如查詢執行計畫所述,SQL 編譯器會將 SQL 陳述式轉換成查詢執行計畫,用來取得查詢的結果。本頁面說明建構 SQL 陳述式的最佳做法,協助 Spanner 找到有效率的執行計畫。
本頁面列出的範例 SQL 陳述式使用下列範例結構定義:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
如需更多資訊,請參閱「Spanner 中的 PostgreSQL 語言」。
使用查詢參數
Spanner 支援查詢參數,可提高效能,並在使用者輸入內容建構查詢時,協助防止 SQL 植入。您可以使用查詢參數取代任意運算式,但不可取代 ID、欄名稱、資料表名稱或查詢的其他部分。
參數可以用於任何使用文字值的地方。在單一 SQL 陳述式中,可以多次使用相同的參數名稱。
簡單來說,查詢參數可透過下列方式支援查詢執行作業:
- 預先最佳化的計畫:使用參數的查詢在每次叫用時能夠獲得更快的執行速度,因為參數化讓 Spanner 更容易快取執行計劃。
- 簡化查詢的撰寫:在查詢參數中提供字串值時,無需逸出字串值。查詢參數也會降低語法錯誤的風險。
- 安全性:查詢參數可抵禦各種 SQL 植入攻擊,讓查詢更安全。這對於您根據使用者輸入內容建立的查詢而言尤其重要。
瞭解 Spanner 執行查詢的方式
Spanner 可讓您使用宣告式 SQL 陳述式查詢資料庫,指定您要擷取的資料。如要瞭解 Spanner 取得結果的方式,請檢查查詢的執行計畫。查詢執行計劃可顯示查詢每個步驟的相關運算成本。您可以利用這些成本,針對查詢效能問題進行除錯,並最佳化查詢。如需更多資訊,請參閱「查詢執行計劃」。
您可以透過 Google Cloud 控制台或用戶端程式庫擷取查詢執行計劃。
如要使用 Google Cloud 控制台取得特定查詢的查詢執行計畫,請按照下列步驟操作:
開啟 Spanner 執行個體頁面。
選取 Spanner 例項和要查詢的資料庫名稱。
按一下左側導覽面板中的「Spanner Studio」。
在文字欄位中輸入查詢內容,然後按一下「執行查詢」。
按一下「說明」
。 Google Cloud 控制台會顯示視覺化的查詢執行計畫。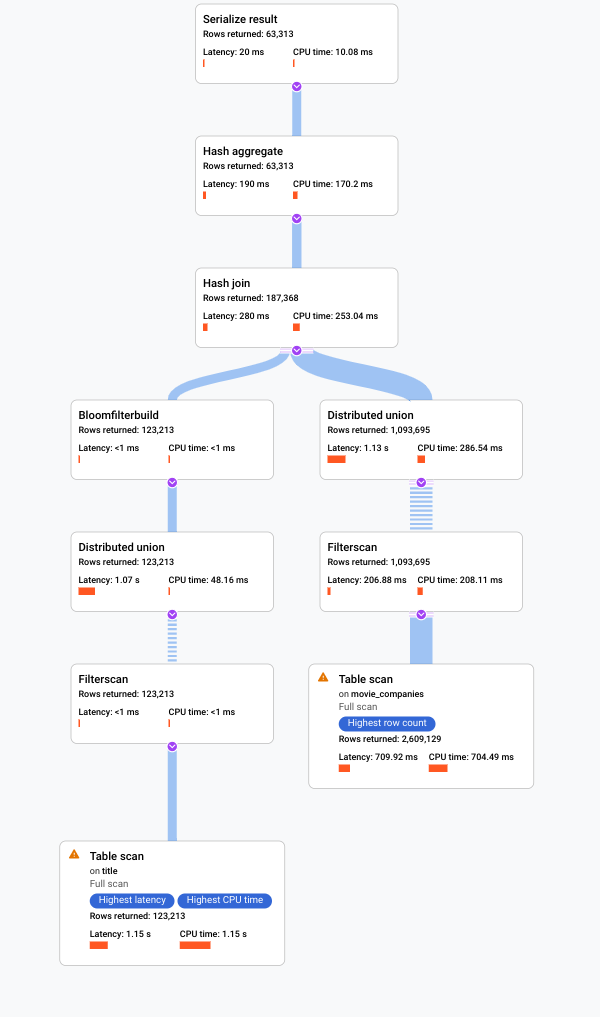
如要進一步瞭解如何解讀視覺化計畫,並使用這些計畫來偵錯查詢,請參閱「使用查詢計畫視覺化工具調整查詢」。
您也可以查看歷來查詢計畫的範例,並比較特定查詢在一段時間內的查詢成效。如需更多資訊,請參閱「取樣的查詢計畫」。
使用次要索引
與其他關聯資料庫相同,Spanner 提供次要索引,您可以透過 SQL 陳述式或 Spanner 的讀取介面,使用次要索引來擷取資料。從索引擷取資料的常見做法是使用 Spanner Studio。在 SQL 查詢中使用次要索引,可讓您指定 Spanner 取得結果的方式。指定次要索引可加快查詢執行速度。
例如,假設您要擷取所有有特定姓氏的歌手 ID。撰寫此種 SQL 查詢的其中一種方式如下:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
此查詢會傳回您預期的結果,但傳回結果可能需要很長的時間。時間取決於 Singers 資料表中的列數,以及符合述詞 WHERE s.LastName = 'Smith' 的數量。如果次要索引沒有包含可讀取的 LastName 資料欄,查詢計劃將讀取整個 Singers 資料表,以找出符合述詞的資料列。讀取整個資料表稱為「完整資料表掃描」。如果資料表中只有一小部分的 Singers 有該姓氏,為取得結果而進行完整資料表掃描的費用將十分昂貴。
您可以在姓氏欄上定義次要索引,來改善此查詢的效能:
CREATE INDEX SingersByLastName ON Singers (LastName);
