本页面介绍了 Spanner 的自动扩缩器工具(自动扩缩器)。它是一种开源工具,可用作 Spanner 的配套工具。借助此工具,您可以根据容量的使用量自动增加或减少一个或多个 Spanner 实例中的计算容量。
如需详细了解 Spanner 中的扩缩,请参阅自动伸缩 Spanner。如需了解如何部署自动扩缩器工具,请参阅以下内容:
本页面介绍了自动扩缩器的功能、架构和高级别配置。这些主题将引导您完成在每种不同拓扑中将自动扩缩器部署到某个受支持的运行时。
自动扩缩器
自动扩缩器工具对于管理 Spanner 部署的利用率和性能非常有用。为了帮助您在费用控制和性能需求之间取得平衡,自动扩缩器会监控您的实例并自动添加或移除节点或处理单元,以帮助确保它们保持在以下参数范围内:
加上或减去可配置的边际。
自动扩缩 Spanner 部署可让您的基础设施自动适应和扩缩以满足负载要求,且几乎不需要干预。自动扩缩还可适当调整预配的基础设施的规模,从而帮助您最大限度地减少产生的费用。
架构
自动扩缩器有两个主要组件,即轮询器和扩缩器和 。虽然您可以将具有不同配置的自动扩缩器部署到具有不同配置的多个拓扑中的多个运行时,但这些核心组件的功能是相同的。
本部分详细介绍了这两个组件及其用途。
轮询器
轮询器负责收集和处理一个或多个 Spanner 实例的时序指标。轮询器对每个 Spanner 实例的指标数据进行预处理,以便仅评估最相关的数据点并将其发送到扩缩器。轮询器执行的预处理还可以简化区域级、双区域和多区域 Spanner 实例的阈值的评估流程。
扩缩器
扩缩器会评估从轮询器组件接收的数据点,并确定是否需要调整节点或处理单元数量,以及如果需要,则调整多大的幅度。扩缩器会将指标值与阈值进行比较,加上或减去允许的边际,并根据配置的扩缩方法调整节点或处理单元数量。如需了解详情,请参阅扩缩方法。
在整个流程中,自动扩缩器工具会将建议和操作的摘要写入 Cloud Logging 以进行跟踪和审核。
自动扩缩器功能
本部分介绍了自动扩缩器工具的主要功能。
管理多个实例
自动扩缩器工具能够跨多个项目管理多个 Spanner 实例。多区域级实例、双区域实例和区域级实例在扩缩时使用的利用率阈值各不相同。例如,多区域级部署和双区域部署在 45% 高优先级 CPU 利用率时进行扩缩,而区域级部署在 65% 的高优先级 CPU 利用率时进行扩缩,两者加上或减去允许的边际。如需详细了解不同的扩缩阈值,请参阅针对高 CPU 利用率的提醒。
独立的配置参数
每个自动扩缩的 Spanner 实例可以有一个或多个轮询时间表。每个轮询时间表都有自己的一组配置参数。
这些参数确定以下因素:
扩缩方法
自动扩缩器工具提供了三种不同的扩容和缩容 Spanner 实例的方法:阶梯、线性和直接。每种方法旨在支持不同类型的工作负载。创建独立的轮询时间表时,您可以将一个或多个方法应用于自动扩缩的每个 Spanner 实例。
以下部分包含有关这些扩缩方法的更多信息。
阶梯
阶梯扩缩对于规模较小或具有多个峰值的工作负载非常有用。它预配了容量,可通过一个自动扩缩事件平滑处理所有工作负载。
下图显示了具有多个负载水平或阶梯的负载模式,其中每个阶梯有多个小峰值。此模式非常适合阶梯方法。
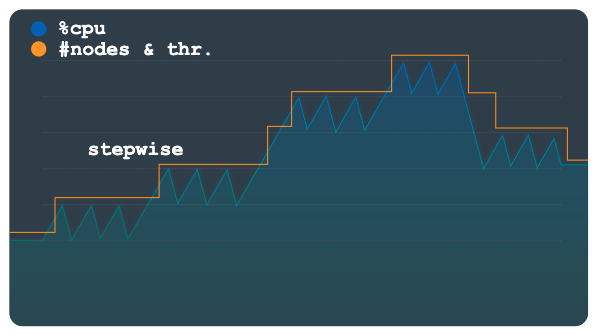
超过负载阈值时,此方法会使用固定但可配置的数字预配和移除节点或处理单元。例如,系统会为每个扩缩操作添加或移除三个节点。通过更改配置,您可以允许在任何时间添加或移除增量更大的容量。
线性
线性扩缩最适合负载逐步变化或具有一些大峰值的负载模式。该方法会计算使利用率低于扩缩阈值所需的最小节点数或处理单元数。 每个扩缩事件中添加或移除的节点或处理单元数量不限于固定步数。
下图中的示例负载模式展示了负载较大的突然增加和减少。这些波动不会像在上一张图表中的阶梯一样明显。使用线性扩缩可能会更好地处理此模式。
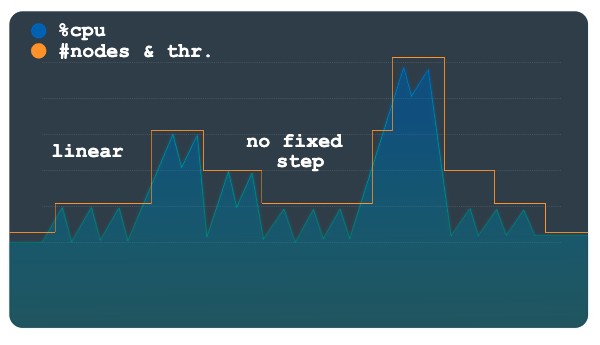
自动扩缩器工具会使用观察到的利用率与利用率阈值的比率,计算在当前总数中增加还是减少节点数或处理单元数。
计算新节点或处理单元数的公式如下所示:
newSize = currentSize * currentUtilization / utilizationThreshold
