Pode usar um glossário para definir a terminologia específica do seu domínio. Com um glossário, pode adicionar pares de termos, incluindo um termo de idioma de origem e de destino. Os pares de termos garantem que o serviço Vertex AI Translation traduz consistentemente a sua terminologia.
Seguem-se exemplos de casos em que pode definir entradas de glossário:
- Nomes dos produtos: identifique os nomes dos produtos para os manter na tradução. Por exemplo, Google Home tem de ser traduzido para Google Home.
- Palavras ambíguas: especifique o significado de palavras vagas e homónimos. Por exemplo, morcego pode significar um animal ou um objeto usado para praticar desporto.
- Palavras emprestadas: esclareça o significado de palavras adotadas de um idioma diferente. Por exemplo, bouillabaisse em francês traduz-se para bouillabaisse em inglês, um prato de caldeirada de peixe.
Os termos num glossário podem ser palavras únicas (também denominadas tokens) ou expressões curtas, normalmente com menos de cinco palavras. O Vertex AI Translation ignora as entradas do glossário correspondentes se as palavras forem palavras vazias.
O Vertex AI Translation oferece os seguintes métodos de glossário disponíveis no Google Distributed Cloud (GDC) air-gapped:
| Método | Descrição |
|---|---|
CreateGlossary |
Crie um glossário. |
GetGlossary |
Devolve um glossário armazenado. |
ListGlossaries |
Devolve uma lista de IDs de glossários num projeto. |
DeleteGlossary |
Elimine um glossário de que já não precisa. |
Antes de começar
Antes de criar um glossário para definir a sua terminologia para tradução, tem de ter um projeto denominado translation-glossary-project. O recurso personalizado do projeto tem de ter o seguinte aspeto:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
Para receber as autorizações necessárias para usar um glossário, peça ao administrador de IAM do projeto para lhe conceder as seguintes funções no espaço de nomes do projeto:
- Programador de tradução de IA: obtenha a função
Programador de tradução de IA (
ai-translation-developer) para aceder ao serviço Vertex AI Translation. - Administrador do contentor do projeto: obtenha a função de administrador do contentor do projeto (
project-bucket-admin) para gerir contentores de armazenamento e objetos nos contentores, o que lhe permite criar e carregar ficheiros.
Para mais informações sobre os pré-requisitos, consulte o artigo Configure um projeto de tradução.
Crie um ficheiro de glossário
Tem de criar um ficheiro de glossário para armazenar os termos do idioma de origem e do idioma de destino. Esta secção contém os dois esquemas de glossário diferentes que pode usar para definir os seus termos.
A tabela seguinte descreve os limites suportados na nuvem distribuída para ficheiros de glossário:
| Descrição | Limite |
|---|---|
| Tamanho máximo do ficheiro | 10,4 milhões (10 485 760) de bytes UTF-8 |
| Comprimento máximo de um termo do glossário | 1024 bytes UTF-8 |
| Número máximo de recursos de glossário para um projeto | 10 000 |
Escolha um dos seguintes esquemas para o ficheiro de glossário:
- Glossário unidirecional: especifique a tradução esperada para um par de termos de origem e de destino num idioma específico. Os glossários unidirecionais suportam os formatos de ficheiros TSV, CSV e TMX.
- Glossário de conjuntos de termos equivalentes: especifique a tradução esperada em vários idiomas em cada linha. Os glossários de conjuntos de termos equivalentes suportam formatos de ficheiros CSV.
Glossário unidirecional
A API Vertex AI Translation aceita valores separados por tabulações (TSV) e valores separados por vírgulas (CSV). Cada linha contém um par de termos separados por um separador (\t) ou uma vírgula (,) para estes formatos de ficheiros.
A API Vertex AI Translation também aceita o formato Translation Memory eXchange (TMX), um formato XML padrão para fornecer os pares de termos de origem e destino da tradução. Os ficheiros de entrada suportados estão num formato baseado na versão 1.4 do TMX.
Os exemplos seguintes mostram a estrutura necessária para os formatos de ficheiros TSV, CSV e TMX de glossários unidirecionais:
TSV e CSV
A imagem seguinte mostra duas colunas num ficheiro TSV ou CSV. A primeira coluna contém o termo do idioma de origem e a segunda coluna contém o termo do idioma de destino.

Quando cria um ficheiro de glossário, pode definir uma linha de cabeçalho. O pedido de glossário disponibiliza o ficheiro à API Vertex AI Translation.
