En este documento se presentan las prácticas recomendadas para diseñar la jerarquía y la separación de las cargas de trabajo en una configuración con air gap de Google Distributed Cloud (GDC) mediante organizaciones, proyectos y clústeres de Kubernetes. Estas directrices equilibran el uso eficiente de los recursos, el aislamiento de las cargas de trabajo y la facilidad de las operaciones.
Diseñar organizaciones para el aislamiento físico y lógico entre clientes
El recurso Organization es la raíz de todos los recursos propiedad de un solo cliente. El control de acceso granular entre las cargas de trabajo de una organización se puede definir mediante enlaces de roles y políticas de red. Para obtener más información, consulta Gestión de identidades y accesos.
Cada organización de una zona de GDC proporciona aislamiento físico para la infraestructura de computación y aislamiento lógico para las redes, el almacenamiento y otros servicios. Los usuarios de una organización no tienen acceso a los recursos de otra organización a menos que se les conceda explícitamente. De forma predeterminada, no se permite la conectividad de red de una organización a otra, a menos que se configure explícitamente para permitir la transferencia de datos de una organización y la transferencia de datos a otra.
Definir el ámbito de las cargas de trabajo que pueden compartir una organización
El ámbito de una organización en el contexto de tu empresa puede variar en función de cómo defina tu empresa los límites de confianza. Es posible que algunas empresas prefieran crear varios recursos de organización para diferentes entidades de la empresa. Por ejemplo, cada departamento de una empresa puede ser un cliente independiente de GDC con una organización independiente si los departamentos requieren una separación física y administrativa completa de sus cargas de trabajo.
En general, te recomendamos que agrupes varias cargas de trabajo en una sola organización en función de las siguientes señales:
- Las cargas de trabajo pueden compartir dependencias. Por ejemplo, puede tratarse de una fuente de datos compartida, de la conectividad entre cargas de trabajo o de una herramienta de monitorización compartida.
- Las cargas de trabajo pueden compartir una raíz de confianza administrativa. Se puede confiar en el mismo administrador para que tenga acceso privilegiado a todas las cargas de trabajo de la organización.
- Las cargas de trabajo pueden compartir la infraestructura física subyacente con otras cargas de trabajo de la misma organización, siempre que haya una separación lógica suficiente.
- El mismo titular del presupuesto es responsable de los presupuestos de carga de trabajo en conjunto. Para obtener información sobre cómo ver los costes agregados de la organización o un análisis detallado por carga de trabajo, consulta la página Facturación.
- Los requisitos de disponibilidad de la carga de trabajo deben cumplir los requisitos de alta disponibilidad de la distancia multizona.
Diseñar proyectos para aislar lógicamente las cargas de trabajo
En una organización, recomendamos aprovisionar varios proyectos para crear una separación lógica entre los recursos. Los proyectos de la misma organización pueden compartir la infraestructura física subyacente, pero se utilizan para separar las cargas de trabajo con un límite lógico basado en las políticas de gestión de identidades y accesos (IAM) y las políticas de red.
Al diseñar los límites de un proyecto, piensa en el conjunto de funciones más grande que puedan compartir los recursos, como los enlaces de rol, las políticas de red o los requisitos de observabilidad. Agrupa los recursos que puedan compartir esta función en un proyecto y mueve los recursos que no puedan compartirla a otro proyecto.
En términos de Kubernetes, un proyecto es un espacio de nombres de Kubernetes reservado en todos los clústeres de una organización. Aunque un espacio de nombres esté reservado en varios clústeres, eso no significa que un pod se programe automáticamente en todos los clústeres. Un pod programado en un clúster concreto sigue programado en ese clúster.
En el siguiente diagrama se muestra cómo se aplica una vinculación de rol a un proyecto que abarca varios clústeres.
