Riepilogo
Questo tutorial spiega il processo di deployment ed erogazione dei modelli Llama 3.1 e 3.2 utilizzando vLLM in Vertex AI. È progettato per essere utilizzato insieme a due notebook separati: Serve Llama 3.1 with vLLM per il deployment di modelli Llama 3.1 solo testuali e Serve Multimodal Llama 3.2 with vLLM per il deployment di modelli Llama 3.2 multimodali che gestiscono input sia di testo che di immagini. I passaggi descritti in questa pagina mostrano come gestire in modo efficiente l'inferenza dei modelli sulle GPU e come personalizzare i modelli per diverse applicazioni, così da avere gli strumenti per integrare modelli linguistici avanzati nei progetti.
Al termine di questa guida, saprai come:
- Scaricare modelli Llama predefiniti da Hugging Face con il container vLLM.
- Utilizzare vLLM per eseguire il deployment di questi modelli su istanze GPU all'interno di Google Cloud Vertex AI Model Garden.
- Erogare i modelli in modo efficiente per gestire le richieste di inferenza su larga scala.
- Eseguire l'inferenza su richieste di solo testo e richieste con testo e immagini.
- Esegui la pulizia.
- Eseguire il debug del deployment.
Funzionalità principali di vLLM
| Funzionalità | Descrizione |
|---|---|
| PagedAttention | Un meccanismo di attenzione ottimizzato che gestisce in modo efficiente la memoria durante l'inferenza. Supporta la generazione di testo ad alta velocità effettiva allocando dinamicamente le risorse di memoria, consentendo la scalabilità per più richieste simultanee. |
| Raggruppamento continuo | Consolida più richieste di input in un unico batch per l'elaborazione parallela, massimizzando l'utilizzo e il throughput della GPU. |
| Token streaming | Consente l'output in tempo reale token per token durante la generazione di testo. Ideale per le applicazioni che richiedono una bassa latenza, come chatbot o sistemi di AI interattivi. |
| Compatibilità del modello | Supporta un'ampia gamma di modelli preaddestrati nei framework più diffusi come Hugging Face Transformers. Semplifica l'integrazione e la sperimentazione di diversi LLM. |
| Multi-GPU e multi-host | Consente un servizio di modelli efficiente distribuendo il workload su più GPU all'interno di una singola macchina e su più macchine in un cluster, aumentando significativamente il throughput e la scalabilità. |
| Implementazione efficiente | Offre un'integrazione perfetta con le API, ad esempio il completamento della chat OpenAI, semplificando l'implementazione per i casi d'uso di produzione. |
| Integrazione perfetta con i modelli Hugging Face | vLLM è compatibile con il formato degli artefatti del modello Hugging Face e supporta il caricamento da HF, il che semplifica il deployment dei modelli Llama insieme ad altri modelli popolari come Gemma, Phi e Qwen in un'impostazione ottimizzata. |
| Progetto open source basato sulla community | vLLM è open source e incoraggia i contributi della community, promuovendo il miglioramento continuo dell'efficienza del servizio LLM. |
Personalizzazioni vLLM di Google Vertex AI: migliora le prestazioni e l'integrazione
L'implementazione di vLLM in Google Vertex AI Model Garden non è un'integrazione diretta della libreria open source. Vertex AI mantiene una versione personalizzata e ottimizzata di vLLM specificamente progettata per migliorare le prestazioni, l'affidabilità e l'integrazione perfetta all'interno di Google Cloud.
- Ottimizzazioni del rendimento:
- Download parallelo da Cloud Storage:accelera in modo significativo i tempi di caricamento e deployment dei modelli consentendo il recupero parallelo dei dati da Cloud Storage, riducendo la latenza e migliorando la velocità di avvio.
- Miglioramenti delle funzionalità:
- Dynamic LoRA con memorizzazione nella cache avanzata e supporto di Cloud Storage: estende le funzionalità di Dynamic LoRA con meccanismi di memorizzazione nella cache del disco locale e gestione robusta degli errori, oltre al supporto per il caricamento dei pesi LoRA direttamente dai percorsi Cloud Storage e dagli URL firmati. Ciò semplifica la gestione e il deployment di modelli personalizzati.
- Analisi della chiamata di funzione Llama 3.1/3.2: implementa un'analisi specializzata per la chiamata di funzione Llama 3.1/3.2, migliorando la robustezza dell'analisi.
- Memorizzazione nella cache del prefisso della memoria host: vLLM esterno supporta solo la memorizzazione nella cache del prefisso della memoria GPU.
- Decodifica speculativa:si tratta di una funzionalità vLLM esistente, ma Vertex AI ha eseguito esperimenti per trovare configurazioni di modelli ad alto rendimento.
Queste personalizzazioni specifiche di Vertex AI, spesso trasparenti per l'utente finale, ti consentono di massimizzare le prestazioni e l'efficienza dei deployment di Llama 3.1 su Vertex AI Model Garden.
- Integrazione dell'ecosistema Vertex AI:
- Supporto del formato di input/output di Vertex AI Prediction:garantisce la compatibilità perfetta con i formati di input e output di Vertex AI Prediction, semplificando la gestione dei dati e l'integrazione con altri servizi Vertex AI.
- Rilevamento delle variabili di ambiente Vertex: rispetta e utilizza
le variabili di ambiente Vertex AI (
AIP_*) per la configurazione e la gestione delle risorse, semplificando il deployment e garantendo un comportamento coerente all'interno dell'ambiente Vertex AI. - Gestione degli errori e robustezza migliorate: implementa meccanismi completi di gestione degli errori, convalida di input/output e terminazione del server per garantire stabilità, affidabilità e funzionamento senza interruzioni nell'ambiente Vertex AI gestito.
- Server Nginx per la funzionalità: integra un server Nginx sopra il server vLLM, facilitando il deployment di più repliche e migliorando la scalabilità e l'alta affidabilità dell'infrastruttura di pubblicazione.
Vantaggi aggiuntivi di vLLM
- Prestazioni di riferimento: vLLM offre prestazioni competitive rispetto ad altri sistemi di pubblicazione come Hugging Face text-generation-inference e FasterTransformer di NVIDIA in termini di velocità effettiva e latenza.
- Facilità d'uso: la libreria fornisce un'API semplice per l'integrazione con i flussi di lavoro esistenti, consentendoti di eseguire il deployment dei modelli Llama 3.1 e 3.2 con una configurazione minima.
- Funzionalità avanzate: vLLM supporta gli output di streaming (generando risposte token per token) e gestisce in modo efficiente i prompt di lunghezza variabile, migliorando l'interattività e la reattività nelle applicazioni.
