En este documento se describe cómo configurar Google Cloud Managed Service para Prometheus con la recogida gestionada. La configuración es un ejemplo mínimo de ingesta que funciona. Utiliza una implementación de Prometheus que monitoriza una aplicación de ejemplo y almacena las métricas recogidas en Monarch.
En este documento se explica cómo hacer lo siguiente:
- Configura tu entorno y tus herramientas de línea de comandos.
- Configura la recogida gestionada de tu clúster.
- Configura un recurso para el raspado de datos y la ingestión de métricas de los destinos.
- Migra los recursos personalizados de prometheus-operator.
Te recomendamos que uses la colección gestionada, ya que reduce la complejidad de desplegar, escalar, fragmentar, configurar y mantener los colectores. La recogida gestionada se admite en GKE y en todos los demás entornos de Kubernetes.
La recogida gestionada ejecuta recopiladores basados en Prometheus como un DaemonSet y garantiza la escalabilidad al extraer solo los destinos de los nodos colocados. Los colectores se configuran con recursos personalizados ligeros para extraer datos de los exportadores mediante la recogida de datos por extracción. A continuación, los colectores envían los datos extraídos al almacén de datos central Monarch. Google Cloud nunca accede directamente a tu clúster para extraer datos de métricas. Tus colectores envían datos aGoogle Cloud. Para obtener más información sobre la recogida de datos gestionada y autodesplegada, consulta Recogida de datos con Managed Service para Prometheus y Ingestión y consultas con la recogida gestionada y autodesplegada.
Antes de empezar
En esta sección se describe la configuración necesaria para las tareas que se indican en este documento.
Configurar proyectos y herramientas
Para usar Google Cloud Managed Service para Prometheus, necesitas los siguientes recursos:
Un Google Cloud proyecto con la API de Cloud Monitoring habilitada.
Si no tienes ningún Google Cloud proyecto, haz lo siguiente:
En la Google Cloud consola, ve a Nuevo proyecto:
En el campo Nombre del proyecto, escribe el nombre que quieras darle al proyecto y, a continuación, haz clic en Crear.
Ve a Facturación:
Selecciona el proyecto que acabas de crear si aún no está seleccionado en la parte superior de la página.
Se te pedirá que elijas un perfil de pagos o que crees uno.
La API Monitoring está habilitada de forma predeterminada en los proyectos nuevos.
Si ya tienes un Google Cloud proyecto, asegúrate de que la API Monitoring esté habilitada:
Vaya a APIs y servicios:
Selecciona el proyecto.
Haz clic en Habilitar APIs y servicios.
Busca "Monitorización".
En los resultados de búsqueda, haz clic en "API Cloud Monitoring".
Si no se muestra "API habilitada", haz clic en el botón Habilitar.
Un clúster de Kubernetes. Si no tienes un clúster de Kubernetes, sigue las instrucciones de la guía de inicio rápido de GKE.
También necesitas las siguientes herramientas de línea de comandos:
gcloudkubectl
Las herramientas gcloud y kubectl forman parte de Google Cloud CLI. Para obtener información sobre cómo instalarlos, consulta Gestionar componentes de Google Cloud CLI. Para ver los componentes de la CLI de gcloud que tienes instalados, ejecuta el siguiente comando:
gcloud components list
Configurar el entorno
Para no tener que introducir repetidamente el ID del proyecto o el nombre del clúster, haz la siguiente configuración:
Configura las herramientas de línea de comandos de la siguiente manera:
Configura gcloud CLI para que haga referencia al ID de tu proyectoGoogle Cloud :
gcloud config set project PROJECT_ID
Configura la CLI de
kubectlpara que use tu clúster:kubectl config set-cluster CLUSTER_NAME
Para obtener más información sobre estas herramientas, consulta los siguientes artículos:
- Información general sobre la CLI de gcloud
- Comandos de
kubectl
Configurar un espacio de nombres
Crea el espacio de nombres de Kubernetes NAMESPACE_NAME para los recursos que crees
como parte de la aplicación de ejemplo:
kubectl create ns NAMESPACE_NAME
Configurar la recogida gestionada
Puedes usar la recogida gestionada en clústeres de Kubernetes de GKE y que no sean de GKE.
Una vez que se haya habilitado la recogida gestionada, los componentes del clúster se ejecutarán, pero aún no se habrán generado métricas. Estos componentes necesitan recursos de PodMonitoring o ClusterPodMonitoring para extraer correctamente los endpoints de métricas. Debe desplegar estos recursos con endpoints de métricas válidos o habilitar uno de los paquetes de métricas gestionados, como métricas de estado de Kube, integrado en GKE. Para obtener información sobre cómo solucionar problemas, consulta Problemas del lado de la ingestión.
Si habilitas la colección gestionada, se instalarán los siguientes componentes en tu clúster:
- El
gmp-operatorDeployment, que despliega el operador de Kubernetes para Managed Service para Prometheus. - El
rule-evaluatordespliegue, que se usa para configurar y ejecutar reglas de alertas y de grabación. - El DaemonSet
collector, que escala horizontalmente la recogida obteniendo métricas solo de los pods que se ejecutan en el mismo nodo que cada recolector. - El StatefulSet
alertmanager, que está configurado para enviar alertas activadas a los canales de notificación que prefieras.
