Crea un clúster de Kubernetes para permitir el despliegue de cargas de trabajo de contenedores. Los clústeres son un recurso de zona y no pueden abarcar varias zonas. Para usar clústeres en un despliegue multizona, debes crear manualmente clústeres en cada zona.
Antes de empezar
Para obtener los permisos necesarios para crear un clúster de Kubernetes, pide al administrador de gestión de identidades y accesos de tu organización que te asigne el rol de administrador de clúster de usuario (user-cluster-admin). Este rol no está vinculado a un espacio de nombres.
Google Distributed Cloud (GDC) con air gap tiene los siguientes límites para los clústeres de Kubernetes:
- 16 clústeres por organización
- 42 nodos de trabajador por clúster y un mínimo de tres nodos de trabajador
- 4620 pods por clúster
- 110 pods por nodo
Configurar el bloque CIDR de los pods
El clúster sigue esta lógica al asignar direcciones IP:
- Kubernetes asigna a cada uno de los nodos un bloque CIDR /24 que consta de 256 direcciones. Esta cantidad se ajusta al máximo predeterminado de 110 pods por nodo para los clústeres de usuarios.
- El tamaño del bloque CIDR asignado a un nodo depende del valor máximo de pods por nodo.
- El bloque siempre contiene al menos el doble de direcciones que el número máximo de pods por nodo.
Consulta el siguiente ejemplo para saber cómo se ha calculado el valor predeterminado de Tamaño de máscara por nodo= /24 para dar cabida a 110 pods:
Maximum pods per node = 110
Total number of IP addresses required = 2 * 110 = 220
Per node mask size = /24
Number of IP addresses in a /24 = 2(32 - 24) = 256
Determina la máscara CIDR de pod que se debe configurar en el clúster de usuarios en función del número de nodos necesario. Planifica las futuras incorporaciones de nodos al clúster al configurar el intervalo CIDR:
Total number of nodes supported = 2(Per node mask size - pod CIDR mask)
Dado que tenemos un tamaño de máscara por nodo predeterminado de /24, consulta la siguiente tabla, que asigna la máscara CIDR de los pods al número de nodos admitidos.
| Máscara de CIDR de pod | Cálculo: 2(Tamaño de la máscara por nodo - Máscara CIDR) | Número máximo de nodos admitidos, incluidos los nodos del plano de control |
|---|---|---|
| /21 | 2(24 - 21) | 8 |
| /20 | 2(24 - 20) | 16 |
| /19 | 2(24 - 19) | 32 |
| /18 | 2(24 - 18) | 64 |
Crear un clúster de Kubernetes
Sigue estos pasos para crear un clúster de Kubernetes:
Consola
En el menú de navegación, selecciona Kubernetes Engine > Clústeres.
.Haz clic en Crear clúster.
En el campo Nombre, especifica un nombre para el clúster.
Selecciona la versión de Kubernetes del clúster.
Selecciona la zona en la que quieras crear el clúster.
Haz clic en Adjuntar proyecto y selecciona un proyecto para adjuntarlo a tu clúster. A continuación, haz clic en Guardar. Puedes adjuntar o separar proyectos después de crear el clúster desde la página de detalles del proyecto. Debes tener un proyecto asociado a tu clúster para poder implementar cargas de trabajo de contenedores en él.
