Spanner 데이터베이스에서 Spanner는 각 테이블의 기본 키에 대한 색인을 자동으로 생성합니다. 예를 들어 Singers의 기본 키는 자동으로 색인이 생성되므로 색인 생성을 위한 별도의 작업이 필요하지 않습니다.
다른 열에 대해 보조 색인을 만들 수도 있습니다. 열에 보조 색인을 추가하면 해당 열의 데이터를 더 효율적으로 조회할 수 있습니다. 예를 들어 제목으로 앨범을 빠르게 조회해야 할 경우 Spanner가 전체 테이블을 스캔할 필요가 없도록 AlbumTitle에 보조 색인을 만들어야 합니다.
이전 예시에서 조회가 읽기-쓰기 트랜잭션 내에서 수행되면 보다 효율적인 조회를 통해 전체 테이블 잠금을 보유하지 않고 AlbumTitle 조회 범위 외부에 있는 행의 테이블에 삽입과 업데이트를 동시에 실행할 수 있습니다.
조회 관련 이점 외에도 보조 색인은 Spanner의 스캔 효율을 높여서 전체 테이블 스캔 대신 색인 스캔을 실행할 수 있게 해줍니다.
Spanner는 각 보조 색인에 다음 데이터를 저장합니다.
- 기본 테이블의 모든 키 열
- 색인에 포함된 모든 열
- 색인 정의의 선택적
STORING절(GoogleSQL 언어 데이터베이스) 또는INCLUDE절(PostgreSQL 언어 데이터베이스)에 지정된 모든 열
시간이 경과하면 Spanner는 테이블을 분석하여 보조 색인이 적절한 쿼리에 사용되는지 확인합니다.
보조 색인 추가
테이블을 만들 때 보조 색인을 추가하는 것이 가장 효율적입니다. 테이블과 테이블 색인을 동시에 만들려면 새 테이블과 새 색인에 대한 DDL 문을 Spanner에 단일 요청으로 전송합니다.
Spanner에서는 데이터베이스에서 트래픽이 계속 처리되는 동안 기존 테이블에 새로운 보조 색인을 추가할 수도 있습니다. Spanner에서 다른 스키마 변경 작업을 수행할 때와 마찬가지로 기존 데이터베이스에 색인을 추가할 때도 데이터베이스를 오프라인으로 전환할 필요가 없으며 전체 열 또는 테이블이 잠기지도 않습니다.
기존 테이블에 새 색인이 추가될 때마다 Spanner가 자동으로 색인 백필 또는 채우기를 수행하여 색인이 생성되는 데이터의 최신 뷰를 반영합니다. Spanner가 이러한 백필 프로세스를 자동으로 관리하며, 이 프로세스는 낮은 우선순위의 노드 리소스를 사용하여 백그라운드에서 실행됩니다. 색인 백필 속도는 색인 생성 중에 변경되는 노드 리소스에 맞게 조정되며 백필은 데이터베이스 성능에 큰 영향을 미치지 않습니다.
색인을 만드는 데는 몇 분에서 여러 시간이 걸릴 수 있습니다. 색인 생성은 스키마 업데이트에 해당하므로 다른 스키마 업데이트와 동일한 성능 제약조건이 적용됩니다. 보조 색인을 만드는 데 필요한 시간은 다음과 같은 몇 가지 요인에 따라 달라집니다.
- 데이터 세트 크기
- 인스턴스의 컴퓨팅 용량
- 인스턴스의 부하
색인 백필 프로세스의 진행 상황을 보려면 진행 상황 섹션을 참조하세요.
커밋 타임스탬프 열을 보조 색인의 첫 번째 부분으로 사용하면 핫스팟을 만들고 쓰기 성능을 줄일 수 있습니다.
스키마에 보조 색인을 정의하려면 CREATE INDEX 문을 사용합니다. 예를 들면 다음과 같습니다.
데이터베이스의 모든 Singers에 대해 가수 이름과 성으로 색인을 생성하려면 다음을 실행합니다.