直接
直接扩缩功能可以即时提升容量。此方法旨在支持批处理工作负载,在其中,需要定期按已知的开始时间调度预先定义的较高节点计数。此方法会将实例扩容到在时间表中指定的节点或处理单元数量上限,并且旨在用作线性或阶梯方法之外的补充方法。
下图描述了负载计划的计划大幅增加,而自动扩缩器为使用直接方法提前预配了容量。
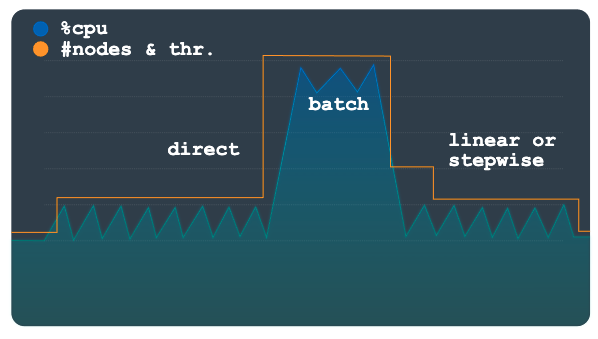
当批量工作负载完成并且利用率达到正常水平(具体取决于您的配置)后,系统将应用线性或阶梯扩缩功能来自动缩减实例。
配置
自动扩缩器工具有不同的配置选项,可用于管理 Spanner 部署的扩缩。虽然 Cloud Run 函数和 GKE 参数类似,但它们的提供方式不同。如需详细了解如何配置自动扩缩器工具,请参阅配置 Cloud Run 函数部署和配置 GKE 部署。
高级配置
自动扩缩器工具具有高级配置选项,让您可以更精细地控制 Spanner 实例的管理时间和方式。以下各部分介绍了这些控制机制的选择。
自定义阈值
自动扩缩器工具使用针对以下负载指标建议的 Spanner 阈值确定要为实例增加或减少的节点数或处理单元数:
- 高优先级 CPU
- CPU 24 小时滚动平均值
- 存储空间利用率
我们建议您使用针对 Spanner 指标创建提醒中所述的默认阈值。但是在某些情况下,您可能需要修改自动扩缩器工具使用的阈值。例如,您可以使用较低的阈值,让自动扩缩器工具的响应速度比较高的阈值还快。此修改有助于防止系统以更高的阈值触发提醒。
自定义指标
虽然自动扩缩器工具中的默认指标可以应对大多数性能和扩缩场景,但在某些情况下,您可能需要指定自己的指标,用于确定何时进行扩缩。在这些场景中,您可以使用 metrics 属性在配置中定义自定义指标。
边际
边际定义了阈值的上限和下限。只有在指标值大于上限或小于下限时,自动扩缩器工具才会触发自动扩缩事件。
此参数的目标是避免自动扩缩事件因阈值造成较小工作负载波动触发,从而减少自动扩缩器操作中的波动量。阈值和边际共同根据指标值您想要定义以下范围:
[threshold - margin, threshold + margin]
边际越小,范围越小,自动扩缩事件触发的可能性就越高。
指定指标的边际参数是可选的,并且默认为该参数前后的 5 个百分点。
数据拆分
Spanner 将称为“分块”的数据范围分配给节点或称为处理单元的节点细分。节点或处理单元独立管理和处理分配的分块中的数据。数据分块是基于多个因素创建的,包括数据量和访问模式。如需了解详情,请参阅 Spanner - 架构和数据模型。
数据会整理成分块,Spanner 会自动管理分块。因此,当自动扩缩器工具添加或移除节点或处理单元时,它需要为 Spanner 后端留出足够的时间来重新分配和重新整理分块,因为在实例中添加或移除了新容量。
自动扩缩器工具对扩容和缩容事件使用冷却期来控制在实例中添加或移除节点或处理单元的速度。此方法会为实例留出重新整理计算节点或处理单元与数据分块之间的关系所需的时间。默认情况下,扩容和缩容冷却期设置为以下最小值:
- 扩容值:5 分钟
- 缩减值:30 分钟
如需详细了解扩缩建议和冷却期,请参阅扩缩 Spanner 实例。
价格
自动扩缩器工具在计算、内存和存储方面的资源消耗量很小。根据您自动扩缩器的配置,当自动扩缩器部署到 Cloud Run functions 时,其资源利用率通常在其依赖服务(Cloud Run functions、Cloud Scheduler、Pub/Sub 和 Firestore)的免费层级内。
您可使用价格计算器根据您的预计使用情况来估算环境费用。
后续步骤
- 了解如何将自动扩缩器工具部署到 Cloud Run functions。
- 了解如何将自动扩缩器工具部署到 GKE。
- 详细了解 Spanner 建议的阈值。
- 详细了解 Spanner CPU 利用率指标和延迟时间指标。
- 了解 Spanner 架构设计的最佳实践,以避免热点并将数据加载到 Spanner。
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。