Para consultar la documentación de referencia sobre el operador de Managed Service para Prometheus, consulta la página de manifiestos.
Habilitar la recogida gestionada: GKE
La recogida gestionada está habilitada de forma predeterminada en los siguientes casos:
Clústeres de Autopilot de GKE que ejecuten la versión 1.25 de GKE o una posterior.
Clústeres de GKE Standard con la versión 1.27 de GKE o una posterior. Puedes anular este valor predeterminado al crear el clúster. Consulta Inhabilitar la recogida gestionada.
Si estás ejecutando en un entorno de GKE que no habilita la recogida gestionada de forma predeterminada, consulta Habilitar la recogida gestionada manualmente.
La recogida gestionada en GKE se actualiza automáticamente cuando se lanzan nuevas versiones de componentes en el clúster.
La colección gestionada en GKE usa los permisos concedidos a la cuenta de servicio predeterminada de Compute Engine. Si tienes una política que modifica los permisos estándar de la cuenta de servicio del nodo predeterminada, es posible que tengas que añadir el rol Monitoring Metric Writer para continuar.
Habilitar la recogida gestionada manualmente
Si estás en un entorno de GKE que no habilita la recogida gestionada de forma predeterminada, puedes habilitarla de las siguientes formas:
- El panel de control Habilitación masiva de clústeres de Prometheus gestionado en Cloud Monitoring.
- La página Kubernetes Engine de la Google Cloud consola.
- Google Cloud CLI. Para usar la CLI de gcloud, debes ejecutar la versión 1.21.4-gke.300 de GKE o una posterior.
Terraform para Google Kubernetes Engine. Para usar Terraform y habilitar Managed Service para Prometheus, debes ejecutar la versión 1.21.4-gke.300 de GKE o una posterior.
Panel de control de habilitación masiva de clústeres de Prometheus gestionado
Para ello, puedes usar el panel de control Habilitación en bloque de clústeres de Prometheus gestionado de Cloud Monitoring.
- Determina si Managed Service para Prometheus está habilitado en tus clústeres y si estás usando la recogida gestionada o la autodesplegada.
- Habilita la recogida gestionada en los clústeres de tu proyecto.
- Consulta otra información sobre tus clústeres.
Para ver el panel de control Habilitación masiva de clústeres de Prometheus gestionado, haga lo siguiente:
-
En la Google Cloud consola, ve a la página
 Paneles de control:
Paneles de control:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuya sección sea Monitorización.
Usa la barra de filtros para buscar la entrada Habilitación masiva de clústeres de Prometheus gestionados y, a continuación, selecciónala.
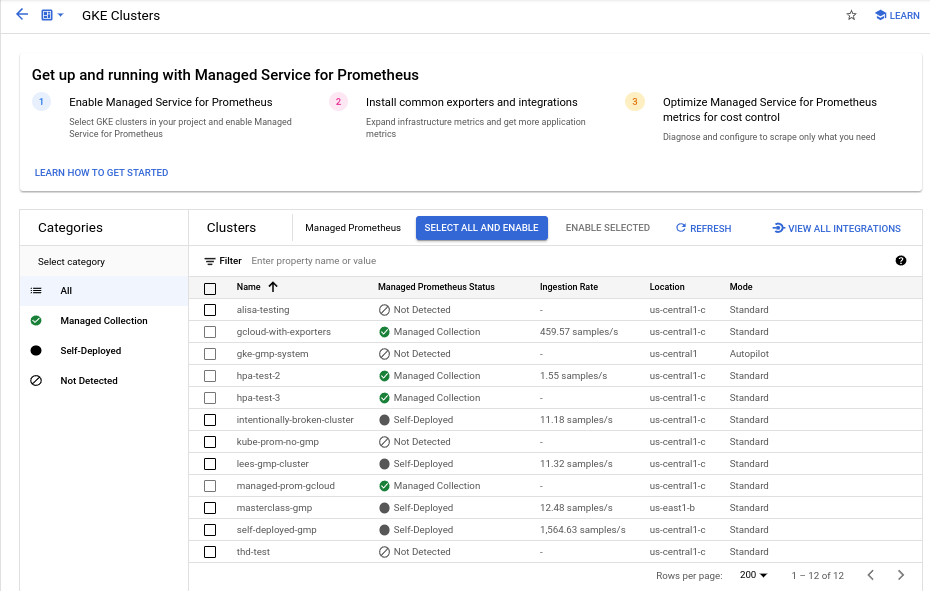
Para habilitar la recogida gestionada en uno o varios clústeres de GKE mediante el panel de control Habilitación masiva de clústeres de Prometheus gestionado, sigue estos pasos:
Marca la casilla de cada clúster de GKE en el que quieras habilitar la recogida gestionada.
Selecciona Habilitar seleccionados.
Interfaz de usuario de Kubernetes Engine
Para ello, sigue estos pasos en la consola Google Cloud :
- Habilita la recogida gestionada en un clúster de GKE.