Per una panoramica del sistema vLLM, consulta l'articolo.
Modelli supportati
vLLM supporta un'ampia selezione di modelli all'avanguardia, consentendoti di scegliere quello più adatto alle tue esigenze. La tabella seguente offre una selezione di questi modelli. Tuttavia, per accedere a un elenco completo di modelli supportati, inclusi quelli per l'inferenza solo testuale e multimodale, puoi consultare il sito web ufficiale di vLLM.
| Category | Modelli |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B e le relative varianti (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) e varianti (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B e varianti (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Altri modelli importanti | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Inizia a utilizzare Model Garden
Il container di servizio delle GPU Cloud vLLM è integrato in Model Garden, il playground, il deployment con un clic e gli esempi di notebook Colab Enterprise. Questo tutorial si concentra sulla famiglia di modelli Llama di Meta AI come esempio.
Utilizzare il notebook Colab Enterprise
Sono disponibili anche Playground e implementazioni con un clic, ma non sono descritte in questo tutorial.
- Vai alla pagina della scheda del modello e fai clic su Apri blocco note.
- Seleziona il notebook Vertex Serving. Il notebook viene aperto in Colab Enterprise.
- Esegui il notebook per eseguire il deployment di un modello utilizzando vLLM e invia richieste di previsione all'endpoint.
Configurazione e requisiti
Questa sezione descrive i passaggi necessari per configurare il progetto Google Cloude assicurarsi di disporre delle risorse necessarie per il deployment e la pubblicazione dei modelli vLLM.
1. Fatturazione
- Abilita fatturazione: assicurati che la fatturazione sia abilitata per il tuo progetto. Puoi fare riferimento ad Attivare, disattivare o modificare la fatturazione per un progetto.
2. Disponibilità e quote delle GPU
- Per eseguire previsioni utilizzando GPU ad alte prestazioni (NVIDIA A100 80 GB o H100 80 GB), assicurati di controllare le quote per queste GPU nella regione selezionata:
| Tipo di macchina | Tipo di acceleratore | Regioni consigliate |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Configurare un progetto Google Cloud
Esegui il seguente esempio di codice per assicurarti che l'ambiente Google Cloud sia configurato correttamente. Questo passaggio installa le librerie Python necessarie e configura l'accesso alle risorse Google Cloud . Le azioni includono:
- Installazione: esegui l'upgrade della libreria
google-cloud-aiplatforme clona il repository contenente le funzioni di utilità. - Configurazione dell'ambiente: definizione delle variabili per l'ID progetto Google Cloud , la regione e un bucket Cloud Storage univoco per l'archiviazione degli artefatti del modello.
- Attivazione API: abilita le API Vertex AI e Compute Engine, essenziali per il deployment e la gestione dei modelli di AI.
- Configurazione del bucket: crea un nuovo bucket Cloud Storage o controlla un bucket esistente per assicurarti che si trovi nella regione corretta.
- Inizializzazione di Vertex AI: inizializza la libreria client Vertex AI con le impostazioni di progetto, località e bucket di staging.
- Configurazione del service account: identifica il account di servizio predefinito per l'esecuzione dei job Vertex AI e concedigli le autorizzazioni necessarie.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Utilizzo di Hugging Face con Meta Llama 3.1, 3.2 e vLLM
Le raccolte Llama 3.1 e 3.2 di Meta forniscono una gamma di modelli linguistici di grandi dimensioni (LLM) multilingue progettati per la generazione di testo di alta qualità in vari casi d'uso. Questi modelli sono preaddestrati e ottimizzati per le istruzioni, eccellendo in attività come il dialogo multilingue, il riepilogo e il recupero di agenti. Prima di utilizzare i modelli Llama 3.1 e 3.2, devi accettare i relativi termini di utilizzo, come mostrato nello screenshot. La libreria vLLM offre un ambiente di servizio open source semplificato con ottimizzazioni per latenza, efficienza della memoria e scalabilità.
 Figura 1: Contratto di licenza per la community Meta LLama 3
Figura 1: Contratto di licenza per la community Meta LLama 3
Panoramica delle raccolte Meta Llama 3.1 e 3.2
Le raccolte Llama 3.1 e 3.2 sono adatte a diverse scale di deployment e dimensioni dei modelli, offrendoti opzioni flessibili per attività di dialogo multilingue e altro ancora. Per ulteriori informazioni, consulta la pagina Panoramica di Llama.
- Solo testo: la raccolta Llama 3.2 di modelli linguistici di grandi dimensioni (LLM) multilingue è una raccolta di modelli generativi preaddestrati e ottimizzati per le istruzioni nelle dimensioni 1B e 3B (testo in entrata, testo in uscita).
- Vision e Vision Instruct: la raccolta Llama 3.2-Vision di modelli linguistici di grandi dimensioni (LLM) multimodali è una raccolta di modelli generativi di ragionamento sulle immagini preaddestrati e ottimizzati per le istruzioni nelle dimensioni di 11 miliardi e 90 miliardi (testo + immagini in entrata, testo in uscita). Ottimizzazione: come Llama 3.1, i modelli 3.2 sono pensati per il dialogo multilingue e offrono ottime prestazioni nelle attività di recupero e riepilogo, ottenendo i migliori risultati nei benchmark standard.
- Architettura del modello: Llama 3.2 è dotato anche di un framework Transformer autoregressivo, con SFT e RLHF applicati per allineare i modelli in termini di utilità e sicurezza.
Token di accesso utente Hugging Face
Questo tutorial richiede un token di accesso in lettura da Hugging Face Hub per accedere alle risorse necessarie. Per configurare l'autenticazione:
 Figura 2: impostazioni del token di accesso a Hugging Face
Figura 2: impostazioni del token di accesso a Hugging Face
Genera un token di accesso in lettura:
- Vai alle impostazioni del tuo account Hugging Face.
- Crea un nuovo token, assegnagli il ruolo di lettura e salvalo in modo sicuro.
Utilizza il token:
- Utilizza il token generato per autenticarti e accedere ai repository pubblici o privati come richiesto per il tutorial.
 Figura 3: gestisci il token di accesso a Hugging Face
Figura 3: gestisci il token di accesso a Hugging Face
Questa configurazione ti garantisce il livello di accesso appropriato senza autorizzazioni non necessarie. Queste pratiche migliorano la sicurezza ed evitano l'esposizione accidentale dei token. Per ulteriori informazioni sulla configurazione dei token di accesso, visita la pagina Token di accesso di Hugging Face.
