicios comunes pueden incluir lo siguiente:
- Plantillas de IaC para configurar entornos de espacio de trabajo de desarrollo de productos de datos básicos, que incluyen lo siguiente:
- IAM
- Registro y supervisión
- Herramientas de redes
- Medidas de seguridad y cumplimiento
- Etiquetado de recursos para la atribución de facturación
- Almacenamiento, transformación y publicación de productos de datos
- Registro, catalogación y etiquetado de metadatos de productos de datos
- Plantillas de IaC que siguen las prácticas recomendadas y los lineamientos de seguridad de la organización, que se pueden usar para implementar recursos de Google Cloud en los espacios de trabajo existentes de desarrollo de productos de datos.
- Plantillas de canalizaciones de datos y aplicaciones que se pueden usar para iniciar proyectos nuevos o como referencia para proyectos existentes Estos son algunos ejemplos de plantillas de este tipo:
- Uso de bibliotecas y frameworks comunes
- Integración con herramientas de registro, supervisión y observabilidad de la plataforma
- Herramientas de compilación y prueba
- Administración de configuración
- Canalizaciones de CI/CD y empaquetado para la implementación
- Autenticación, implementación y administración de credenciales
- Servicios comunes para proporcionar observabilidad y control de productos de datos, que pueden incluir lo siguiente:
- Verificaciones de tiempo de actividad para mostrar el estado general de los productos de datos.
- Métricas personalizadas para brindar indicadores útiles sobre los productos de datos.
- Asistencia operativa del equipo central para que los equipos de consumidores de datos reciban alertas sobre los cambios en los productos de datos que usan.
- Cuadros de evaluación de productos para mostrar el rendimiento de los productos de datos
- Es un catálogo de metadatos para descubrir productos de datos.
- Es un conjunto de políticas computacionales definidas de forma centralizada que se pueden aplicar de manera global en toda la malla de datos.
- Un mercado de datos para facilitar el uso compartido de datos entre los equipos de dominio
En Crea componentes y soluciones de la plataforma con plantillas de IaC, se analizan las ventajas de las plantillas de IaC para exponer e implementar productos de datos. En Proporciona servicios comunes, se analiza por qué es útil proporcionar a los equipos de dominios componentes de infraestructura comunes que compiló y administra el equipo de plataforma de datos.
Crea componentes y soluciones de la plataforma con plantillas de IaC
El objetivo de los equipos de plataformas de datos es configurar plataformas de datos de autoservicio para obtener más valor de los datos. Para crear estas plataformas, proporcionan a los equipos de dominio plantillas de infraestructura verificadas, seguras y de autoservicio. Los equipos de dominio usan estas plantillas para implementar sus entornos de desarrollo y consumo de datos. Las plantillas de IaC ayudan a los equipos de la plataforma de datos a alcanzar ese objetivo y permiten la escalabilidad. El uso de plantillas de IaC verificadas y confiables simplifica el proceso de implementación de recursos para los equipos de dominio, ya que les permite reutilizar las canalizaciones de CI/CD existentes. Este enfoque permite que los equipos de dominio comiencen a trabajar rápidamente y sean productivos dentro de la malla de datos.
Las plantillas de IaC se pueden crear con una herramienta de IaC. Aunque existen varias herramientas de IaC, incluidas Cloud Config Connector, Pulumi, Chef yAnsible, en este documento, se proporcionan ejemplos de Terraform basadas en IaC. Terraform es una herramienta de IaC de código abierto que permite al equipo de la plataforma de datos crear de manera eficiente componentes y soluciones de plataforma componibles para los recursos deGoogle Cloud . Con Terraform, el equipo de la plataforma de datos escribe código que especifica el estado final elegido y permite que la herramienta determine cómo lograr ese estado. Este enfoque declarativo permite que el equipo de la plataforma de datos trate los recursos de infraestructura como artefactos inmutables para la implementación en todos los entornos. También ayuda a reducir el riesgo de que surjan inconsistencias entre los recursos implementados y el código declarado en el control de código fuente (lo que se conoce como desvío de configuración). El desvío de configuración causado por cambios manuales y ad hoc en la infraestructura dificulta la implementación segura y repetible de componentes de IaC en entornos de producción.