- Crea un clúster de GKE con la recogida gestionada habilitada.
Para actualizar un clúster, sigue estos pasos:
-
En la Google Cloud consola, ve a la página Clústeres de Kubernetes:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo sea Kubernetes Engine.
Haz clic en el nombre del clúster.
En la lista Funciones, busca la opción Managed Service para Prometheus. Si aparece como inhabilitado, haz clic en edit Editar y, a continuación, selecciona Habilitar Managed Service for Prometheus.
Haz clic en Guardar cambios.
Para crear un clúster con la recogida gestionada habilitada, sigue estos pasos:
-
En la Google Cloud consola, ve a la página Clústeres de Kubernetes:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo sea Kubernetes Engine.
Haz clic en Crear.
Haz clic en Configurar en la opción Estándar.
En el panel de navegación, haz clic en Funciones.
En la sección Operaciones, selecciona Habilitar servicio gestionado para Prometheus.
Haz clic en Guardar.
CLI de gcloud
Puedes hacer lo siguiente con gcloud CLI:
- Habilita la recogida gestionada en un clúster de GKE.
- Crea un clúster de GKE con la recogida gestionada habilitada.
Estos comandos pueden tardar hasta 5 minutos en completarse.
Primero, configura tu proyecto:
gcloud config set project PROJECT_ID
Para actualizar un clúster, ejecuta uno de los siguientes comandos de update en función de si el clúster es zonal o regional:
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
Para crear un clúster con la recogida gestionada habilitada, ejecuta el siguiente comando:
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
Autopilot de GKE
La recogida gestionada está activada de forma predeterminada en los clústeres de Autopilot de GKE que ejecutan la versión 1.25 de GKE o una posterior. No puedes desactivar la recogida gestionada.
Si tu clúster no habilita la recogida gestionada automáticamente al actualizar a la versión 1.25, puedes habilitarla manualmente ejecutando el comando de actualización en la sección de la CLI de gcloud.
Terraform
Para obtener instrucciones sobre cómo configurar la recogida gestionada con Terraform, consulta el registro de Terraform para google_container_cluster.
Para obtener información general sobre el uso de Google Cloud con Terraform, consulta Terraform con Google Cloud.
Inhabilitar la recogida gestionada
Si quieres inhabilitar la recogida gestionada en tus clústeres, puedes usar uno de los siguientes métodos:
Interfaz de usuario de Kubernetes Engine
Para ello, sigue estos pasos en la consola Google Cloud :
- Inhabilita la recogida gestionada en un clúster de GKE.
- Anula la habilitación automática de la recogida gestionada al crear un clúster estándar de GKE con la versión 1.27 de GKE o una posterior.
Para actualizar un clúster, sigue estos pasos:
-
En la Google Cloud consola, ve a la página Clústeres de Kubernetes:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo sea Kubernetes Engine.
Haz clic en el nombre del clúster.
En la sección Funciones, busca la opción Managed Service para Prometheus. Haz clic en edit Editar y desmarca Habilitar Managed Service para Prometheus.
Haz clic en Guardar cambios.
Para anular la habilitación automática de la recogida gestionada al crear un clúster estándar de GKE (versión 1.27 o posterior), sigue estos pasos:
-
En la Google Cloud consola, ve a la página Clústeres de Kubernetes:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo sea Kubernetes Engine.
Haz clic en Crear.
Haz clic en Configurar en la opción Estándar.
En el panel de navegación, haz clic en Funciones.
En la sección Operaciones, desmarca Habilitar Managed Service para Prometheus.
Haz clic en Guardar.
CLI de gcloud
Puedes hacer lo siguiente con gcloud CLI:
- Inhabilita la recogida gestionada en un clúster de GKE.
- Anula la habilitación automática de la recogida gestionada al crear un clúster estándar de GKE con la versión 1.27 de GKE o una posterior.
Estos comandos pueden tardar hasta 5 minutos en completarse.
Primero, configura tu proyecto:
gcloud config set project PROJECT_ID
Para inhabilitar la recogida gestionada en un clúster, ejecuta uno de los siguientes comandos update en función de si el clúster es zonal o regional:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
Para anular la habilitación automática de la recogida gestionada al crear un clúster estándar de GKE (versión 1.27 o posterior), ejecuta el siguiente comando:
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
Autopilot de GKE
No puedes desactivar la recogida gestionada en los clústeres de Autopilot de GKE que ejecuten la versión 1.25 de GKE o una posterior.
Terraform
Para inhabilitar la recogida gestionada, asigna el valor false al atributo enabled en el bloque de configuración managed_prometheus. Para obtener más información sobre este bloque de configuración, consulta el registro de Terraform de google_container_cluster.
Para obtener información general sobre el uso de Google Cloud con Terraform, consulta Terraform con Google Cloud.