Evita di condividere o esporre il token pubblicamente o online. Quando imposti il token come variabile di ambiente durante il deployment, rimane privato per il tuo progetto. Vertex AI garantisce la propria sicurezza impedendo ad altri utenti di accedere ai tuoi modelli e ai tuoi endpoint.
Per maggiori informazioni sulla protezione del token di accesso, consulta la pagina Token di accesso di Hugging Face - Best Practices.
Deployment di modelli Llama 3.1 solo testuali con vLLM
Per il deployment a livello di produzione di modelli linguistici di grandi dimensioni, vLLM fornisce una soluzione di serving efficiente che ottimizza l'utilizzo della memoria, riduce la latenza e aumenta la velocità effettiva. Ciò lo rende particolarmente adatto alla gestione dei modelli Llama 3.1 più grandi e dei modelli multimodali Llama 3.2.
Passaggio 1: scegli un modello di cui eseguire il deployment
Scegli la variante del modello Llama 3.1 di cui eseguire il deployment. Le opzioni disponibili includono varie dimensioni e versioni ottimizzate per le istruzioni:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Passaggio 2: controlla l'hardware di deployment e la quota
La funzione di deployment imposta il tipo di GPU e di macchina appropriato in base alle dimensioni del modello e controlla la quota in quella regione per un progetto specifico:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
Verifica la disponibilità della quota GPU nella regione specificata:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Passaggio 3: ispeziona il modello utilizzando vLLM
La seguente funzione carica il modello su Vertex AI, configura le impostazioni di deployment ed esegue il deployment su un endpoint utilizzando vLLM.
- Immagine Docker: il deployment utilizza un'immagine Docker vLLM predefinita per un servizio efficiente.
- Configurazione: configura l'utilizzo della memoria, la lunghezza del modello e altre impostazioni vLLM. Per ulteriori informazioni sugli argomenti supportati dal server, visita la pagina della documentazione ufficiale di vLLM.
- Variabili di ambiente: imposta le variabili di ambiente per l'autenticazione e l'origine del deployment.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Passaggio 4: esegui il deployment
Esegui la funzione di deployment con il modello e la configurazione selezionati. Questo passaggio esegue il deployment del modello e restituisce le istanze del modello e dell'endpoint:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Dopo aver eseguito questo esempio di codice, il modello Llama 3.1 verrà sottoposto a deployment su Vertex AI e sarà accessibile tramite l'endpoint specificato. Puoi interagire con lui per attività di inferenza come la generazione di testo, il riassunto e il dialogo. A seconda delle dimensioni del modello, il deployment del nuovo modello può richiedere fino a un'ora. Puoi controllare l'avanzamento nella previsione online.
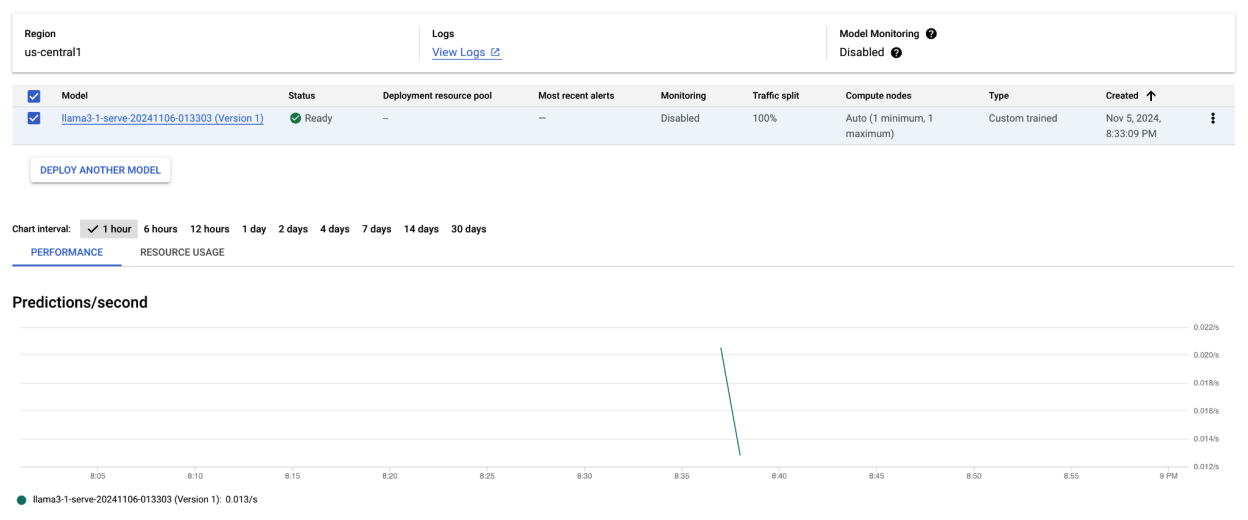 Figura 4: endpoint di deployment di Llama 3.1 nella dashboard Vertex
Figura 4: endpoint di deployment di Llama 3.1 nella dashboard Vertex
Fare previsioni con Llama 3.1 su Vertex AI
Dopo aver eseguito il deployment del modello Llama 3.1 su Vertex AI, puoi iniziare a fare previsioni inviando prompt di testo all'endpoint. Questa sezione fornisce un esempio di generazione di risposte con vari parametri personalizzabili per controllare l'output.
Passaggio 1: definisci il prompt e i parametri
Inizia configurando il prompt di testo e i parametri di campionamento per guidare la risposta del modello. Ecco i parametri principali:
prompt: il testo di input per cui vuoi che il modello generi una risposta. Ad esempio, prompt = "Che cos'è un'auto?".max_tokens: il numero massimo di token nell'output generato. La riduzione di questo valore può contribuire a evitare problemi di timeout.temperature: controlla la casualità delle previsioni. Valori più alti (ad esempio, 1,0) aumentano la diversità, mentre valori più bassi (ad esempio, 0,5) rendono l'output più mirato.top_p: limita il pool di campionamento alla probabilità cumulativa più alta. Ad esempio, se imposti top_p = 0,9, verranno presi in considerazione solo i token con una massa di probabilità del 90% superiore.top_k: limita il campionamento ai primi k token più probabili. Ad esempio, se imposti top_k = 50, il campionamento verrà eseguito solo sui primi 50 token.raw_response: se è True, restituisce l'output grezzo del modello. Se False, applica una formattazione aggiuntiva con la struttura "Prompt:\n{prompt}\nOutput:\n{output}".lora_id(facoltativo): percorso dei file dei pesi LoRA per applicare i pesi dell'adattamento a basso ranking (LoRA). Può essere un bucket Cloud Storage o un URL del repository Hugging Face. Tieni presente che questa opzione funziona solo se--enable-loraè impostato negli argomenti di deployment. Dynamic LoRA non è supportato per i modelli multimodali.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Passaggio 2: invia la richiesta di previsione
Ora che l'istanza è configurata, puoi inviare la richiesta di previsione all'endpoint Vertex AI di cui è stato eseguito il deployment. Questo esempio mostra come fare una previsione e stampare il risultato:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Output di esempio
Ecco un esempio di come il modello potrebbe rispondere al prompt "Che cos'è un'auto?":
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Note aggiuntive
- Moderazione: per garantire contenuti sicuri, puoi moderare il testo generato con le funzionalità di moderazione del testo di Vertex AI.