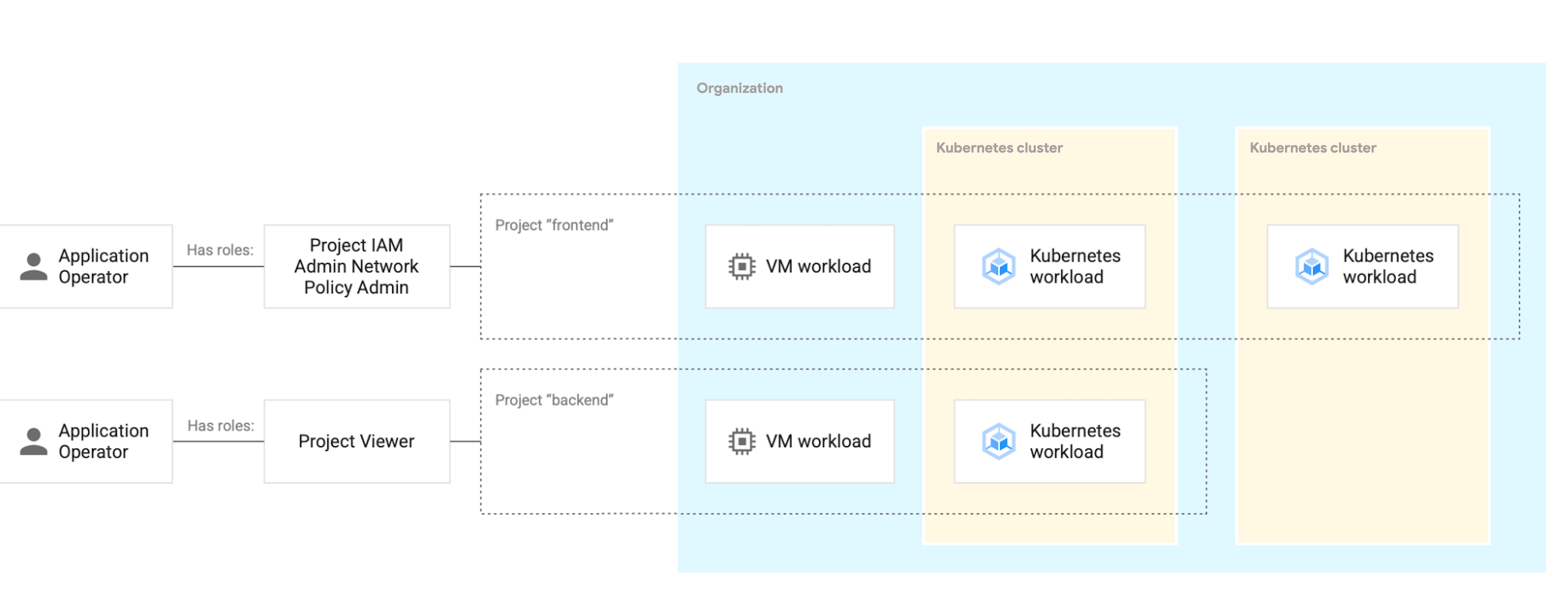
Las vinculaciones de roles se definen a nivel de proyecto para determinar quién puede hacer qué en cada tipo de recurso. Las cargas de trabajo, como las máquinas virtuales o los pods, se implementan en un proyecto y el acceso a ellas se rige por la vinculación de roles. La vinculación de roles se aplica de forma coherente a las cargas de trabajo basadas en máquinas virtuales y a las cargas de trabajo basadas en contenedores, independientemente del clúster en el que se implementen.
En el siguiente diagrama se muestra cómo gestionan las políticas de red el acceso entre proyectos.
La comunicación entre proyectos de Backend Project, Frontend Project y Database Project está inhabilitada. Sin embargo, los recursos de cada proyecto pueden comunicarse entre sí.
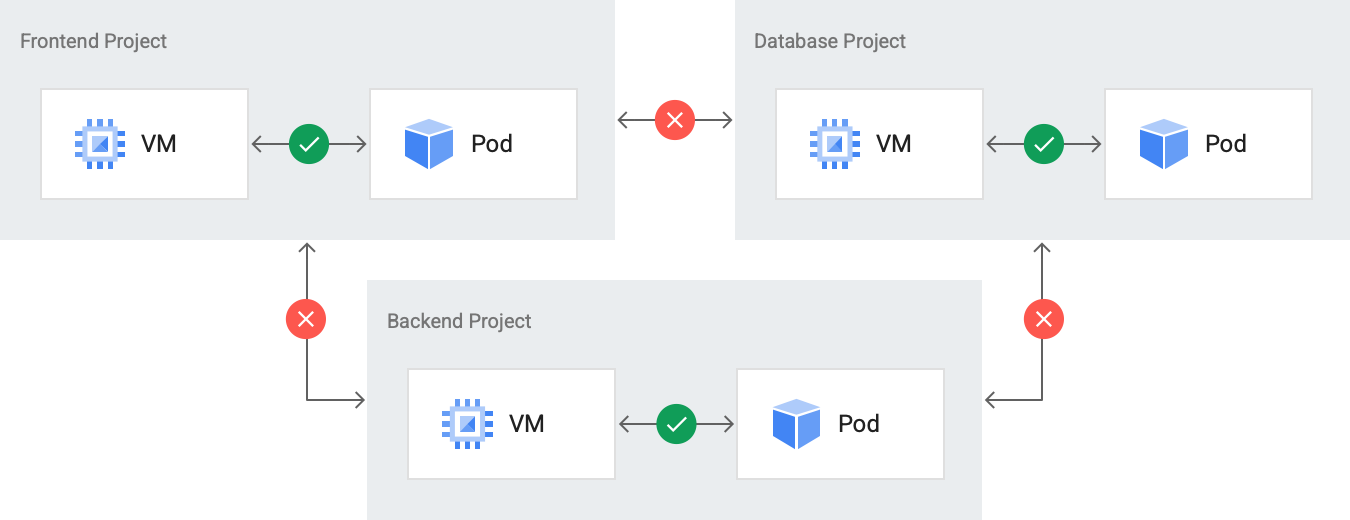
Las políticas de red se definen a nivel de proyecto para permitir de forma selectiva el acceso a la red entre recursos. De forma predeterminada, todos los recursos de un mismo proyecto pueden comunicarse entre sí en la red interna, y un recurso de un proyecto no puede comunicarse con un recurso de otro proyecto. Este comportamiento de las políticas de red se aplica tanto si los recursos se despliegan en el mismo clúster como si no.
