El visualizador de planes de consultas te permite entender rápidamente la estructura del plan de consultas que ha elegido Spanner para evaluar una consulta. En esta guía se describe cómo puedes usar un plan de consulta para entender la ejecución de tus consultas.
Antes de empezar
.Para familiarizarte con las partes de la interfaz de usuario de la consola Google Cloud que se mencionan en esta guía, consulta lo siguiente:
Ejecutar una consulta en la consola de Google Cloud
- Ve a la página Instancias de Spanner en la Google Cloud consola.
-
Selecciona el nombre de la instancia que contiene la base de datos que quieres consultar.
Google Cloud La consola muestra la página Información general de la instancia.
-
Selecciona el nombre de la base de datos que quieras consultar.
Google Cloud muestra la página Información general de la base de datos.
-
En el menú lateral, haz clic en Spanner Studio.
Google Cloud muestra la página Spanner Studio de la base de datos.
- Introduce la consulta SQL en el panel del editor.
-
Haz clic en Ejecutar.
Spanner ejecuta la consulta.
- Haz clic en la pestaña Explicación para ver la visualización del plan de consulta.
Visita guiada por el editor de consultas
La página de Spanner Studio proporciona pestañas de consultas que te permiten escribir o pegar consultas SQL e instrucciones DML, ejecutarlas en tu base de datos y ver sus resultados y planes de ejecución de consultas. Los componentes clave de la página de Spanner Studio están numerados en la siguiente captura de pantalla.
- La barra de pestañas muestra las pestañas de consulta que tienes abiertas. Para crear una pestaña, haz clic en Nueva pestaña.
La barra de pestañas también proporciona una lista de plantillas de consulta que puedes usar para pegar consultas que proporcionen estadísticas sobre consultas de bases de datos, transacciones, lecturas y más, tal como se describe en Descripción general de las herramientas de introspección.
- La barra de comandos del editor ofrece estas opciones:
- El comando Ejecutar ejecuta las instrucciones introducidas en el panel de edición y muestra los resultados de la consulta en la pestaña Resultados y los planes de ejecución de la consulta en la pestaña Explicación. Cambia el comportamiento predeterminado mediante el menú desplegable para obtener Solo resultados o Solo explicación.
Si resaltas algo en el editor, el comando Ejecutar cambia a Ejecutar selección, lo que te permite ejecutar solo lo que has seleccionado.
- El comando Borrar consulta elimina todo el texto del editor y borra las subpestañas Resultados y Explicación.
- El comando Formatear consulta da formato a las instrucciones del editor para que sean más fáciles de leer.
- El comando Combinaciones de teclas muestra el conjunto de combinaciones de teclas que puedes usar en el editor.
- El enlace Ayuda con las consultas de SQL abre una pestaña del navegador con documentación sobre la sintaxis de las consultas de SQL.
Las consultas se validan automáticamente cada vez que se actualizan en el editor. Si las instrucciones son válidas, en la barra de comandos del editor se mostrará una marca de verificación de confirmación y el mensaje Válido. Si hay algún problema, se mostrará un mensaje de error con los detalles.
- El comando Ejecutar ejecuta las instrucciones introducidas en el panel de edición y muestra los resultados de la consulta en la pestaña Resultados y los planes de ejecución de la consulta en la pestaña Explicación. Cambia el comportamiento predeterminado mediante el menú desplegable para obtener Solo resultados o Solo explicación.
- En el editor, puedes introducir consultas SQL e instrucciones DML.
Se identifican con colores y los números de línea se añaden automáticamente a las
instrucciones de varias líneas.
Si introduces más de una instrucción en el editor, debes usar un punto y coma de terminación después de cada instrucción, excepto la última.
- El panel inferior de una pestaña de consulta tiene tres subpestañas:
- En la subpestaña Esquema se muestran las tablas de la base de datos y sus esquemas. Úsala como referencia rápida al redactar declaraciones en el editor.
- La subpestaña Resultados muestra los resultados cuando ejecutas las
instrucciones en el editor. En el caso de las consultas, se muestra una tabla de resultados y, en el de las instrucciones DML, como
INSERTy >UPDATE, se muestra un mensaje sobre el número de filas afectadas. - La subpestaña Explicación muestra gráficos visuales de los planes de consulta creados al ejecutar las instrucciones en el editor.
- Las subpestañas Resultados y Explicación incluyen un selector de instrucciones que puedes usar para elegir los resultados o el plan de consulta de la instrucción que quieras ver.
Ver planes de consulta muestreados
- Ve a la página Instancias de Spanner en la Google Cloud consola.
-
Haz clic en el nombre de la instancia con las consultas que quieras investigar.
Google Cloud La consola muestra la página Información general de la instancia.
-
En el menú Navegación, vaya al encabezado Observabilidad y haga clic en Estadísticas de consultas.
Google Cloud muestra la página Estadísticas de consultas de la instancia.
-
En el menú desplegable Base de datos, seleccione la base de datos con las consultas que quiera investigar.
La consolaGoogle Cloud muestra la información de carga de consultas de la base de datos. En la tabla de consultas y etiquetas principales se muestra la lista de las consultas y etiquetas de solicitud principales ordenadas por uso de CPU.
-
Busca la consulta con un uso elevado de la CPU de la que quieras ver planes de consulta muestreados. Haz clic en el valor FPRINT de esa consulta.
En la página Detalles de la consulta se muestra un gráfico de Ejemplos de planes de consulta de su consulta a lo largo del tiempo. Puedes alejar la imagen hasta siete días antes de la hora actual. Nota: Los planes de consulta no se admiten en las consultas con partitionTokens obtenidos de la API PartitionQuery ni en las consultas de DML particionado.
-
Haz clic en uno de los puntos del gráfico para ver un plan de consultas anterior y visualizar los pasos que se han seguido durante la ejecución de la consulta. También puedes hacer clic en cualquier operador para ver información ampliada sobre él.
