Puoi utilizzare un glossario per definire la terminologia specifica del tuo dominio. Con un glossario, puoi aggiungere coppie di termini, inclusi un termine di lingua di origine e di lingua di destinazione. Le coppie di termini assicurano che il servizio Vertex AI Translation traduca in modo coerente la tua terminologia.
Di seguito sono riportati alcuni esempi di casi in cui puoi definire le voci del glossario:
- Nomi dei prodotti: identifica i nomi dei prodotti per mantenerli nella traduzione. Ad esempio, Google Home deve essere tradotto in Google Home.
- Parole ambigue: specifica il significato di parole vaghe e omonimi. Ad esempio, bat può significare una mazza da baseball o un pipistrello.
- Parole prese in prestito: chiarisci il significato delle parole adottate da un'altra lingua. Ad esempio, bouillabaisse in francese si traduce in bouillabaisse in inglese, un piatto di stufato di pesce.
I termini di un glossario possono essere singole parole (chiamate anche token) o brevi frasi, in genere più brevi di cinque parole. Vertex AI Translation ignora le voci del glossario corrispondenti se le parole sono stopword.
Vertex AI Translation offre i seguenti metodi di glossario disponibili in Google Distributed Cloud (GDC) con air gap:
| Metodo | Descrizione |
|---|---|
CreateGlossary |
Creare un glossario. |
GetGlossary |
Restituisce un glossario memorizzato. |
ListGlossaries |
Restituisce un elenco di ID glossario in un progetto. |
DeleteGlossary |
Elimina un glossario che non ti serve più. |
Prima di iniziare
Prima di creare un glossario per definire la terminologia per la traduzione, devi
avere un progetto denominato translation-glossary-project. La risorsa personalizzata del
progetto deve essere simile a quella dell'esempio seguente:
apiVersion: resourcemanager.gdc.goog/v1
kind: Project
metadata:
labels:
atat.config.google.com/clin-number: CLIN_NUMBER
atat.config.google.com/task-order-number: TASK_ORDER_NUMBER
name: translation-glossary-project
namespace: platform
Per ottenere le autorizzazioni necessarie per utilizzare un glossario, chiedi all'amministratore IAM del progetto di concederti i seguenti ruoli nello spazio dei nomi del progetto:
- Sviluppatore AI Translation: ottieni il ruolo
Sviluppatore AI Translation (
ai-translation-developer) per accedere al servizio Vertex AI Translation. - Amministratore bucket progetto: ottieni il ruolo Amministratore bucket progetto
(
project-bucket-admin) per gestire i bucket e gli oggetti di archiviazione all'interno dei bucket, che ti consente di creare e caricare file.
Per ulteriori informazioni sui prerequisiti, consulta la sezione Configurare un progetto di traduzione.
Creare un file glossario
Devi creare un file glossario per archiviare i termini della lingua di origine e della lingua di destinazione. Questa sezione contiene i due diversi layout del glossario che puoi utilizzare per definire i termini.
La tabella seguente descrive i limiti supportati su Distributed Cloud per i file di glossario:
| Descrizione | Limite |
|---|---|
| Massima dimensione del file | 10,4 milioni (10.485.760) di byte UTF-8 |
| Lunghezza massima di un termine del glossario | 1024 byte UTF-8 |
| Numero massimo di risorse di glossario per un progetto | 10.000 |
Scegli uno dei seguenti layout per il file del glossario:
- Glossario unidirezionale: specifica la traduzione prevista per una coppia di termini di origine e di destinazione in una lingua specifica. I glossari unidirezionali supportano i formati file TSV, CSV e TMX.
- Glossario dei set di termini equivalenti: specifica la traduzione prevista in più lingue in ogni riga. I glossari di insiemi di termini equivalenti supportano i formati di file CSV.
Glossario unidirezionale
L'API Vertex AI Translation accetta valori delimitati da tabulazioni (TSV) e
valori separati da virgole (CSV). Ogni riga contiene una coppia di termini separati da una
tabulazione (\t) o da una virgola (,) per questi formati di file.
L'API Vertex AI Translation accetta anche il formato TMX (Translation Memory eXchange), un formato XML standard per fornire le coppie di termini di origine e destinazione della traduzione. I file di input supportati sono in un formato basato su TMX versione 1.4.