Las plantillas de IaC comunes para los componentes de la plataforma compuestas incluyen el uso de módulos de Terraform para implementar recursos como un conjunto de datos de BigQuery, un bucket de Cloud Storage o una base de datos de Cloud SQL. Los módulos de Terraform se pueden combinar en soluciones de extremo a extremo para implementar proyectos completos de Google Cloud , incluidos los recursos relevantes implementados utilizando los módulos componibles. Puedes encontrar módulos de Terraform de ejemplo en los planos de Terraform para Google Cloud.
De forma predeterminada, cada módulo de Terraform debe satisfacer las protecciones de seguridad y las políticas de cumplimiento que usa tu organización. Estos parámetros de referencia y políticas también se pueden expresar como código y automatizarse con herramientas de verificación de cumplimiento automatizadas, como la Google Cloud herramienta de validación de políticas.
Tu organización debe probar continuamente los módulos de Terraform proporcionados por la plataforma, utilizando los mismos mecanismos de protección de cumplimiento automatizados que usa para promover los cambios en la producción.
Para que los componentes y las soluciones de IaC sean detectables y utilizables para los equipos de dominio que tienen poca experiencia con Terraform, te recomendamos que uses servicios como Service Catalog. Los usuarios que tengan requisitos de personalización significativos deberían poder crear sus propias soluciones de implementación a partir de las mismas plantillas de Terraform componibles que usan las soluciones existentes.
Cuando uses Terraform, te recomendamos que sigas las Google Cloudprácticas recomendadas que se describen enPrácticas recomendadas para usar Terraform.
Para ilustrar cómo se puede usar Terraform para crear componentes de la plataforma, en las siguientes secciones, se analizan ejemplos de cómo se puede usar Terraform para exponer interfaces de consumo y consumir un producto de datos.
Expón una interfaz de consumo
Una interfaz de consumo para un producto de datos es un conjunto de garantías sobre la calidad de los datos y los parámetros operativos que proporciona el equipo del dominio de datos para permitir que otros equipos descubran y usen sus productos de datos. Cada interfaz de consumo también incluye un modelo de asistencia de productos y documentación del producto. Un producto de datos puede tener diferentes tipos de interfaces de consumo, como APIs o transmisiones, como se describe en Compila productos de datos en una malla de datos. La interfaz de consumo más común puede ser un conjunto de datos, una vista o una función autorizados de BigQuery. Esta interfaz expone una tabla virtual de solo lectura, que se expresa como una consulta en la malla de datos. La interfaz no otorga permisos de lectura para acceder directamente a los datos subyacentes.
Google proporciona un ejemplo de módulo de Terraform para crear vistas autorizadas sin otorgar permisos a los equipos para acceder a los conjuntos de datos autorizados subyacentes. El siguiente código de este módulo de Terraform otorga estos permisos de IAM en la vista autorizada dataset_id:
module "add_authorization" {
source = "terraform-google-modules/bigquery/google//modules/authorization"
version = "~> 4.1"
dataset_id = module.dataset.bigquery_dataset.dataset_id
project_id = module.dataset.bigquery_dataset.project
roles = [
{
role = "roles/bigquery.dataEditor"
group_by_email = "ops@mycompany.com"
}
]
authorized_views = [
{
project_id = "view_project"
dataset_id = "view_dataset"
table_id = "view_id"
}
]
authorized_datasets = [
{
project_id = "auth_dataset_project"
dataset_id = "auth_dataset"
}
]
}
Si necesitas otorgarles a los usuarios acceso a varias vistas, otorgar acceso a cada vista autorizada puede llevar mucho tiempo y ser más difícil de mantener. En lugar de crear varias vistas autorizadas, puedes usar un conjunto de datos autorizado para autorizar automáticamente las vistas creadas en el conjunto de datos autorizado.