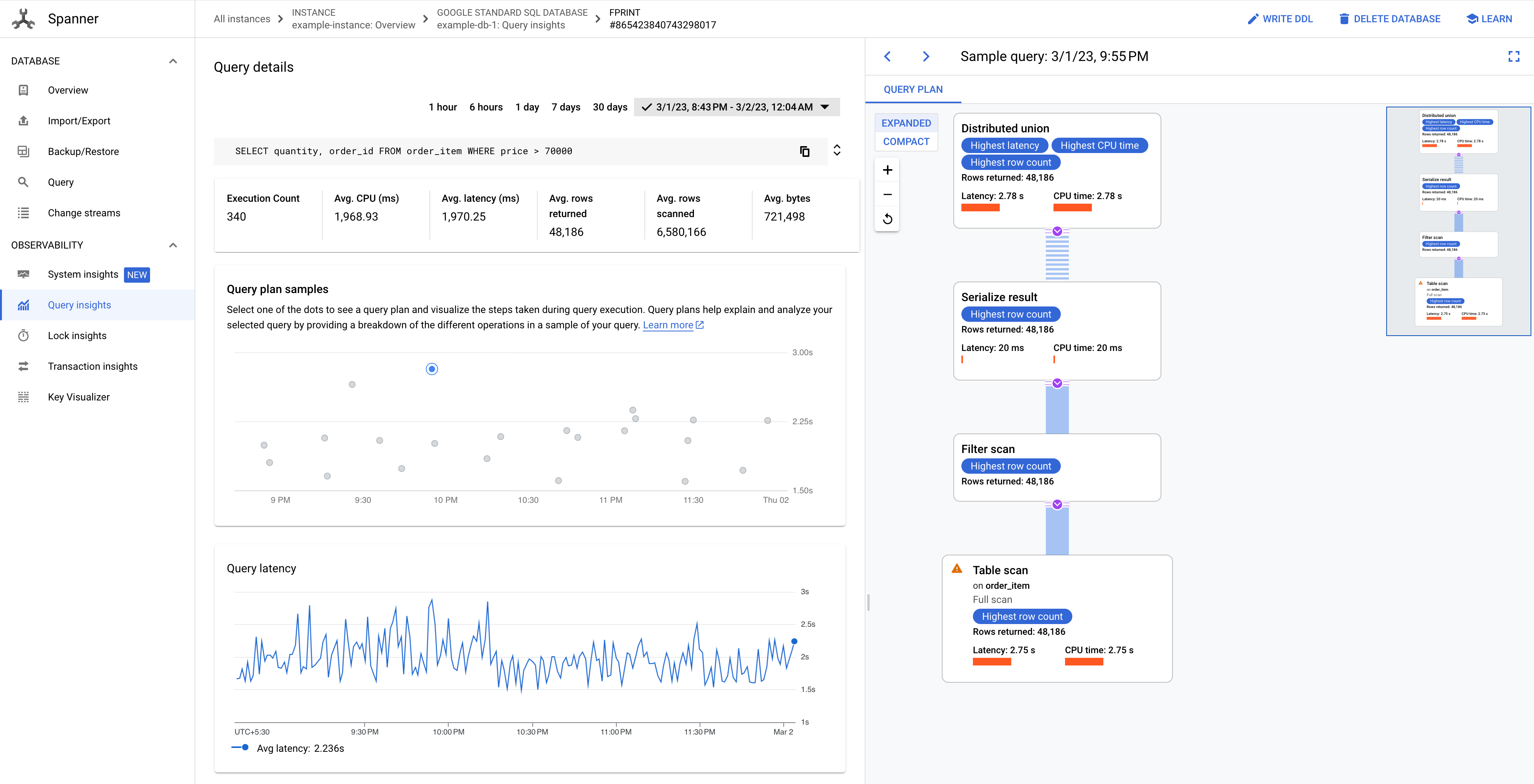
Imagen 8. Gráfico de ejemplos de planes de consultas.
En algunos casos, puede que quieras ver planes de consultas muestreados y comparar el rendimiento de una consulta a lo largo del tiempo. En el caso de las consultas que consumen más CPU, Spanner conserva los planes de consulta muestreados durante 30 días en la página Estadísticas de consultas de la consola de Google Cloud . Para ver los planes de consulta muestreados, siga estos pasos:
Hacer un recorrido por el visualizador de planes de consultas
Los componentes clave del visualizador se han anotado en la siguiente captura de pantalla y se describen con más detalle. Después de ejecutar una consulta en una pestaña de consulta, selecciona la pestaña EXPLANATION (EXPLICACIÓN) situada debajo del editor de consultas para abrir el visualizador del plan de ejecución de la consulta.
El flujo de datos del siguiente diagrama es de abajo arriba, es decir, todas las tablas e índices se encuentran en la parte inferior del diagrama y el resultado final está en la parte superior.
