En esta página se presenta la herramienta de escalado automático de Spanner (Autoscaler), una herramienta de código abierto que puedes usar como herramienta complementaria de Spanner. Esta herramienta te permite aumentar o reducir automáticamente la capacidad de computación de una o varias instancias de Spanner en función de la capacidad que se esté usando.
Para obtener más información sobre el escalado en Spanner, consulta Autoescalado de Spanner. Para obtener información sobre cómo implementar la herramienta de autoescalado, consulta lo siguiente:
- Despliega la herramienta de escalado automático de Spanner en funciones de Cloud Run.
- Despliega la herramienta Autoscaler para Spanner en Google Kubernetes Engine (GKE).
En esta página se describen las funciones, la arquitectura y la configuración de alto nivel del escalador automático. En estos temas se explica cómo desplegar el escalador automático en uno de los tiempos de ejecución admitidos en cada una de las topologías.
Herramienta de adaptación dinámica
La herramienta de escalado automático es útil para gestionar la utilización y el rendimiento de tus implementaciones de Spanner. Para ayudarte a equilibrar el control de costes con las necesidades de rendimiento, la herramienta de autoescalado monitoriza tus instancias y añade o elimina nodos o unidades de procesamiento automáticamente para asegurarse de que se mantengan dentro de los siguientes parámetros:
Más o menos un margen configurable.
El autoescalado de las implementaciones de Spanner permite que tu infraestructura se adapte y se escale automáticamente para cumplir los requisitos de carga con poca o ninguna intervención. El escalado automático también ajusta el tamaño de la infraestructura aprovisionada, lo que puede ayudarte a minimizar los cargos incurridos.
Arquitectura
El escalador automático tiene dos componentes principales: el Poller y el Scaler. Aunque puedes implementar el escalador automático con diferentes configuraciones en varios tiempos de ejecución de varias topologías con diferentes configuraciones, la funcionalidad de estos componentes principales es la misma.
En esta sección se describen estos dos componentes y sus finalidades con más detalle.
Sondeador
El Poller recoge y procesa las métricas de serie temporal de una o varias instancias de Spanner. El Poller preprocesa los datos de métricas de cada instancia de Spanner para que solo se evalúen y se envíen al escalador los puntos de datos más relevantes. El preprocesamiento que realiza Poller también simplifica el proceso de evaluación de los umbrales de las instancias de Spanner regionales, birregionales y multirregionales.
Escalador
El escalador evalúa los puntos de datos recibidos del componente Poller y determina si es necesario ajustar el número de nodos o unidades de procesamiento y, en caso afirmativo, en qué medida. Compara los valores de las métricas con el umbral, más o menos un margen permitido, y ajusta el número de nodos o unidades de procesamiento en función del método de escalado configurado. Para obtener más información, consulta Métodos de escalado.
A lo largo del flujo, la herramienta de escalado automático escribe un resumen de sus recomendaciones y acciones en Cloud Logging para hacer un seguimiento y una auditoría.
Funciones de la herramienta de adaptación dinámica
En esta sección se describen las principales funciones de la herramienta de escalado automático.
Gestionar varias instancias
La herramienta de escalado automático puede gestionar varias instancias de Spanner en varios proyectos. Las instancias multirregionales, birregionales y regionales tienen umbrales de utilización diferentes que se usan al escalar. Por ejemplo, las implementaciones multirregionales y birregionales se escalan al 45% de utilización de la CPU de alta prioridad, mientras que las implementaciones regionales se escalan al 65% de utilización de la CPU de alta prioridad. En ambos casos, se aplica un margen permitido. Para obtener más información sobre los diferentes umbrales de escalado, consulta Alertas por uso elevado de la CPU.
Parámetros de configuración independientes
Cada instancia de Spanner con escalado automático puede tener una o varias programaciones de sondeo. Cada programación de sondeo tiene su propio conjunto de parámetros de configuración.
Estos parámetros determinan los siguientes factores:
- El número mínimo y máximo de nodos o unidades de procesamiento que controlan el tamaño de tu instancia, lo que te ayuda a controlar los cargos incurridos.
- El método de escalado que se usa para ajustar tu instancia de Spanner a tu carga de trabajo.
- Los periodos de enfriamiento para permitir que Spanner gestione las divisiones de datos.
Métodos de escalado
La herramienta de escalado automático ofrece tres métodos de escalado diferentes para aumentar y reducir el tamaño de tus instancias de Spanner: por pasos, lineal y directo. Cada método está diseñado para admitir diferentes tipos de cargas de trabajo. Puedes aplicar uno o varios métodos a cada instancia de Spanner que se escale automáticamente cuando crees programaciones de sondeo independientes.
En las siguientes secciones se ofrece más información sobre estos métodos de escalado.
Paso a paso
El escalado por pasos es útil para cargas de trabajo que tienen picos pequeños o múltiples. Proporciona capacidad para suavizarlos todos con un solo evento de escalado automático.