Gli esempi riportati di seguito mostrano la struttura richiesta per i formati di file TSV, CSV e TMX dei glossari unidirezionali:
TSV e CSV
L'immagine seguente mostra due colonne in un file TSV o CSV. La prima colonna contiene il termine nella lingua di origine, mentre la seconda colonna contiene il termine nella lingua di destinazione.

Quando crei un file glossario, puoi definire una riga di intestazione. La richiesta di glossario rende il file disponibile per l'API Vertex AI Translation.
TMX
L'esempio seguente illustra la struttura richiesta in un file TMX:
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE tmx SYSTEM "tmx14.dtd">
<tmx version="1.4">
<header segtype="sentence" o-tmf="UTF-8" adminlang="en" srclang="en" datatype="PlainText"/>
<body>
<tu>
<tuv xml:lang="en">
<seg>account</seg>
</tuv>
<tuv xml:lang="es">
<seg>cuenta</seg>
</tuv>
</tu>
<tu>
<tuv xml:lang="en">
<seg>directions</seg>
</tuv>
<tuv xml:lang="es">
<seg>indicaciones</seg>
</tuv>
</tu>
</body>
</tmx>
Se il file contiene tag XML non mostrati in questo esempio, l'API Vertex AI Translation li ignora.
Includi i seguenti elementi nel file TMX per garantire l'elaborazione corretta da parte dell'API Vertex AI Translation:
<header>: identifica la lingua di origine utilizzando l'attributosrclang.<tu>: includi una coppia di elementi<tuv>con le stesse lingue di origine e di destinazione. Questi elementi<tuv>rispettano quanto segue:- Ogni elemento
<tuv>identifica la lingua del testo contenuto utilizzando l'attributoxml:lang. Utilizza i codici ISO-639-1 per identificare le lingue di origine e di destinazione. Consulta l'elenco delle lingue supportate e i relativi codici lingua. - Se un elemento
<tu>contiene più di due elementi<tuv>, l'API Vertex AI Translation elabora solo il primo elemento<tuv>che corrisponde alla lingua di origine e il primo elemento<tuv>che corrisponde alla lingua di destinazione. Il servizio ignora il resto degli elementi<tuv>. - Se un elemento
<tu>non ha una coppia corrispondente di elementi<tuv>, l'API Vertex AI Translation ignora l'elemento<tu>non valido.
- Ogni elemento
<seg>: Rappresentano stringhe di testo generalizzate. L'API Vertex AI Translation esclude i tag di markup da un elemento<seg>prima di elaborare il file. Se un elemento<tuv>contiene più elementi<seg>, l'API Vertex AI Translation concatena il testo in un unico elemento con uno spazio tra le stringhe di testo.
Dopo aver identificato i termini del glossario nel glossario unidirezionale, carica il file in un bucket di archiviazione e rendilo disponibile per l'API Vertex AI Translation creando e importando un glossario.
Glossario di insiemi di termini equivalenti
L'API Vertex AI Translation accetta file di glossario per set di termini equivalenti utilizzando il formato CSV. Per definire set di termini equivalenti, crea un file CSV multicolonna in cui ogni riga elenca un singolo termine del glossario in più lingue. Consulta l'elenco delle lingue supportate e i rispettivi codici lingua.
L'immagine seguente mostra un esempio di file CSV a più colonne. Ogni riga rappresenta un termine del glossario e ogni colonna rappresenta una traduzione del termine in lingue diverse.
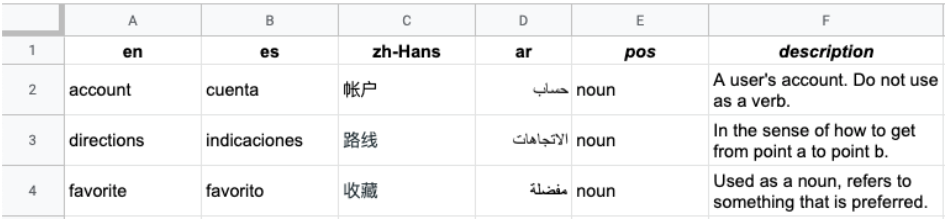
L'intestazione è la prima riga del file, che identifica la lingua di ogni
colonna. La riga di intestazione utilizza i codici lingua standard ISO-639-1 o BCP-47. L'API Vertex AI Translation non utilizza informazioni sulla parte del discorso (pos) e i valori di posizione specifici non vengono convalidati.
