En esta página, se describe cómo puedes usar la guía de inicio rápido de GKE Inference para simplificar la implementación de cargas de trabajo de inferencia de IA/ML en Google Kubernetes Engine (GKE). Inference Quickstart es una utilidad que te permite especificar tus requisitos comerciales de inferencia y obtener configuraciones de Kubernetes optimizadas según las prácticas recomendadas y las comparativas de Google para modelos, servidores de modelos, aceleradores (GPUs, TPUs) y escalamiento. Esto te ayuda a evitar el proceso que requiere mucho tiempo de ajustar y probar las configuraciones de forma manual.
Esta página está dirigida a ingenieros de aprendizaje automático (AA), administradores y operadores de plataformas, y especialistas en IA y datos que desean comprender cómo administrar y optimizar GKE de manera eficiente para la inferencia de IA/AA. Para obtener más información sobre los roles comunes y las tareas de ejemplo a las que hacemos referencia en el contenido de Google Cloud , consulta Roles de usuario y tareas comunes de GKE Enterprise.
Para obtener más información sobre los conceptos y la terminología de la entrega de modelos, y cómo las capacidades de IA generativa de GKE pueden mejorar y respaldar el rendimiento de la entrega de modelos, consulta Acerca de la inferencia de modelos en GKE.
Antes de leer esta página, asegúrate de estar familiarizado con Kubernetes, GKE y la publicación de modelos.
Usa la guía de inicio rápido de Inference
Los pasos de alto nivel para usar la guía de inicio rápido de Inference son los siguientes: Haz clic en los vínculos para obtener instrucciones detalladas.
- Ver prácticas recomendadas personalizadas: En la página de IA/ML de GKE de la consola de Google Cloud o en Google Cloud CLI en la terminal, comienza por proporcionar entradas como tu modelo abierto preferido (por ejemplo, Llama, Gemma o Mistral).
- Puedes especificar el objetivo de latencia de tu aplicación, lo que indica si es sensible a la latencia (como un chatbot) o al rendimiento (como las estadísticas por lotes).
- Según tus requisitos, Inference Quickstart proporciona opciones de aceleradores, métricas de rendimiento y manifiestos de Kubernetes, lo que te brinda control total para la implementación o modificaciones adicionales. Los manifiestos generados hacen referencia a imágenes públicas del servidor de modelos, por lo que no tienes que crear estas imágenes tú mismo.
- Implementa manifiestos: Implementa los manifiestos recomendados con la consola de Google Cloud o el comando
kubectl apply. Antes de implementar, debes asegurarte de tener suficiente cuota de aceleradores para las GPUs o las TPUs seleccionadas en tu proyecto de Google Cloud . - Supervisa el rendimiento: Usa Cloud Monitoring para supervisar las métricas de rendimiento de la carga de trabajo que proporciona GKE. Puedes ver los paneles del servidor de modelos y ajustar tu implementación según sea necesario.
Beneficios
La guía de inicio rápido de Inference te ayuda a ahorrar tiempo y recursos, ya que proporciona configuraciones optimizadas. Estas optimizaciones mejoran el rendimiento y reducen los costos de infraestructura de las siguientes maneras:
- Recibirás prácticas recomendadas detalladas y personalizadas para configurar el acelerador (GPU y TPU), el servidor de modelos y los parámetros de configuración de escalamiento. GKE actualiza la herramienta de forma rutinaria con las correcciones, las imágenes y las comparativas de rendimiento más recientes.
- Puedes especificar los requisitos de latencia y capacidad de procesamiento de tu carga de trabajo con la IU de la consola deGoogle Cloud o una interfaz de línea de comandos, y obtener prácticas recomendadas detalladas y personalizadas como manifiestos de implementación de Kubernetes.
Casos de uso
La guía de inicio rápido de Inference es adecuada para situaciones como las siguientes:
- Descubre arquitecturas de inferencia óptimas de GKE: Si estás realizando una transición desde otro entorno, como un entorno local o un proveedor de servicios en la nube diferente, y deseas conocer las arquitecturas de inferencia recomendadas más actualizadas en GKE para tus necesidades específicas de rendimiento.
- Acelera las implementaciones de inferencia de IA/AA: Si eres un usuario experimentado de Kubernetes y deseas comenzar rápidamente a implementar cargas de trabajo de inferencia de IA, la guía de inicio rápido de Inference te ayuda a descubrir e implementar implementaciones de prácticas recomendadas en GKE, con configuraciones detalladas de YAML basadas en prácticas recomendadas.