En el siguiente gráfico se muestra un patrón de carga con varias mesetas o pasos de carga, donde cada paso tiene varios picos pequeños. Este patrón es adecuado para el método de pasos.
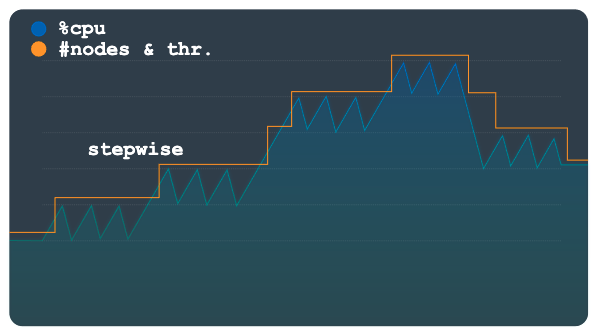
Cuando se supera el umbral de carga, este método aprovisiona y elimina nodos o unidades de procesamiento mediante un número fijo, pero configurable. Por ejemplo, se añaden o se quitan tres nodos por cada acción de escalado. Si cambia la configuración, podrá añadir o quitar incrementos de capacidad más grandes en cualquier momento.
Lineal
El escalado lineal se usa mejor con patrones de carga que cambian de forma más gradual o que tienen algunos picos grandes. El método calcula el número mínimo de nodos o unidades de procesamiento necesarios para mantener la utilización por debajo del umbral de escalado. El número de nodos o unidades de procesamiento que se añaden o quitan en cada evento de escalado no se limita a una cantidad fija.
El patrón de carga de ejemplo del siguiente gráfico muestra grandes aumentos y disminuciones repentinos de la carga. Estas fluctuaciones no se agrupan en pasos discernibles como en el gráfico anterior. Este patrón se puede gestionar mejor con el escalado lineal.
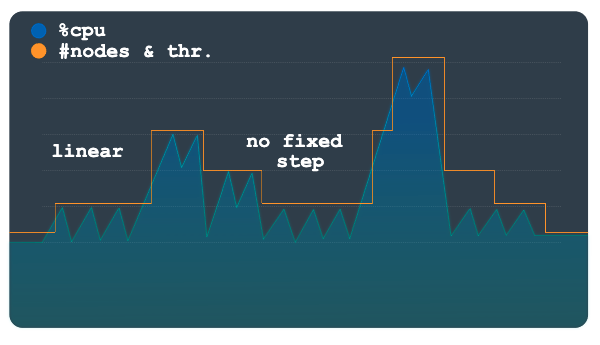
La herramienta de autoescalado usa la proporción de la utilización observada con respecto al umbral de utilización para calcular si se deben añadir o restar nodos o unidades de procesamiento del número total actual.
La fórmula para calcular el nuevo número de nodos o unidades de procesamiento es la siguiente:
newSize = currentSize * currentUtilization / utilizationThreshold
Directo
El escalado directo proporciona un aumento inmediato de la capacidad. Este método se ha diseñado para admitir cargas de trabajo por lotes en las que se requiere periódicamente un número de nodos superior predeterminado en una programación con una hora de inicio conocida. Este método escala la instancia hasta el número máximo de nodos o unidades de procesamiento especificado en la programación y se debe usar junto con un método lineal o escalonado.
En el siguiente gráfico se muestra el gran aumento de carga previsto, para el que Autoscaler ha aprovisionado capacidad previamente mediante el método directo.
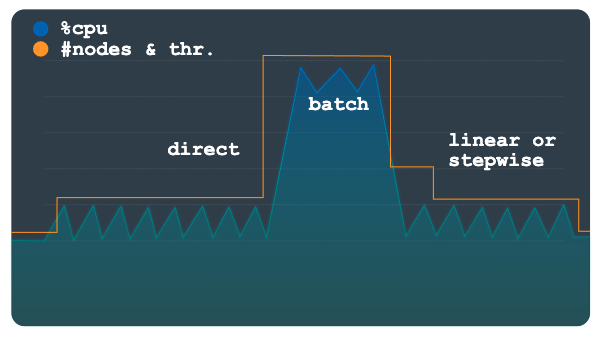
Una vez que se haya completado la carga de trabajo por lotes y la utilización vuelva a niveles normales, se aplicará un escalado lineal o gradual, en función de tu configuración, para reducir la escala de la instancia automáticamente.
Configuración
La herramienta de escalado automático tiene diferentes opciones de configuración que puede usar para gestionar el escalado de sus implementaciones de Spanner. Aunque los parámetros de las funciones de Cloud Run y de GKE son similares, se proporcionan de forma diferente. Para obtener más información sobre cómo configurar la herramienta de escalado automático, consulta los artículos Configurar una implementación de funciones de Cloud Run y Configurar una implementación de GKE.
