Auf dieser Seite wird beschrieben, wie Dienstkonten in Cloud Data Fusion verwendet werden. Weitere Informationen finden Sie unter Dienstkonten verwenden.
Mandanten- und Kundenprojekte
Cloud Data Fusion richtet Dienstkonten ein, um auf Ressourcen in den folgenden Projekten zuzugreifen:
- Mandantenprojekt
Cloud Data Fusion erstellt ein Mandantenprojekt, das die Ressourcen und Dienste enthält, die es zur Verwaltung von Pipelines in Ihrem Namen benötigt. Beispiel: Pipelines auf Ihren Dataproc-Clustern ausführen, die sich in Ihrem Kundenprojekt befinden. Ein Mandantenprojekt ist für Sie nicht verfügbar. Wenn Sie jedoch eine private Instanz erstellen, müssen Sie möglicherweise den Mandantenprojektnamen verwenden, um VPC-Peering einzurichten.
Weitere Informationen finden Sie in der Service Infrastructure-Dokumentation zu Mandantenprojekten.
- Kundenprojekt
Sie erstellen und besitzen dieses Projekt. Standardmäßig erstellt Cloud Data Fusion in diesem Projekt einen sitzungsspezifischen Dataproc-Cluster, um Ihre Pipelines auszuführen.
Das folgende Diagramm zeigt eine Cloud Data Fusion-Instanz, die in einem Mandantenprojekt ausgeführt wird, und eine Pipeline, die in einem Dataproc-Cluster in einem Kundenprojekt ausgeführt wird.
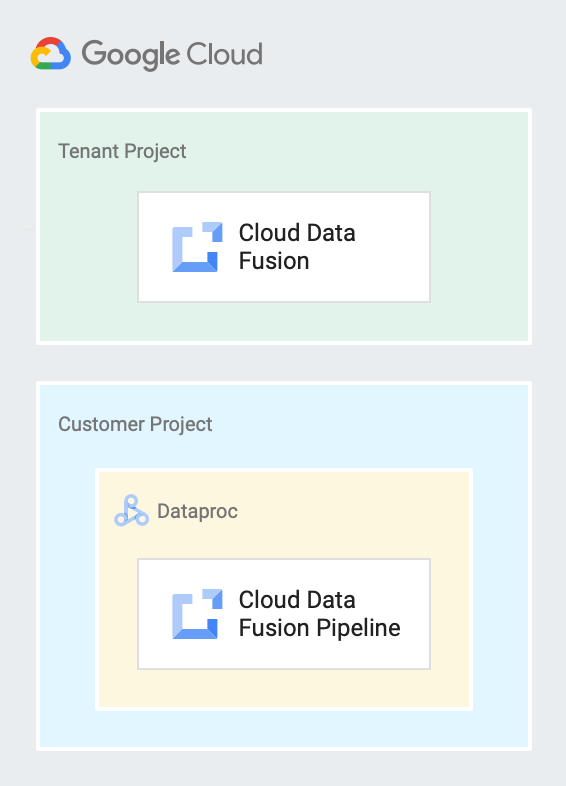
Dienstkonten in Cloud Data Fusion
Ein Dienstkonto bietet eine Identität für Cloud Data Fusion, die Cloud Data Fusion Zugriff auf Ihre Ressourcen gewährt.
Wenn Sie die Cloud Data Fusion API aktivieren und eine Cloud Data Fusion-Instanz erstellen, wird Ihrem Projekt ein Dienstkonto hinzugefügt, um auf Ressourcen wie Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner und Bigtable zuzugreifen. Dieses Dienstkonto wird als Cloud Data Fusion API-Dienst-Agent bezeichnet. Diesem Dienst-Agent werden automatisch Rollen zugewiesen.
Ein Dienstkonto wird durch seine E-Mail-Adresse definiert, die für das Konto spezifisch ist.
In Cloud Data Fusion werden die folgenden Arten von Dienstkonten verwendet. Weitere Informationen finden Sie unter Arten von Dienstkonten.
| Dienstkonto | Beschreibung |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
Der Dienst-Agent, der sogenannte Cloud Data Fusion API-Dienst-Agent, den Cloud Data Fusion erstellt, um Zugriff auf Kundenressourcen zu erhalten, damit der Dienst im Namen des Kunden agieren kann. Dieses Konto wird im Mandantenprojekt verwendet, um auf Ressourcen von Kundenprojekten zuzugreifen. Beispielsweise wird die Vorschau im Arbeitsspeicher statt in einem Dataproc-Cluster ausgeführt. Identity and Access Management-Rolle Cloud Data Fusion API Service Agent ( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
Das Compute Engine-Standarddienstkonto, das von Cloud Data Fusion erstellt wird, um Jobs bereitzustellen, die auf andere Google Cloud -Ressourcen zugreifen. Dieses Konto wird standardmäßig einer Dataproc-Cluster-VM hinzugefügt, damit Cloud Data Fusion während der Ausführung einer Pipeline auf Dataproc-Ressourcen zugreifen kann. In der Cloud Data Fusion Enterprise Edition können Sie Pipelines über ein nutzerverwaltetes Dienstkonto ausführen. Erstellen Sie dazu ein Profil über die Cloud Data Fusion-Konsole → Systemadministrator → Tab „Konfiguration“ und fügen Sie das benutzerdefinierte Dienstkonto hinzu. In Version 6.2.3 und höher können Sie ein benutzerdefiniertes Dienstkonto auswählen, das beim Erstellen einer Cloud Data Fusion-Instanz an den Dataproc-Cluster angehängt werden soll. Weitere Informationen finden Sie unter Dienstkonten in Dataproc. |
Nächste Schritte
- Datenzugriff steuern
- Dienstkontonutzerberechtigungen erteilen.
- Preise für Cloud Data Fusion