- Explora las TPU para mejorar el rendimiento: Si ya utilizas Kubernetes en GKE con GPUs, puedes usar la guía de inicio rápido de Inference para explorar los beneficios de usar TPU y, potencialmente, lograr un mejor rendimiento.
Cómo funciona
La guía de inicio rápido de Inference proporciona prácticas recomendadas personalizadas basadas en las exhaustivas comparativas internas de Google sobre el rendimiento de una sola réplica para combinaciones de topología de modelos, servidores de modelos y aceleradores. Estos gráficos de comparativas muestran la latencia en comparación con la capacidad de procesamiento, incluidas las métricas de tamaño de la cola y de caché de KV, que trazan las curvas de rendimiento para cada combinación.
Cómo se generan las prácticas recomendadas personalizadas
Medimos la latencia en tiempo normalizado por token de salida (NTPOT) en milisegundos y el rendimiento en tokens de salida por segundo, saturando los aceleradores. Para obtener más información sobre estas métricas de rendimiento, consulta Acerca de la inferencia del modelo en GKE.
En el siguiente ejemplo de perfil de latencia, se ilustra el punto de inflexión en el que el rendimiento alcanza su punto máximo (verde), el punto posterior a la inflexión en el que la latencia empeora (rojo) y la zona ideal (azul) para un rendimiento óptimo en el objetivo de latencia. La guía de inicio rápido de Inference proporciona datos de rendimiento y configuraciones para esta zona ideal.
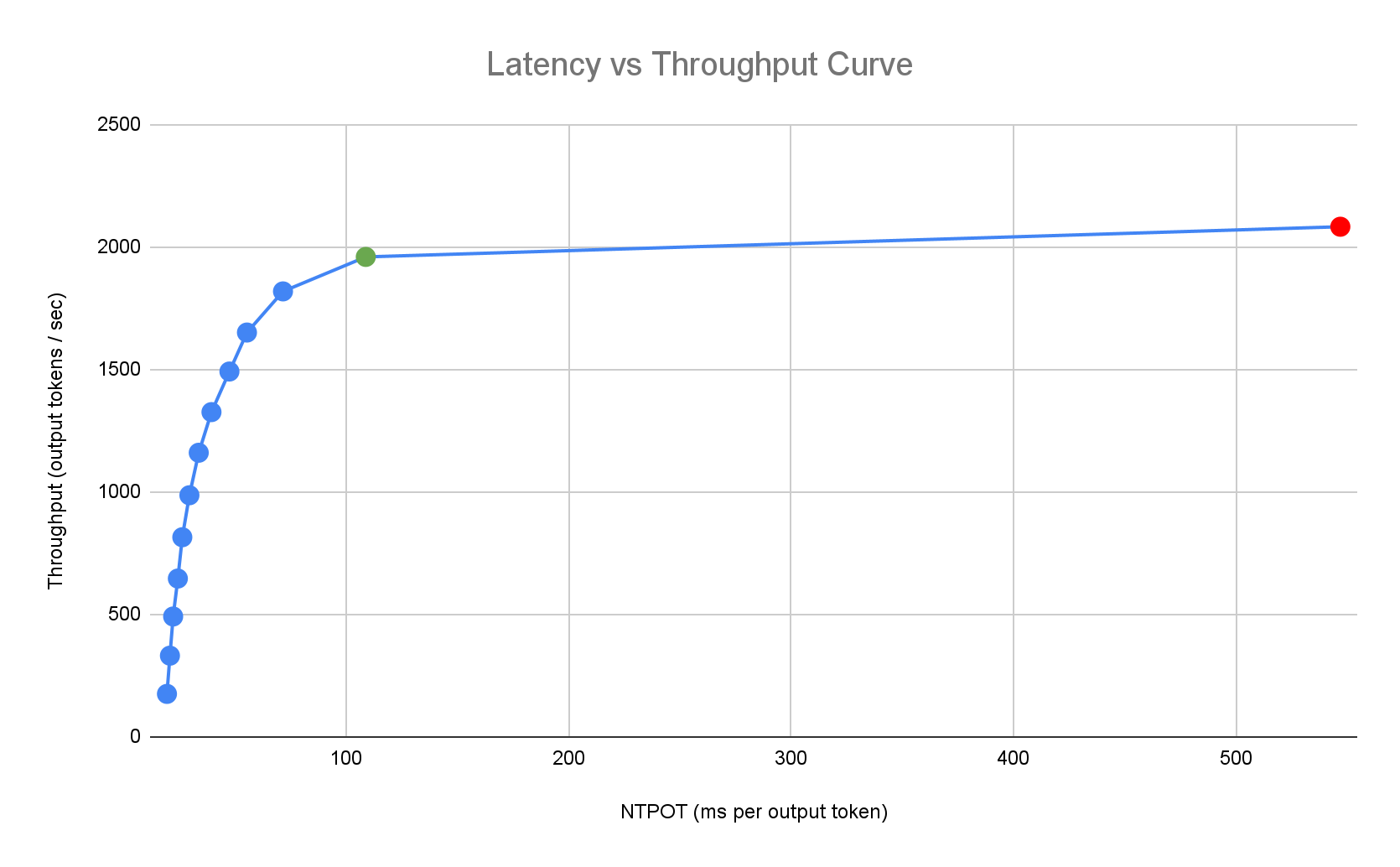
Según los requisitos de latencia de una aplicación de inferencia, Inference Quickstart identifica combinaciones adecuadas y determina el punto de funcionamiento óptimo en la curva de latencia y capacidad de procesamiento. Este punto establece el umbral del Horizontal Pod Autoscaler (HPA), con un búfer para tener en cuenta la latencia del aumento de escala. El umbral general también proporciona información sobre la cantidad inicial de réplicas necesarias, aunque el HPA ajusta dinámicamente esta cantidad en función de la carga de trabajo.
Comparativas
Los datos de rendimiento y las configuraciones proporcionados se basan en comparativas que utilizan el conjunto de datos de ShareGPT para enviar tráfico con la siguiente distribución de entrada y salida.
| Tokens de entrada | Tokens de salida | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mín. | Mediana | Media | P90 | P99 | Máx. | Mín. | Mediana | Media | P90 | P99 | Máx. |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Antes de comenzar