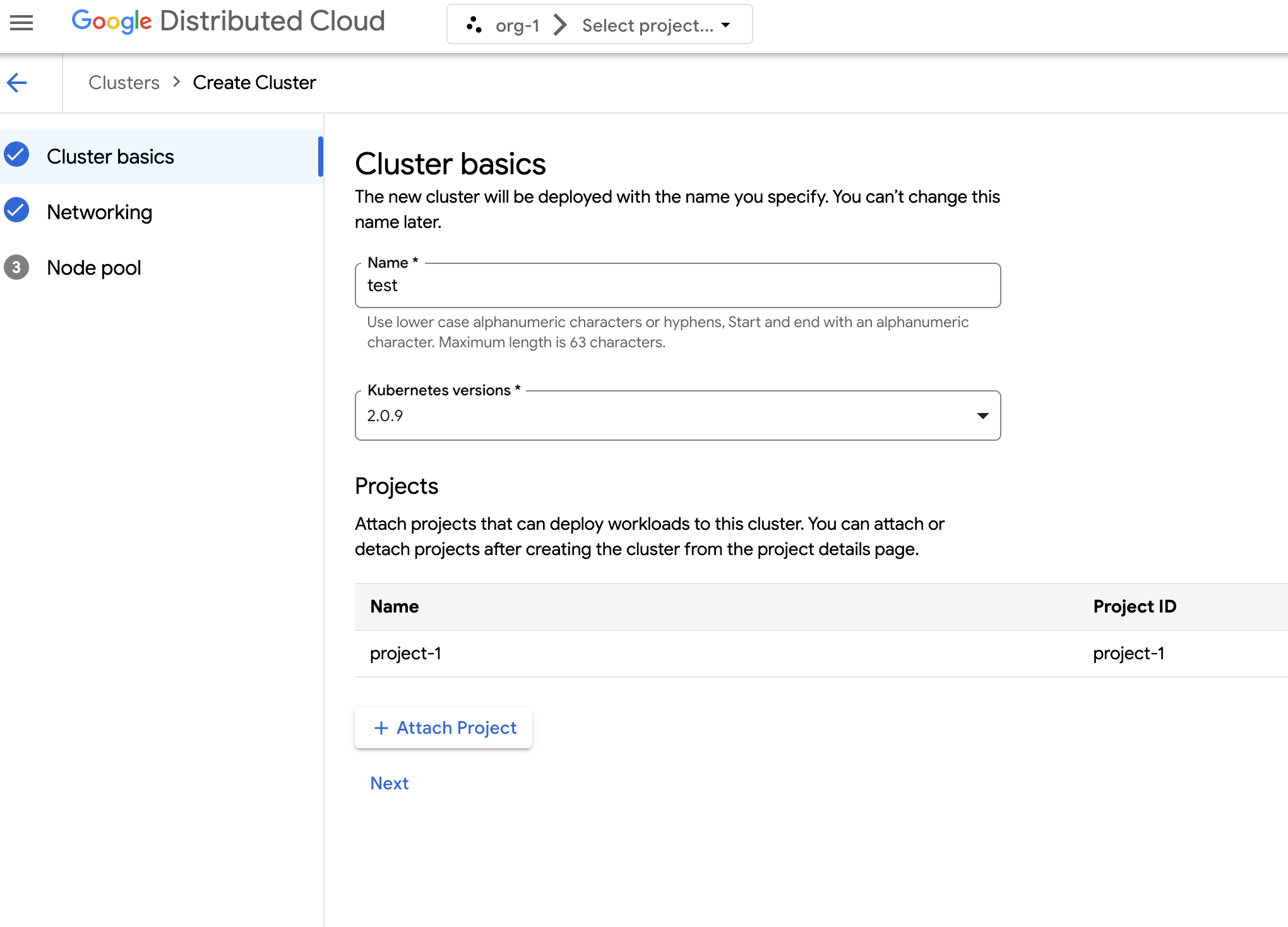
Haz clic en Siguiente.
Configura los ajustes de red de tu clúster. No puedes cambiar estos ajustes de red después de crear el clúster. El protocolo de Internet predeterminado y único compatible con los clústeres de Kubernetes es el protocolo de Internet versión 4 (IPv4).
Si quieres crear nodos de balanceador de carga dedicados, introduce el número de nodos que quieras crear. De forma predeterminada, se asignan 20 nodos. Si no asignas ningún nodo, el tráfico del balanceador de carga se dirige a los nodos del plano de control. Este valor se puede actualizar después de crear el clúster.
Selecciona el CIDR de servicio (enrutamiento de interdominios sin clases) que quieras usar. Tus servicios implementados, como los balanceadores de carga, tienen asignadas direcciones IP de este intervalo.
Selecciona el CIDR de pod que quieras usar. El clúster asigna direcciones IP de este intervalo a tus pods y VMs.
Haz clic en Siguiente.
Revisa los detalles del grupo de nodos predeterminado generado automáticamente del clúster. Haz clic en edit Editar para modificar el grupo de nodos predeterminado.
Para crear más grupos de nodos, selecciona Añadir grupo de nodos. Cuando editas el grupo de nodos predeterminado o añades uno nuevo, puedes personalizarlo con las siguientes opciones:
- Asigna un nombre al pool de nodos. No puedes modificar el nombre después de crear el grupo de nodos.
- Especifica el número de nodos de trabajador que se crearán en el grupo de nodos.
Selecciona la clase de máquina que mejor se adapte a los requisitos de tu carga de trabajo. Consulta la lista de los siguientes ajustes:
- Tipo de máquina
- CPU
- Memoria
Haz clic en Guardar.
Haz clic en Crear para que se genere el clúster.