由於次要索引 SingersByLastName 包含被索引的資料欄 LastName 和主鍵欄 SingerId,Spanner 可以從較小的索引資料表擷取所有資料,不必掃描完整的 Singers 資料表。
在這種情況下,Spanner 會在執行查詢時自動使用次要索引 SingersByLastName (只要資料庫建立後已過三天,請參閱關於新資料庫的注意事項)。不過,建議您在 FROM 子句中指定索引指令,明確告知 Spanner 使用該索引:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
現在,假設除了 ID 之外,您也想要擷取歌手的名字。即使索引中未包含 FirstName 資料欄,您也可使用之前的做法來指定索引指令:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
您仍可透過索引來獲得效能優勢,因為 Spanner 不需要在執行查詢計劃時進行完整表格掃描。而是從 SingersByLastName 索引中選取一部分滿足述詞的資料列,然後在主資料表 Singers 執行查詢,針對該資料列子集擷取名字。
如果您不希望 Spanner 從主資料表擷取任何資料列,可以選擇將 FirstName 資料欄的複本儲存在索引中:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
像這樣使用 STORING 子句 (適用於 GoogleSQL 方言) 或 INCLUDE 子句 (適用於 PostgreSQL 方言) 雖然會消耗額外的儲存空間,但會提供下列優勢:
- 如果 SQL 查詢使用索引並選取儲存在
STORING或INCLUDE子句中的資料欄,就不需額外與主資料表彙整。 - 如果讀取呼叫使用索引,可讀取儲存在
STORING或INCLUDE子句中的資料欄。
上方範例說明次要索引加速查詢的方法:藉由使用次要索引,快速找出查詢的 WHERE 子句選取的資料列。
另一個次要索引可提供效能優勢的情境是讓特定查詢傳回排序結果。例如,假設您想要擷取所有專輯名稱和其發行日期,並依發行日期遞增和專輯名稱遞減的順序傳回。您可以編寫類似下方的 SQL 查詢:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
少了次要索引,在查詢計劃中,此查詢的排序步驟中可能十分昂貴。您可以透過定義下方這個次要索引,加快查詢執行的速度:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
然後,重新寫入查詢以使用次要索引:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
此查詢和索引定義同時符合下列兩個條件:
- 如要移除排序步驟,請確認
ORDER BY子句中的資料欄清單是索引鍵清單的前置字串。 - 為避免從主資料表彙整回來,以便擷取任何遺漏的資料欄,請確保索引涵蓋查詢使用的資料表中所有資料欄。
雖然次要索引可加速一般查詢作業,但增加次要索引可能會增加修訂作業的延遲時間。因為每個次要索引通常在每次修訂時都需要使用一個額外的節點。就多數的工作負載而言,少量的次要索引不會產生問題。然而,您必須決定您比較在意讀取或寫入的延遲,並考慮對您的工作負載來說,哪些作業最為關鍵。為工作負載設定基準,確保工作負載的效能滿足您的期望。
如需完整的次要索引參考資料,請參閱次要索引。
最佳化掃描
在掃描資料時,使用以批次為導向的處理方法,而非較常見的以列為導向的處理方法,可能會讓某些 Spanner 查詢更有效率。以批次處理掃描作業是處理大量資料的更有效率方式,可讓查詢降低 CPU 使用率和延遲時間。