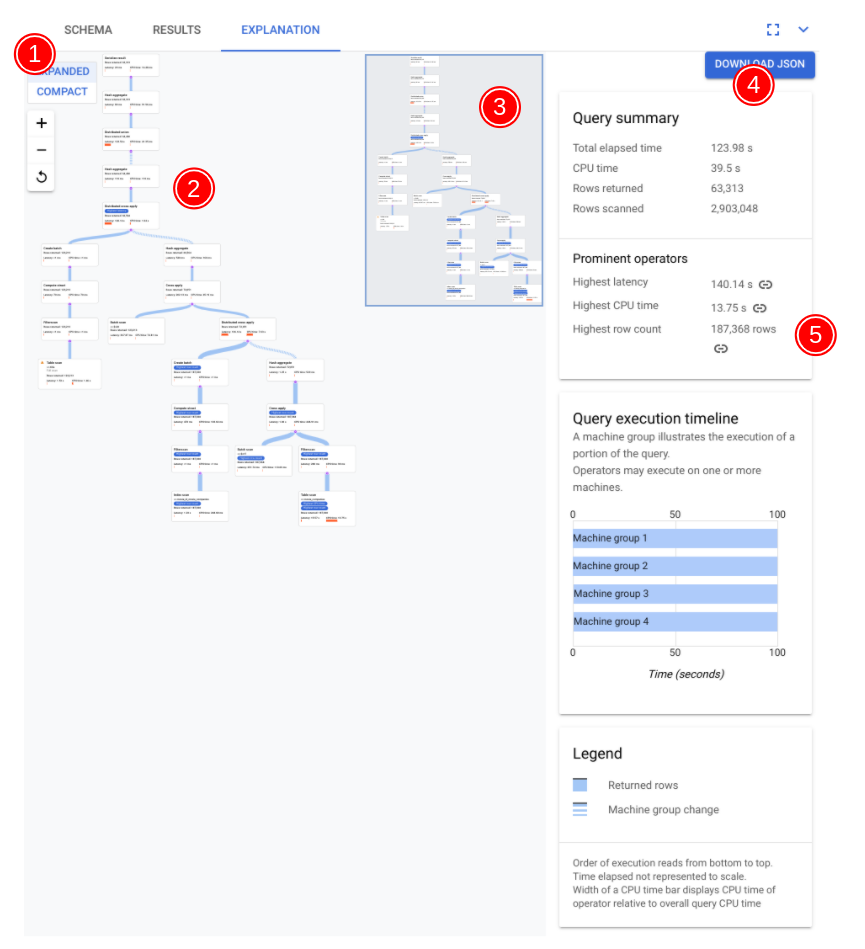
- La visualización de tu plan puede ser grande, en función de la consulta que hayas ejecutado. Para ocultar y mostrar los detalles, activa o desactiva el selector de vista EXPANDIDA/COMPACTA. Puedes personalizar la parte del plan que quieres ver en cada momento con el control de zoom.
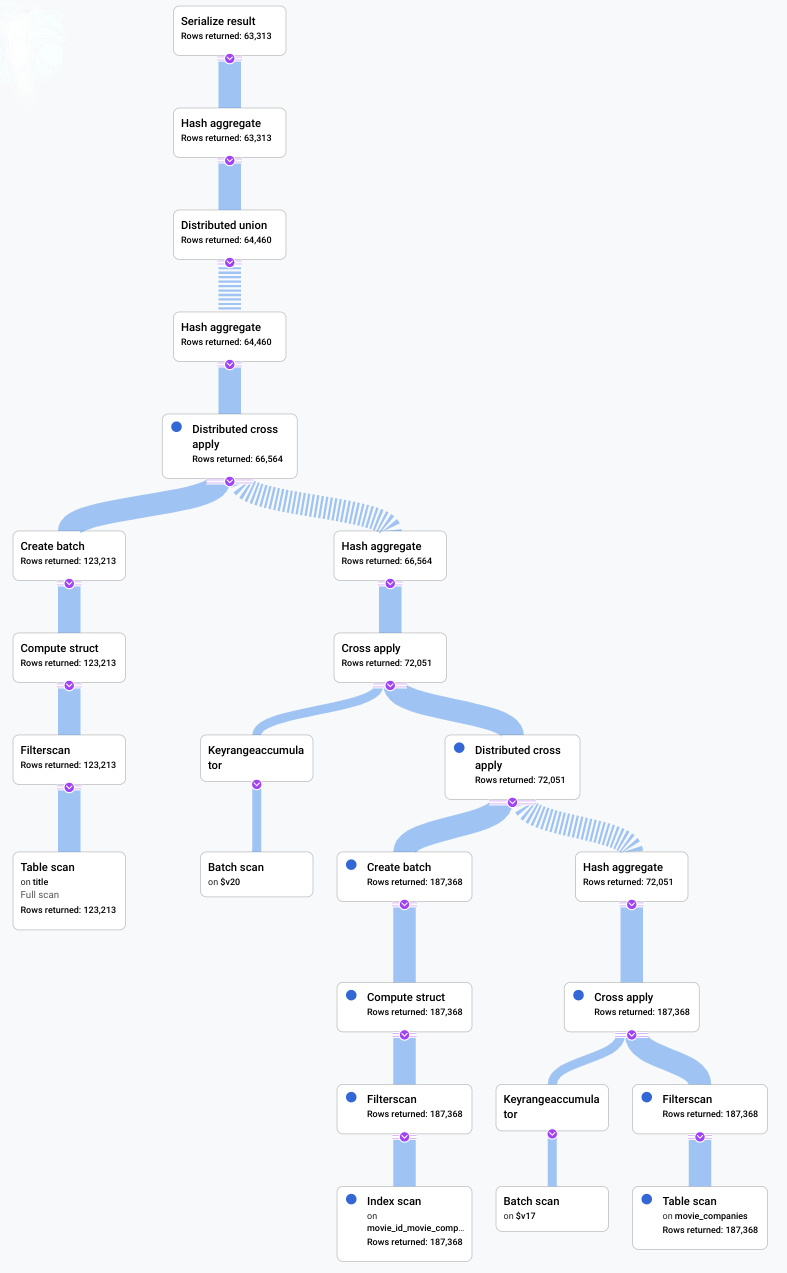
- El álgebra que explica cómo ejecuta Spanner la consulta se representa como un gráfico acíclico, donde cada nodo corresponde a un iterador que consume filas de sus entradas y produce filas para su elemento superior. En la imagen 9 se muestra un plan de ejemplo. Haz clic en el diagrama
para ver una vista ampliada de algunos de los detalles del plan.