Cómo consumir un producto de datos
En la mayoría de los casos de uso de estadísticas, la aplicación en la que se usan los datos determina los patrones de consumo. El uso principal de un entorno de consumo proporcionado de forma centralizada es la exploración de datos antes de que se utilicen en la aplicación de consumo. Como se explicó en Descubre y consume productos en una malla de datos, SQL es el método más común para consultar productos de datos. Por este motivo, la plataforma de datos debe proporcionar a los consumidores de datos una aplicación SQL para explorar los datos.
Según el caso de uso de estadísticas, es posible que puedas usar Terraform a fin de implementar el entorno de consumo para los consumidores de datos. Por ejemplo, la ciencia de datos es un caso de uso común para los consumidores de datos. Puedes usar Terraform para implementar notebooks administrados por el usuario de Vertex AI que se usarán como un entorno de desarrollo de ciencia de datos. Desde los notebooks de ciencia de datos, los consumidores de datos pueden usar sus credenciales para acceder a la malla de datos y explorar los datos a los que tienen acceso, así como desarrollar modelos de AA basados en estos datos.
Si deseas obtener información para usar Terraform a fin de implementar y ayudar a proteger un entorno de notebook en Google Cloud, consulta Crea e implementa modelos de IA generativa y aprendizaje automático en una empresa.
Proporcionar servicios comunes
Además de los componentes y las soluciones de IaC de autoservicio, el equipo de la plataforma de datos también puede tomar la propiedad de la compilación y la operación de servicios comunes de plataforma compartida que usan varios equipos de dominios de datos. Los ejemplos habituales de servicios de plataforma compartida incluyen software de terceros autoalojados, como herramientas de visualización de inteligencia empresarial o un clúster de Kafka. En Google Cloud, el equipo de la plataforma de datos puede elegir administrar recursos como Dataplex Universal Catalog y los receptores de Cloud Logging en nombre de los equipos de dominio de datos. La administración de recursos para los equipos de dominios de datos permite que el equipo de la plataforma de datos facilite la auditoría y la administración centralizadas de políticas en toda la organización.
En las siguientes secciones, se muestra cómo usar Dataplex Universal Catalog para la administración y el control centrales dentro de una malla de datos en Google Cloud, y la implementación de funciones de observabilidad de datos en una malla de datos.
Dataplex Universal Catalog para la administración de datos
Dataplex Universal Catalog proporciona una plataforma de administración de datos que te ayuda a crear dominios de datos independientes dentro de una malla de datos que abarca toda la organización. Dataplex Universal Catalog te permite mantener controles centrales para supervisar y controlar los datos en todos los dominios.
Con Dataplex Universal Catalog, una organización puede organizar de forma lógica sus datos (fuentes de datos compatibles) y artefactos relacionados, como código, notebooks y registros, en un lake de Dataplex Universal Catalog que representa un dominio de datos. En el siguiente diagrama, un dominio de ventas usa Dataplex Universal Catalog para organizar sus recursos, incluidas las métricas y los registros de calidad de los datos, en zonas de Dataplex Universal Catalog.