Habilitar la recogida gestionada: Kubernetes que no sea de GKE
Si se ejecuta en un entorno que no es de GKE, puede habilitar la recogida gestionada de la siguiente manera:
- La CLI
kubectl. Implementaciones on-premise de VMware o bare metal con la versión 1.12 o posterior.
kubectl CLI
Para instalar recopiladores gestionados cuando utilices un clúster de Kubernetes que no sea de GKE, ejecuta los siguientes comandos para instalar los manifiestos de configuración y del operador:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
On‑premise
Para obtener información sobre cómo configurar la recogida gestionada en clústeres locales, consulta la documentación de tu distribución:
Desplegar la aplicación de ejemplo
La aplicación de ejemplo emite la métrica de contador example_requests_total y la métrica de histograma example_random_numbers (entre otras) en su puerto metrics. El archivo de manifiesto de la aplicación define tres réplicas.
Para desplegar la aplicación de ejemplo, ejecuta el siguiente comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Configura un recurso de PodMonitoring
Para ingerir los datos de métricas emitidos por la aplicación de ejemplo, Managed Service para Prometheus usa el raspado de destinos. El raspado de datos y la ingestión de métricas de los destinos seleccionados se configuran con recursos personalizados de Kubernetes. El servicio gestionado usa recursos propios de PodMonitoring.
Un CR de PodMonitoring solo raspa los objetivos del espacio de nombres en el que se ha implementado el CR.
Para raspar destinos en varios espacios de nombres, implemente el mismo CR de PodMonitoring en cada espacio de nombres. Para comprobar que el recurso PodMonitoring se ha instalado en el espacio de nombres previsto, ejecuta kubectl get podmonitoring -A.
Para consultar la documentación de referencia sobre todos los CRs de Managed Service for Prometheus, consulta la referencia de la API de prometheus-engine/doc.
El siguiente manifiesto define un recurso de PodMonitoring, prom-example, en el espacio de nombres NAMESPACE_NAME. El recurso usa un selector de etiquetas de Kubernetes para encontrar todos los pods del espacio de nombres que tengan la etiqueta app.kubernetes.io/name con el valor prom-example.
Los pods coincidentes se rastrean en un puerto llamado metrics cada 30 segundos en la ruta HTTP /metrics.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
Para aplicar este recurso, ejecuta el siguiente comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
Tu recolector gestionado ahora está obteniendo datos de los pods coincidentes. Para ver el estado de tu objetivo de raspado, habilita la función de estado del objetivo.
Para configurar la recogida horizontal que se aplica a un intervalo de pods en todos los espacios de nombres, usa el recurso ClusterPodMonitoring. El recurso ClusterPodMonitoring proporciona la misma interfaz que el recurso PodMonitoring, pero no limita los pods descubiertos a un espacio de nombres concreto.
Si utilizas GKE, puedes hacer lo siguiente:
- Para consultar las métricas ingeridas por la aplicación de ejemplo mediante PromQL en Cloud Monitoring, consulta Consultar con Cloud Monitoring.
- Para consultar las métricas insertadas por la aplicación de ejemplo con Grafana, consulta Consultar con Grafana o cualquier consumidor de la API de Prometheus.
- Para obtener información sobre cómo filtrar las métricas exportadas y adaptar los recursos de prom-operator, consulta Temas adicionales sobre la recogida gestionada.
Si no usas GKE, debes crear una cuenta de servicio y autorizarla para que escriba tus datos de métricas, tal como se describe en la siguiente sección.
Proporcionar credenciales explícitamente
Cuando se ejecuta en GKE, el servidor de Prometheus que recoge datos obtiene automáticamente las credenciales del entorno en función de la cuenta de servicio del nodo. En los clústeres de Kubernetes que no sean de GKE, las credenciales deben proporcionarse explícitamente a través del recurso OperatorConfig en el espacio de nombres gmp-public.
Define el contexto de tu proyecto de destino:
gcloud config set project PROJECT_ID
Crea una cuenta de servicio:
gcloud iam service-accounts create gmp-test-sa
Concede los permisos necesarios a la cuenta de servicio:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Crea y descarga una clave para la cuenta de servicio:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Añade el archivo de claves como secreto a tu clúster que no sea de GKE:
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Abre el recurso OperatorConfig para editarlo:
kubectl -n gmp-public edit operatorconfig config
Añade el texto que se muestra en negrita al recurso:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonrulespara que funcione la evaluación de reglas gestionadas.Guarda el archivo y cierra el editor. Una vez aplicado el cambio, los pods se vuelven a crear y empiezan a autenticarse en el backend de métricas con la cuenta de servicio proporcionada.
Temas adicionales sobre colecciones gestionadas
En esta sección se describe cómo hacer lo siguiente:
- Habilita la función de estado del objetivo para facilitar la depuración.
- Configura el raspado de destinos con Terraform.
- Filtra los datos que exportas al servicio gestionado.
- Recoge métricas de Kubelet y cAdvisor.
- Convierte tus recursos de prom-operator para usarlos con el servicio gestionado.
- Ejecutar colecciones gestionadas fuera de GKE.
Habilitar la función de estado del objetivo
Managed Service para Prometheus ofrece una forma de comprobar si los recopiladores descubren y raspan correctamente tus destinos. Este informe de estado de destino se ha diseñado para ayudarte a depurar problemas graves. Le recomendamos que habilite esta función solo para investigar problemas inmediatos. Si dejas activado el informe de estado de destino en clústeres grandes, es posible que el operador se quede sin memoria y entre en un bucle de fallos.