Ogni riga successiva contiene i termini del glossario equivalenti nelle lingue identificate nell'intestazione. Puoi lasciare vuote le colonne se il termine non è disponibile in tutte le lingue.
Dopo aver identificato i termini del glossario nel set di termini equivalenti, carica il file in un bucket di archiviazione e rendilo disponibile per l'API Vertex AI Translation creando e importando un glossario.
Carica il file del glossario in un bucket di archiviazione
Segui questi passaggi per caricare il file del glossario in un bucket di archiviazione:
- Configura gcloud CLI per l'archiviazione degli oggetti.
Crea un bucket di archiviazione nello spazio dei nomi del progetto. Utilizza una classe di archiviazione
Standard.Puoi creare il bucket di archiviazione eseguendo il deployment di una risorsa
Bucketnello spazio dei nomi del progetto:apiVersion: object.gdc.goog/v1 kind: Bucket metadata: name: glossary-bucket namespace: translation-glossary-project spec: description: bucket for translation glossary storageClass: Standard bucketPolicy: lockingPolicy: defaultObjectRetentionDays: 90Concedi le autorizzazioni
readsul bucket al account di servizio (ai-translation-system-sa) utilizzato dal servizio Vertex AI Translation.Per creare il ruolo e l'associazione di ruolo utilizzando risorse personalizzate:
Crea il ruolo eseguendo il deployment di una risorsa
Rolenello spazio dei nomi del progetto:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: ai-translation-glossary-reader namespace: translation-glossary-project rules: - apiGroups: - object.gdc.goog resources: - buckets verbs: - read-objectCrea l'associazione di ruolo eseguendo il deployment di una risorsa
RoleBindingnello spazio dei nomi del progetto:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: ai-translation-glossary-reader-rolebinding namespace: translation-glossary-project roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: ai-translation-glossary-reader subjects: - kind: ServiceAccount name: ai-translation-system-sa namespace: ai-translation-system
Carica il file del glossario nel bucket di archiviazione che hai creato. Per ulteriori informazioni, vedi Caricare e scaricare oggetti di archiviazione nei progetti.
Creare un glossario
Il metodo CreateGlossary crea un glossario e restituisce l'identificatore all'operazione a lunga esecuzione che genera il glossario.
Per creare un glossario, sostituisci quanto segue prima di utilizzare i dati della richiesta:
ENDPOINT: l'endpoint Vertex AI Translation che utilizzi per la tua organizzazione. Per saperne di più, visualizza lo stato e gli endpoint del servizio.PROJECT_ID: il tuo ID progetto.GLOSSARY_ID: l'ID del glossario, ovvero il nome della risorsa.BUCKET_NAME: il nome del bucket di archiviazione in cui si trova il file del glossario.GLOSSARY_FILENAME: il nome del file del glossario nel bucket di archiviazione.
Di seguito è riportata la sintassi per una richiesta HTTP per creare un glossario:
POST https://ENDPOINT/v3/projects/PROJECT_ID/glossaries
In base al file del glossario che hai creato, scegli una delle seguenti opzioni per creare un glossario:
Unidirezionale
Per creare un glossario unidirezionale, specifica una coppia di lingue
(language_pair) con una lingua di origine (source_language_code) e una
lingua di destinazione (target_language_code).
Per creare un glossario unidirezionale:
Salva il seguente corpo della richiesta in un file JSON denominato
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID, "language_pair": { "source_language_code": "SOURCE_LANGUAGE", "target_language_code": "TARGET_LANGUAGE" }, "{"input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Sostituisci quanto segue:
SOURCE_LANGUAGE: il codice lingua della lingua di origine del glossario. Consulta l'elenco delle lingue supportate e i rispettivi codici lingua.TARGET_LANGUAGE: il codice lingua della lingua di destinazione del glossario. Consulta l'elenco delle lingue supportate e i rispettivi codici lingua.
Invia la richiesta. Gli esempi seguenti utilizzano un metodo API REST e la riga di comando, ma puoi anche utilizzare le librerie client per creare un glossario unidirezionale.
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest
-Method POST
-Headers $headers
-ContentType: "application/json; charset=utf-8"
-InFile request.json
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
Devi ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/operations/operation-id",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Insieme di termini equivalente
Per creare un glossario di insiemi di termini equivalenti, specifica un insieme di lingue
(language_codes_set) con i codici lingua (language_codes) del
glossario.