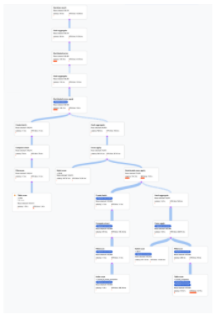
Imagen 9. Plan visual de muestra (haz clic para ampliar). 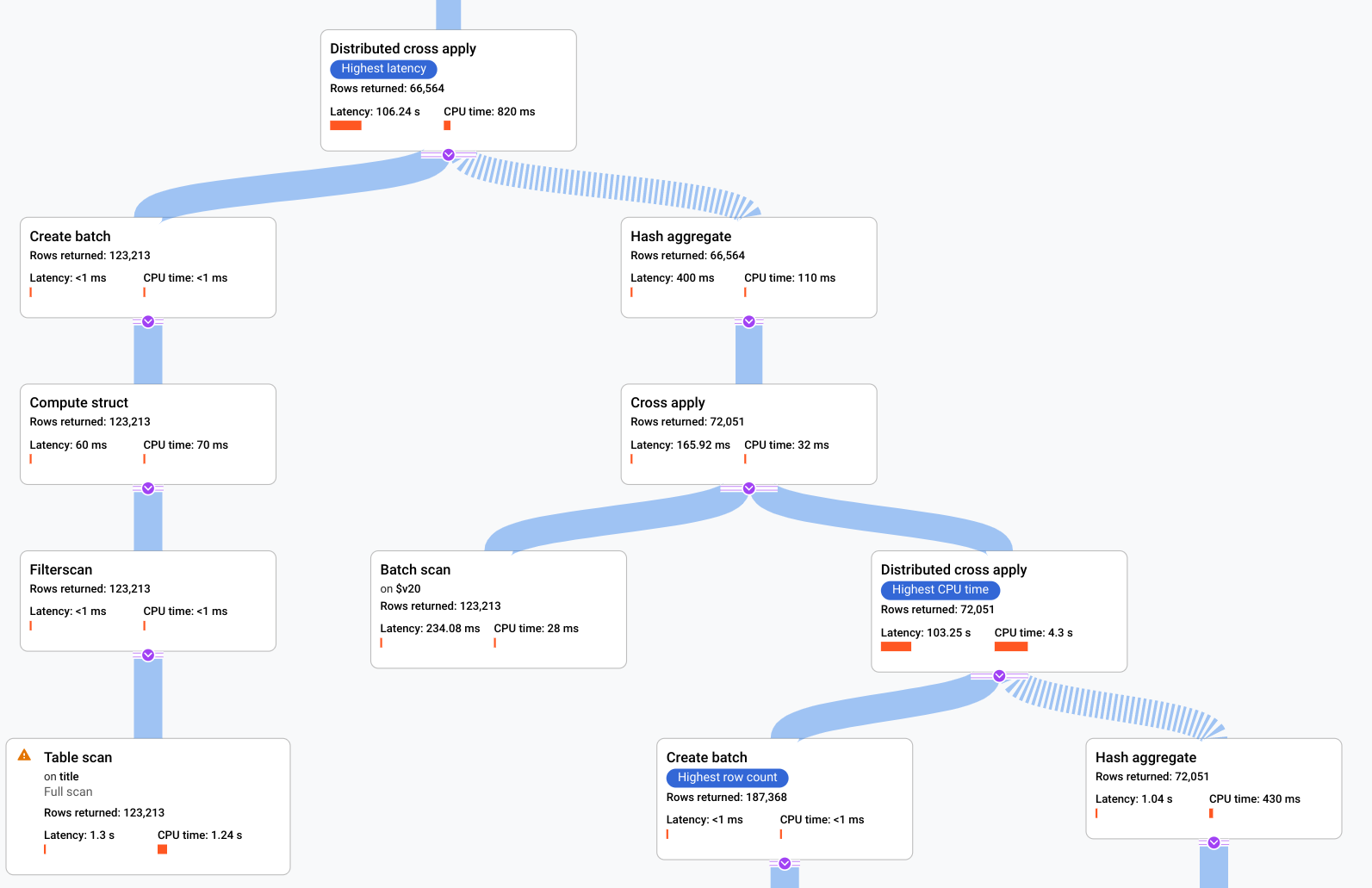
Cada nodo, o tarjeta, del gráfico representa un iterador y contiene la siguiente información:
- Nombre del iterador. Un iterador consume filas de su entrada y genera filas.
- Estadísticas de tiempo de ejecución que indican cuántas filas se han devuelto, cuál ha sido la latencia y cuánta CPU se ha consumido.
- Proporcionamos las siguientes pistas visuales para ayudarte a identificar posibles problemas en el plan de ejecución de la consulta.
- Las barras rojas de un nodo son indicadores visuales del porcentaje de latencia o tiempo de CPU de este iterador en comparación con el total de la consulta.
- El grosor de las líneas que conectan cada nodo representa el número de filas. Cuanto más gruesa sea la línea, mayor será el número de filas que se pasen al siguiente nodo. El número real de filas se muestra en cada tarjeta y cuando coloca el puntero sobre un conector.
- Se muestra un triángulo de advertencia en un nodo en el que se ha realizado un análisis completo de la tabla. En el panel de información se incluyen más detalles, como recomendaciones para añadir un índice o revisar la consulta o el esquema de otras formas, si es posible, para evitar un análisis completo.
- Selecciona una tarjeta del plan para ver los detalles en el panel de información de la derecha (5).
- El minimapa del plan de ejecución muestra una vista alejada del plan completo y es útil para determinar la forma general del plan de ejecución y para desplazarse rápidamente a diferentes partes del plan. Arrastra directamente en el minimapa o haz clic en el lugar que quieras enfocar para ir a otra parte del plan visual.
Selecciona DESCARGAR JSON para descargar una versión JSON del plan de ejecución, que es útil para solucionar problemas. También puedes compartirlo cuando te pongas en contacto con el equipo de Spanner para obtener asistencia. Al guardar el JSON, no se guarda el resultado de la consulta.
Para descargar y guardar una versión JSON del plan de ejecución para visualizarla más adelante, haz lo siguiente:
- En Spanner Studio, ejecuta una consulta.
- Selecciona la pestaña Explicación.
- Haz clic en DESCARGAR JSON para descargar la versión JSON del plan de ejecución.
- Guarda y copia el contenido del archivo JSON.
- Abre una nueva pestaña del editor de consultas.
- En la pestaña del editor, introduce lo siguiente:
PROTO: CONTENT_OF_JSON
- Haz clic en Ejecutar.