Antes de comenzar, asegúrate de haber realizado las siguientes tareas:
- Habilita la API de Google Kubernetes Engine. Habilitar la API de Google Kubernetes Engine
- Si quieres usar Google Cloud CLI para esta tarea,
instala y, luego,
inicializa
gcloud CLI. Si ya instalaste gcloud CLI, ejecuta
gcloud components updatepara obtener la versión más reciente.
En la Google Cloud consola, en la página de selección de proyecto, selecciona o crea un Google Cloud proyecto.
Asegúrate de tener habilitada la facturación para tu Google Cloud proyecto.
Asegúrate de tener suficiente capacidad de acelerador para tu proyecto:
- Si usas GPUs, consulta la página Cuotas.
- Si usas TPUs, consulta Asegúrate de tener cuota para las TPU y otros recursos de GKE.
Genera un token de acceso de Hugging Face y un Secret de Kubernetes correspondiente, si aún no tienes uno. Para crear un Secret de Kubernetes que contenga el token de Hugging Face, ejecuta el siguiente comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACEReemplaza los siguientes valores:
- HUGGING_FACE_TOKEN: El token de Hugging Face que creaste antes.
- NAMESPACE: Es el espacio de nombres de Kubernetes en el que deseas implementar tu servidor de modelos.
Es posible que algunos modelos también requieran que aceptes y firmes su contrato de licencia de consentimiento.
Prepárate para usar la interfaz de usuario de IA/AA de GKE
Si usas la consola de Google Cloud , también debes crear un clúster de Autopilot si aún no se creó uno en tu proyecto. Sigue las instrucciones en Crea un clúster de Autopilot.
Prepárate para usar la interfaz de línea de comandos
Si usas gcloud CLI para ejecutar la guía de inicio rápido de Inference, también debes ejecutar estos comandos adicionales:
gkerecommender.googleapis.comHabilita la APIgcloud services enable gkerecommender.googleapis.comConfigura el proyecto de cuota de facturación que usas para las llamadas a la API:
gcloud config set billing/quota_project PROJECT_IDVerifica que tu versión de gcloud CLI sea al menos la 526.0.0. Ten en cuenta que no se admiten las versiones 530.0.0 y 531.0.0. Si se necesita una actualización, ejecuta el siguiente comando:
gcloud components update
Limitaciones
Ten en cuenta las siguientes limitaciones antes de comenzar a usar la guía de inicio rápido de Inference:
- La implementación de modelos de la consola deGoogle Cloud solo admite la implementación en clústeres de Autopilot.