API
Para crear un clúster con la API directamente, aplica un recurso personalizado a tu instancia de GDC:
Crea un
Clusterrecurso personalizado y guárdalo como un archivo YAML, comocluster.yaml:apiVersion: cluster.gdc.goog/v1 kind: Cluster metadata: name: CLUSTER_NAME namespace: platform spec: clusterNetwork: podCIDRSize: POD_CIDR serviceCIDRSize: SERVICE_CIDR initialVersion: kubernetesVersion: KUBERNETES_VERSION loadBalancer: ingressServiceIPSize: LOAD_BALANCER_POOL_SIZE nodePools: - machineTypeName: MACHINE_TYPE name: NODE_POOL_NAME nodeCount: NUMBER_OF_WORKER_NODES taints: TAINTS labels: LABELS acceleratorOptions: gpuPartitionScheme: GPU_PARTITION_SCHEME releaseChannel: channel: UNSPECIFIEDHaz los cambios siguientes:
CLUSTER_NAME: el nombre del clúster. El nombre del clúster no puede terminar con-system. El sufijo-systemestá reservado para los clústeres creados por GDC.POD_CIDR: tamaño de los intervalos de red desde los que se asignan las direcciones IP virtuales de los pods. Si no se define, se usa el valor predeterminado21.SERVICE_CIDR: tamaño de los intervalos de red desde los que se asignan las direcciones IP virtuales de servicio. Si no se define, se usa el valor predeterminado23.KUBERNETES_VERSION: la versión de Kubernetes del clúster, como1.26.5-gke.2100. Para ver la lista de versiones de Kubernetes disponibles que se pueden configurar, consulta Listar las versiones de Kubernetes disponibles de un clúster.LOAD_BALANCER_POOL_SIZE: tamaño de los grupos de direcciones IP no superpuestos que usan los servicios de balanceador de carga. Si no se define, se usa el valor predeterminado20. Si se define en0, el tráfico del balanceador de carga se dirige a través de los nodos del plano de control. Este valor se puede actualizar después de crear el clúster.MACHINE_TYPE: el tipo de máquina de los nodos de trabajador del grupo de nodos. Consulta los tipos de máquinas disponibles para ver qué se puede configurar.NODE_POOL_NAME: el nombre del grupo de nodos.NUMBER_OF_WORKER_NODES: número de nodos de trabajo que se aprovisionarán en el grupo de nodos.TAINTS: los taints que se aplicarán a los nodos de este grupo de nodos. Este campo es opcional.LABELS: las etiquetas que se aplicarán a los nodos de este grupo de nodos. Contiene una lista de pares clave-valor. Este campo es opcional.GPU_PARTITION_SCHEME: el esquema de partición de GPU, si ejecutas cargas de trabajo de GPU. Por ejemplo,mixed-2. La GPU no se particiona si no se define este campo. Para ver los perfiles de GPU con varias instancias (MIG) disponibles, consulta Perfiles de MIG admitidos.
Aplica el recurso personalizado a tu instancia de GDC:
kubectl apply -f cluster.yaml --kubeconfig MANAGEMENT_API_SERVERSustituye
MANAGEMENT_API_SERVERpor la ruta de kubeconfig del servidor de la API zonal. Si aún no has generado un archivo kubeconfig para el servidor de la API en tu zona de destino, consulta Iniciar sesión para obtener más información.