Spanner 掃描作業一律會在以列為導向的方法中開始執行。在這段期間,Spanner 會收集多個執行階段指標。接著,Spanner 會根據這些指標的結果套用一組經驗法則,以決定最佳掃描方法。在適當情況下,Spanner 會切換為以批次為導向的處理方法,以便提升掃描吞吐量和效能。
常見用途
具有下列特徵的查詢通常可從使用以批次為導向的處理作業中受益:
- 針對更新頻率不高的資料執行大規模掃描作業。
- 在固定寬度資料欄上使用謂詞進行掃描。
- 掃描時需要大量搜尋次數。(搜尋會使用索引來擷取記錄)。
沒有效能提升的用途
並非所有查詢都適合以批次為導向的處理方式。以下查詢類型在以列為導向的掃描處理作業中,效能會更佳:
- 點對點查詢:只擷取一列的查詢。
- 小型掃描查詢:資料表掃描作業只掃描少數資料列,除非這些資料列有大量搜尋計數。
- 使用
LIMIT的查詢。 - 讀取高流失率資料的查詢:讀取的資料超過 10% 經常更新的查詢。
- 查詢包含大型值的資料列:大型值資料列是指單一資料欄中包含的值大於 32,000 個位元組 (經過壓縮)。
檢查查詢使用的掃描方法
如要確認查詢是否使用批次導向處理、列導向處理,或自動在兩種掃描方法之間切換:
前往Google Cloud 控制台的 Spanner「Instances」(執行個體) 頁面。
按一下要調查查詢的執行個體名稱。
在「資料庫」表格下方,按一下含有要調查查詢的資料庫。
在導覽選單中,按一下「Spanner Studio」。
按一下 「New SQL editor tab」或 「New tab」,開啟新分頁。
查詢編輯器隨即顯示,請編寫查詢。
按一下「執行」。
Spanner 會執行查詢並顯示結果。
按一下查詢編輯器下方的「Explanation」分頁標籤。
Spanner 會顯示查詢執行計畫檢視器。圖表中的每張資訊卡都代表一個疊代器。
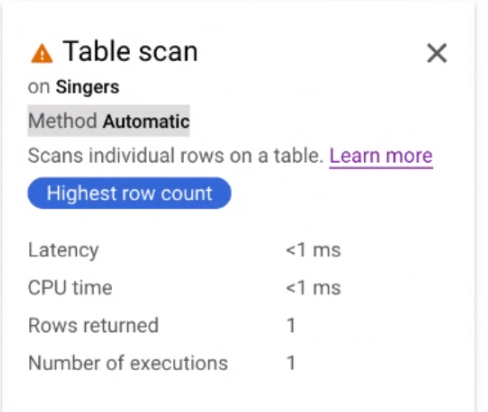
按一下「表格掃描」疊代器資訊卡,開啟資訊面板。
資訊面板會顯示所選掃描作業的背景資訊。這個資訊卡會顯示掃描方法。「Automatic」表示 Spanner 會決定掃描方法。其他可能的值包括 Batch (針對批次導向處理) 和 Row (針對列導向處理)。
強制執行查詢使用的掃描方法
為了提升查詢效能,Spanner 會為查詢選擇最佳掃描方法。建議您使用這個預設掃描方法。不過,在某些情況下,您可能會想強制執行特定類型的掃描方法。
強制執行批次導向掃描
您可以在表格層級和陳述式層級強制執行批次導向掃描作業。
如要在資料表層級強制執行以批次為導向的掃描方法,請在查詢中使用資料表提示:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
如要在陳述式層級強制執行以批次為導向的掃描方法,請在查詢中使用陳述式提示:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
停用自動掃描功能並強制執行以列為導向的掃描
雖然我們不建議停用 Spanner 設定的自動掃描方法,但您可以選擇停用該方法,並使用以列為導向的掃描方法來排解問題,例如診斷延遲。
如要停用自動掃描方法,並在資料表層級強制執行資料列處理作業,請在查詢中使用資料表提示:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
如要停用自動掃描方法,並在陳述式層級強制執行資料列處理作業,請在查詢中使用陳述式提示:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
最佳化查詢執行作業
除了最佳化掃描,您也可以在陳述式層級強制執行方法,藉此最佳化查詢執行作業。這項功能僅適用於部分運算子,且與掃描方法無關,後者僅供掃描運算子使用。