- La guía de inicio rápido de Inference no proporciona perfiles para todos los modelos admitidos por un servidor de modelos determinado.
Cómo ver las configuraciones optimizadas para la inferencia de modelos
En esta sección, se describe cómo generar y ver recomendaciones de configuración con la consola de Google Cloud o la línea de comandos.
Console
- Haz clic en Deploy Models.
Selecciona el modelo que deseas ver. Los modelos compatibles con la guía de inicio rápido de Inference se muestran con la etiqueta Optimized.
- Si seleccionaste un modelo base, se abrirá una página del modelo. Haz clic en Implementar. Aún puedes modificar la configuración antes de la implementación real.
- Se te solicitará que crees un clúster de Autopilot si no hay uno en tu proyecto. Sigue las instrucciones en Crea un clúster de Autopilot. Después de crear el clúster, vuelve a la página de IA/AA de GKE en la consola de Google Cloud para seleccionar un modelo.
La página de implementación del modelo se completa previamente con el modelo seleccionado, así como con el servidor de modelos y el acelerador recomendados. También puedes configurar parámetros como la latencia máxima.
Para ver el manifiesto con la configuración recomendada, haz clic en Ver YAML.
gcloud
Usa el comando gcloud alpha container ai profiles para explorar y ver combinaciones optimizadas de modelo, servidor de modelos, versión del servidor de modelos y aceleradores:
Modelos
Para explorar y seleccionar un modelo, usa la opción models.
gcloud alpha container ai profiles models list
Servidores de modelos
Para explorar los servidores de modelos recomendados para el modelo que te interesa, usa la opción model-servers. Por ejemplo:
gcloud alpha container ai profiles model-servers list \
--model=meta-llama/Meta-Llama-3-8B
El resultado es similar al siguiente:
Supported model servers:
- vllm
Versiones del servidor
De manera opcional, para explorar las versiones compatibles del servidor de modelos que te interesan, usa la opción model-server-versions. Si omites este paso, la guía de inicio rápido de Inference usará la versión más reciente de forma predeterminada.
Por ejemplo:
gcloud alpha container ai profiles model-server-versions list \
--model=meta-llama/Meta-Llama-3-8B \
--model-server=vllm
El resultado es similar al siguiente:
Supported model server versions:
- e92694b6fe264a85371317295bca6643508034ef
- v0.7.2
Aceleradores
Para explorar los aceleradores recomendados para la combinación de modelo y servidor de modelos que te interesa, usa la opción accelerators.
Por ejemplo:
gcloud alpha container ai profiles accelerators list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server-version=v0.7.2
El resultado es similar al siguiente:
Supported accelerators:
accelerator | model | model server | model server version | accelerator count | output tokens per second | ntpot ms
---------------------|-----------------------------------------|--------------|------------------------------------------|-------------------|--------------------------|---------
nvidia-tesla-a100 | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | vllm | v0.7.2 | 1 | 3357 | 72
nvidia-h100-80gb | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | vllm | v0.7.2 | 1 | 6934 | 30
For more details on each accelerator, use --format=yaml
El resultado muestra una lista de tipos de aceleradores y estas métricas:
- Capacidad de procesamiento, en tokens de salida por segundo
- Tiempo normalizado por token de salida (NTPOT), en milisegundos
Los valores representan el rendimiento observado en el punto en el que el procesamiento deja de aumentar y la latencia comienza a aumentar de forma drástica (es decir, el punto de inflexión o saturación) para un perfil determinado con este tipo de acelerador. Para obtener más información sobre estas métricas de rendimiento, consulta Acerca de la inferencia del modelo en GKE.
Para obtener más opciones, consulta la documentación de Google Cloud CLI.
Después de elegir un modelo, un servidor de modelos, una versión del servidor de modelos y un acelerador, puedes continuar con la creación de un manifiesto de implementación.
Implementa los parámetros de configuración recomendados
En esta sección, se describe cómo generar y, luego, implementar recomendaciones de configuración con la consola de Google Cloud o la línea de comandos.