- Gestione dei timeout: se riscontri problemi come
ServiceUnavailable: 503, prova a ridurre il parametromax_tokens.
Questo approccio offre un modo flessibile per interagire con il modello Llama 3.1 utilizzando diverse tecniche di campionamento e adattatori LoRA, rendendolo adatto a una varietà di casi d'uso, dalla generazione di testo generico alle risposte specifiche per attività.
Deployment di modelli Llama 3.2 multimodali con vLLM
Questa sezione descrive il processo di caricamento dei modelli Llama 3.2 predefiniti nel registro dei modelli e il loro deployment in un endpoint Vertex AI. Il tempo di deployment può richiedere fino a un'ora, a seconda delle dimensioni del modello. I modelli Llama 3.2 sono disponibili in versioni multimodali che supportano input sia di testo che di immagini. vLLM supporta:
- Formato solo testo
- Formato con una sola immagine e testo
Questi formati rendono Llama 3.2 adatto ad applicazioni che richiedono l'elaborazione sia di immagini che di testo.
Passaggio 1: scegli un modello di cui eseguire il deployment
Specifica la variante del modello Llama 3.2 di cui vuoi eseguire il deployment. L'esempio seguente
utilizza Llama-3.2-11B-Vision come modello selezionato, ma puoi scegliere tra altre
opzioni disponibili in base ai tuoi requisiti.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Passaggio 2: configura l'hardware e le risorse
Seleziona l'hardware appropriato per le dimensioni del modello. vLLM può utilizzare GPU diverse a seconda delle esigenze di calcolo del modello:
- Modelli 1B e 3B: utilizza le GPU NVIDIA L4.
- Modelli da 11 miliardi: utilizza le GPU NVIDIA A100.
- Modelli da 90 miliardi: utilizza le GPU NVIDIA H100.
Questo esempio configura il deployment in base alla selezione del modello:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Assicurati di disporre della quota GPU richiesta:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Passaggio 3: esegui il deployment del modello utilizzando vLLM
La seguente funzione gestisce il deployment del modello Llama 3.2 su Vertex AI. Configura l'ambiente, l'utilizzo della memoria e le impostazioni vLLM del modello per una pubblicazione efficiente.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Passaggio 4: esegui il deployment
Esegui la funzione di deployment con il modello e le impostazioni configurati. La funzione restituirà sia le istanze del modello sia quelle dell'endpoint, che puoi utilizzare per l'inferenza.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
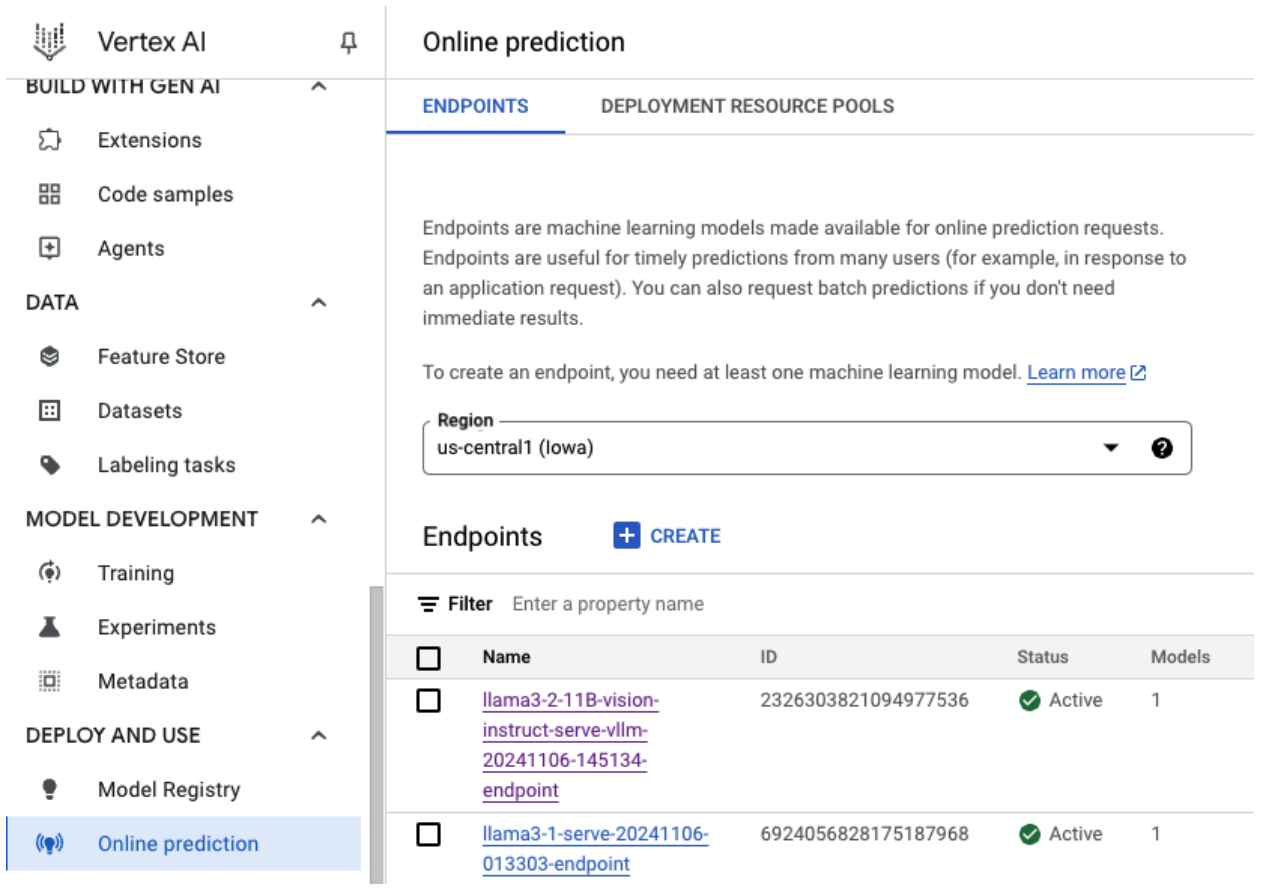 Figura 5: endpoint di deployment di Llama 3.2 nella dashboard Vertex
Figura 5: endpoint di deployment di Llama 3.2 nella dashboard Vertex
A seconda delle dimensioni del modello, il deployment del nuovo modello può richiedere fino a un'ora. Puoi controllare l'avanzamento nella previsione online.
