Para que os casos de uso dos consumidores de dados sejam atendidos, é essencial que os produtos de dados em uma malha de dados sejam projetados e criados com cuidado. O design de um produto de dados começa com a definição de como os consumidores de dados usariam esse produto e como ele seria exposto aos consumidores. Os produtos de dados em uma malha de dados são criados sobre um repositório de dados, por exemplo, um data warehouse de domínio ou data lake. Ao criar produtos de dados em uma malha de dados, recomendamos que você considere alguns fatores importantes ao longo do processo. As considerações estão descritas neste documento.
Este documento faz parte de uma série em que se descreve como implementar uma malha de dados no Google Cloud. Ele pressupõe que você leu e conhece os conceitos descritos em Arquitetura e funções em uma malha de dados e Criar uma malha de dados moderna e distribuída com o Google Cloud.
A série tem as seguintes partes:
- Arquitetura e funções em uma malha de dados
- Projetar uma plataforma de dados de autoatendimento para uma malha de dados
- Criar produtos de dados em uma malha de dados (este documento)
- Descobrir e consumir produtos de dados em uma malha de dados
Ao criar produtos de dados com base em um data warehouse do domínio, recomendamos que os produtores de dados projetem com cuidado interfaces de análise (consumo) para esses produtos. Essas interfaces de consumo são um conjunto de garantias sobre a qualidade de dados e os parâmetros operacionais, com um modelo de suporte ao produto e a documentação do produto. O custo de mudar as interfaces de consumo geralmente é alto por causa da necessidade do produtor de dados e, possivelmente, de vários consumidores de dados mudarem os processos e aplicativos de consumo. Como os consumidores de dados provavelmente estão em unidades organizacionais separadas dos produtores de dados, coordenar as alterações pode ser difícil.
As seções a seguir fornecem informações básicas sobre o que considerar ao criar um armazenamento de domínios, definir interfaces de consumo e expô-las aos consumidores de dados.
Criar um data warehouse de domínio
Não há uma diferença fundamental entre criar um data warehouse autônomo e um de domínio a partir do qual a equipe de produtores de dados cria produtos de dados. A única diferença real entre os dois é que o segundo expõe um subconjunto de dados com interfaces de consumo.
Em muitos data warehouses, a ingestão de dados brutos de fontes de dados operacionais passam pelo processo de enriquecimento e verificação da qualidade de dados (processamento). Nos data lakes gerenciados pelo Dataplex Universal Catalog, os dados tratados normalmente são armazenados em zonas selecionadas designadas. Após a conclusão do processamento, um subconjunto dos dados estará pronto para consumo externo do domínio por meio de vários tipos de interfaces. Para definir essas interfaces de consumo, a organização precisa fornecer um conjunto de ferramentas para as equipes de domínio que não estão familiarizadas com a abordagem de malha de dados. Com essas ferramentas, os produtores de dados podem criar novos produtos de dados de autoatendimento. Para práticas recomendadas, confira Criar uma plataforma de dados de autoatendimento.
Além disso, os produtos de dados precisam atender aos requisitos de governança de dados definidos centralmente. Esses requisitos afetam a qualidade e a disponibilidade dos dados, e o gerenciamento do ciclo de vida. Como esses requisitos fazem os consumidores de dados confiarem nos produtos de dados e incentivam o uso do produto de dados, os benefícios da implementação desses requisitos valem o esforço.
Definir interfaces de consumo
Recomendamos que os produtores de dados usem vários tipos de interfaces, em vez de definir apenas uma ou duas. Cada tipo de interface na análise de dados tem vantagens e desvantagens, e não há um único tipo de interface que seja boa em tudo. Ao avaliar a adequação de cada tipo de interface, os produtores de dados precisam considerar o seguinte:
- Capacidade de realizar o processamento de dados necessário.
- Escalonabilidade para casos de uso atuais e futuros de consumidores de dados
- Desempenho exigido pelos consumidores de dados.
- Custo de desenvolvimento e manutenção.
- Custo de execução da interface.
- Suporte pelas linguagens e ferramentas usadas pela sua organização.
- Suporte para separação de armazenamento e computação.
Por exemplo, se o requisito de negócios for a capacidade de executar consultas analíticas em um conjunto de dados com tamanho de petabyte, a única interface viável é uma visualização do BigQuery. No entanto, se os requisitos forem fornecer dados de streaming quase em tempo real, uma interface baseada no Pub/Sub é mais apropriada.
Muitas dessas interfaces não exigem que você copie ou replique dados existentes. A maioria delas também permite separar armazenamento e computação, um recurso essencial das ferramentas analíticas doGoogle Cloud . Os consumidores de dados expostos a essas interfaces processam os dados usando os recursos de computação disponíveis para eles. Os produtores de dados não precisam fazer nenhum provisionamento de infraestrutura adicional.