Para comprobar el estado de tus destinos en los recursos de PodMonitoring o ClusterPodMonitoring, asigna el valor
trueafeatures.targetStatus.enableden el recurso de OperatorConfig, como se muestra a continuación:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: trueAl cabo de unos segundos, el campo
Status.Endpoint Statusesaparece en todos los recursos de PodMonitoring o ClusterPodMonitoring válidos, cuando se configuran.Si tienes un recurso PodMonitoring con el nombre
prom-exampleen el espacio de nombresNAMESPACE_NAME, puedes comprobar el estado ejecutando el siguiente comando:kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
La salida tiene este aspecto:
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887La salida incluye los siguientes campos de estado:
Status.Conditions.Statuses true cuando el servicio gestionado de Prometheus reconoce y procesa el PodMonitoring o el ClusterPodMonitoring.Status.Endpoint Statuses.Active Targetsmuestra el número de destinos de raspado que Managed Service para Prometheus cuenta en todos los recopiladores de este recurso PodMonitoring. En la aplicación de ejemplo, laprom-exampleimplementación tiene tres réplicas con un único objetivo de métrica, por lo que el valor es3. Si hay destinos no operativos, aparece el campoStatus.Endpoint Statuses.Unhealthy Targets.Status.Endpoint Statuses.Collectors Fractionmuestra el valor1(es decir, el 100%) si Managed Service para Prometheus puede acceder a todos los recopiladores gestionados.Status.Endpoint Statuses.Last Update Timemuestra la hora de la última actualización. Si la hora de la última actualización es significativamente mayor que el tiempo de intervalo de raspado que has definido, la diferencia puede indicar que hay problemas con tu destino o clúster.- El campo
Status.Endpoint Statuses.Sample Groupsmuestra las muestras de destino agrupadas por etiquetas de destino comunes insertadas por el recolector. Este valor es útil para depurar situaciones en las que no se descubren sus objetivos. Si todos los destinos están en buen estado y se están recogiendo datos, el valor esperado del campoHealthesupy el valor del campoLast Scrape Duration Secondses la duración habitual de un destino típico.
Para obtener más información sobre estos campos, consulta el documento de la API Managed Service for Prometheus.
Cualquiera de los siguientes elementos puede indicar que hay un problema con tu configuración:
- No hay ningún campo
Status.Endpoint Statusesen tu recurso PodMonitoring. - El valor del campo
Last Scrape Duration Secondses demasiado antiguo. - Ves muy pocos objetivos.
- El valor del campo
Healthindica que el destino esdown.
Para obtener más información sobre cómo depurar problemas de detección de destinos, consulta la sección Problemas del lado de la ingestión de la documentación sobre solución de problemas.
Configurar un endpoint de raspado autorizado
Si el destino de raspado requiere autorización, puede configurar el recolector para que use el tipo de autorización correcto y proporcione los secretos pertinentes.
Google Cloud Managed Service para Prometheus admite los siguientes tipos de autorización:
mTLS
mTLS se suele configurar en entornos de confianza cero, como la malla de servicios de Istio o Cloud Service Mesh.
Para habilitar los endpoints de raspado protegidos con mTLS, asigna el valor
httpsal campoSpec.Endpoints[].Schemede tu recurso PodMonitoring. Aunque no es recomendable, puedes definir el campoSpec.Endpoints[].tls.insecureSkipVerifyen tu recurso PodMonitoring comotruepara omitir la verificación de la autoridad del certificado. También puede configurar Managed Service para Prometheus para que cargue certificados y claves de recursos secretos.Por ejemplo, el siguiente recurso Secret contiene claves para los certificados de cliente (
cert), clave privada (key) y autoridad de certificación (ca):kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
Concede al recopilador de Managed Service para Prometheus permiso para acceder a ese recurso Secret:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
En los clústeres de Autopilot de GKE, el aspecto es el siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar un recurso de PodMonitoring que use el recurso de Secret anterior, modifica el recurso para añadir las secciones
schemeytls:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: keyPara consultar la documentación de referencia sobre todas las opciones de mTLS de Managed Service for Prometheus, consulta la documentación de referencia de la API.
BasicAuth
Para habilitar los endpoints de scraping protegidos con BasicAuth, defina el campo
Spec.Endpoints[].BasicAuthde su recurso PodMonitoring con su nombre de usuario y contraseña. Para ver otros tipos de encabezado de autorización HTTP, consulta Encabezado de autorización HTTP.Por ejemplo, el siguiente recurso Secret contiene una clave para almacenar la contraseña:
kind: Secret metadata: name: secret-example stringData: password: ********
Concede al recopilador de Managed Service para Prometheus permiso para acceder a ese recurso Secret:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
En los clústeres de Autopilot de GKE, el aspecto es el siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar un recurso de PodMonitoring que use el recurso de Secret anterior y el nombre de usuario
foo, modifica el recurso para añadir una secciónbasicAuth:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: passwordPara consultar la documentación de referencia sobre todas las opciones de BasicAuth de Managed Service for Prometheus, consulta la documentación de referencia de la API.