TMX
O exemplo seguinte ilustra a estrutura necessária num ficheiro TMX:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
Se o seu ficheiro contiver etiquetas XML que não são apresentadas neste exemplo, a API Vertex AI Translation ignora essas etiquetas.
Inclua os seguintes elementos no ficheiro TMX para garantir o processamento bem-sucedido pela API Vertex AI Translation:
<header>: identifique o idioma de origem através do atributosrclang.<tu>: inclua um par de elementos<tuv>com a mesma origem e idiomas de destino. Estes elementos<tuv>cumprem o seguinte:- Cada elemento
<tuv>identifica o idioma do texto contido através do atributoxml:lang. Use códigos ISO-639-1 para identificar os idiomas de origem e de destino. Consulte a lista de idiomas suportados e os respetivos códigos de idioma. - Se um elemento
<tu>contiver mais de dois elementos<tuv>, a API Vertex AI Translation processa apenas o primeiro elemento<tuv>que corresponda ao idioma de origem e o primeiro elemento<tuv>que corresponda ao idioma de destino. O serviço ignora o resto dos elementos<tuv>. - Se um elemento
<tu>não tiver um par correspondente de elementos<tuv>, a API Vertex AI Translation ignora o elemento<tu>inválido.
- Cada elemento
<seg>: representam strings de texto generalizadas. A API Vertex AI Translation exclui as etiquetas de marcação de um elemento<seg>antes de processar o ficheiro. Se um elemento<tuv>contiver mais do que um elemento<seg>, a API Vertex AI Translation concatena o texto num único elemento com um espaço entre as strings de texto.
Depois de identificar os termos do glossário no seu glossário unidirecional, carregue o ficheiro para um contentor de armazenamento e disponibilize-o à API Vertex AI Translation criando e importando um glossário.
Glossário de conjuntos de termos equivalentes
A API Vertex AI Translation aceita ficheiros de glossário para conjuntos de termos equivalentes através do formato CSV. Para definir conjuntos de termos equivalentes, crie um ficheiro CSV de várias colunas no qual cada linha liste um único termo do glossário em vários idiomas. Consulte a lista de idiomas suportados e os respetivos códigos de idioma.
A imagem seguinte mostra um exemplo de um ficheiro CSV com várias colunas. Cada linha representa um termo do glossário e cada coluna representa uma tradução do termo em diferentes idiomas.
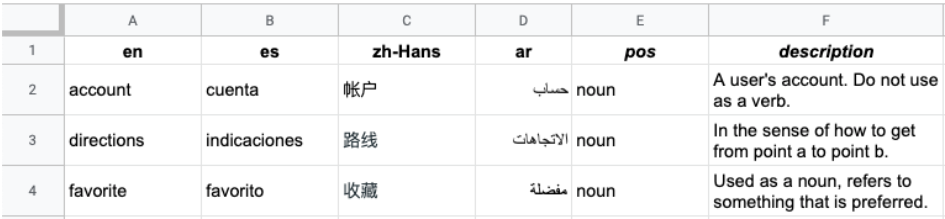
O cabeçalho é a primeira linha do ficheiro, que identifica o idioma de cada coluna. A linha de cabeçalho usa os códigos de idioma padrão ISO-639-1 ou BCP-47. A API Vertex AI Translation não usa informações de partes do discurso (pos) e os valores de posição específicos não são validados.
Cada linha subsequente contém termos do glossário equivalentes nos idiomas identificados no cabeçalho. Pode deixar as colunas em branco se o termo não estiver disponível em todos os idiomas.
Depois de identificar os termos do glossário no seu conjunto de termos equivalente, carregue o ficheiro para um contentor de armazenamento e disponibilize-o à API Vertex AI Translation criando e importando um glossário.
Carregue o ficheiro do glossário para um contentor de armazenamento
Siga estes passos para carregar o ficheiro de glossário para um contentor de armazenamento:
- Configure a CLI gcloud para o armazenamento de objetos.
Crie um contentor de armazenamento no namespace do seu projeto. Use uma
Standardclasse de armazenamento.Pode criar o contentor de armazenamento implementando um recurso
Bucketno espaço de nomes do projeto:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Conceda autorizações
readno contentor à conta de serviço (ai-translation-system-sa) usada pelo serviço Vertex AI Translation.Pode seguir estes passos para criar a função e a associação de funções através de recursos personalizados:
Crie a função implementando um recurso
Roleno espaço de nomes do projeto:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectCrie a associação de funções implementando um recurso
RoleBindingno espaço de nomes do projeto:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
Carregue o ficheiro de glossário para o contentor de armazenamento que criou. Para mais informações, consulte o artigo Carregue e transfira objetos de armazenamento em projetos.