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
데이터베이스의 모든 Songs에 대해 SongName 값으로 색인을 생성하려면 다음을 실행합니다.
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
특정 가수의 노래만 색인으로 지정하려면 INTERLEAVE IN 절을 사용하여 Singers 테이블에서 색인을 인터리브합니다.
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
특정 앨범의 노래만 색인을 생성하려면 다음을 실행합니다.
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
SongName을 내림차순으로 색인을 생성하려면 다음을 실행합니다.
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
이전 DESC 주석은 SongName에만 적용됩니다. 다른 색인 키에 대해 내림차순으로 색인을 생성하려면 해당 키에도 DESC 주석을 사용합니다(예: SingerId DESC, AlbumId DESC).
또한 PRIMARY_KEY는 예약된 단어이며 색인 이름으로 사용할 수 없습니다. 이 이름은 기본 키 사양이 있는 테이블을 만들 때 생성되는 의사 색인으로 지정된 이름입니다.
인터리브 처리되지 않은 색인과 인터리브 처리된 색인을 선택하는 방법에 대한 자세한 내용과 권장사항은 색인 옵션 및 값이 단조 증가 또는 감소하는 열에 인터리브 처리된 색인 사용을 참조하세요.
색인 및 인터리브 처리
Spanner 색인은 색인 행을 다른 테이블의 행과 함께 배치하기 위해 다른 테이블과 인터리브 처리될 수 있습니다. Spanner 테이블 인터리브 처리와 마찬가지로 색인의 상위 요소 기본 키 열은 색인이 생성된 열의 프리픽스여야 하며 유형과 정렬 순서가 일치해야 합니다. 인터리브 처리된 테이블과 달리 열 이름은 일치할 필요가 없습니다. 인터리브 처리된 색인의 각 행은 연결된 상위 행과 함께 물리적으로 저장됩니다.
예를 들어 다음 스키마를 가정해 보세요.
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
데이터베이스의 모든 Singers에 가수 이름과 성으로 색인을 생성하려면 색인을 만들어야 합니다. 색인 SingersByFirstLastName을 정의하는 방법은 다음과 같습니다.
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
(SingerId, AlbumId, SongName)에 Songs 색인을 만들려면 다음을 수행하면 됩니다.
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
또는 다음과 같이 Songs 상위 요소와 인터리브 처리되는 색인을 만들 수 있습니다.
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
또한 Publishers와 같이 Songs의 상위 요소가 아닌 테이블과 인터리브 처리된 (PublisherId, SingerId, AlbumId, SongName)에 Songs의 색인을 만들 수도 있습니다. 다음 예시에서 Publishers 테이블(id)의 기본 키는 색인이 생성된 열의 프리픽스가 아닙니다. Publishers.Id 및 Songs.PublisherId가 같은 유형, 정렬 순서, null 허용 여부를 공유하므로 여전히 허용됩니다.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
색인 백필 진행 상황 확인
콘솔
Spanner 탐색 메뉴에서 작업 탭을 클릭합니다. 작업 페이지에 실행 중인 작업 목록이 표시됩니다.