Encabezado de autorización HTTP
Para habilitar los endpoints de raspado protegidos mediante encabezados de autorización HTTP, define el campo
Spec.Endpoints[].Authorizationen tu recurso PodMonitoring con el tipo y las credenciales. Para los endpoints de BasicAuth, usa la configuración de BasicAuth.Por ejemplo, el siguiente recurso Secret contiene una clave para almacenar las credenciales:
kind: Secret metadata: name: secret-example stringData: credentials: ********
Concede al recopilador de Managed Service para Prometheus permiso para acceder a ese recurso Secret:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
En los clústeres de Autopilot de GKE, el aspecto es el siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar un recurso de PodMonitoring que use el recurso de Secret anterior y un tipo
Bearer, modifica el recurso para añadir una secciónauthorization:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentialsPara consultar la documentación de referencia sobre todas las opciones del encabezado de autorización HTTP de Managed Service for Prometheus, consulta la documentación de referencia de la API.
OAuth 2
Para habilitar los endpoints de raspado protegidos con OAuth 2, debes definir el campo
Spec.Endpoints[].OAuth2en tu recurso PodMonitoring.Por ejemplo, el siguiente recurso Secret contiene una clave para almacenar el secreto del cliente:
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
Concede al recopilador de Managed Service para Prometheus permiso para acceder a ese recurso Secret:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
En los clústeres de Autopilot de GKE, el aspecto es el siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Para configurar un recurso de PodMonitoring que use el recurso de Secret anterior con un ID de cliente
fooy una URL de tokenexample.com/token, modifica el recurso para añadir una secciónoauth2:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/tokenPara consultar la documentación de referencia sobre todas las opciones de OAuth 2 de Managed Service for Prometheus, consulta la documentación de referencia de la API.
Configurar el raspado de destinos con Terraform
Puedes automatizar la creación y la gestión de recursos de PodMonitoring y de ClusterPodMonitoring si usas los tipos de recurso de Terraform
kubernetes_manifestokubectl_manifest, que te permiten especificar recursos personalizados arbitrarios.Para obtener información general sobre el uso de Google Cloud con Terraform, consulta Terraform con Google Cloud.
Filtrar métricas exportadas
Si recoges muchos datos, puede que quieras evitar que se envíen algunas series temporales a Managed Service para Prometheus para reducir los costes. Para ello, puedes usar reglas de reetiquetado de Prometheus con una acción
keeppara una lista de permitidos o una accióndroppara una lista de denegados. En el caso de las colecciones gestionadas, esta regla se incluye en la secciónmetricRelabelingdel recurso PodMonitoring o ClusterPodMonitoring.Por ejemplo, la siguiente regla de cambio de nombre de métrica filtrará cualquier métrica que empiece por
foo_bar_,foo_baz_ofoo_qux_:metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]La página Gestión de métricas de Cloud Monitoring proporciona información que puede ayudarte a controlar el importe que gastas en métricas facturables sin que esto afecte a la observabilidad. En la página Gestión de métricas se muestra la siguiente información:
- Volúmenes de ingesta para la facturación basada en bytes y en muestras, en todos los dominios de métricas y para métricas concretas.
- Datos sobre las etiquetas y la cardinalidad de las métricas.
- Número de lecturas de cada métrica.
- Uso de métricas en políticas de alertas y paneles de control personalizados.
- Tasa de errores de escritura de métricas.
También puede usar la página Gestión de métricas para excluir las métricas que no necesite y, de esta forma, no incurrir en los costes de ingesta. Para obtener más información sobre la página Gestión de métricas, consulta el artículo Ver y gestionar el uso de métricas.
Para obtener más sugerencias sobre cómo reducir los costes, consulta Controles de costes y atribución.
Recogida de métricas de Kubelet y cAdvisor
Kubelet expone métricas sobre sí mismo, así como métricas de cAdvisor sobre los contenedores que se ejecutan en su nodo. Puedes configurar la recogida gestionada para monitorizar las métricas de Kubelet y cAdvisor editando el recurso OperatorConfig. Para obtener instrucciones, consulta la documentación del exportador de Kubelet y cAdvisor.
Convertir recursos de prometheus-operator
Normalmente, puedes convertir tus recursos de prometheus-operator en recursos de PodMonitoring y ClusterPodMonitoring de recogida gestionada de Managed Service para Prometheus.