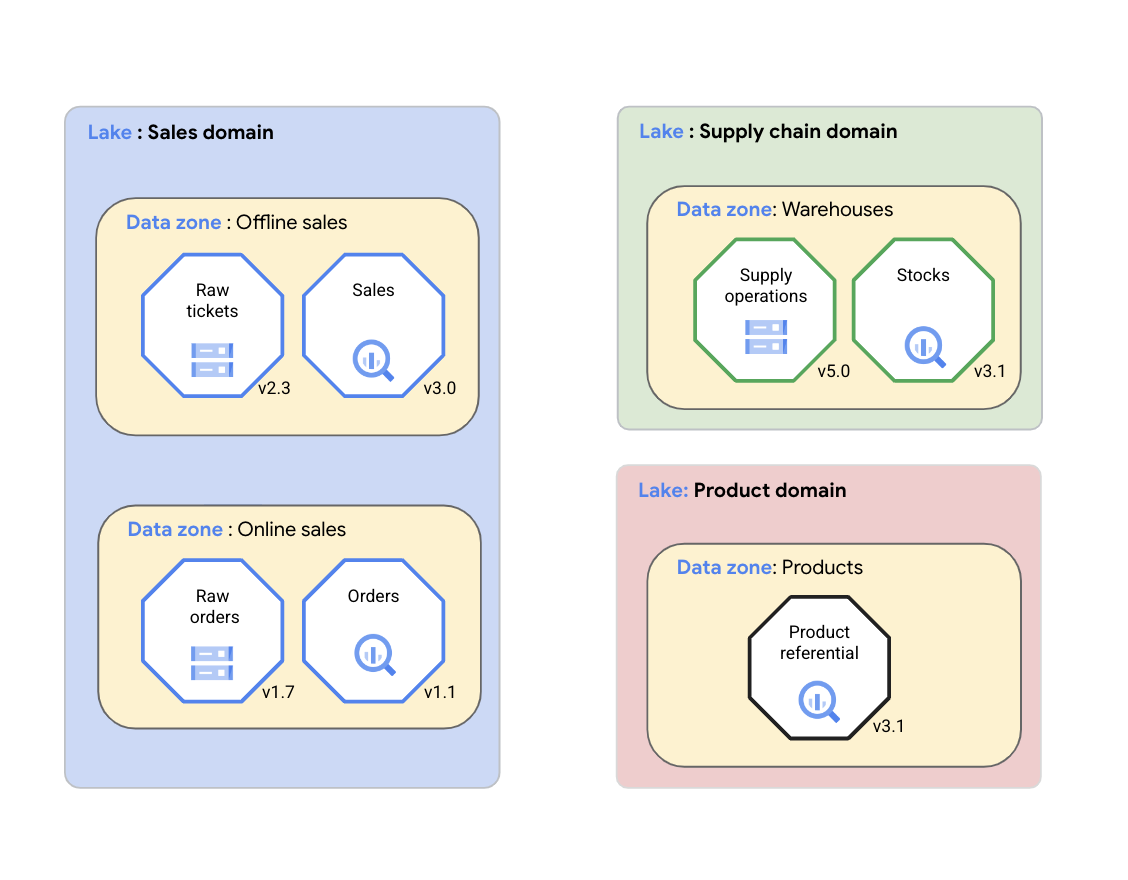
Como se muestra en el diagrama anterior, Dataplex Universal Catalog se puede usar para administrar los datos del dominio en los siguientes recursos:
- Dataplex Universal Catalog permite que los equipos de dominios de datos administren de forma coherente sus recursos de datos en un grupo lógico llamado lake de Dataplex Universal Catalog. El equipo de dominio de datos puede organizar sus recursos de Dataplex Universal Catalog dentro del mismo lake de Dataplex Universal Catalog sin mover físicamente los datos ni almacenarlos en un solo sistema de almacenamiento. Los recursos de Dataplex Universal Catalog pueden hacer referencia a buckets de Cloud Storage y conjuntos de datos de BigQuery almacenados en varios proyectos de Google Cloud que no sean el proyecto deGoogle Cloud que contiene el lake de Dataplex Universal Catalog. Los recursos de Dataplex Universal Catalog pueden ser estructurados o no estructurados, o pueden almacenarse en un data lake o almacén de datos analíticos. En el diagrama, se incluyen data lakes para el dominio de ventas, el dominio de cadena de suministro y el dominio de productos.