Há uma ampla variedade de interfaces de consumo. As interfaces abaixo são as mais comuns usadas em uma malha de dados e são abordadas nas seguintes seções:
- Visualizações e funções autorizadas
- APIs de leitura direta
- Dados como streams
- API de acesso aos dados
- Looker Block
- Modelos de machine learning (ML)
A lista de interfaces neste documento não está completa. Há também outras opções que podem ser consideradas para suas interfaces de consumo (por exemplo, o BigQuery Sharing (antigo Analytics Hub)). No entanto, essas outras interfaces estão fora do escopo deste documento.
Visualizações e funções autorizadas
Na medida do possível, os produtos de dados precisam ser expostos por meio de visualizações autorizadas e funções autorizadas,incluindo funções com valor de tabela. Os conjuntos de dados autorizados fornecem uma maneira conveniente de autorizar várias visualizações automaticamente. O uso de visualizações autorizadas impede o acesso direto às tabelas base e permite otimizar as tabelas e consultas subjacentes sem afetar o uso dessas visualizações pelo consumidor. Os consumidores dessa interface usam SQL para consultar os dados. No diagrama a seguir, ilustramos o uso de conjuntos de dados autorizados como a interface de consumo.
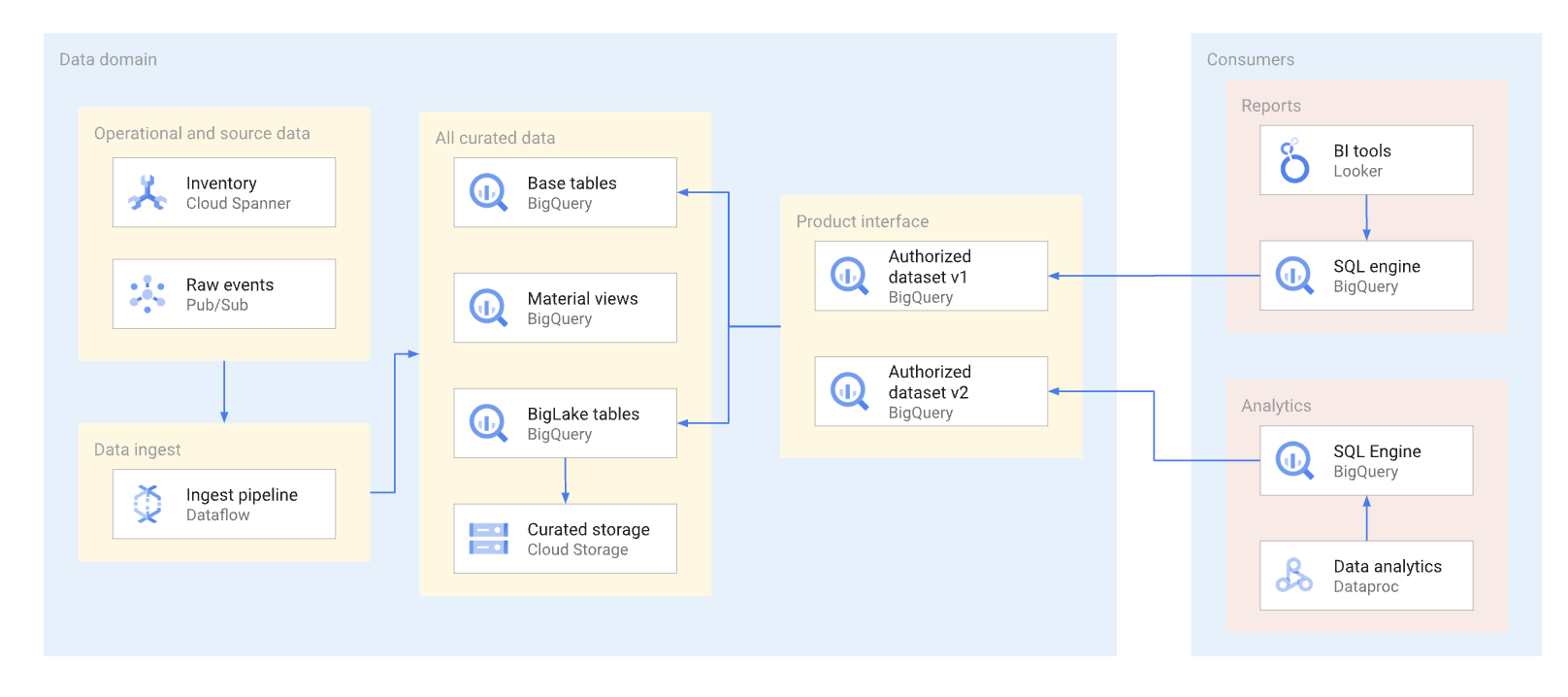