根據預設,大多數運算子會以以列為導向的方式執行,也就是一次處理一列資料。向量化運算子會以批次導向方法執行,有助於提升執行吞吐量和效能。這些運算子會一次處理一個區塊的資料。如果運算子需要處理多個資料列,以批次為導向的執行方法通常會更有效率。
執行方法與掃描方法
查詢執行方法與查詢掃描方法無關。您可以在查詢提示中設定其中一種或兩種方法,也可以不設定任何方法。
查詢執行方法是指查詢運算子處理中繼結果的方式,以及運算子彼此互動的方式;而掃描方法則是指掃描運算子與 Spanner 儲存層互動的方式。
強制執行查詢使用的執行方法
為提升查詢效能,Spanner 會根據各種推論法,為查詢選擇最佳執行方法。建議您使用這個預設執行方法。不過,在某些情況下,您可能會想強制執行特定類型的執行方法。
您可以在陳述式層級強制執行方法。EXECUTION_METHOD 是查詢提示,而非指令。最終,查詢最佳化工具會決定要為每個運算子使用哪種方法。
如要在陳述式層級強制執行批次導向方法,請在查詢中使用陳述式提示:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
雖然我們不建議停用 Spanner 設定的自動執行方法,但您可以選擇停用該方法,並使用以列為導向的執行方法來排除問題,例如診斷延遲。
如要停用自動執行方法,並在陳述式層級強制執行以列為導向的執行方法,請在查詢中使用陳述式提示:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
檢查已啟用的執行方法
並非所有 Spanner 運算子都支援以批次為導向和以列為導向的執行方法。針對每個運算子,查詢執行計畫視覺化工具會在迭代器資訊卡中顯示執行方法。如果執行方法是批次導向,則會顯示「批次」。如果是列向資料,則會顯示「列」。
如果查詢中的運算子使用不同的執行方法執行,執行方法轉接器 DataBlockToRowAdapter 和 RowToDataBlockAdapter 會顯示在運算子之間,以顯示執行方法的變更。
最佳化範圍索引鍵查詢
SQL 查詢的常見用途是根據一系列已知索引鍵,從 Spanner 讀取多個資料列。
下列最佳做法說明如何撰寫有效率的查詢,透過一系列索引鍵擷取資料:
若索引鍵是稀疏且不相鄰的,使用查詢參數與
UNNEST來建構查詢內容。例如,若您的索引鍵清單為
{1, 5, 1000},請依下列方式撰寫查詢:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
注意:
若索引鍵相鄰且在同一範圍內,請在
WHERE子句中指定索引鍵範圍的最高值與最低值。例如,若索引鍵清單為
{1,2,3,4,5},請依下列方式建構查詢內容:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
只有索引鍵範圍內的索引鍵相鄰時,這個查詢才會更有效率。換句話說,如果索引鍵清單為
{1, 5, 1000},因為產生的查詢會掃描 1 到 1000 之間的每個值,您就不需要如上方查詢一般,指定最高和最低值。
彙整作業最佳化
彙整作業可能會耗費大量資源,因為這類作業會大量增加查詢必須掃描的資料列數,導致查詢變得緩慢。除了使用您在其他關聯資料庫慣用的最佳化彙整查詢技巧之外,下方有一些使用 Spanner SQL 時,讓 JOIN 更有效率的最佳做法:
可能的話,利用主鍵將資料彙整於交錯的資料表中。例如:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
如結構定義與資料模型中所述,系統保證會將交錯資料表
Albums中的資料列實體儲存在與Singers中父項資料列的相同分割中。因此,彙整作業可以完全儲存在本機,而不需要跨網路傳送大量資料。如要強制排序彙整,請使用 join 指令。例如:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