Configuración avanzada
La herramienta Auto Scaler tiene opciones de configuración avanzadas que te permiten controlar con mayor precisión cuándo y cómo se gestionan tus instancias de Spanner. En las siguientes secciones se presenta una selección de estos controles.
Umbrales personalizados
La herramienta de ajuste automático determina el número de nodos o unidades de procesamiento que se van a añadir o restar a una instancia mediante los umbrales recomendados de Spanner para las siguientes métricas de carga:
- CPU de prioridad alta
- Uso de CPU (promedio de 24 horas)
- Uso de almacenamiento
Te recomendamos que uses los umbrales predeterminados, tal como se describe en el artículo Crear alertas para métricas de Spanner. Sin embargo, en algunos casos, puede que quieras modificar los umbrales que usa la herramienta de escalado automático. Por ejemplo, puedes usar umbrales más bajos para que la herramienta de escalado automático reaccione más rápido que con umbrales más altos. Esta modificación ayuda a evitar que se activen alertas con umbrales más altos.
Métricas personalizadas
Aunque las métricas predeterminadas de la herramienta de escalado automático cubren la mayoría de los casos de rendimiento y escalado, hay algunas situaciones en las que puede que tengas que especificar tus propias métricas para determinar cuándo se debe aumentar o reducir la escala. En estos casos, puede definir métricas personalizadas en la configuración mediante la propiedad metrics.
Márgenes
Un margen define un límite superior y otro inferior en torno al umbral. La herramienta de autoescalado solo activa un evento de autoescalado si el valor de la métrica es superior al límite superior o inferior al límite inferior.
El objetivo de este parámetro es evitar que se activen eventos de autoescalado debido a pequeñas fluctuaciones de la carga de trabajo en torno al umbral, lo que reduce la cantidad de fluctuaciones en las acciones de la herramienta de autoescalado. El umbral y el margen definen el siguiente intervalo, según el valor que quiera que tenga la métrica:
[threshold - margin, threshold + margin]
Cuanto menor sea el margen, más estrecho será el intervalo, lo que dará lugar a una mayor probabilidad de que se active un evento de autoescalado.
Especificar un parámetro de margen para una métrica es opcional. De forma predeterminada, el margen es de cinco puntos porcentuales tanto antes como después del parámetro.
Divisiones de datos
Spanner asigna intervalos de datos llamados divisiones a nodos o subdivisiones de un nodo llamadas unidades de procesamiento. El nodo o las unidades de procesamiento gestionan y sirven los datos de las divisiones asignadas de forma independiente. Las divisiones de datos se crean en función de varios factores, como el volumen de datos y los patrones de acceso. Para obtener más información, consulta Spanner: esquema y modelo de datos.
Los datos se organizan en divisiones y Spanner gestiona automáticamente las divisiones. Por lo tanto, cuando la herramienta de autoescalado añade o elimina nodos o unidades de procesamiento, debe permitir que el backend de Spanner tenga tiempo suficiente para reasignar y reorganizar las divisiones a medida que se añade o se elimina capacidad de las instancias.
La herramienta de escalado automático usa periodos de enfriamiento en los eventos de escalado vertical y horizontal para controlar la rapidez con la que puede añadir o quitar nodos o unidades de procesamiento de una instancia. Este método permite que la instancia tenga el tiempo necesario para reorganizar las relaciones entre las notas de cálculo o las unidades de procesamiento y las divisiones de datos. De forma predeterminada, los periodos de enfriamiento de ampliación y reducción se definen en los siguientes valores mínimos:
- Valor de ampliación: 5 minutos
- Valor de reducción: 30 minutos
Para obtener más información sobre las recomendaciones de escalado y los periodos de enfriamiento, consulta el artículo Escalar instancias de Spanner.
Precios
El consumo de recursos de la herramienta de escalado automático es mínimo en términos de computación, memoria y almacenamiento. En función de la configuración del escalador automático, cuando se despliega en Cloud Run Functions, la utilización de recursos del escalador automático suele estar en el nivel gratuito de sus servicios dependientes (Cloud Run Functions, Cloud Scheduler, Pub/Sub y Firestore).
Usa la calculadora de precios para generar una estimación de los costes de tus entornos en función del uso previsto.
Siguientes pasos
- Consulta cómo desplegar la herramienta Autoscaler en funciones de Cloud Run.
- Consulta cómo desplegar la herramienta de escalado automático en GKE.
- Consulta más información sobre los umbrales recomendados de Spanner.
- Consulta más información sobre las métricas de uso de CPU y las métricas de latencia de Spanner.
- Consulta las prácticas recomendadas para diseñar esquemas de Spanner y evitar puntos de acceso y cargar datos en Spanner.
- Consulta arquitecturas de referencia, diagramas y prácticas recomendadas sobre Google Cloud. Consulta nuestro Centro de arquitectura de Cloud.