Per creare un glossario di termini equivalenti:
Salva il seguente corpo della richiesta in un file JSON denominato
request.json:{ "name":"projects/PROJECT_ID/glossaries/GLOSSARY_ID", "language_codes_set": { "language_codes": ["LANGUAGE_CODE_1", "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ... ] }, "input_config": { "s3_source": { "input_uri": "s3://BUCKET_NAME/GLOSSARY_FILENAME" } } }Sostituisci
LANGUAGE_CODEcon il codice della lingua o delle lingue del glossario. Consulta l'elenco delle lingue supportate e i relativi codici lingua.Effettua la richiesta:
curl
curl -X POST \
-H "Authorization: Bearer TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
Devi ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID,
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
PowerShell
$cred = TOKEN
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://ENDPOINT/v3/projects/PROJECT_ID/glossaries"
| Select-Object -Expand Content
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
Devi ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/operations/GLOSSARY_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.translation.v3.CreateGlossaryMetadata",
"name": "projects/PROJECT_ID/glossaries/GLOSSARY_ID",
"state": "RUNNING",
"submitTime": TIME
}
}
Python
Installa l'ultima versione della libreria client Vertex AI Translation.
Imposta le variabili di ambiente richieste in uno script Python.
Aggiungi il seguente codice allo script Python che hai creato:
from google.cloud import translate_v3 as translate def create_glossary( project_id=PROJECT_ID, input_uri= "s3://BUCKET_NAME/GLOSSARY_FILENAME", glossary_id=GLOSSARY_ID, timeout=180, ): client = translate.TranslationServiceClient() # Supported language codes source_lang_code = "LANGUAGE_CODE_1" target_lang_code = "LANGUAGE_CODE_2", "LANGUAGE_CODE_3", ...Salva lo script Python.
Esegui lo script Python:
python SCRIPT_NAME
Sostituisci SCRIPT_NAME con il nome che hai assegnato allo script Python, ad esempio glossary.py.
Per ulteriori informazioni sul metodo create_glossary, consulta la libreria client Python.
A seconda delle dimensioni del file del glossario, la creazione di un glossario richiede in genere meno di 10 minuti. Puoi recuperare lo stato di questa operazione per sapere quando è terminata.
Ottenere un glossario
Il metodo GetGlossary restituisce un glossario memorizzato. Se il glossario non
esiste, l'output restituisce il valore NOT_FOUND. Per chiamare il metodo GetGlossary, specifica l'ID progetto e l'ID glossario. I metodi
CreateGlossary e ListGlossaries
restituiscono l'ID glossario.
Ad esempio, le seguenti richieste restituiscono informazioni su un glossario specifico nel tuo progetto:
curl
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
Python
from google.cloud import translate_v3 as translate
def get_glossary(project_id="PROJECT_ID", glossary_id="GLOSSARY_ID"):
"""Get a particular glossary based on the glossary ID."""
client = translate.TranslationServiceClient()
name = client.glossary_path(project_id, glossary_id)
response = client.get_glossary(name=name)
print(u"Glossary name: {}".format(response.name))
print(u"Input URI: {}".format(response.input_config.s3_source.input_uri))
Elenco glossari
Il metodo ListGlossaries restituisce un elenco di ID glossario in un progetto. Se non esiste un glossario, l'output restituisce il valore NOT_FOUND. Per chiamare il metodo
ListGlossaries, specifica l'ID progetto e l'endpoint Vertex AI Translation.
Ad esempio, la seguente richiesta restituisce un elenco di ID glossario nel tuo progetto:
curl -X GET \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries?page_size=10"
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.
Eliminare un glossario
Il metodo DeleteGlossary elimina un glossario. Se il glossario non esiste,
l'output restituisce il valore NOT_FOUND. Per chiamare il metodo DeleteGlossary,
specifica l'ID progetto, l'ID glossario e l'endpoint Vertex AI Translation.
I metodi
CreateGlossary e ListGlossaries
restituiscono l'ID glossario.
Ad esempio, la seguente richiesta elimina un glossario dal tuo progetto:
curl -X DELETE \
-H "Authorization: Bearer TOKEN" \
"http://ENDPOINT/v3/projects/PROJECT_ID/glossaries/GLOSSARY_ID"
Sostituisci TOKEN con
il token di autenticazione
che hai ottenuto.