Terraform
En un archivo de configuración de Terraform, inserta el siguiente fragmento de código:
provider "kubernetes" { config_path = "MANAGEMENT_API_SERVER" } resource "kubernetes_manifest" "cluster-create" { manifest = { "apiVersion" = "cluster.gdc.goog/v1" "kind" = "Cluster" "metadata" = { "name" = "CLUSTER_NAME" "namespace" = "platform" } "spec" = { "clusterNetwork" = { "podCIDRSize" = "POD_CIDR" "serviceCIDRSize" = "SERVICE_CIDR" } "initialVersion" = { "kubernetesVersion" = "KUBERNETES_VERSION" } "loadBalancer" = { "ingressServiceIPSize" = "LOAD_BALANCER_POOL_SIZE" } "nodePools" = [{ "machineTypeName" = "MACHINE_TYPE" "name" = "NODE_POOL_NAME" "nodeCount" = "NUMBER_OF_WORKER_NODES" "taints" = "TAINTS" "labels" = "LABELS" "acceleratorOptions" = { "gpuPartitionScheme" = "GPU_PARTITION_SCHEME" } }] "releaseChannel" = { "channel" = "UNSPECIFIED" } } } }Haz los cambios siguientes:
MANAGEMENT_API_SERVER: la ruta de kubeconfig del servidor de la API zonal. Si aún no has generado un archivo kubeconfig para el servidor de la API de tu zona de destino, consulta Iniciar sesión para obtener más información.CLUSTER_NAME: el nombre del clúster. El nombre del clúster no puede terminar con-system. El sufijo-systemestá reservado para los clústeres creados por GDC.POD_CIDR: tamaño de los intervalos de red desde los que se asignan las direcciones IP virtuales de los pods. Si no se define, se usa el valor predeterminado21.SERVICE_CIDR: tamaño de los intervalos de red desde los que se asignan las direcciones IP virtuales de servicio. Si no se define, se usa el valor predeterminado23.KUBERNETES_VERSION: la versión de Kubernetes del clúster, como1.26.5-gke.2100. Para ver la lista de versiones de Kubernetes disponibles que se pueden configurar, consulta Listar las versiones de Kubernetes disponibles de un clúster.LOAD_BALANCER_POOL_SIZE: tamaño de los grupos de direcciones IP no superpuestos que usan los servicios de balanceador de carga. Si no se define, se usa el valor predeterminado20. Si se define en0, el tráfico del balanceador de carga se dirige a través de los nodos del plano de control. Este valor se puede actualizar después de crear el clúster.MACHINE_TYPE: el tipo de máquina de los nodos de trabajador del grupo de nodos. Consulta los tipos de máquinas disponibles para ver qué se puede configurar.NODE_POOL_NAME: el nombre del grupo de nodos.NUMBER_OF_WORKER_NODES: número de nodos de trabajo que se aprovisionarán en el grupo de nodos.TAINTS: los taints que se aplicarán a los nodos de este grupo de nodos. Este campo es opcional.LABELS: las etiquetas que se aplicarán a los nodos de este grupo de nodos. Contiene una lista de pares clave-valor. Este campo es opcional.GPU_PARTITION_SCHEME: el esquema de partición de GPU, si ejecutas cargas de trabajo de GPU. Por ejemplo,mixed-2. La GPU no se particiona si no se define este campo. Para ver los perfiles de GPU con varias instancias (MIG) disponibles, consulta Perfiles de MIG admitidos.
Aplica el nuevo clúster de Kubernetes con Terraform:
terraform apply
Lista de versiones de Kubernetes disponibles para un clúster
Puedes consultar las versiones de Kubernetes disponibles en tu instancia de GDC con la CLI de kubectl:
kubectl get userclustermetadata.upgrade.private.gdc.goog \
-o=custom-columns=K8S-VERSION:.spec.kubernetesVersion \
--kubeconfig MANAGEMENT_API_SERVER
Sustituye MANAGEMENT_API_SERVER por la ruta de kubeconfig del servidor de la API zonal de tu clúster.
El resultado es similar al siguiente:
K8S-VERSION
1.25.10-gke.2100
1.26.5-gke.2100
1.27.4-gke.500
Admitir cargas de trabajo de GPU en un clúster
Distributed Cloud ofrece compatibilidad con GPUs de NVIDIA para clústeres de Kubernetes, que ejecutan tus dispositivos GPU como cargas de trabajo de usuario. Por ejemplo, puede que prefieras ejecutar cuadernos de inteligencia artificial (IA) y aprendizaje automático en un entorno de GPU. Asegúrate de que tu clúster sea compatible con dispositivos de GPU antes de usar los cuadernos de IA y aprendizaje automático. La compatibilidad con GPU está habilitada de forma predeterminada en los clústeres que tienen máquinas con GPU aprovisionadas.
Los clústeres se pueden crear directamente mediante la consola o la API de GDC. Asegúrate de aprovisionar máquinas con GPU para tu clúster de forma que pueda admitir cargas de trabajo de GPU en sus contenedores asociados. Para obtener más información, consulta Crear un clúster de Kubernetes.
Las GPUs se asignan de forma estática. Las cuatro primeras GPUs siempre se dedican a cargas de trabajo como las APIs de inteligencia artificial (IA) y aprendizaje automático (ML) preentrenadas. Estas GPUs no se ejecutan en un clúster de Kubernetes. Las GPUs restantes están disponibles para los clústeres de Kubernetes. Los cuadernos de IA y AA se ejecutan en clústeres de Kubernetes.
Asegúrate de asignar máquinas con GPU a los tipos de clúster correctos para que se puedan usar componentes como las APIs de IA y aprendizaje automático, así como los cuadernos.