También puedes definir un ProjectNetworkPolicy recurso personalizado para habilitar la comunicación entre proyectos. Esta política se define para cada proyecto con el fin de permitir el tráfico de entrada de otros proyectos. En el siguiente diagrama se muestra un recurso personalizado ProjectNetworkPolicy definido para Backend Project con el fin de habilitar la transferencia de datos desde Frontend Project y Database Project.
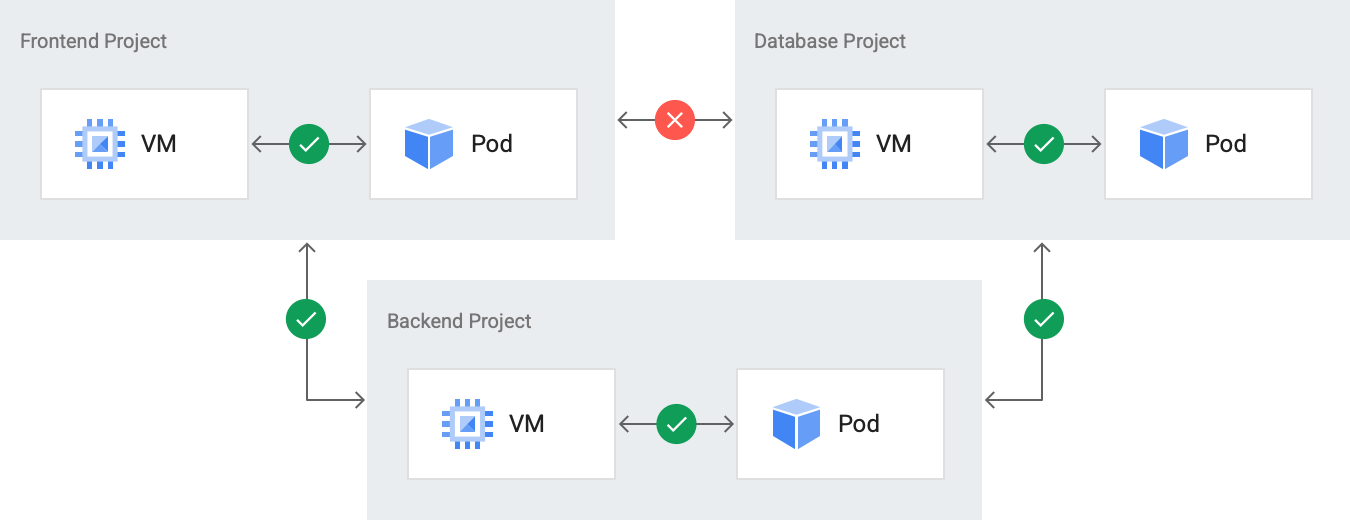
Además, la pila de monitorización recoge métricas de toda la organización, pero puedes filtrar y consultar en varios niveles de la jerarquía de recursos. Puedes consultar métricas con entidades como un clúster o un espacio de nombres.
Crear proyectos por entorno de desarrollo de software
Para cada carga de trabajo, te recomendamos que crees proyectos independientes para cada entorno de desarrollo de software. Un entorno de desarrollo de software es un área de tu universo de GDC destinada a todas las operaciones que corresponden a una fase del ciclo de vida designada. Por ejemplo, puedes tener entornos de desarrollo de software para pruebas, desarrollo y producción. Si separas tus entornos de desarrollo de software, podrás definir enlaces de roles y políticas de red de forma granular, de modo que los cambios que se hagan en un proyecto usado en un entorno que no sea de producción no afecten al entorno de producción.
Otorgar enlaces de roles a nivel de recurso en proyectos
En función de la estructura y los requisitos de tu equipo, puedes permitir que los desarrolladores modifiquen cualquier recurso del proyecto que gestionen o puedes requerir un control de acceso más granular. En un proyecto, puedes conceder enlaces de roles granulares para permitir que desarrolladores concretos accedan a algunos recursos del proyecto, pero no a todos. Por ejemplo, un equipo puede tener un administrador de bases de datos que deba gestionar la base de datos, pero no modificar otros recursos, mientras que los desarrolladores de software del equipo no deben tener permiso para modificar la base de datos.
Diseñar clústeres para aislar lógicamente las operaciones de Kubernetes
Un clúster de Kubernetes no es un límite de arrendatario estricto, ya que las vinculaciones de roles y las políticas de red se aplican a los proyectos, no a los clústeres de Kubernetes. Los clústeres y los proyectos de Kubernetes tienen una relación de muchos a muchos. Puede que tengas varios clústeres de Kubernetes en un solo proyecto o un solo clúster de Kubernetes que abarque varios proyectos.