join 指令
FORCE_JOIN_ORDER會告訴 Spanner 使用查詢中指定的彙整順序 (也就是Singers JOIN Albums,而非Albums JOIN Singers)。不論 Spanner 選擇何種順序,傳回的結果都是相同的。然而,若您發現 Spanner 在查詢計劃中變更彙整順序會導致不想要的結果,例如更大量的中繼資料或失去搜尋資料列的機會,您可以考慮使用此 join 指令。使用 join 指令選擇 join 實作方式。使用 SQL 查詢多個資料表時,Spanner 會自動使用可能有助提高查詢效率的彙整方法。不過,Google 建議您使用不同的彙整演算法進行測試。選擇適當的 join 演算法可改善延遲和/或記憶體耗用。此查詢示範使用 JOIN 指令搭配
JOIN_METHOD提示,選擇HASH JOIN的語法:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
如果您使用
HASH JOIN或APPLY JOIN,而且您JOIN的其中一方是高度選擇性的WHERE子句,請將產生最少資料列數的資料表當做 join 中FROM子句的第一個資料表。這個結構很有幫助,因為在HASH JOIN中,Spanner 一律會將左側資料表當做建構,右側資料表當做探查。同樣地,針對APPLY JOIN,Spanner 會將左手邊的資料表當做外部資料,右手邊的資料表當做內部資料。如要進一步瞭解這些彙整類型,請參閱 Hash 彙整和 套用彙整。針對對工作負載至關重要的查詢,請在 SQL 陳述式中指定效能最高的彙整方法和彙整順序,以便取得更一致的效能。
使用時間戳記預設值下推功能最佳化查詢
時戳判定式推送是 Spanner 中使用的查詢最佳化技術,可改善使用時戳和資料的查詢效率,並搭配以年齡為依據的分層儲存空間政策。啟用這項最佳化功能後,系統會盡早在查詢執行計畫中執行時間戳記資料欄的篩選作業。這樣一來,可以大幅減少所處理的資料量,並改善整體查詢效能。
透過時間戳記述詞推送,資料庫引擎會分析查詢並識別時間戳記篩選器。接著,系統會將這個篩選器「推送」至儲存層,這樣一來,系統只會從 SSD 讀取符合時間戳記條件的相關資料。這樣一來,處理和傳輸的資料量就會降到最低,進而加快查詢執行速度。
如要將查詢最佳化,只存取 SSD 上儲存的資料,必須符合下列條件:
- 查詢必須啟用時間戳記述詞推送功能。詳情請參閱「GoogleSQL 陳述式提示」和「PostgreSQL 陳述式提示」
- 查詢必須使用以年齡為基礎的限制,且該限制必須等於或小於資料傾印政策中指定的年齡 (使用
CREATE LOCALITY GROUP或ALTER LOCALITY GROUPDDL 陳述式中的ssd_to_hdd_spill_timespan選項設定)。詳情請參閱 GoogleSQLLOCALITY GROUP陳述式和 PostgreSQLLOCALITY GROUP陳述式。 在查詢中篩選的資料欄必須是包含修訂時間戳記的時間戳記欄。如要進一步瞭解如何建立修訂時間戳記資料欄,請參閱「在 GoogleSQL 中設定修訂時間戳記」和「在 PostgreSQL 中設定修訂時間戳記」。這些資料欄必須與時間戳記欄一併更新,且位於具有年齡層級儲存空間政策的相同區域群組中。
如果針對特定資料列,部分查詢的資料欄位於 SSD 上,而部分資料欄位於 HDD 上 (因為資料欄會在不同時間更新,並在不同時間過期至 HDD),則使用提示時,查詢的效能可能會變差。這是因為查詢必須填入來自不同儲存層的資料。使用提示後,Spanner 會根據每個儲存格的提交時間戳記,在個別儲存格層級 (列和欄精細程度層級) 淘汰資料,導致查詢速度變慢。為避免發生這個問題,請務必在同一個交易中,定期更新使用這項最佳化技巧查詢的所有資料欄,讓所有資料欄共用相同的提交時間戳記,並從最佳化中受益。