Inferenza con vLLM su Vertex AI utilizzando il percorso di previsione predefinito
Questa sezione ti guida nella configurazione dell'inferenza per il modello Llama 3.2 Vision su Vertex AI utilizzando il percorso di previsione predefinito. Utilizzerai la libreria vLLM per un servizio efficiente e interagirai con il modello inviando un prompt visivo in combinazione con il testo.
Per iniziare, assicurati che l'endpoint del modello sia implementato e pronto per le previsioni.
Passaggio 1: definisci il prompt e i parametri
Questo esempio fornisce un URL immagine e un prompt di testo, che il modello elaborerà per generare una risposta.
 Figura 6: input di esempio di un'immagine per richiedere a Llama 3.2 di generare un prompt
Figura 6: input di esempio di un'immagine per richiedere a Llama 3.2 di generare un prompt
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Passaggio 2: configura i parametri di previsione
Modifica i seguenti parametri per controllare la risposta del modello:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Passaggio 3: prepara la richiesta di previsione
Configura la richiesta di previsione con l'URL dell'immagine, il prompt e altri parametri.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Passaggio 4: fai la previsione
Invia la richiesta all'endpoint Vertex AI ed elabora la risposta:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Se si verifica un problema di timeout (ad esempio, ServiceUnavailable: 503 Took too
long to respond when processing), prova a ridurre il valore di max_tokens a un numero inferiore, ad esempio 20, per ridurre il tempo di risposta.
Inferenza con vLLM su Vertex AI utilizzando OpenAI Chat Completion
Questa sezione descrive come eseguire l'inferenza sui modelli Llama 3.2 Vision utilizzando l'API Chat Completions di OpenAI su Vertex AI. Questo approccio ti consente di utilizzare le funzionalità multimodali inviando al modello prompt di testo e immagini per risposte più interattive.
Passaggio 1: esegui il deployment del modello Llama 3.2 Vision Instruct
Esegui la funzione di deployment con il modello e le impostazioni configurati. La funzione restituirà sia le istanze del modello sia quelle dell'endpoint, che puoi utilizzare per l'inferenza.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Passaggio 2: configura la risorsa endpoint
Inizia configurando il nome della risorsa endpoint per il deployment di Vertex AI.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Passaggio 3: installa l'SDK OpenAI e le librerie di autenticazione
Per inviare richieste utilizzando l'SDK di OpenAI, assicurati che le librerie necessarie siano installate:
!pip install -qU openai google-auth requests
Passaggio 4: definisci i parametri di input per il completamento della chat
Configura l'URL dell'immagine e il prompt di testo che verranno inviati al modello. Regola
max_tokens e temperature per controllare rispettivamente la lunghezza e la casualità della risposta.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Passaggio 5: configura l'autenticazione e l'URL di base
Recupera le credenziali e imposta l'URL di base per le richieste API.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Passaggio 6: invia la richiesta di completamento della chat
Utilizzando l'API Chat Completions di OpenAI, invia l'immagine e il prompt di testo al tuo endpoint Vertex AI:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
(Facoltativo) Passaggio 7: ricollega un endpoint esistente
Per riconnetterti a un endpoint creato in precedenza, utilizza l'ID endpoint. Questo passaggio è utile se vuoi riutilizzare un endpoint anziché crearne uno nuovo.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Questa configurazione offre la flessibilità di passare da endpoint appena creati a endpoint esistenti in base alle esigenze, consentendo test e implementazione semplificati.
Esegui la pulizia
Per evitare addebiti continui e liberare risorse, assicurati di eliminare i modelli e gli endpoint di cui è stato eseguito il deployment e, facoltativamente, il bucket di archiviazione utilizzato per questo esperimento.
Passaggio 1: elimina endpoint e modelli
Il seguente codice annulla il deployment di ogni modello ed elimina gli endpoint associati:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Passaggio 2: (facoltativo) elimina il bucket Cloud Storage
Se hai creato un bucket Cloud Storage appositamente per questo esperimento, puoi eliminarlo impostando delete_bucket su True. Questo passaggio è facoltativo, ma consigliato se il bucket non è più necessario.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Se segui questi passaggi, ti assicuri che tutte le risorse utilizzate in questo tutorial vengano eliminate, riducendo i costi non necessari associati all'esperimento.
Debug dei problemi comuni
Questa sezione fornisce indicazioni per identificare e risolvere i problemi comuni riscontrati durante il deployment e l'inferenza del modello vLLM su Vertex AI.
Controllare i log
Controlla i log per identificare la causa principale degli errori di deployment o del comportamento inatteso:
- Vai alla console Vertex AI Prediction:vai alla console Vertex AI Prediction nella console Google Cloud .
- Seleziona l'endpoint:fai clic sull'endpoint che presenta problemi. Lo stato dovrebbe indicare se il deployment non è riuscito.
- Visualizza log:fai clic sull'endpoint e poi vai alla scheda Log o fai clic su Visualizza log. Viene visualizzato Cloud Logging, filtrato per mostrare i log specifici per l'endpoint e il deployment del modello. Puoi anche accedere ai log direttamente tramite il servizio Cloud Logging.
- Analizza i log: esamina le voci dei log per trovare messaggi di errore, avvisi e altre informazioni pertinenti. Visualizza i timestamp per correlare le voci di log con azioni specifiche. Cerca problemi relativi a vincoli delle risorse (memoria e CPU), problemi di autenticazione o errori di configurazione.
Problema comune 1: esaurimento della memoria CUDA durante il deployment
Gli errori CUDA Out of Memory (OOM) si verificano quando l'utilizzo di memoria del modello supera la capacità GPU disponibile.