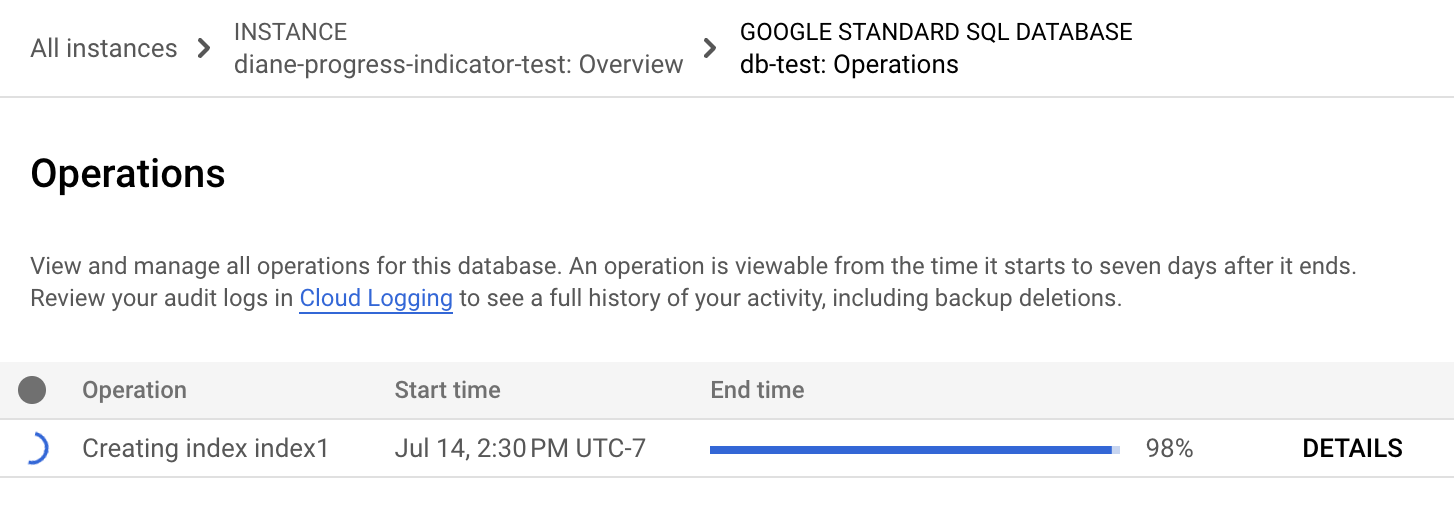
목록에서 백필 작업을 찾습니다. 아직 실행 중이면 다음 이미지와 같이 종료 시간 열의 진행률 표시기에 완료된 작업 비율이 표시됩니다.
gcloud
gcloud spanner operations describe를 사용하여 작업 진행 상황을 확인합니다.
작업 ID를 가져옵니다.
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
다음을 바꿉니다.
- INSTANCE-NAME: Spanner 인스턴스 이름
- DATABASE-NAME: 데이터베이스 이름
사용 참고사항:
목록을 제한하려면
--filter태그를 지정합니다. 예를 들면 다음과 같습니다.--filter="metadata.name:example-db"는 특정 데이터베이스의 작업만 나열합니다.--filter="error:*"는 실패한 백업 작업만 나열합니다.
필터 문법에 대한 자세한 내용은 gcloud topic filters를 참조하세요. 백업 작업 필터링에 대한 자세한 내용은 ListBackupOperationsRequest의
filter필드를 참조하세요.--type플래그는 대소문자를 구분하지 않습니다.
결과는 다음과 유사합니다.
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadatagcloud spanner operations describe을 실행합니다.gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
다음을 바꿉니다.
- INSTANCE-NAME: Spanner 인스턴스 이름
- DATABASE-NAME: Spanner 데이터베이스 이름
- PROJECT-NAME: 프로젝트 이름
- OPERATION-ID: 확인할 작업의 작업 ID
출력의
progress섹션에 완료된 작업의 비율이 표시됩니다. 출력은 다음과 유사합니다.done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
작업 ID를 가져옵니다.
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
다음을 바꿉니다.
- INSTANCE-NAME: Spanner 인스턴스 이름
- DATABASE-NAME: 데이터베이스 이름
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT-ID: 프로젝트 ID
- INSTANCE-ID: 인스턴스 ID
- DATABASE-ID: 데이터베이스 ID
- OPERATION-ID: 작업 ID
HTTP 메서드 및 URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
gcloud 및 REST의 경우 progress 섹션에서 각 색인 백필 문의 진행 상황을 찾을 수 있습니다. 문 배열의 각 문마다 진행 상황 배열에 해당하는 필드가 있습니다. 진행 상황 배열의 순서는 문 배열 순서와 일치합니다. 사용할 수 있게 되면 startTime, progressPercent, endTime 필드가 자동으로 채워집니다.