如要在陳述式層級啟用時間戳記述詞推送,請在查詢中使用陳述式提示。例如:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
避免在讀寫交易內執行大量讀取作業
讀寫交易允許在修訂呼叫前,進行零個或多個序列讀取作業或 SQL 查詢作業,而且可包含一組變異。為了維持資料的一致性,Spanner 會在寫入和讀取資料表及索引時取得鎖定。如要進一步瞭解鎖定功能,請參閱「讀取和寫入作業的生命週期」。
基於鎖定在 Spanner 中的運作方式,若您執行讀取作業或 SQL 查詢時需要讀取大量資料列 (例如 SELECT * FROM Singers),在您修訂或取消交易之前,任何其他交易都無法寫入您已讀取的資料列。
此外,由於交易正在處理大量資料列,與讀取較小資料列範圍的交易相比 (例如 SELECT LastName FROM Singers WHERE SingerId = 7),這項作業可能會耗費更長的時間,造成問題惡化並降低系統的總處理量。
因此,您應盡量避免在交易中進行大量讀取作業 (例如:完整資料表掃描或大量彙整作業),除非您願意接受低寫入總處理量。
在某些情況下,以下模式可產生更好的結果:
- 在唯讀交易中執行大量讀取作業 由於唯讀交易不會使用鎖定,因此允許更高的匯總總處理量。
- 選用步驟:對剛才讀取的資料進行任何必要的處理。
- 開始讀寫交易。
- 請確認關鍵資料列的值在您執行步驟 1 的唯讀交易後就沒有再變更。
- 如果資料列有變更,請復原交易,然後從步驟 1 重新開始。
- 如果沒有問題,請修訂變異。
確保您不會在讀寫交易中進行大量讀取的方法之一,是查看查詢作業所產生的執行計劃。
使用 ORDER BY 確保 SQL 結果會依預期排序
如果您希望 SELECT 查詢的結果以特定順序呈現,請明確加入 ORDER BY 子句。例如:若要依主鍵順序列出所有歌手,請使用此查詢:
SELECT * FROM Singers
ORDER BY SingerId;
只有在查詢中出現 ORDER BY 子句時,Spanner 才能保證結果的順序。換句話說,請看下方沒有 ORDER
BY 的查詢:
SELECT * FROM Singers;
Spanner 不保證此查詢的結果會依主鍵順序排列。再者,結果的排序可隨時變更,也不保證每次叫用的結果都會有一樣的順序。如果查詢含有 ORDER BY 子句,且 Spanner 使用提供必要順序的索引,Spanner 就不會明確排序資料。因此,請放心加入這個子句,不會對效能造成影響。您可以查看查詢計畫,確認執行作業是否包含明確的排序作業。
使用 STARTS_WITH 而非 LIKE
由於 Spanner 會到執行時間才評估參數化 LIKE 模式,因此必須先讀取所有資料列,並使用 LIKE 陳述式進行評估,才能篩選出不相符的資料列。
如果 LIKE 模式為 foo% 格式 (例如開頭為固定字串,結尾為單一萬用字元百分比),且資料欄已編入索引,請使用 STARTS_WITH 而非 LIKE。這個選項可讓 Spanner 更有效地最佳化查詢執行計畫。
不建議使用:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
建議做法:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
使用修訂時間戳記
如果應用程式需要查詢在特定時間之後寫入的資料,請在相關資料表中新增提交時間戳記資料欄。提交時間戳記可啟用 Spanner 最佳化功能,藉此減少查詢的 I/O,因為查詢的 WHERE 子句會將結果限制在比特定時間更近期寫入的資料列。
如要進一步瞭解這項最佳化功能,請參閱「使用 GoogleSQL 方言資料庫」或「使用 PostgreSQL 方言資料庫」。