Nel caso del modello solo testo, abbiamo utilizzato i seguenti argomenti del motore:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
Nel caso del modello multimodale, abbiamo utilizzato i seguenti argomenti del motore:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
Il deployment del modello multimodale con max_num_seqs = 256, come abbiamo fatto nel caso del modello solo di testo, potrebbe causare il seguente errore:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
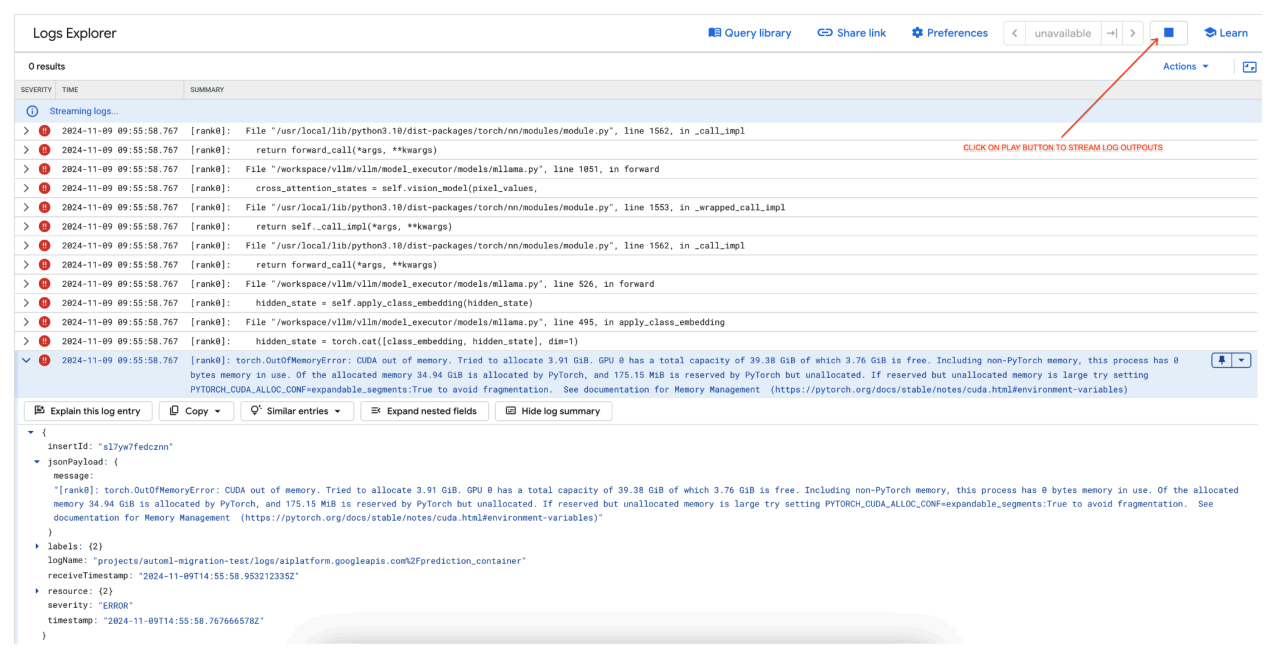 Figura 7: Log degli errori della GPU Out of Memory (OOM)
Figura 7: Log degli errori della GPU Out of Memory (OOM)
Informazioni su max_num_seqs e memoria GPU:
- Il parametro
max_num_seqsdefinisce il numero massimo di richieste simultanee che il modello può gestire. - Ogni sequenza elaborata dal modello consuma memoria GPU. L'utilizzo totale della memoria è proporzionale a
max_num_seqsvolte la memoria per sequenza. - I modelli solo testuali (come Meta-Llama-3.1-8B) in genere consumano meno memoria per sequenza rispetto ai modelli multimodali (come Llama-3.2-11B-Vision-Instruct), che elaborano sia testo che immagini.
Esamina il log degli errori (figura 8):
- Il log mostra un
torch.OutOfMemoryErrordurante il tentativo di allocare memoria sulla GPU. - L'errore si verifica perché l'utilizzo della memoria del modello supera la capacità della GPU
disponibile. La GPU NVIDIA L4 ha 24 GB e l'impostazione del parametro
max_num_seqstroppo elevato per il modello multimodale causa un overflow. - Il log suggerisce di impostare
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Trueper migliorare la gestione della memoria, anche se il problema principale è l'utilizzo elevato della memoria.
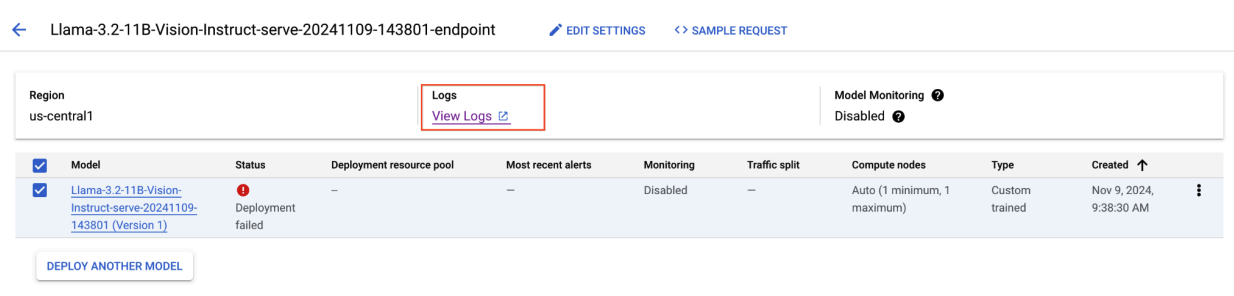 Figura 8: deployment di Llama 3.2 non riuscito
Figura 8: deployment di Llama 3.2 non riuscito