출력에는 백필 진행이 완료되는 예상 시간이 표시되지 않습니다.
작업에 시간이 너무 오래 걸리는 경우 취소할 수 있습니다. 자세한 내용은 색인 만들기 취소를 참조하세요.
색인 백필 진행 상황을 볼 때의 시나리오
색인 백필의 진행 상황을 확인할 때 발생할 수 있는 다양한 시나리오는 다음과 같습니다. 색인 백필이 필요한 색인 생성 문은 스키마 업데이트 작업의 일부이며 스키마 업데이트 작업에 속하는 여러 문이 있을 수 있습니다.
첫 번째 시나리오가 가장 간단하며, 색인 생성 문이 스키마 업데이트 작업의 첫 번째 문입니다. 색인 생성 문이 첫 번째 문이기 때문에 실행 순서에 따라 첫 번째로 처리되고 실행됩니다.
즉시 색인 생성 문의 startTime 필드가 스키마 업데이트 작업의 시작 시간으로 채워집니다. 그런 다음 색인 백필의 진행률이 0%를 초과하면 색인 생성 문의 progressPercent 필드가 채워집니다. 마지막으로 문이 커밋될 때 endTime 필드가 채워집니다.
두 번째 시나리오는 색인 생성 문이 스키마 업데이트 작업의 첫 번째 문이 아닌 경우입니다. 실행 순서에 따라 이전 문이 커밋될 때까지 색인 생성 문과 관련된 필드가 채워지지 않습니다.
이전 시나리오와 비슷하게, 이전 문이 커밋된 다음에는 색인 생성 문의 startTime 필드가 먼저 채워지고 그 다음 progressPercent 필드가 채워집니다. 마지막으로 문 커밋이 완료되면 endTime 필드가 채워집니다.
색인 생성 취소
Google Cloud CLI를 사용하여 색인 생성을 취소할 수 있습니다. Spanner 데이터베이스에 대한 스키마 업데이트 작업 목록을 검색하려면 gcloud spanner operations list 명령어를 사용하고 --filter 옵션을 포함합니다.
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
취소하려는 작업의 OPERATION_ID를 찾은 다음 gcloud spanner operations cancel 명령어를 사용하여 작업을 취소합니다.
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
기존 색인 보기
데이터베이스의 기존 색인에 대한 정보를 보려면Google Cloud 콘솔이나 Google Cloud CLI를 사용하면 됩니다.
콘솔
Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
보려는 인스턴스의 이름을 클릭합니다.
왼쪽 창에서 보려는 데이터베이스를 클릭한 다음 보려는 테이블을 클릭합니다.
색인 탭을 클릭합니다. Google Cloud 콘솔에 색인 목록이 표시됩니다.
선택사항: 색인에 포함된 열 등 색인에 대한 세부정보를 보려면 색인 이름을 클릭합니다.
gcloud
gcloud spanner databases ddl describe 명령어를 사용합니다.
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
gcloud CLI는 데이터 정의 언어(DDL) 문을 출력하여 데이터베이스의 테이블과 색인을 만듭니다. CREATE
INDEX 문은 기존 색인을 설명합니다. 예를 들면 다음과 같습니다.
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
특정 색인을 사용하는 쿼리
다음 섹션에서는 SQL 문에서 색인을 지정하는 방법과 Spanner용 읽기 인터페이스로 색인을 지정하는 방법을 설명합니다. 이 섹션의 예시에서는 Albums 테이블에 MarketingBudget 열을 추가하고 AlbumsByAlbumTitle이라는 색인을 만들었다고 가정합니다.
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
SQL 문에서 색인 지정
SQL을 사용하여 Spanner 테이블을 쿼리하면 Spanner는 쿼리 효율을 높일 수 있는 모든 색인을 자동으로 사용합니다. 따라서 SQL 쿼리에는 색인을 지정할 필요가 없습니다. 하지만 워크로드에 중요한 쿼리의 경우 보다 일관된 성능을 위해 SQL 문에서 FORCE_INDEX 지시문을 사용하는 것이 좋습니다.