Visualizações e conjuntos de dados autorizados facilitam o controle de versões das interfaces. Conforme mostrado no diagrama a seguir, há duas abordagens principais de controle de versões que os produtores de dados podem seguir:
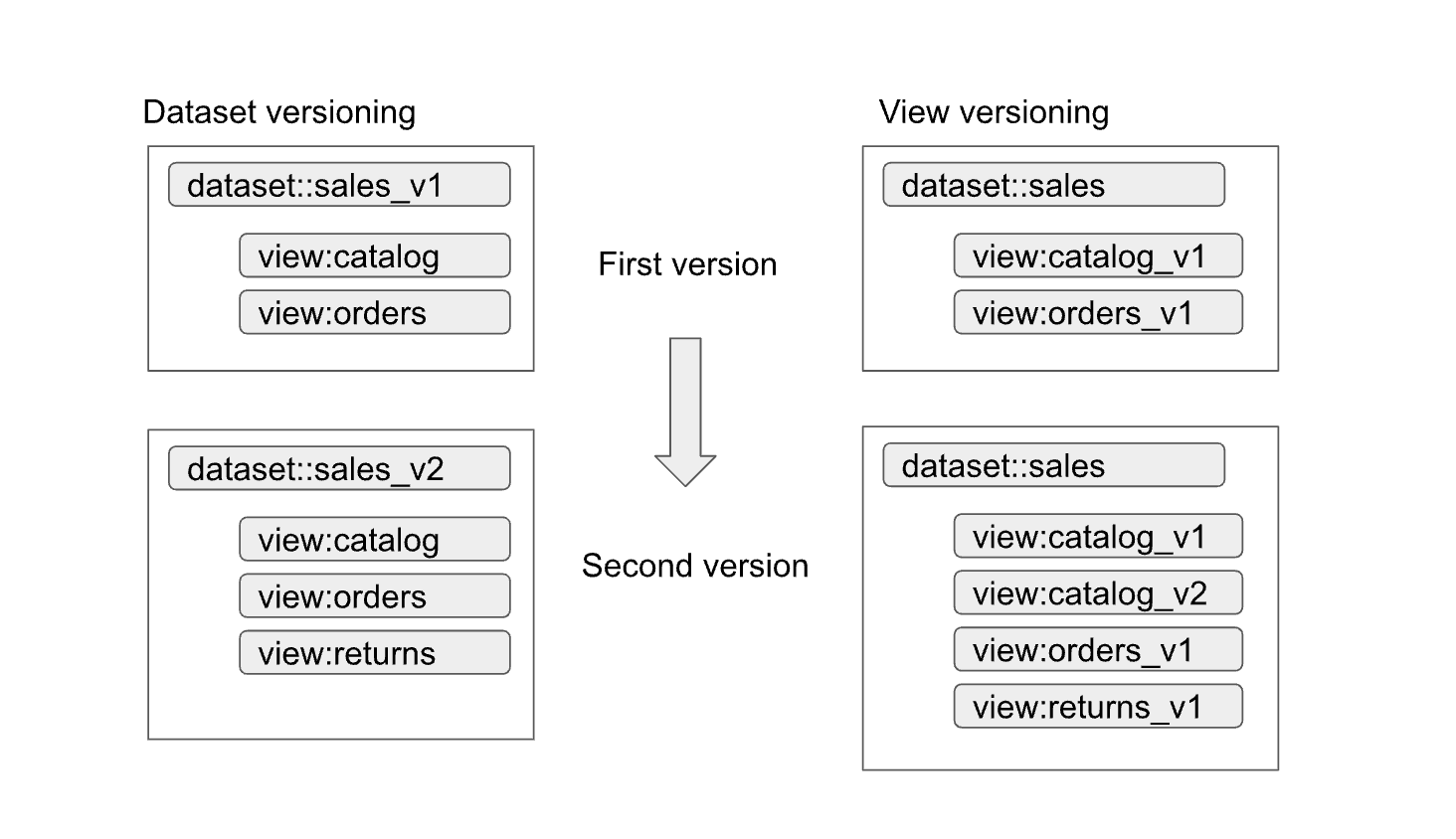
As abordagens podem ser resumidas da seguinte forma:
- Controle de versões do conjunto de dados: nessa abordagem, você controla a versão do nome do conjunto de dados.
Você não controla a versão das visualizações e funções dentro do conjunto de dados. Você mantém os
mesmos nomes para as visualizações e funções, independentemente da versão. Por exemplo,
a primeira versão de um conjunto de dados de vendas é definida em um conjunto chamado
sales_v1com duas visualizações,catalogeorders. Na segunda versão, o conjunto de dados de vendas foi renomeado comosales_v2, e todas as visualizações anteriores mantiveram os nomes, mas com novos esquemas. A segunda versão do conjunto de dados também pode ter novas visualizações adicionadas a ela ou pode remover qualquer uma das anteriores. - Controle de versão de visualização: nessa abordagem, as visualizações dentro do conjunto de dados têm
controle de versão, em vez de conjunto de dados. Por exemplo, o conjunto de dados de vendas mantém o nome
sales, independente da versão. No entanto, os nomes das visualizações dentro do conjunto de dados mudam para refletir cada nova versão da visualização (comocatalog_v1,catalog_v2,orders_v1,orders_v2eorders_v3).