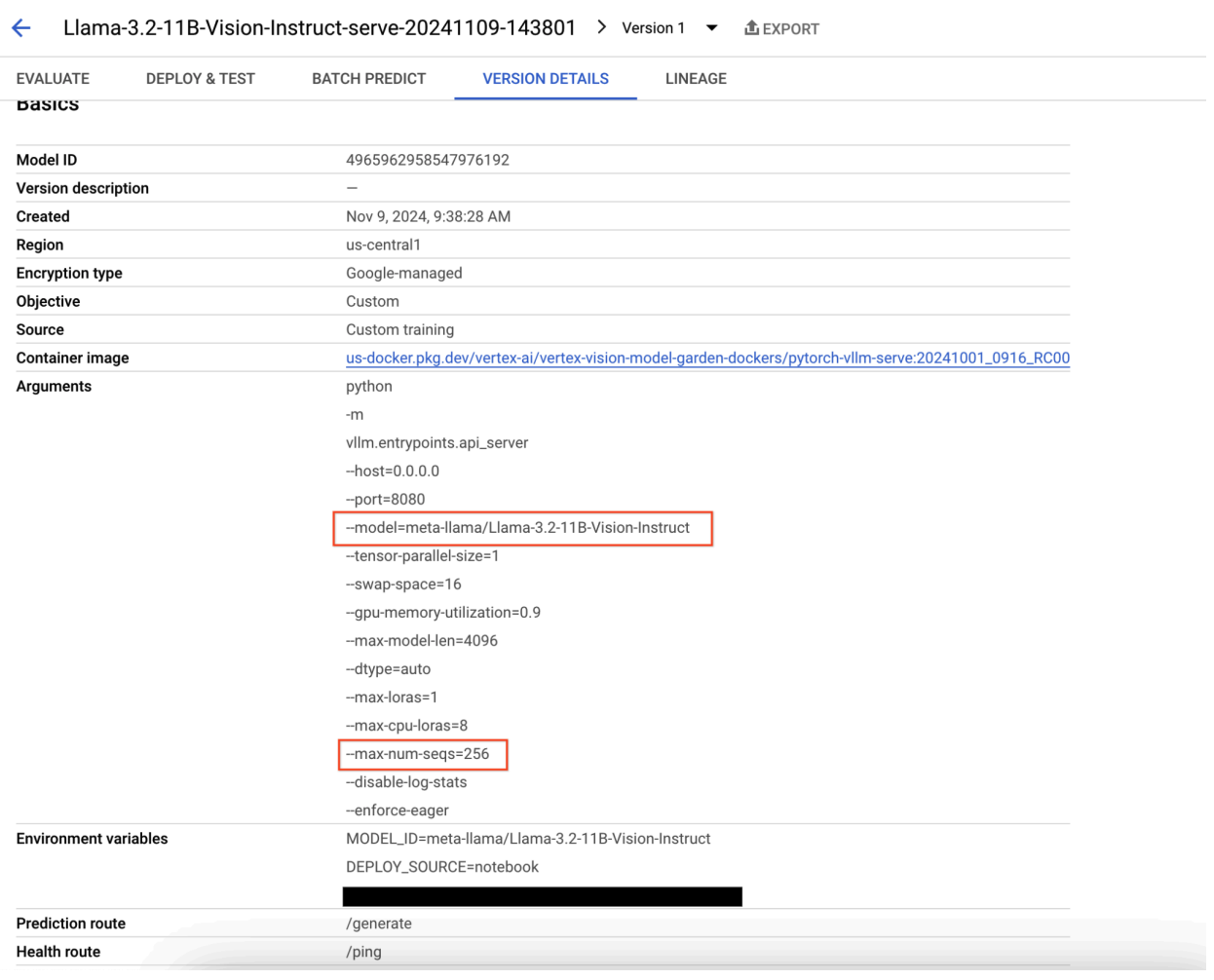 Figura 9: Riquadro dei dettagli della versione del modello
Figura 9: Riquadro dei dettagli della versione del modello
Per risolvere il problema, vai alla console Vertex AI Prediction e fai clic sull'endpoint. Lo stato dovrebbe indicare che il deployment non è riuscito. Fai clic per visualizzare i log. Verifica che max-num-seqs = 256. Questo valore è troppo alto per Llama-3.2-11B-Vision-Instruct. Un valore più adeguato dovrebbe essere 12.
Problema comune 2: è necessario il token Hugging Face
Gli errori del token Hugging Face si verificano quando il modello è protetto e richiede credenziali di autenticazione appropriate per l'accesso.
Lo screenshot seguente mostra una voce di log in Log Explorer di Google Cloud che mostra un messaggio di errore relativo all'accesso al modello Meta LLaMA-3.2-11B-Vision ospitato su Hugging Face. L'errore indica che l'accesso al modello è limitato e richiede l'autenticazione per procedere. Il messaggio indica specificamente "Impossibile accedere al repository controllato per l'URL", sottolineando che il modello è controllato e richiede credenziali di autenticazione appropriate per l'accesso. Questa voce di log può aiutarti a risolvere i problemi di autenticazione quando lavori con risorse con limitazioni in repository esterni.
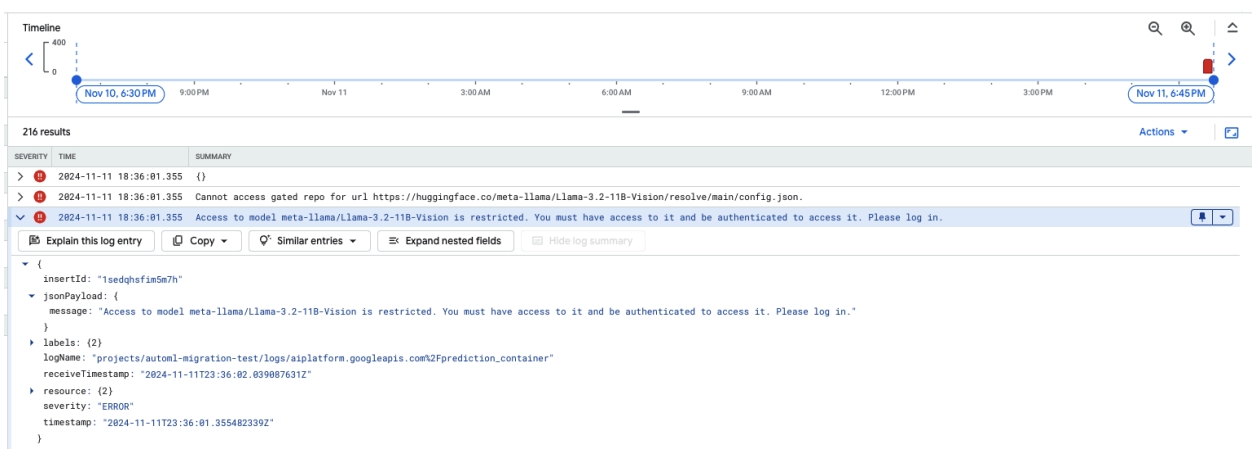 Figura 10: errore del token Hugging Face
Figura 10: errore del token Hugging Face
Per risolvere il problema, verifica le autorizzazioni del token di accesso a Hugging Face. Copia l'ultimo token e implementa un nuovo endpoint.
Problema comune 3: è necessario un modello di chat
Gli errori del modello di chat si verificano quando il modello di chat predefinito non è più consentito e deve essere fornito un modello di chat personalizzato se il tokenizer non ne definisce uno.