일부 경우에는 Spanner가 선택한 색인으로 인해 쿼리 지연 시간이 증가할 수도 있습니다. 성능 회귀 문제해결 단계를 따른 경우 쿼리에 다른 색인을 시도하려면 색인을 쿼리의 일부로 지정하면 됩니다.
SQL 문에서 색인을 지정하려면 FORCE_INDEX 힌트를 사용하여 색인 지시문을 제공합니다. 색인 지시문은 다음 문법을 사용합니다.
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
색인 지시문을 사용하여 Spanner가 색인을 사용하지 않고 기본 테이블을 스캔하도록 지정할 수도 있습니다.
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
색인 지시문을 사용하여 Spanner가 이름이 지정된 스키마가 있는 테이블의 색인을 스캔하도록 지정할 수 있습니다.
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
다음 예시에서는 색인을 지정하는 SQL 쿼리를 보여줍니다.
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
색인 지시문을 사용하면 쿼리에 필요하지만 색인에 저장되지 않은 추가 열을 Spanner의 쿼리 프로세서가 강제로 읽도록 할 수 있습니다.
쿼리 프로세서는 색인과 기본 테이블을 조인하여 이러한 열을 검색합니다. 이러한 추가 조인을 방지하려면 STORING 절(GoogleSQL 언어 데이터베이스) 또는 INCLUDE 절(PostgreSQL 언어 데이터베이스)을 사용하여 색인에 추가 열을 저장합니다.
이전 예시에서 MarketingBudget 열은 색인에 저장되지 않지만 SQL 쿼리가 이 열을 선택합니다. 따라서 Spanner는 기본 테이블에서 MarketingBudget 열을 조회한 후 이를 색인의 데이터와 조인하여 쿼리 결과를 반환해야 합니다.
색인 지시문에 다음과 같은 문제가 있으면 Spanner에서 오류가 발생합니다.
- 색인이 없는 경우
- 색인이 다른 기본 테이블에 있는 경우
- 쿼리에
NULL_FILTERED색인의 필수NULL필터링 표현식이 누락된 경우
다음 예시에서는 AlbumsByAlbumTitle 색인을 사용하여 AlbumId, AlbumTitle, MarketingBudget 값을 가져오는 쿼리를 작성하고 실행하는 방법을 보여줍니다.
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
읽기 인터페이스에서 색인 지정
Spanner에 대한 읽기 인터페이스를 사용하는 경우 Spanner에서 색인을 사용하도록 하려면 색인을 지정해야 합니다. 읽기 인터페이스는 색인을 자동으로 선택하지 않습니다.
또한 색인에는 기본 키의 일부인 열을 제외하고 쿼리 결과에 나타나는 모든 데이터가 포함되어야 합니다. 이러한 제한이 있는 것은 읽기 인터페이스가 색인과 기본 테이블 간의 조인을 지원하지 않기 때문입니다. 쿼리 결과에 다른 열을 포함해야 하는 경우에는 다음과 같은 몇 가지 옵션을 사용할 수 있습니다.
STORING또는INCLUDE절을 사용하여 색인에 추가 열을 저장합니다.- 추가 열을 포함하지 않고 쿼리한 다음 기본 키를 사용하여 추가 열을 읽는 다른 쿼리를 전송합니다.
Spanner는 색인의 값을 색인 키를 기준으로 오름차순으로 반환합니다. 값을 내림차순으로 검색하려면 다음 단계를 완료하세요.
색인 키에
DESC로 주석을 추가합니다. 예를 들면 다음과 같습니다.CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);DESC주석은 단일 색인 키에 적용됩니다. 색인에 키가 2개 이상 포함된 경우 모든 키를 기준으로 쿼리 결과를 내림차순으로 표시하려면 각 키에 대해DESC주석을 포함합니다.읽기 인터페이스에서 키 범위를 지정하는 경우 키 범위도 내림차순이어야 합니다. 즉, 시작 키의 값이 종료 키의 값보다 커야 합니다.