- Selecciona la pestaña Explicación situada debajo del editor de consultas para ver una representación visual del plan de ejecución descargado.
- El panel de información muestra información contextual detallada sobre el nodo seleccionado en el diagrama del plan de consultas. La información se organiza en las siguientes categorías.
- La información del iterador proporciona detalles y estadísticas de tiempo de ejecución de la tarjeta de iterador que has seleccionado en el gráfico.
- En Resumen de la consulta se proporcionan detalles sobre el número de filas devueltas y el tiempo que se ha tardado en ejecutar la consulta. Los operadores destacados son aquellos que muestran una latencia significativa, consumen una cantidad de CPU significativa en comparación con otros operadores y devuelven un número significativo de filas de datos.
- La cronología de ejecución de la consulta es un gráfico cronológico que muestra cuánto tiempo ha estado ejecutando cada grupo de máquinas su parte de la consulta. Es posible que un grupo de máquinas no se ejecute durante toda la duración de la consulta. También es posible que un grupo de máquinas se haya ejecutado varias veces durante la ejecución de la consulta, pero la cronología solo representa el inicio de la primera vez que se ejecutó y el final de la última vez que se ejecutó.
Ajustar una consulta que tenga un rendimiento bajo
Supongamos que tu empresa gestiona una base de datos de películas online que contiene información sobre películas, como el reparto, las productoras, los detalles de las películas, etc. El servicio se ejecuta en Spanner, pero últimamente ha tenido algunos problemas de rendimiento.