Questo screenshot mostra una voce di log in Log Explorer di Google Cloud, in cui si verifica un ValueError a causa di un modello di chat mancante nella versione 4.44 della libreria transformers. Il messaggio di errore indica che il modello di chat predefinito non è più consentito e che deve essere fornito un modello di chat personalizzato se il tokenizer non ne definisce uno. Questo errore evidenzia una recente modifica nella libreria che richiede la definizione esplicita di un modello di chat, utile per il debug dei problemi durante il deployment di applicazioni basate sulla chat.
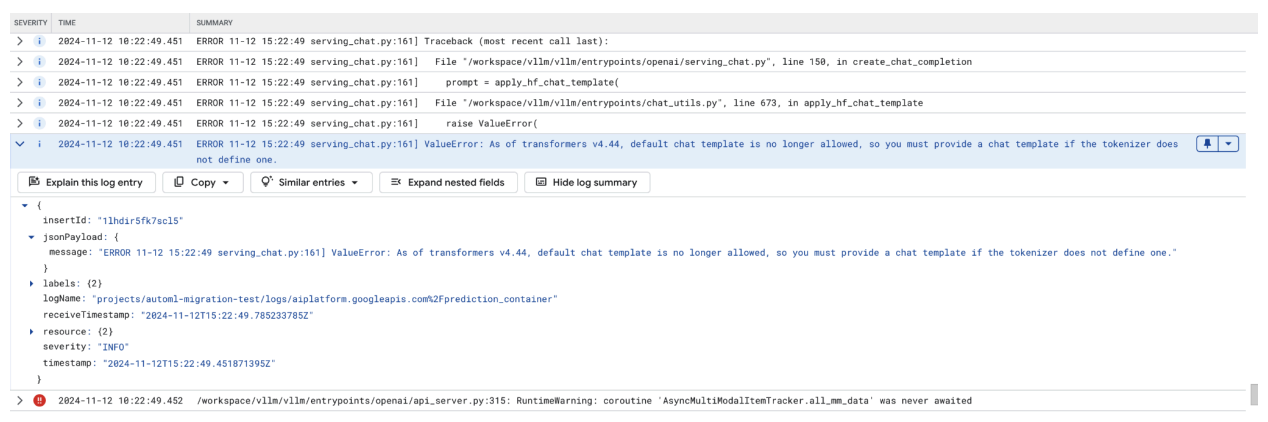 Figura 11: Modello di chat necessario
Figura 11: Modello di chat necessario
Per aggirare questo problema, assicurati di fornire un modello di chat durante il deployment utilizzando l'argomento di input --chat-template. I modelli di esempio sono disponibili nel repository
di esempi vLLM.
Problema comune 4: Model Max Seq Len
Gli errori relativi alla lunghezza massima della sequenza del modello si verificano quando la lunghezza massima della sequenza del modello (4096) è maggiore del numero massimo di token che possono essere archiviati nella cache KV (2256).
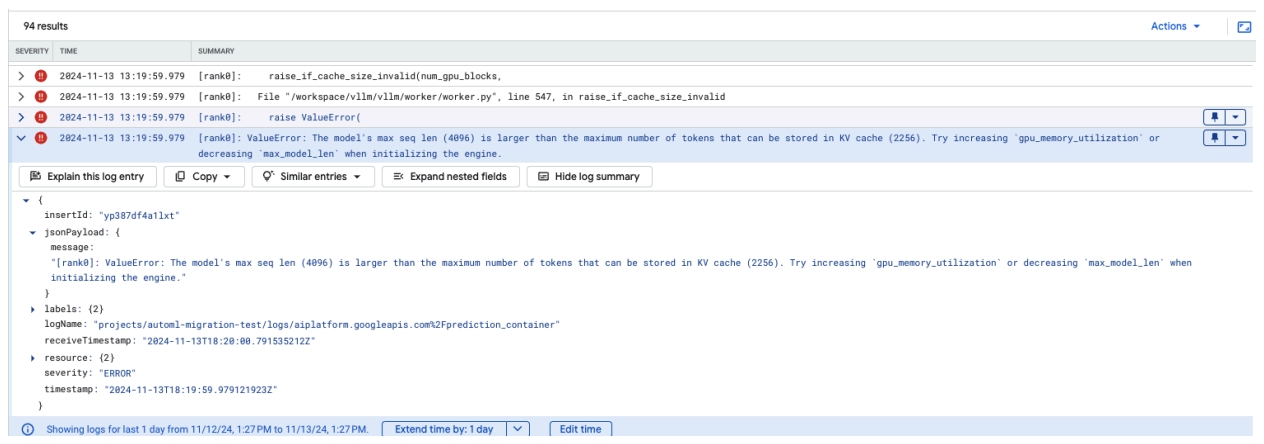 Figura 12: Max Seq Length troppo grande
Figura 12: Max Seq Length troppo grande
ValueError: The model's max seq len (4096) is larger than the maximum number of
tokens that can be stored in KV cache (2256). Prova ad aumentare
gpu_memory_utilization o diminuire max_model_len durante l'inizializzazione
del motore.
Per risolvere il problema, imposta max_model_len su 2048, che è inferiore a 2256. Un'altra soluzione a questo problema è utilizzare GPU più numerose o più grandi. Se scegli di utilizzare più GPU, tensor-parallel-size dovrà essere impostato in modo appropriato.
Note di rilascio del container vLLM di Model Garden
Release principali
vLLM standard
Data di uscita |
Architettura |
Versione vLLM |
URI container |
|---|---|---|---|
| 17 luglio 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10 luglio 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20 giugno 2025 | x86 |
Dopo la versione v0.9.1, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11 giugno 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2 giugno 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6 maggio 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| Apr 29, 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| Apr 17, 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| Apr 10, 2025 | x86 |
Versioni successive alla 0.8.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| Apr 7, 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| Apr 7, 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| Apr 5, 2025 | x86 |
Versioni successive alla v0.8.2, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31 marzo 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26 marzo 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| Mar 23, 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21 marzo 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| Mar 11, 2025 | x86 |
Versioni precedenti alla v0.7.3, commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| Mar 3, 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14 gen 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2 dic 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12 nov 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16 ottobre 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
vLLM ottimizzato
Data di uscita |
Architettura |
URI container |
|---|---|---|
| 21 gennaio 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29 ottobre 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Altre uscite
L'elenco completo delle release dei contenitori vLLM standard di VMG è disponibile nella pagina Artifact Registry.
Le release di vLLM-TPU in stato sperimentale sono contrassegnate con <yyyymmdd_hhmm_tpu_experimental_RC00>.