A melhor abordagem de controle de versões para sua organização depende das políticas dela e do número de visualizações que ficam obsoletas com a atualização dos dados subjacentes. O controle de versões do conjunto de dados é melhor quando é necessária uma atualização importante do produto e a maioria das visualizações precisa mudar. O controle de versão gera menos visualizações com nomes idênticos em conjuntos de dados diferentes, mas pode gerar ambiguidades. Por exemplo, como saber se uma junção entre conjuntos de dados funciona corretamente. A abordagem híbrida pode ser uma boa opção. Na abordagem híbrida, alterações de esquema compatíveis são permitidas em um único conjunto de dados, e alterações incompatíveis exigem um novo conjunto de dados.
Considerações da tabela do BigLake
As visualizações autorizadas podem ser criadas não apenas em tabelas do BigQuery, mas também em tabelas do BigLake. Com as tabelas do BigLake, os consumidores podem consultar os dados armazenados no Cloud Storage usando a interface SQL do BigQuery. As tabelas do BigLake são compatíveis com controle de acesso granular, sem que os consumidores de dados precisem ter permissões de leitura para o bucket subjacente do Cloud Storage.
Os produtores de dados precisam considerar o seguinte nas tabelas do BigLake:
- O design dos formatos de arquivo e o layout dos dados influencia o desempenho das consultas. Formatos baseados em colunas, como Parquet ou ORC, geralmente têm um desempenho muito melhor em consultas analíticas do que os formatos JSON ou CSV.
- Um layout particionado do Hive permite eliminar partições e acelerar consultas que usam colunas de particionamento.
- O número de arquivos e o desempenho de consulta preferido para o tamanho do arquivo também precisam ser considerados no estágio de design.
Se as consultas que usam tabelas do BigLake não atenderem aos requisitos do contrato de nível de serviço (SLA) para a interface e não puderem ser ajustadas, recomendamos as seguintes ações:
- Para dados que precisam ser expostos ao consumidor de dados, converta-os em um armazenamento do BigQuery.
- Redefina as visualizações autorizadas para usar as tabelas do BigQuery.
Geralmente, essa abordagem não causa nenhuma interrupção aos consumidores de dados nem exige alterações nas consultas. As consultas no armazenamento do BigQuery podem ser otimizadas usando técnicas que não são possíveis com as tabelas do BigLake. Por exemplo, com o armazenamento do BigQuery, os consumidores podem consultar visualizações materializadas que têm particionamento e clustering diferentes das tabelas base e podem usar o BigQuery BI Engine.
APIs de leitura direta
Embora não seja recomendado que os produtores concedam aos consumidores de dados acesso direto de leitura às tabelas base, às vezes pode ser prático permitir esse acesso por motivos como desempenho e custo. Nesses casos, é preciso ter cuidado extra para garantir que o esquema da tabela esteja estável.
Há duas maneiras de acessar dados diretamente em um warehouse comum. Os produtores de dados podem usar a API Storage Read do BigQuery ou as APIs JSON ou XML do Cloud Storage. O diagrama a seguir ilustra dois exemplos de consumidores que usam essas APIs. Um é um caso de uso de machine learning (ML) e o outro é um job de processamento de dados.