Console
- Haz clic en Deploy Models.
Selecciona un modelo que quieras implementar. Los modelos compatibles con la guía de inicio rápido de Inference se muestran con la etiqueta Optimized.
- Si seleccionaste un modelo base, se abrirá una página del modelo. Haz clic en Implementar. Aún puedes modificar la configuración antes de la implementación real.
- Se te solicitará que crees un clúster de Autopilot si no hay uno en tu proyecto. Sigue las instrucciones en Crea un clúster de Autopilot. Después de crear el clúster, vuelve a la página de IA/AA de GKE en la consola de Google Cloud para seleccionar un modelo.
La página de implementación del modelo se completa previamente con el modelo seleccionado, así como con el servidor de modelos y el acelerador recomendados. También puedes configurar parámetros como la latencia máxima.
(Opcional) Para ver el manifiesto con la configuración recomendada, haz clic en Ver YAML.
Para implementar el manifiesto con la configuración recomendada, haz clic en Implementar. La operación de implementación puede tardar varios minutos en completarse.
Para ver tu implementación, ve a la página Kubernetes Engine > Cargas de trabajo.
gcloud
Genera manifiestos: En la terminal, usa la opción
manifestspara generar manifiestos de Deployment, Service y PodMonitoring:gcloud alpha container ai profiles manifests createUsa los parámetros obligatorios
--model,--model-servery--accelerator-typepara personalizar tu manifiesto.De manera opcional, puedes establecer estos parámetros:
--target-ntpot-milliseconds: Establece este parámetro para especificar tu umbral de HPA. Este parámetro te permite definir un umbral de ajuste para mantener la latencia del percentil 50 del tiempo normalizado por token de salida (NTPOT) por debajo del valor especificado. Elige un valor superior a la latencia mínima de tu acelerador. El HPA se configura para lograr la capacidad de procesamiento máxima si especificas un valor de NTPOT superior a la latencia máxima de tu acelerador. Por ejemplo:gcloud alpha container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--model-server-version: Es la versión del servidor del modelo. Si no se especifica, se usará la versión más reciente de forma predeterminada.--namespace: Es el espacio de nombres en el que se implementarán los manifiestos. El espacio de nombres predeterminado es "default".--output: Los valores válidos incluyenmanifest,commentsyall. De forma predeterminada, este parámetro se establece enall. Puedes elegir generar solo el manifiesto para implementar cargas de trabajo o solo los comentarios si deseas ver instrucciones para habilitar funciones.--output-path: Si se especifica, el resultado se guarda en la ruta de acceso proporcionada, en lugar de imprimirse en la terminal, para que puedas editarlo antes de implementarlo. Por ejemplo, puedes usar esta opción con--output=manifestsi deseas guardar tu manifiesto en un archivo YAML. Por ejemplo:gcloud alpha container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Para obtener más opciones, consulta la documentación de Google Cloud CLI.
Aprovisiona tu infraestructura: Asegúrate de que tu infraestructura esté configurada correctamente para la implementación, la supervisión y el ajuste de escala del modelo. Para ello, sigue estos pasos de aprovisionamiento.
Implementa los manifiestos: Ejecuta el comando
kubectl applyy pasa el archivo YAML para tus manifiestos. Por ejemplo:kubectl apply -f ./manifests.yaml
Aprovisiona tu infraestructura
Sigue estos pasos para asegurarte de que tu infraestructura esté configurada correctamente para la implementación, la supervisión y el escalamiento de modelos:
Crea un clúster: Puedes entregar tu modelo en clústeres de GKE Autopilot o Standard. Te recomendamos que uses un clúster de Autopilot para una experiencia de Kubernetes completamente administrada. Para elegir el modo de operación de GKE que se adapte mejor a tus cargas de trabajo, consulta Elige un modo de operación de GKE.
Si no tienes un clúster existente, sigue estos pasos:
Autopilot
Sigue estas instrucciones para crear un clúster de Autopilot. GKE se encarga de aprovisionar los nodos con capacidad de GPU o TPU según los manifiestos de implementación, si tienes la cuota necesaria en tu proyecto.
Estándar
- Crea un clúster zonal o regional.
Crea un grupo de nodos con los aceleradores adecuados. Sigue estos pasos según el tipo de acelerador que elijas:
- GPUs: Primero, consulta la página Cuotas en la consola de Google Cloud para asegurarte de tener suficiente capacidad de GPU. Luego, sigue las instrucciones en Crea un grupo de nodos de GPU.