Por ejemplo, el recurso ServiceMonitor define la monitorización de un conjunto de servicios. El recurso PodMonitoring ofrece un subconjunto de los campos que ofrece el recurso ServiceMonitor. Puede convertir un CR de ServiceMonitor en un CR de PodMonitoring asignando los campos tal como se describe en la siguiente tabla:
monitoring.coreos.com/v1
ServiceMonitorCompatibilidad
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.SelectorIdéntico .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPortse asigna a.Port
.Path: compatible
.Interval: compatible
.Timeout: compatible.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsPodMonitor debe especificar lo siguiente:
.FromPod[].Frometiqueta de pod
.FromPod[].Toetiqueta de destino.PodMonitoringSpec.TargetLabelsA continuación, se muestra un ejemplo de CR de ServiceMonitor. El contenido en negrita se sustituye en la conversión, mientras que el contenido en cursiva se asigna directamente:
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - fooA continuación se muestra el CR de PodMonitoring análogo, suponiendo que tu servicio y sus pods tengan la etiqueta
app=example-app. Si no se cumple esta condición, debes usar los selectores de etiquetas del recurso Service subyacente.El contenido en negrita se ha sustituido en la conversión:
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: fooSiempre puedes seguir usando tus recursos y configuraciones de implementación de prometheus-operator con recopiladores autodesplegados en lugar de recopiladores gestionados. Puedes consultar las métricas enviadas desde ambos tipos de recopiladores, por lo que te recomendamos que utilices recopiladores autodesplegados para tus despliegues de Prometheus actuales y recopiladores gestionados para los nuevos.
Etiquetas reservadas
Managed Service para Prometheus añade automáticamente las siguientes etiquetas a todas las métricas recogidas. Estas etiquetas se usan para identificar de forma única un recurso en Monarch:
project_id: identificador del Google Cloud proyecto asociado a tu métrica.location: la ubicación física (Google Cloud región) donde se almacenan los datos. Este valor suele ser la región de tu clúster de GKE. Si los datos se recogen de una implementación de AWS o local, el valor puede ser la región de Google Cloud más cercana.cluster: nombre del clúster de Kubernetes asociado a la métrica.namespace: nombre del espacio de nombres de Kubernetes asociado a la métrica.job: la etiqueta de trabajo del destino de Prometheus, si se conoce. Puede estar vacía en los resultados de la evaluación de reglas.instance: etiqueta de instancia del destino de Prometheus, si se conoce. Puede estar vacía en los resultados de la evaluación de reglas.
Aunque no se recomienda cuando se ejecuta en Google Kubernetes Engine, puedes anular las etiquetas
project_id,locationyclusterañadiéndolas comoargsal recurso Deployment enoperator.yaml. Si usas alguna etiqueta reservada como etiqueta de métrica, Managed Service para Prometheus las vuelve a etiquetar automáticamente añadiendo el prefijoexported_. Este comportamiento coincide con la forma en que Prometheus upstream gestiona los conflictos con etiquetas reservadas.Configuraciones de compresión
Si tienes muchos recursos de PodMonitoring, puede que te quedes sin espacio en ConfigMap. Para solucionarlo, habilita la compresión
gzipen tu recurso OperatorConfig:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzipHabilitar el autoescalado de pods vertical (VPA) para la colección gestionada
Si se producen errores de falta de memoria en los pods del colector de tu clúster o si las solicitudes y los límites de recursos predeterminados de los colectores no se ajustan a tus necesidades, puedes usar el autoescalado vertical de pods para asignar recursos de forma dinámica.
Cuando defines el campo
scaling.vpa.enabled: trueen el recursoOperatorConfig, el operador implementa un manifiestoVerticalPodAutoscaleren el clúster que permite que las solicitudes y los límites de recursos de los pods del recopilador se definan automáticamente en función del uso.Para habilitar VPA en los pods del recopilador de Managed Service para Prometheus, ejecuta el siguiente comando:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergeSi el comando se completa correctamente, el operador configura el autoescalado de pods vertical para los pods del recolector. Los errores de falta de memoria provocan un aumento inmediato de los límites de recursos. Si no hay errores de falta de memoria, el primer ajuste de las solicitudes y los límites de recursos de los pods del recolector suele producirse en un plazo de 24 horas.
Puede que recibas este error al intentar habilitar VPA:
vertical pod autoscaling is not available - install vpa support and restart the operatorPara solucionar este error, primero debes habilitar el autoescalado vertical de pods a nivel de clúster:
Ve a la página Kubernetes Engine - Clústeres en laGoogle Cloud consola.
En la Google Cloud consola, ve a la página Clústeres de Kubernetes:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo sea Kubernetes Engine.
Selecciona el clúster que quieras modificar.
En la sección Automatización, edita el valor de la opción Autoescalado de pods vertical.
Seleccione la casilla Habilitar escalado automático vertical de pods y, a continuación, haga clic en Guardar cambios. Este cambio reinicia el clúster. El operador se reinicia como parte de este proceso.
Vuelve a intentar ejecutar el siguiente comando:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergepara habilitar VPA en Managed Service para Prometheus.
Para confirmar que el recurso
OperatorConfigse ha editado correctamente, ábrelo con el comandokubectl -n gmp-public edit operatorconfig config. Si la solicitud se hace correctamente, tuOperatorConfigincluirá la siguiente sección en negrita:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: trueSi ya has habilitado el autoescalado de pods vertical a nivel de clúster y sigues viendo el error
vertical pod autoscaling is not available - install vpa support and restart the operator, es posible que el podgmp-operatortenga que volver a evaluar la configuración del clúster. Si tienes un clúster estándar, ejecuta el siguiente comando para volver a crear el pod:kubectl -n gmp-system rollout restart deployment/gmp-operator
Una vez que se haya reiniciado el pod
gmp-operator, sigue los pasos anteriores para parchear elOperatorConfigde nuevo.Si tienes un clúster de Autopilot, ponte en contacto con el equipo de Asistencia para que te ayude a reiniciar el clúster.