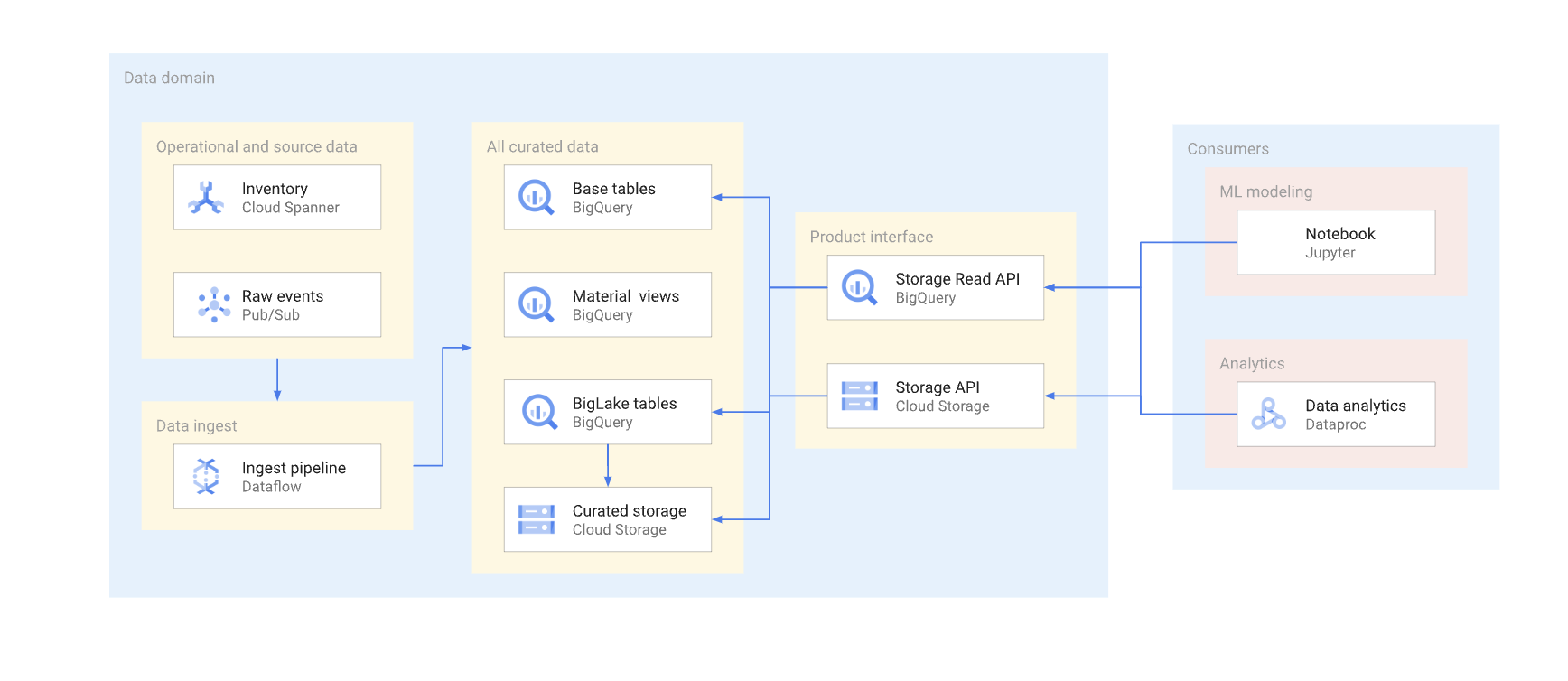
O controle de versões de uma interface de leitura direta é complexo. Normalmente, os produtores de dados precisam criar outra tabela com um esquema diferente. Eles também precisam manter duas versões da tabela até que todos os consumidores de dados da versão descontinuada migrem para a nova. Se os consumidores puderem tolerar a interrupção da recriação da tabela e da mudança para o novo esquema, será possível evitar a duplicação de dados. Nos casos em que as alterações de esquema são compatíveis com versões anteriores, a migração da tabela base pode ser evitada. Por exemplo, você não precisará migrar a tabela base se apenas novas colunas forem adicionadas e os dados nelas forem preenchidos em todas as linhas.
Confira a seguir um resumo das diferenças entre a API Storage Read e a API Cloud Storage. Em geral, sempre que possível, recomendamos que os produtores de dados usem a API BigQuery em aplicativos analíticos.
API Storage Read: essa API pode ser usada para ler dados em tabelas do BigQuery e do BigLake. Essa API oferece suporte a filtragem e controle de acesso granular e pode ser uma boa opção para análises de dados estáveis ou consumidores de ML.
API Cloud Storage: os produtores de dados talvez precisem compartilhar um bucket específico do Cloud Storage diretamente com os consumidores de dados. Por exemplo, os produtores de dados podem compartilhar o bucket se os consumidores não puderem usar a interface SQL por algum motivo ou se o bucket tiver formatos de dados que não são compatíveis com a API Storage Read.
Em geral, não recomendamos que os produtores de dados permitam o acesso direto com as APIs de armazenamento porque o acesso direto não permite filtragem e controle de acesso granular. No entanto, a abordagem de acesso direto pode ser uma opção viável para conjuntos de dados estáveis e pequenos (gigabytes).
Permitir o acesso do Pub/Sub ao bucket oferece aos consumidores de dados uma maneira fácil de copiar e processar os dados nos seus projetos. Em geral, não recomendamos a cópia de dados se isso puder ser evitado. Várias cópias de dados aumentam o custo de armazenamento e aumentam a sobrecarga de manutenção e rastreamento de linhagem.
Dados como streams
Um domínio pode expor dados de streaming publicando esses dados em um tópico do Pub/Sub. Os assinantes que querem consumir os dados criam assinaturas para consumir as mensagens publicadas naquele tópico. Cada assinante recebe e consome dados de forma independente. O diagrama a seguir mostra um exemplo desses fluxos de dados.