- Las zonas de Dataplex Universal Catalog permiten que el equipo de dominio de datos organice aún más los recursos de datos en subgrupos más pequeños dentro del mismo lake de Dataplex Universal Catalog y agregue estructuras que capturen aspectos clave del subgrupo. Por ejemplo, las zonas de Dataplex Universal Catalog se pueden usar para agrupar los recursos de datos asociados en un producto de datos. Agrupar los recursos de datos en una sola zona de Dataplex Universal Catalog permite que los equipos de dominios de datos administren las políticas de acceso y las políticas de administración de datos de manera coherente en toda la zona como un solo producto de datos. En el diagrama, se incluyen zonas de datos para ventas tradicionales, ventas en línea, almacenes de cadena de suministro y productos.
Las zonas y los lakes de Dataplex Universal Catalog permiten que una organización unifique datos distribuidos y los organice en función del contexto empresarial. Este acuerdo sienta las bases para actividades como la administración de metadatos, la configuración de políticas de administración y la supervisión de la calidad de los datos. Estas actividades permiten que la organización administre sus datos distribuidos a gran escala, como en una malla de datos.
Observabilidad de los datos
Cada dominio de datos debe implementar sus propios mecanismos de supervisión y alertas, idealmente con un enfoque estandarizado. Cada dominio puede aplicar las prácticas de supervisión que se describen en Conceptos de supervisión de servicios y realizar los ajustes necesarios en los dominios de datos. La observabilidad es un tema extenso y está fuera del alcance de este documento. En esta sección, solo se abordan los patrones que son útiles en las implementaciones de malla de datos.
En el caso de los productos con varios consumidores de datos, proporcionar información oportuna a cada consumidor sobre el estado del producto puede convertirse en una carga operativa. Las soluciones básicas, como las distribuciones de correo electrónico administradas manualmente, suelen ser propensas a errores. Pueden ser útiles para notificar a los consumidores sobre interrupciones planificadas, lanzamientos de productos próximos y bajas, pero no proporcionan información operativa en tiempo real.
Los servicios centrales pueden desempeñar un rol importante en la supervisión del estado y la calidad de los productos en la malla de datos. Aunque no es un requisito para una implementación exitosa de la malla de datos, la implementación de funciones de observabilidad puede mejorar la satisfacción de los consumidores y los productores de datos, y reducir los costos operativos y de asistencia generales. En el siguiente diagrama, se muestra una arquitectura de observabilidad de la malla de datos basada en Cloud Monitoring.

En las siguientes secciones, se describen los componentes que se muestran en el diagrama, que son los siguientes:
- Verificaciones de tiempo de actividad para mostrar el estado general de los productos de datos.
- Métricas personalizadas para brindar indicadores útiles sobre los productos de datos.
- Asistencia operativa por parte del equipo de la plataforma de datos central para alertar a los consumidores de datos sobre los cambios en los productos de datos que usan.
- Cuadros de evaluación de productos y paneles para mostrar el rendimiento de los productos de datos
Verificaciones de tiempo de actividad
Los productos de datos pueden crear aplicaciones personalizadas simples que implementen verificaciones de tiempo de actividad. Estas verificaciones pueden servir como indicadores de alto nivel del estado general del producto. Por ejemplo, si el equipo de productos de datos descubre una disminución repentina en la calidad de los datos de su producto, el equipo puede marcar ese producto como en mal estado. Las verificaciones de tiempo de actividad cercanas al tiempo real son especialmente importantes para los consumidores de datos que tienen productos derivados que dependen de la disponibilidad constante de los datos en el producto de datos de la etapa anterior. Los productores de datos deben crear sus verificaciones de tiempo de actividad para incluir la verificación de sus dependencias upstream, lo que proporciona una imagen precisa del estado de su producto a sus consumidores de datos.