다음 예시에서는 AlbumsByAlbumTitle 색인을 사용하여 AlbumId 및 AlbumTitle 값을 검색하는 방법을 보여줍니다.
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
색인 전용 스캔에 대한 색인 만들기
필요한 경우 STORING 절(GoogleSQL 언어 데이터베이스의 경우) 또는 INCLUDE 절(PostgreSQL 언어 데이터베이스의 경우)을 사용하여 색인에 열의 사본을 저장할 수 있습니다. 이러한 유형의 색인은 추가 스토리지를 사용하는 대신 색인을 사용하는 쿼리와 읽기 호출에 다음과 같은 이점을 제공합니다.
- 색인을 사용하고
STORING또는INCLUDE절에 저장된 열을 선택하는 SQL 쿼리는 기본 테이블에 추가 조인을 할 필요가 없습니다. - 색인을 사용하는
read()호출은STORING/INCLUDE절로 저장된 열을 읽을 수 있습니다.
예를 들어 색인에 MarketingBudget 열의 사본을 저장하는 AlbumsByAlbumTitle의 대체 버전을 만들었다고 가정해 보겠습니다(굵게 표시된 STORING 또는 INCLUDE 절 참고).
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
이전의 AlbumsByAlbumTitle 색인을 사용할 경우 Spanner는 기본 테이블과 색인을 조인한 다음 기본 테이블에서 열을 검색해야 합니다. 새로운 AlbumsByAlbumTitle2 색인을 사용할 경우에는 Spanner가 색인에서 직접 열을 읽으므로 더 효율적입니다.
SQL 대신 읽기 인터페이스를 사용하는 경우에도 새로운 AlbumsByAlbumTitle2 색인을 사용하여 MarketingBudget 열을 직접 읽을 수 있습니다.
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
색인 변경
ALTER INDEX 문을 사용하여 기존 색인에 열을 추가하거나 열을 삭제할 수 있습니다. 색인을 만들 때 STORING 절(GoogleSQL 언어 데이터베이스) 또는 INCLUDE 절(PostgreSQL 언어 데이터베이스)에서 정의된 열 목록을 업데이트할 수 있습니다. 이 문은 색인 키에 열을 추가하거나 열을 삭제할 때 사용할 수 없습니다. 예를 들어 다음 예시와 같이 새 색인 AlbumsByAlbumTitle2를 만드는 대신 ALTER INDEX를 사용하여 AlbumsByAlbumTitle에 열을 추가할 수 있습니다.
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
기존 색인에 새 열을 추가할 때 Spanner는 백그라운드 백필 프로세스를 사용합니다. 백필이 진행되는 동안 색인의 열을 읽을 수 없으므로 성능이 예상한 대로 부스트되지 않을 수 있습니다. gcloud spanner operations 명령어를 사용하여 장기 실행 작업을 나열하고 상태를 확인할 수 있습니다.
자세한 내용은 작업 설명을 참조하세요.
작업 취소를 사용하여 실행 중인 작업을 취소할 수도 있습니다.
백필이 완료되면 Spanner는 색인에 열을 추가합니다. 색인이 커지면 색인을 사용하는 쿼리의 속도가 느려질 수 있습니다.
다음 예시에서는 색인에서 열을 삭제하는 방법을 보여줍니다.
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
NULL 값의 색인
기본적으로 Spanner는 NULL 값을 색인으로 만듭니다. 예를 들어 Singers 테이블의 SingersByFirstLastName 색인에 대한 정의를 다시 살펴보세요.
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Singers의 모든 행은 FirstName 또는 LastName 중 하나, 또는 둘 모두가 NULL인 경우에도 색인이 생성됩니다.

NULL 값의 색인을 생성하면 NULL 값을 포함하는 데이터에 대해 효율적인 SQL 쿼리 및 읽기를 수행할 수 있습니다. 예를 들어 FirstName이 NULL인 모든 Singers를 찾으려면 다음 SQL 쿼리 문을 사용합니다.