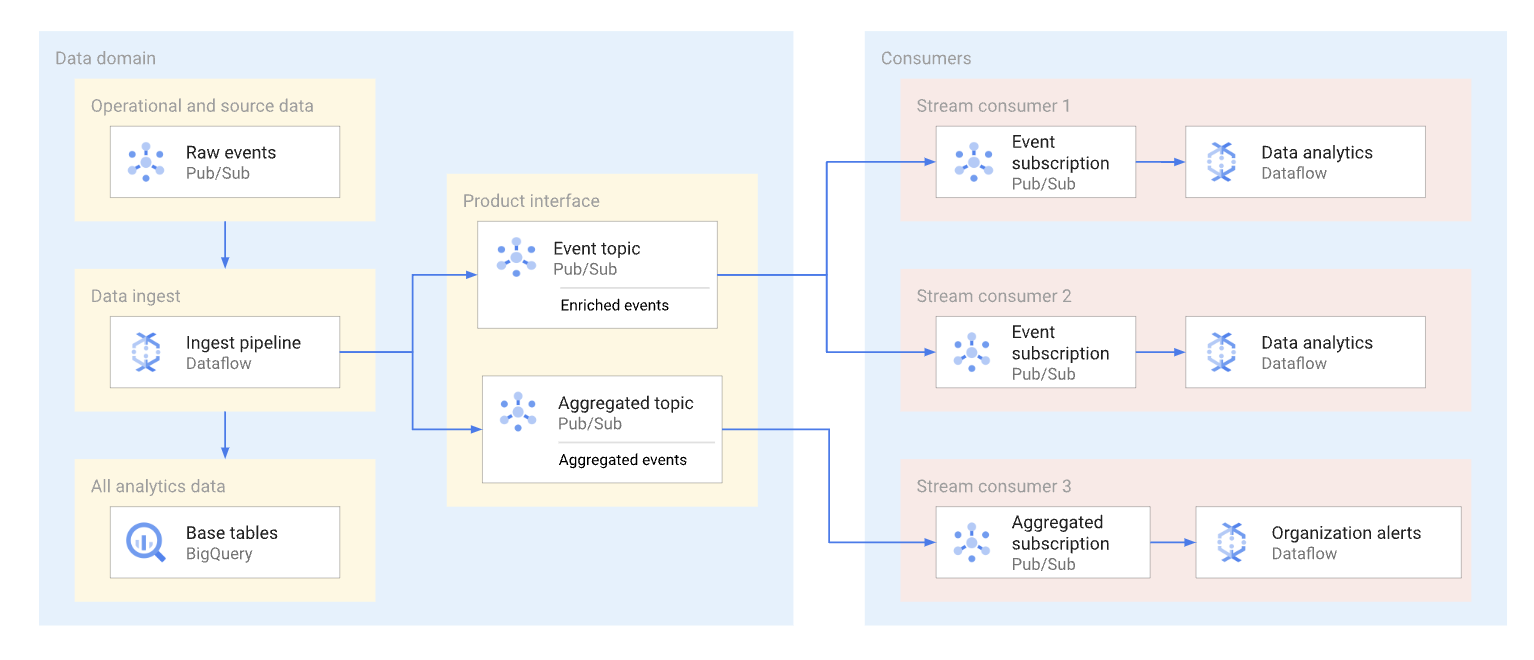
No diagrama, o pipeline de ingestão lê eventos brutos, enriquece-os (processa) e salva os dados processados no repositório de dados analítico (tabela base do BigQuery). Ao mesmo tempo, o pipeline publica os eventos enriquecidos em um tópico dedicado. Esse tópico é consumido por vários assinantes, cada um deles possivelmente filtra esses eventos para receber apenas os que são relevantes para ele. O pipeline também agrega e publica estatísticas de eventos no próprio tópico para ser processado por outro consumidor de dados.
Confira abaixo exemplos de casos de uso de assinaturas do Pub/Sub:
- Eventos enriquecidos, como fornecer informações completas do perfil do cliente, com dados sobre um pedido específico do cliente.
- Notificações de agregação quase em tempo real, como estatísticas totais de pedidos nos últimos 15 minutos.
- Alertas de negócios, por exemplo, gerar um alerta se o volume dos pedidos cair 20% em comparação com um período semelhante no dia anterior.
- Notificações de mudança de dados (conceito semelhantes às notificações de captura de dados alterados), como um status de alteração de pedido específico.
O formato de dados que os produtores de dados usam para mensagens do Pub/Sub afeta os custos e a maneira como essas mensagens são processadas. Para fluxos de alto volume em uma arquitetura de malha de dados, os formatos Avro ou Protobuf são boas opções. Se os produtores de dados usarem esses formatos, eles poderão atribuir esquemas a tópicos do Pub/Sub. Os esquemas ajudam a garantir que os consumidores recebam mensagens bem formadas.