Crie um glossário
O método CreateGlossary cria um glossário e devolve o identificador à operação de longa duração que gera o glossário.
Para criar um glossário, substitua o seguinte antes de usar qualquer um dos dados de pedido:
ENDPOINT: o ponto final do Vertex AI Translation que usa para a sua organização. Para mais informações, veja o estado do serviço e os pontos finais.PROJECT_ID: o ID do seu projeto.GLOSSARY_ID: o ID do glossário, que é o nome do recurso.BUCKET_NAME: o nome do contentor de armazenamento onde se encontra o ficheiro de glossário.GLOSSARY_FILENAME: o nome do ficheiro de glossário no contentor de armazenamento.
Segue-se a sintaxe de um pedido HTTP para criar um glossário:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
De acordo com o ficheiro de glossário que criou, escolha uma das seguintes opções para criar um glossário:
Unidirecional
Para criar um glossário unidirecional, especifique um par de idiomas (language_pair) com um idioma de origem (source_language_code) e um idioma de destino (target_language_code).
Siga estes passos para criar um glossário unidirecional:
Guarde o seguinte corpo do pedido num ficheiro JSON denominado
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Substitua o seguinte:
SOURCE_LANGUAGE: o código do idioma de origem do glossário. Consulte a lista de idiomas suportados e os respetivos códigos de idioma.TARGET_LANGUAGE: o código do idioma de destino do glossário. Consulte a lista de idiomas suportados e os respetivos códigos de idioma.
Faça o pedido. Os exemplos seguintes usam um método da API REST e a linha de comandos, mas também pode usar bibliotecas cliente para criar um glossário unidirecional.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
Tem de receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Conjunto de termos equivalentes
Para criar um glossário de termos equivalentes, especifique um conjunto de idiomas (language_codes_set) com os códigos de idioma (language_codes) do glossário.
Siga estes passos para criar um glossário de conjuntos de termos equivalentes:
Guarde o seguinte corpo do pedido num ficheiro JSON denominado
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Substitua
LANGUAGE_CODEpelo código do idioma ou dos idiomas do glossário. Consulte a lista de idiomas suportados e os respetivos códigos de idioma.Faça o pedido:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
Tem de receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
Tem de receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
Instale a versão mais recente da biblioteca cliente da Vertex AI Translation.
Defina as variáveis de ambiente necessárias num script Python.
Adicione o seguinte código ao script Python que criou:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Guarde o script Python.
Execute o script Python:
python SCRIPT_NAME
Substitua SCRIPT_NAME pelo nome que deu ao seu script Python, como glossary.py.
Para mais informações sobre o método create_glossary, consulte a biblioteca cliente Python.
Normalmente, a criação de um glossário demora menos de 10 minutos, consoante o tamanho do ficheiro de glossário. Pode obter o estado desta operação para saber quando termina.
Obtenha um glossário
O método GetGlossary devolve um glossário armazenado. Se o glossário não existir, o resultado devolve o valor NOT_FOUND. Para chamar o método GetGlossary, especifique o ID do projeto e o ID do glossário. Os métodos CreateGlossary e ListGlossaries devolvem o ID do glossário.
Por exemplo, os seguintes pedidos devolvem informações sobre um glossário específico no seu projeto:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
Listar glossários
O método ListGlossaries devolve uma lista de IDs de glossários num projeto. Se não existir um glossário, o resultado devolve o valor NOT_FOUND. Para chamar o método
ListGlossaries, especifique o ID do seu projeto e o
ponto final do Vertex AI Translation.
Por exemplo, o pedido seguinte devolve uma lista de IDs de glossários no seu projeto:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
Substitua TOKEN pelo
símbolo de autenticação
que obteve.
Elimine um glossário
O método DeleteGlossary elimina um glossário. Se o glossário não existir,
o resultado devolve o valor NOT_FOUND. Para chamar o método DeleteGlossary, especifique o ID do projeto, o ID do glossário e o ponto final do Vertex AI Translation.
Os métodos CreateGlossary e ListGlossaries devolvem o ID do glossário.
Por exemplo, o seguinte pedido elimina um glossário do seu projeto:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Substitua TOKEN pelo
símbolo de autenticação
que obteve.