- TPUs: Primero, asegúrate de tener suficientes TPUs siguiendo las instrucciones en Asegúrate de tener cuota para las TPU y otros recursos de GKE. Luego, continúa con Crea un nodo TPU TPU.
(Opcional, pero recomendado) Habilita las funciones de observabilidad: En la sección de comentarios del manifiesto generado, se proporcionan comandos adicionales para habilitar las funciones de observabilidad sugeridas. Habilitar estas funciones proporciona más estadísticas para ayudarte a supervisar el rendimiento y el estado de las cargas de trabajo y la infraestructura subyacente.
El siguiente es un ejemplo de un comando para habilitar las funciones de observabilidad:
gcloud beta container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLPara obtener más información, consulta Supervisa tus cargas de trabajo de inferencia.
(Solo para HPA) Implementa un adaptador de métricas: Se necesita un adaptador de métricas, como el adaptador de métricas personalizadas de Stackdriver, si se generaron recursos de HPA en los manifiestos de implementación. El adaptador de métricas permite que el HPA acceda a las métricas del servidor del modelo que usan la API de métricas externas de kube. Para implementar el adaptador, consulta la documentación del adaptador en GitHub.
Prueba tus extremos de implementación
Si implementaste el manifiesto con la línea de comandos, el servicio implementado se expone en el siguiente extremo:
http://model-model_server-service:port/
Prueba tu servicio. En una terminal separada, ejecuta el siguiente comando para configurar la redirección de puertos:
kubectl port-forward service/model-model_server-service 8000:8000
Para ver ejemplos de cómo compilar y enviar una solicitud a tu extremo, consulta la documentación de vLLM.
Supervisa tus cargas de trabajo de inferencia
Para supervisar las cargas de trabajo de inferencia implementadas, ve al Explorador de métricas en la Google Cloud consola.
Habilita la supervisión automática
GKE incluye una función de supervisión automática que forma parte de las funciones de observabilidad más amplias. Esta función analiza el clúster en busca de cargas de trabajo que se ejecuten en servidores de modelos compatibles y, luego, implementa los recursos PodMonitoring que permiten que las métricas de estas cargas de trabajo sean visibles en Cloud Monitoring. Para obtener más información sobre cómo habilitar y configurar la supervisión automática, consulta Configura la supervisión automática de aplicaciones para cargas de trabajo.
Después de habilitar la función, GKE instala paneles prediseñados para supervisar aplicaciones para cargas de trabajo compatibles.
Si realizas la implementación desde la página de IA/ML de GKE en la Google Cloud consola, los recursos de PodMonitoring y HPA se crearán automáticamente para ti con la configuración detargetNtpot.
Soluciona problemas
- Si estableces la latencia demasiado baja, es posible que la guía de inicio rápido de Inference no genere una recomendación. Para solucionar este problema, selecciona un objetivo de latencia entre la latencia mínima y máxima que se observó para los aceleradores seleccionados.
- La guía de inicio rápido de Inference existe independientemente de los componentes de GKE, por lo que la versión de tu clúster no es directamente relevante para usar el servicio. Sin embargo, recomendamos usar un clúster nuevo o actualizado para evitar discrepancias en el rendimiento.
- Si recibes un error
PERMISSION_DENIEDpara los comandos degkerecommender.googleapis.comque indica que falta un proyecto de cuota, debes configurarlo de forma manual. Ejecutagcloud config set billing/quota_project PROJECT_IDpara corregir este problema.
¿Qué sigue?
- Visita el portal de organización de IA/AA en GKE para explorar nuestras guías, instructivos y casos de uso oficiales para ejecutar cargas de trabajo de IA/AA en GKE.
- Para obtener más información sobre la optimización de la entrega de modelos, consulta Prácticas recomendadas para optimizar la inferencia de modelos de lenguaje grandes con GPUs. Abarca las prácticas recomendadas para la entrega de LLM con GPU en GKE, como la cuantización, el paralelismo de tensor y la administración de memoria.
- Para obtener más información sobre las prácticas recomendadas para el ajuste de escala automático, consulta estas guías:
- Explora muestras experimentales para aprovechar GKE y acelerar tus iniciativas de IA/AA en GKE AI Labs.