Los consumidores de datos pueden incluir verificaciones del tiempo de actividad del producto en su procesamiento. Por ejemplo, un trabajo de composición que genera un informe basado en los datos proporcionados por un producto de datos puede, como primer paso, validar si el producto está en estado "en ejecución". Te recomendamos que tu aplicación de verificación de tiempo de actividad devuelva una carga útil estructurada en el cuerpo del mensaje de su respuesta HTTP. Esta carga útil estructurada debe indicar si hay un problema, la causa raíz del problema en formato legible y, si es posible, el tiempo estimado para restablecer el servicio. Esta carga útil estructurada también puede proporcionar información más detallada sobre el estado del producto. Por ejemplo, puede contener la información de salud de cada una de las vistas del conjunto de datos autorizado que se expone como producto.
Métricas personalizadas
Los productos de datos pueden tener varias métricas personalizadas para medir su utilidad. Los equipos de productores de datos pueden publicar estas métricas personalizadas en sus proyectos Google Cloud específicos del dominio designados. Para crear una experiencia de supervisión unificada en todos los productos de datos, se puede otorgar acceso a un proyecto de supervisión de la malla de datos central a esos proyectos específicos de dominio.
Cada tipo de interfaz de consumo de productos de datos tiene diferentes métricas para medir su utilidad. Las métricas también pueden ser específicas del dominio de la empresa. Por ejemplo, las métricas de las tablas de BigQuery expuestas a través de vistas o de la API de Storage Read pueden ser las siguientes:
- El número de filas.
- Actualidad de los datos (expresada como la cantidad de segundos antes de la hora de la medición).
- Es la puntuación de calidad de los datos.
- Los datos que están disponibles. Esta métrica puede indicar que los datos están disponibles para realizar consultas. Una alternativa es usar las verificaciones de tiempo de actividad que se mencionaron anteriormente en este documento.
Estas métricas se pueden ver como indicadores de nivel de servicio (SLI) para un producto en particular.
Para las transmisiones de datos (implementadas como temas de Pub/Sub), esta lista pueden ser las métricas de Pub/Sub estándar, que están disponibles a través de temas.
Asistencia operativa prestada por el equipo central de plataforma de datos
El equipo central de la plataforma de datos puede exponer paneles personalizados para mostrar diferentes niveles de detalles a los consumidores de datos. Un panel de estado simple que enumera los productos en la malla de datos y el estado de actividad de esos productos puede ayudar a responder varias solicitudes de los usuarios finales.
El equipo central también puede funcionar como centro de distribución de notificaciones para informar a los consumidores de datos sobre diversos eventos en los productos de datos que usan. Por lo general, este centro se crea con políticas de alertas. Centralizar esta función puede reducir el trabajo que debe realizar cada equipo de productores de datos. La creación de estas políticas no requiere conocimiento de los dominios de datos y debería ayudar a evitar cuellos de botella en el consumo de datos.
El estado final ideal para la supervisión de la malla de datos es que la plantilla de etiquetas del producto de datos exponga los SLI y los objetivos de nivel de servicio (SLO) que admite el producto cuando esté disponible. Luego, el equipo central puede implementar automáticamente las alertas correspondientes con la supervisión de servicios a través de la API de Monitoring.
Cuadros de evaluación de productos
Como parte del acuerdo de gobernanza central, las cuatro funciones de una malla de datos pueden definir los criterios para crear cuadros de evaluación de los productos de datos. Estos cuadros de evaluación pueden convertirse en una medición objetiva del rendimiento de los productos de datos.
Muchas de las variables que se usan para calcular los cuadros de evaluación son el porcentaje de tiempo en el que los productos de datos cumplen con su SLO. Los criterios útiles pueden ser el porcentaje de tiempo de actividad, las puntuaciones promedio de calidad de los datos y el porcentaje de productos con una actualidad de los datos que no se encuentre por debajo de un umbral. Para calcular estas métricas automáticamente con el lenguaje de consulta de Prometheus (PromQL), las métricas personalizadas y los resultados de las verificaciones de tiempo de actividad del proyecto de supervisión central deberían ser suficientes.
¿Qué sigue?
- Más información sobre BigQuery
- Lee acerca de Dataplex.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.