Como desarrollador principal del servicio, se te pide que investigues estos problemas de rendimiento, ya que están provocando malas valoraciones del servicio. Abre la Google Cloud consola, ve a tu instancia de base de datos y, a continuación, abre el editor de consultas. Introduce la siguiente consulta en el editor y ejecútala.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
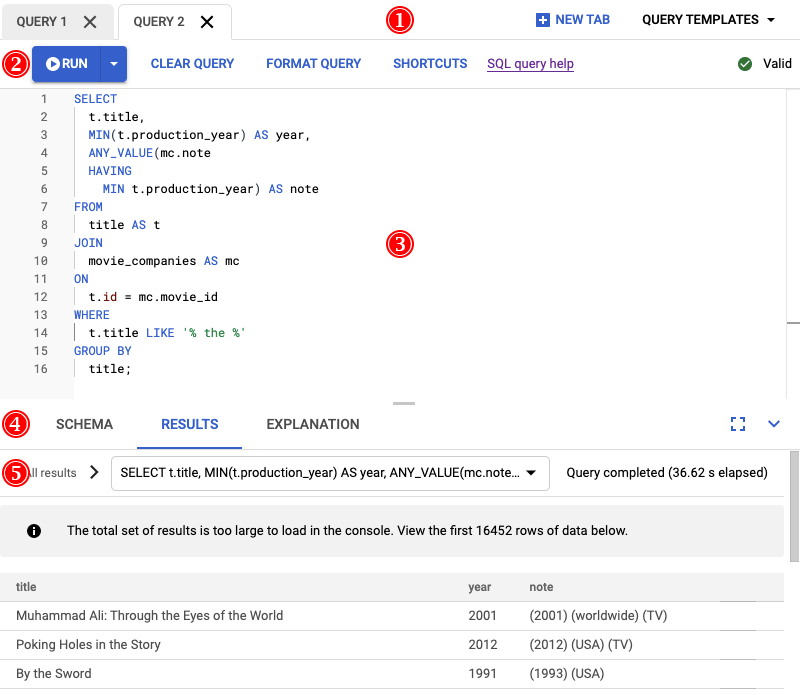
El resultado de ejecutar esta consulta se muestra en la siguiente captura de pantalla. Hemos dado formato a la consulta en el editor seleccionando APLICAR FORMATO A LA CONSULTA. También hay una nota en la parte superior derecha de la pantalla que indica que la consulta es válida.
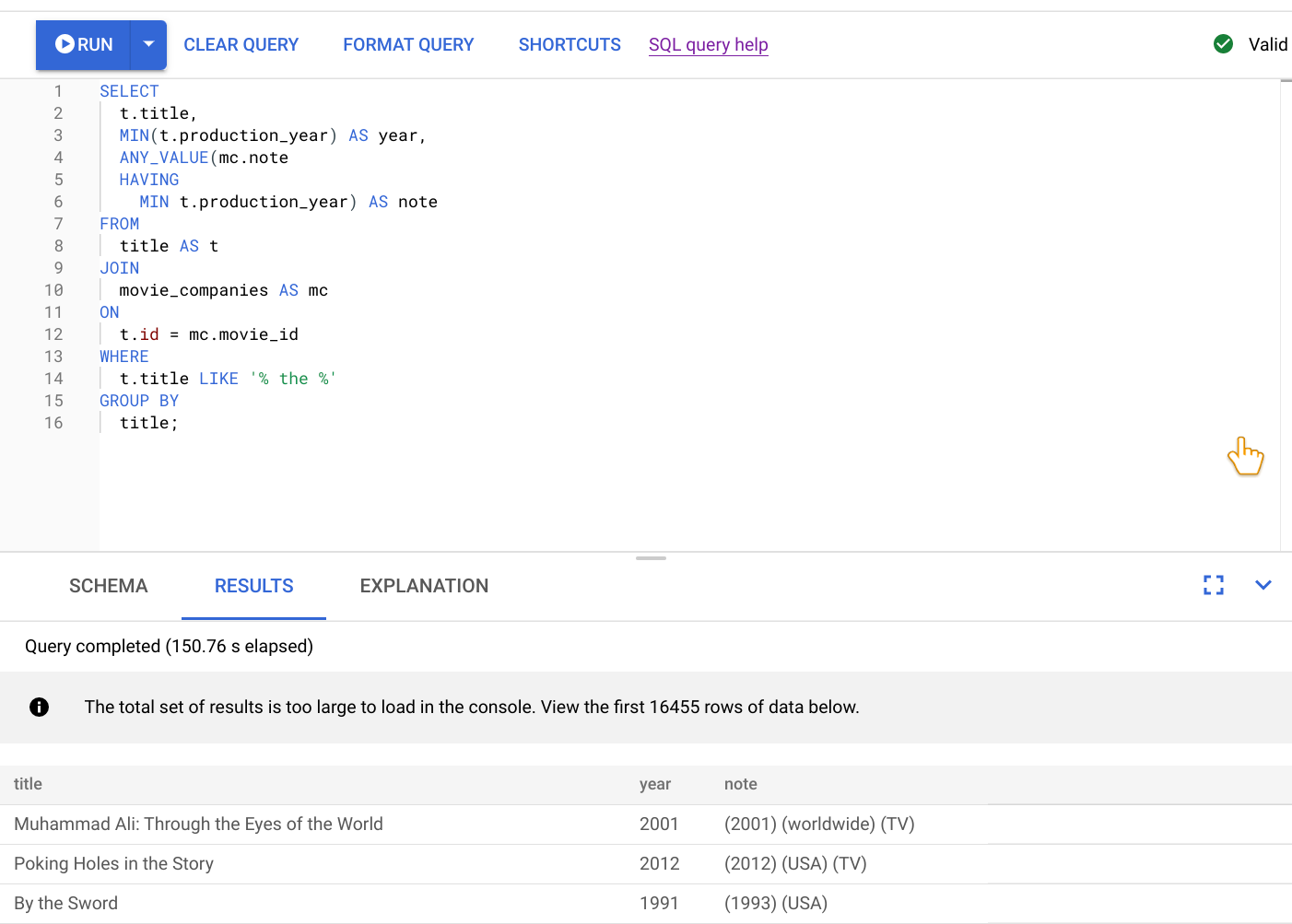
La pestaña RESULTADOS, situada debajo del editor de consultas, muestra que la consulta se ha completado en poco más de dos minutos. Decides analizar la consulta en detalle para ver si es eficiente.
Analizar consultas lentas con el visualizador de planes de consultas
En este punto, sabemos que la consulta del paso anterior tarda más de dos minutos, pero no sabemos si es lo más eficiente posible y, por lo tanto, si esta duración es la esperada.
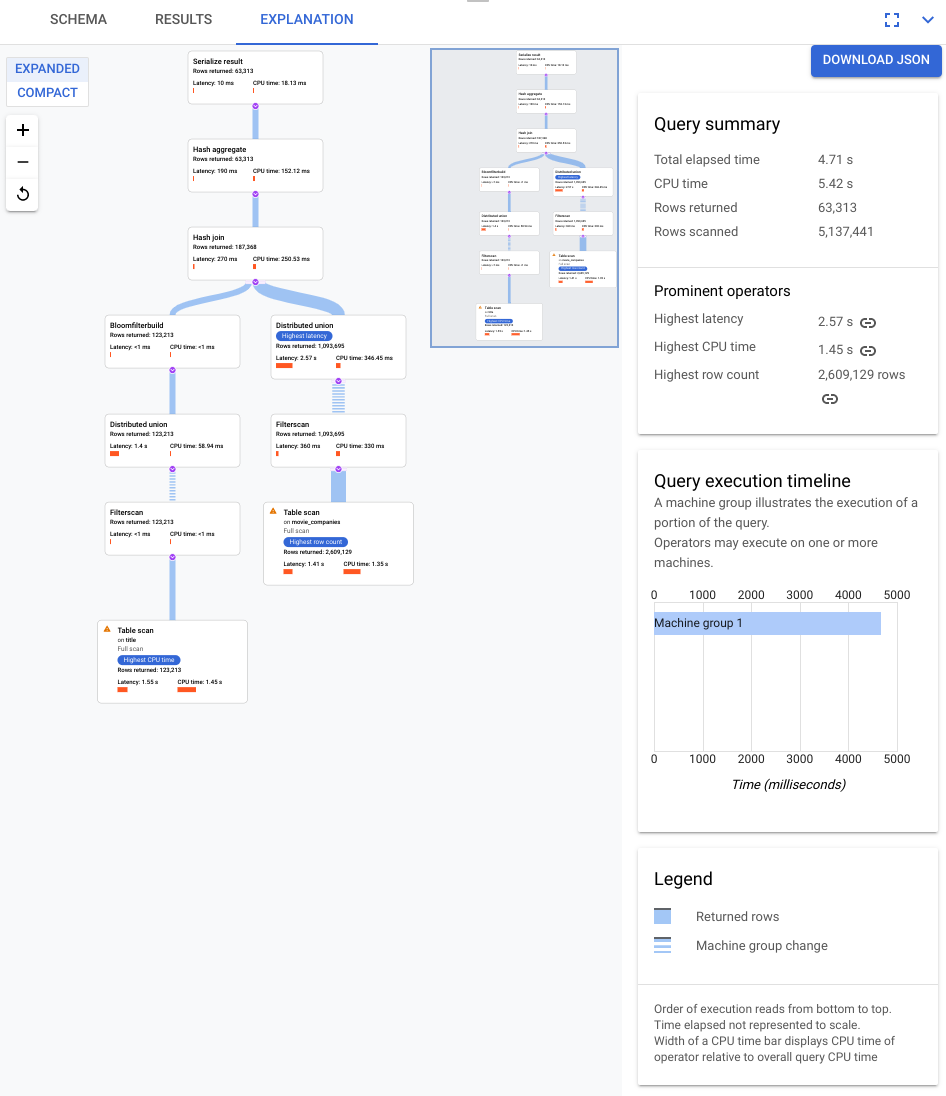
Selecciona la pestaña EXPLANATION (EXPLICACIÓN) situada justo debajo del editor de consultas para ver una representación visual del plan de ejecución que ha creado Spanner para ejecutar la consulta y devolver los resultados.
El plan que se muestra en la siguiente captura de pantalla es relativamente grande, pero, incluso con este nivel de zoom, puedes hacer las siguientes observaciones.