Como uma estrutura de dados de streaming pode mudar constantemente, o controle de versões dessa interface requer a coordenação entre os produtores e os consumidores de dados. Há várias abordagens comuns que os produtores de dados podem adotar, que são as seguintes:
- Um novo tópico é criado sempre que a estrutura da mensagem é alterada. Este
tópico geralmente tem um esquema com linguagem explícita do Pub/Sub. Os consumidores de dados
que precisam da nova interface podem começar a consumir os novos dados. A versão da mensagem
está implícita no nome do tópico, por exemplo,
click_events_v1. Os formatos de mensagem são fortemente tipados. Não há variação no formato das mensagens no mesmo tópico. A desvantagem dessa abordagem é que pode haver consumidores de dados que não consigam mudar para a nova assinatura. Nesse caso, o produtor de dados precisa continuar publicando eventos em todos os tópicos ativos por algum tempo, e os consumidores de dados que se inscreverem no tópico precisarão lidar com uma lacuna no fluxo de mensagens ou eliminar a duplicação das mensagens. - Os dados são sempre publicados no mesmo tópico. No entanto, a estrutura
da mensagem pode mudar. Um
atributo de mensagem
do Pub/Sub (separado do payload) define a versão da mensagem. Por exemplo,
v=1.0. Essa abordagem elimina a necessidade de lidar com lacunas ou duplicatas. No entanto, todos os consumidores de dados precisam estar prontos para receber um novo tipo de mensagens. Os produtores de dados também não podem usar esquemas de tópicos do Pub/Sub para essa abordagem. - Uma abordagem híbrida. O esquema de mensagem pode ter uma seção de dados arbitrária que pode ser usada para novos campos. Essa abordagem pode oferecer um equilíbrio razoável entre ter dados fortemente tipados e mudanças de versão frequentes e complexas.
API de acesso aos dados
Os produtores de dados podem criar uma API personalizada para acessar diretamente as tabelas base em um data warehouse. Normalmente, esses produtores expõem essa API personalizada como uma API REST ou gRPC e implantam no Cloud Run ou em um cluster do Kubernetes. Um gateway de API como a Apigee pode fornecer outros recursos extras, como limitação de tráfego ou uma camada de armazenamento em cache. Essas funcionalidades são úteis ao expor a API de acesso aos dados para consumidores fora de uma organização do Google Cloud . As possíveis candidatas a uma API de acesso aos dados são consultas sensíveis à latência e de alta simultaneidade, que retornam um resultado relativamente pequeno em uma única API e podem ser armazenadas em cache de maneira eficaz.
Confira alguns exemplos dessa API personalizada para acesso aos dados:
- Uma visualização combinada das métricas de SLA da tabela ou do produto.
- Os 10 registros principais (possivelmente armazenados em cache) de uma tabela específica.
- Um conjunto de dados de estatísticas da tabela (número total de linhas ou distribuição de dados em colunas de chave).
Todas as diretrizes e governança que a organização tem em relação à criação de APIs de aplicativos também se aplicam às APIs personalizadas criadas pelos produtores de dados. As diretrizes e a governança da organização precisam abordar questões como hospedagem, monitoramento, controle de acesso e controle de versões.
A desvantagem de uma API personalizada é que os produtores de dados são responsáveis por qualquer infraestrutura extra necessária para hospedar essa interface, além da programação e manutenção personalizadas da API. Recomendamos que os produtores de dados investiguem outras opções antes de decidir criar APIs personalizadas de acesso aos dados do cliente. Por exemplo, os produtores de dados podem usar o BigQuery BI Engine para diminuir a latência de resposta e aumentar a simultaneidade.
Looker Block
Para produtos como o Looker, que são muito usados em ferramentas de Business intelligence (BI), pode ser útil manter um conjunto de widgets específicos de ferramentas de BI. Como a equipe de produtores de dados conhece o modelo de dados subjacente usado no domínio, essa equipe é a mais indicada para criar e manter um conjunto pré-criado de visualizações.
No caso do Looker, essa visualização pode ser um conjunto de Looker Blocks (modelos de dados pré-criados do LookML). Os Looker Blocks podem ser facilmente incorporados a painéis hospedados por consumidores.
Modelos de ML
Como as equipes que trabalham em domínios de dados conhecem e entendem bem os dados, elas geralmente são as melhores para criar e manter modelos de ML treinados nos dados do domínio. Esses modelos de ML podem ser expostos por meio de várias interfaces diferentes, incluindo:
- Os modelos do BigQuery ML podem ser implantados em um conjunto de dados dedicado e compartilhados com consumidores de dados para previsões em lote do BigQuery.
- Os modelos do BigQuery ML podem ser exportados para a Vertex AI para serem usados em previsões on-line.