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
NULL 값의 정렬 순서
Spanner는 NULL을 지정된 유형에서 가장 작은 값으로 정렬합니다. 오름차순(ASC) 열에서는 NULL 값이 가장 먼저 정렬되고 내림차순(DESC) 열에서는 NULL 값이 가장 나중에 정렬됩니다.
NULL 값의 색인 생성 중지
GoogleSQL
null의 색인 생성을 중지하려면 NULL_FILTERED 키워드를 색인 정의에 추가합니다. NULL_FILTERED 색인은 대부분의 행에 NULL 값이 있는 희소 열의 색인을 생성하는 데 특히 유용합니다. 이러한 경우에 NULL_FILTERED 색인은 NULL 값이 포함된 일반 색인보다 훨씬 더 작고 효율적일 수 있습니다.
다음은 NULL 값의 색인을 생성하지 않는 SingersByFirstLastName의 대체 정의입니다.
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
NULL_FILTERED 키워드는 모든 색인 키 열에 적용됩니다. 열 단위로 NULL 필터링을 지정할 수는 없습니다.
PostgreSQL
하나 이상의 색인이 생성된 열에서 Null 값이 있는 행을 필터링하려면 WHERE COLUMN IS NOT NULL 조건자를 사용합니다.
Null 필터링된 색인은 대부분의 행에 NULL 값이 포함된 희소 열의 색인을 생성하는 데 특히 유용합니다. 이러한 경우에 Null 필터링된 색인은 NULL 값이 포함된 일반 색인보다 훨씬 더 작고 효율적일 수 있습니다.
다음은 NULL 값의 색인을 생성하지 않는 SingersByFirstLastName의 대체 정의입니다.
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
NULL 값을 필터링하면 Spanner가 일부 쿼리에 이를 사용할 수 없게 됩니다. 예를 들어 이 색인은 LastName이 NULL인 모든 Singers 행을 생략하므로 Spanner는 이 쿼리에 이 색인을 사용하지 않습니다. 따라서 이 색인을 사용하면 쿼리에서 올바른 행이 반환되지 않습니다.
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Spanner가 이 색인을 사용할 수 있도록 하려면 색인에서 제외된 행을 마찬가지로 제외하도록 쿼리를 다시 작성해야 합니다.
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
proto 필드 색인 생성
생성된 열을 사용해서 PROTO 열에 저장된 프로토콜 버퍼의 필드로 색인을 생성할 수 있습니다. 이를 위해서는 색인을 생성할 필드에 기본 또는 ENUM 데이터 유형이 사용되어야 합니다.
프로토콜 메시지 필드에 색인을 정의할 경우 proto 스키마에서 해당 필드를 수정하거나 삭제할 수 없습니다. 자세한 내용은 proto 필드의 색인을 포함하는 스키마 업데이트를 참조하세요.
다음은 SingerInfo proto 메시지 열이 있는 Singers 테이블의 예시입니다. PROTO의 nationality 필드에서 색인을 정의하려면 저장된 생성 열을 만들어야 합니다.
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
다음과 같은 googlesql.example.SingerInfo proto 유형의 정의가 포함됩니다.
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
그런 후 proto의 nationality 필드에 색인을 정의합니다.
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
다음 SQL 쿼리는 이전 색인을 사용하여 데이터를 읽습니다.
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
참고:
- 프로토콜 버퍼 열의 필드에서 색인에 액세스하려면 색인 지시문을 사용합니다.
- 반복되는 프로토콜 버퍼 필드에는 색인을 만들 수 없습니다.
proto 필드의 색인을 포함하는 스키마 업데이트
프로토콜 메시지 필드에 색인을 정의할 경우 proto 스키마에서 해당 필드를 수정하거나 삭제할 수 없습니다. 색인을 정의한 후에는 스키마가 업데이트될 때마다 유형 검사가 수행되기 때문입니다. Spanner는 색인 정의에 사용된 경로에서 모든 필드에 대해 유형 정보를 캡처합니다.