El autoescalado vertical de pods funciona mejor cuando se ingieren cantidades constantes de muestras, divididas equitativamente entre los nodos. Si la carga de métricas es irregular o tiene picos, o si la carga de métricas varía mucho entre los nodos, puede que VPA no sea una solución eficiente.
Para obtener más información, consulta el artículo sobre el autoescalado vertical de pods en GKE.
Configurar statsd_exporter y otros exportadores que registren métricas de forma centralizada
Si usas statsd_exporter para Prometheus, Envoy para Istio, SNMP exporter, Prometheus Pushgateway o kube-state-metrics, o bien tienes otro exportador similar que intermedia y registra métricas en nombre de otros recursos que se ejecutan en tu entorno, debes hacer algunos cambios pequeños para que tu exportador funcione con Managed Service para Prometheus.
Para obtener instrucciones sobre cómo configurar estos exportadores, consulta esta nota de la sección Solución de problemas.
Desmontaje
Para inhabilitar la recogida gestionada implementada mediante
gcloudo la interfaz de usuario de GKE, puedes hacer lo siguiente:Ejecuta el siguiente comando:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
Usa la interfaz de usuario de GKE:
Selecciona Kubernetes Engine en la consola de Google Cloud y, a continuación, Clústeres.
Busca el clúster en el que quieras inhabilitar la recolección gestionada y haz clic en su nombre.
En la pestaña Detalles, desplázate hacia abajo hasta Funciones y cambia el estado a Inhabilitado con el botón de edición.
Para inhabilitar la recogida gestionada implementada con Terraform, especifica
enabled = falseen la secciónmanaged_prometheusdel recursogoogle_container_cluster.Para inhabilitar la recogida gestionada implementada con
kubectl, ejecuta el siguiente comando:kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
Si inhabilitas la recogida gestionada, tu clúster dejará de enviar datos nuevos a Managed Service para Prometheus. Esta acción no elimina los datos de métricas que ya estén almacenados en el sistema.
Si inhabilita la colección gestionada, también se eliminará el espacio de nombres
gmp-publicy todos los recursos que contenga, incluidos los exportadores instalados en ese espacio de nombres.Ejecutar una colección gestionada fuera de GKE
En entornos de GKE, puedes ejecutar la recogida gestionada sin necesidad de realizar más configuraciones. En otros entornos de Kubernetes, debes proporcionar explícitamente las credenciales, un valor
project-idque contenga tus métricas, un valorlocation(regiónGoogle Cloud ) donde se almacenarán tus métricas y un valorclusterpara guardar el nombre del clúster en el que se ejecuta el recopilador.Como
gcloudno funciona fuera de los entornos de Google Cloud , debes implementar con kubectl. A diferencia degcloud, al implementar una colección gestionada conkubectlno se actualiza automáticamente tu clúster cuando hay una nueva versión disponible. No olvides consultar la página de lanzamientos para ver las nuevas versiones y actualizar manualmente volviendo a ejecutar los comandoskubectlcon la nueva versión.Puedes proporcionar una clave de cuenta de servicio modificando el recurso OperatorConfig en
operator.yaml, tal como se describe en Proporcionar credenciales explícitamente. Puede proporcionar los valores deproject-id,locationyclusterañadiéndolos comoargsal recurso Deployment enoperator.yaml.Te recomendamos que elijas
project-iden función del modelo de tenencia que tengas previsto para las lecturas. Elige un proyecto en el que almacenar las métricas en función de cómo quieras organizar las lecturas más adelante con los ámbitos de métricas. Si no te importa, puedes ponerlo todo en un proyecto.En el caso de
location, te recomendamos que elijas la región Google Cloud más cercana a tu implementación. Cuanto más lejos esté la región elegida de tu implementación, mayor será la latencia de escritura y más te afectarán los posibles problemas de red. Google Cloud Puede consultar esta lista de regiones de varias nubes. Si no te importa, puedes ponerlo todo en una Google Cloud región. No puedes usarglobalcomo tu ubicación.En el caso de
cluster, te recomendamos que elijas el nombre del clúster en el que se ha desplegado el operador.Si se configura correctamente, OperatorConfig debería tener este aspecto:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.jsonEl recurso Deployment debería tener este aspecto:
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"En este ejemplo, se presupone que ha asignado a la variable
REGIONun valor comous-central1.Si ejecutas el servicio gestionado de Prometheus fuera de Google Cloud , se te cobrarán tarifas por transferencia de datos. Se aplican tarifas por transferir datos a Google Cloud, y es posible que se te cobren tarifas por transferir datos desde otra nube. Puedes minimizar estos costes habilitando la compresión gzip a través de la red mediante OperatorConfig. Añade el texto que se muestra en negrita al recurso:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...Más información sobre los recursos personalizados de colecciones gestionadas
Para consultar la documentación de referencia sobre todos los recursos personalizados de Managed Service for Prometheus, consulta la referencia de la API de prometheus-engine/doc.
Siguientes pasos