Considerações do localizador de dados para interfaces de consumo
Uma consideração importante quando os produtores de dados definem interfaces de consumo para produtos de dados é a localização dos dados. Em geral, para minimizar custos, os dados precisam ser processados na mesma região em que estão armazenados. Essa abordagem ajuda a evitar cobranças de saída de dados entre regiões. Essa abordagem também tem a menor latência de consumo de dados. Por esses motivos, os dados armazenados em locais multirregionais do BigQuery costumam ser mais adequados para exposição como um produto de dados.
No entanto, por motivos de desempenho, os dados armazenados no Cloud Storage e expostos pelas tabelas do BigLake ou APIs de leitura direta precisam ser armazenados em buckets regionais.
Se os dados expostos em um produto estiverem em uma região e precisarem ser combinados com dados de outro domínio em outra região, os consumidores de dados precisarão considerar as seguintes limitações:
- As consultas entre regiões que usam SQL do BigQuery ficam indisponíveis. Se o método de consumo principal dos dados for o BigQuery SQL, todas as tabelas na consulta precisam estar no mesmo local.
- Os compromissos de taxa fixa do BigQuery são regionais. Se um projeto usar apenas um compromisso de taxa fixa em uma região, mas consultar um produto de dados em outra, os preços sob demanda são aplicados.
- Os consumidores de dados podem usar APIs de leitura direta para ler dados de outra região. No entanto, aplicam-se cobranças de saída de rede entre regiões, e os consumidores de dados provavelmente terão latência em grandes transferências de dados.
Os dados acessados com frequência nas regiões podem ser replicados para essas
regiões com o objetivo de reduzir o custo e a latência das consultas feitas pelos consumidores
do produto. Por exemplo, os
conjuntos de dados do BigQuery podem ser copiados
para outras regiões. No entanto, os dados só devem ser copiados quando necessário. Recomendamos
que os produtores de dados disponibilizem apenas um subconjunto de dados de produtos
disponíveis para várias regiões ao copiar dados. Essa abordagem ajuda a
minimizar a latência e o custo da replicação. Essa abordagem pode resultar na necessidade de
fornecer várias versões da interface de consumo, com a região do local dos dados
indicada explicitamente. Por exemplo, as visualizações autorizadas do BigQuery
podem ser expostas usando nomes como sales_eu_v1 e sales_us_v1.
As interfaces de fluxo de dados que usam tópicos do Pub/Sub não precisam de outra lógica de replicação para consumir mensagens em regiões que não são da mesma região em que a mensagem está armazenada. No entanto, cobranças de saída entre regiões são aplicadas nesse caso.
Expor interfaces de consumo aos consumidores de dados
Esta seção discute como tornar as interfaces de consumo detectáveis para consumidores em potencial. O Data Catalog é um serviço totalmente gerenciado que as organizações podem usar para fornecer os serviços de descoberta de dados e gerenciamento de metadados. Os produtores de dados precisam tornar as interfaces de consumo dos produtos de dados pesquisáveis e anotá-las com os metadados apropriados para permitir que os consumidores os acessem de maneira autônoma. Qua
As seções a seguir explicam como cada tipo de interface é definido como uma entrada do Data Catalog.
Interfaces SQL baseadas no BigQuery
Os metadados técnicos, como um nome ou esquema de tabela totalmente qualificado, são registrados automaticamente para visualizações autorizadas, visualizações do BigLake e tabelas do BigQuery disponíveis na API Storage Read. Recomendamos que os produtores de dados também forneçam informações adicionais na documentação do produto de dados para ajudar os consumidores de dados. Por exemplo, para ajudar os usuários a encontrar a documentação do produto de uma entrada, os produtores de dados podem adicionar um URL a uma das tags aplicadas à entrada. Os produtores também podem oferecer o seguinte:
- Conjuntos de colunas em cluster que precisam ser usadas em filtros de consulta.
- Valores de enumeração para campos que têm tipo de enumeração lógica, se o tipo não for fornecido como parte da descrição do campo.
- Mesclagens compatíveis com outras tabelas.
STREAMS DE DADOS
Os tópicos do Pub/Sub são registrados automaticamente com o Data Catalog. No entanto, os produtores de dados precisam descrever o esquema na documentação do produto de dados.
API Cloud Storage
O Data Catalog é compatível com a definição de entradas de arquivo do Cloud Storage e os seus esquemas. Se um conjunto de arquivos do data lake for gerenciado pelo Dataplex Universal Catalog, ele será registrado automaticamente no Data Catalog. Os conjuntos de arquivos que não estão associados ao Dataplex Universal Catalog são adicionados usando uma abordagem diferente.
Outras interfaces
É possível adicionar outras interfaces que não têm suporte integrado do Data Catalog criando entradas personalizadas.
A seguir
- Consulte uma implementação de referência da arquitetura da malha de dados.
- Saiba mais sobre o BigQuery.
- Conheça o Dataplex.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.