Según el Resumen de la consulta del panel de información de la derecha, se han analizado casi 3 millones de filas y se han devuelto menos de 64.000.
También podemos ver en el panel Cronología de ejecución de la consulta que en la consulta se han utilizado 4 grupos de máquinas. Un grupo de máquinas se encarga de ejecutar una parte de la consulta. Los operadores pueden realizar acciones en una o varias máquinas. Si seleccionas un grupo de máquinas en la cronología, se resaltará en el plan visual la parte de la consulta que se ha ejecutado en ese grupo.
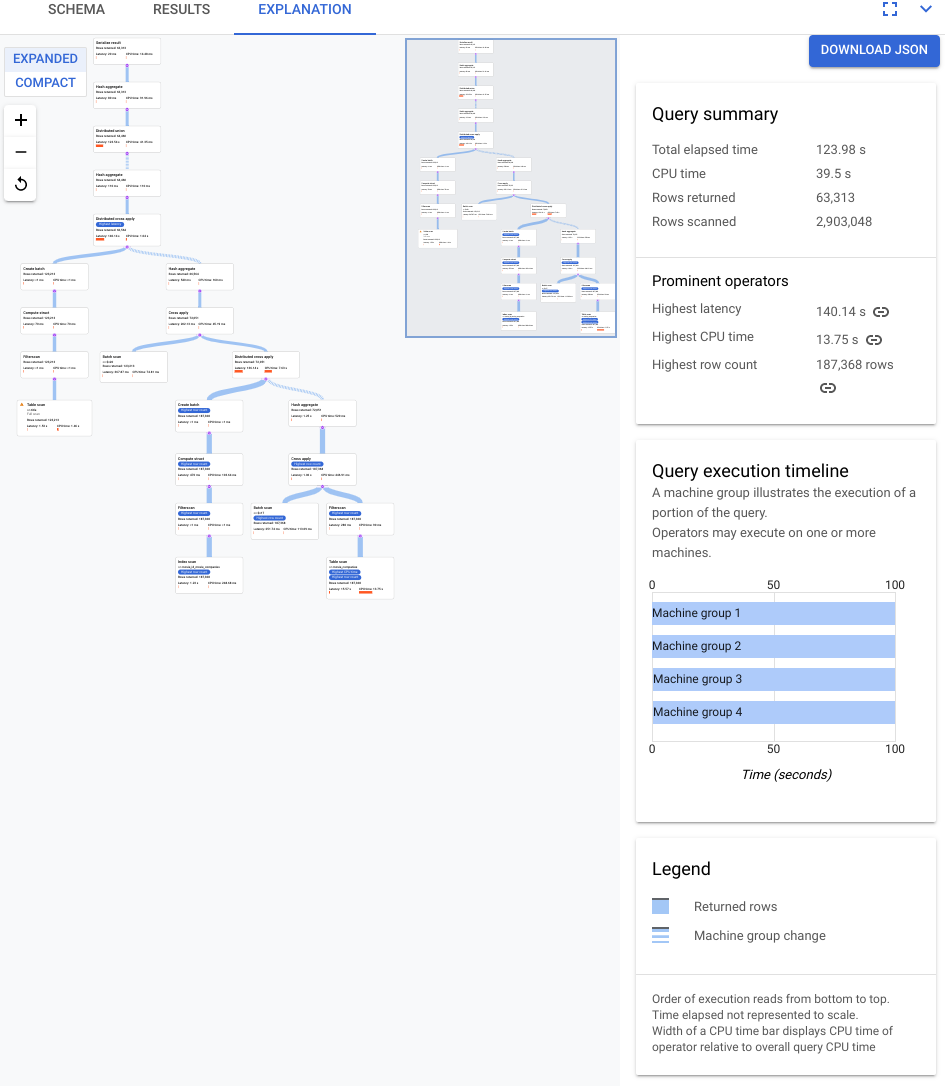
Debido a estos factores, decides que se puede mejorar el rendimiento cambiando la combinación de una combinación de aplicación, que Spanner eligió de forma predeterminada, a una combinación hash.
Mejorar la consulta
Para mejorar el rendimiento de la consulta, utiliza una sugerencia de unión para cambiar el método de unión a una unión hash. Esta implementación de la combinación ejecuta un procesamiento basado en conjuntos.
Esta es la consulta actualizada:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
En la siguiente captura de pantalla se muestra la consulta actualizada. Como se muestra en la captura de pantalla, la consulta se ha completado en menos de 5 segundos, lo que supone una mejora significativa con respecto a los 120 segundos que tardaba antes de este cambio.
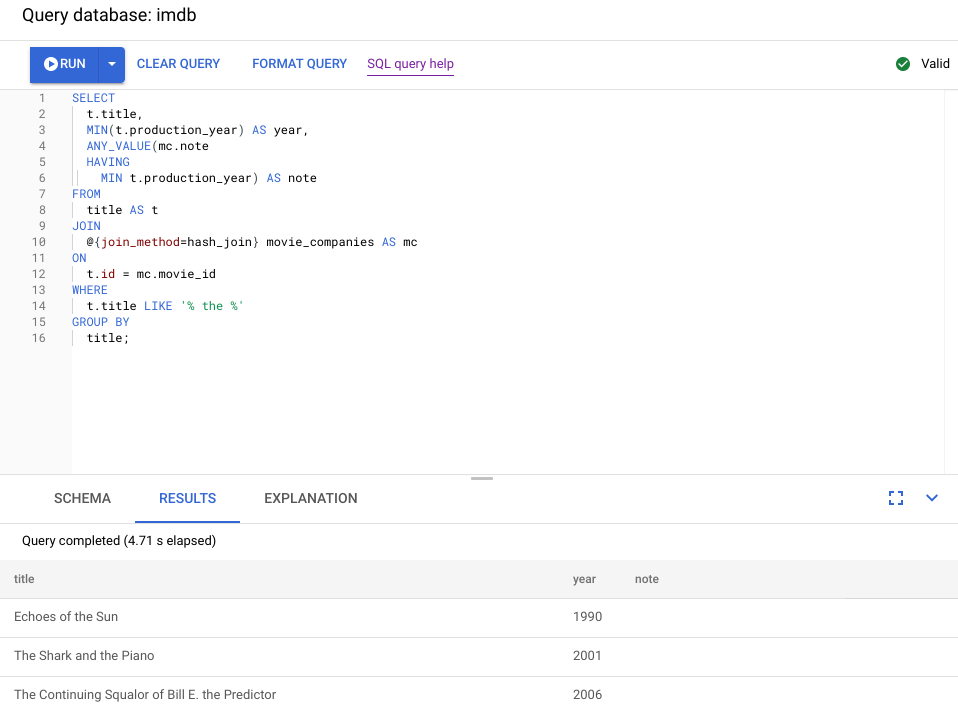
Examina el nuevo plan visual, que se muestra en el siguiente diagrama, para ver qué nos dice sobre esta mejora.