고유 색인
색인은 UNIQUE로 선언할 수 있습니다. UNIQUE 색인은 색인이 생성되는 데이터에 지정된 색인 키의 중복 항목을 금지하는 제약조건을 추가합니다.
이 제약조건은 Spanner에서 트랜잭션 커밋 시 적용됩니다.
특히 같은 키에 여러 색인 항목을 만드는 트랜잭션은 커밋되지 않습니다.
테이블에서 처음에 UNIQUE가 아닌 데이터가 있는 경우 테이블에 UNIQUE 색인을 만들려고 하면 실패합니다.
UNIQUE NULL_FILTERED 색인에 대한 참고사항
UNIQUE NULL_FILTERED 색인은 색인의 키 부분 중 적어도 하나가 NULL이면 색인 키 고유성을 적용하지 않습니다.
예를 들어 다음과 같은 테이블과 색인을 만들었다고 가정해보겠습니다.
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
ExampleTable의 다음 두 행은 보조 색인 키 Key1, Key2, Col1에 같은 값이 있습니다.
1, NULL, 1, 1
1, NULL, 2, 1
Key2가 NULL이고 색인이 null로 필터링되었으므로 ExampleIndex 색인에 행이 표시되지 않습니다. 해당 행이 색인에 삽입되지 않으므로 이 색인은 (Key1, Key2,
Col1)의 고유성 위반에 대해 행을 거부하지 않습니다.
색인이 튜플(Key1, Key2, Col1)의 값 고유성을 적용하도록 하려면 테이블 정의에서 Key2에 NOT NULL 주석을 추가하거나 null로 필터링되지 않는 색인을 만들어야 합니다.
색인 삭제
스키마에서 보조 색인을 삭제하려면 DROP INDEX 문을 사용합니다.
SingersByFirstLastName이라는 색인을 삭제하려면 다음을 실행합니다.
DROP INDEX SingersByFirstLastName;
빠른 스캔을 위한 색인
Spanner로 색인 조회 대신 테이블 스캔을 수행해서 하나 이상의 열에서 값을 가져와야 할 경우 해당 열에 그리고 쿼리로 지정된 순서로 색인이 존재할 경우 결과를 더 빠르게 얻을 수 있습니다. 스캔이 필요한 쿼리를 자주 수행할 경우에는 스캔 효율을 높이기 위해 보조 색인을 만드는 것이 좋습니다.
특히 Spanner로 테이블의 기본 키 또는 기타 색인을 역순으로 자주 스캔할 경우 선택한 순서를 명시적으로 지정하는 보조 색인을 통해 효율을 높일 수 있습니다.
예를 들어 다음 쿼리는 Spanner가 SongId의 최저 값을 찾기 위해 Songs를 스캔해야 하지만 항상 빠른 결과를 반환합니다.
SELECT SongId FROM Songs LIMIT 1;
SongId는 오름차순으로 저장된(모든 기본 키 사용) 테이블의 기본 키입니다. Spanner는 키 색인을 스캔하고 첫 번째 결과를 빠르게 찾을 수 있습니다.
하지만 보조 색인을 사용할 경우 특히 Songs에 많은 데이터가 포함되었으면 다음 쿼리가 이렇게 빠르게 결과를 반환하지 않습니다.
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
SongId가 테이블의 기본 키이지만 Spanner가 전체 테이블 스캔을 사용하지 않으면 열에서 가장 높은 값을 가져올 수 있는 방법이 없습니다.
다음 색인을 추가하면 이 쿼리가 더 빠르게 결과를 반환할 수 있습니다.
CREATE INDEX SongIdDesc On Songs(SongId DESC);
이 색인을 사용하면 Spanner가 이를 사용해서 보조 쿼리에 대해 결과를 훨씬 더 빠르게 반환합니다.
다음 단계
- Spanner용 SQL 권장사항 알아보기
- Spanner의 쿼리 실행 계획 이해하기
- SQL 쿼리에서의 성능 회귀 문제해결 방법 알아보기