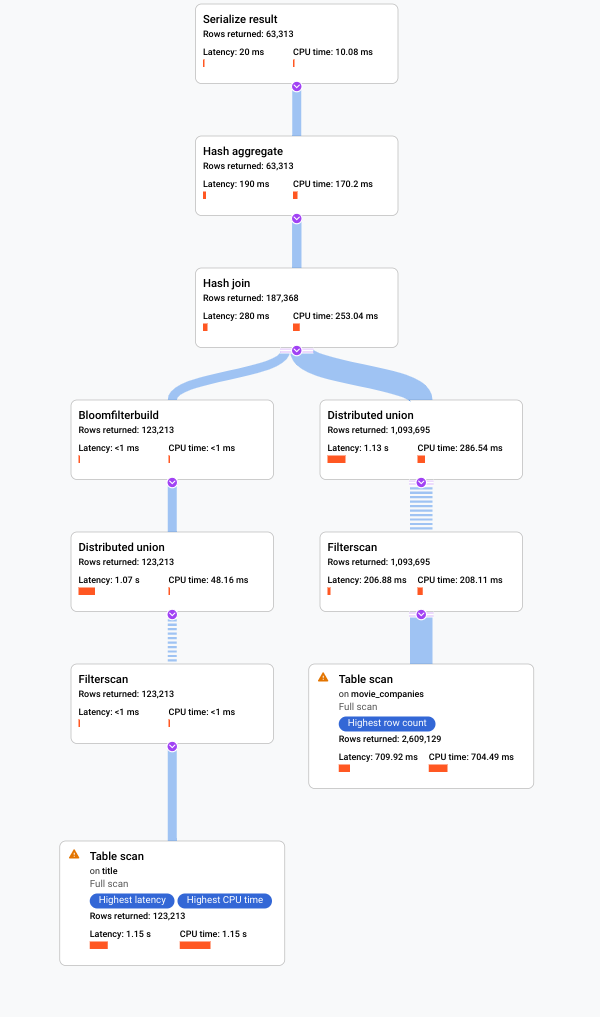
Inmediatamente, notarás algunas diferencias:
Solo se ha incluido un grupo de máquinas en la ejecución de esta consulta.
El número de agregaciones se ha reducido drásticamente.
Conclusión
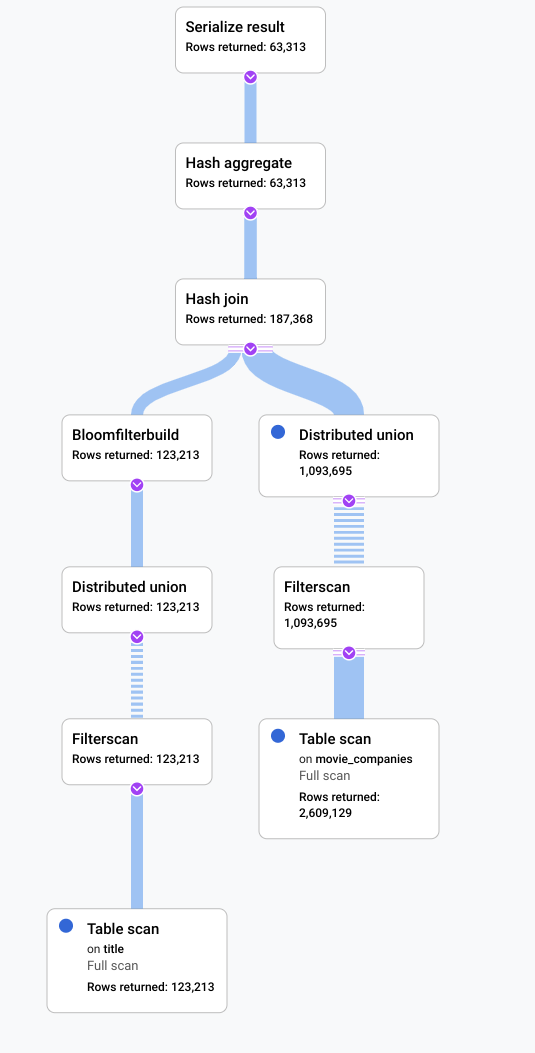
En este caso, hemos ejecutado una consulta lenta y hemos analizado su plan visual para buscar ineficiencias. A continuación, se muestra un resumen de las consultas y los planes antes y después de que se hayan realizado los cambios. En cada pestaña se muestra la consulta que se ha ejecutado y una vista compacta de la visualización del plan de ejecución de la consulta completa.
Antes
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Después
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Un indicador de que se podía mejorar algo en este caso era que una gran proporción de las filas de la tabla title cumplían el filtro LIKE
'% the %'. Buscar en otra tabla con tantas filas probablemente sea caro. Al cambiar nuestra implementación de la unión a una unión hash, el rendimiento mejoró significativamente.
Siguientes pasos
Para consultar la referencia completa del plan de consulta, consulte Planes de ejecución de consultas.
Para consultar la referencia completa de los operadores, consulta Operadores de ejecución de consultas.